
Jun 8
A new study shows that well-tuned Small Language Models (SLMs) can outperform prompted large language models on citation verification tasks across multiple languages. Even more striking, models trained primarily on English data were able to generalize effectively to lower-resource languages with minimal
In "Multilingual and Cross-Lingual Citation Needed Detection on Wikipedia for Lower-Resource Languages," the researchers demonstrate that capability is not always a function of scale. For many multilingual and low-resource use cases, smaller, specialized models can deliver stronger performance while remaining more affordable and accessible to deploy.
For organizations building AI in resource-constrained environments, this is an important reminder: the future of AI may depend less on building bigger models and more on building the right ones.
Read the full paper >> arxiv.org/abs/2605.31136
@gerritquaremba @RechkemmerAmy @MyLove4Crochet @vrandezo @esimperl @KingsCollegeLon @Wikimedia @alcaassociation @LANGUAGESAFRICA @AfriLanguages
@AfriLanguages
#SmallLanguageModels #SLMs #LanguageAI #LowResourceLanguages #MultilingualAI #AIResearch #DigitalInclusion #SovereignAI #EqualyzAI

1
13
58
Jun 5
AI is quietly moving in a different direction. Not bigger, Not louder, but smarter about language.
We’re entering the era of lightweight language-aware systems, where intelligence is no longer concentrated in massive models, but distributed across small, efficient systems that understand how people actually speak.
Instead of forcing every conversation into one global language layer, these systems detect the language first, route the request intelligently and respond using specialized small models built for the context
It’s a shift from monolithic AI to modular, local, and language-sensitive intelligence.
For regions like Africa, where thousands of languages coexist, and code-switching is the norm, this isn’t just technical progress. It’s alignment, because the future of AI here won’t be defined by size. It will be defined by understanding.
Read more here: medium.com/@equalyz_ai/light…
@africanlanguag5 @AfricanLanguag4 @AfricaConsults @africalanguage @AfricaAI_Summit @AfricaAi2025 @AISafari
#EqualyzAI #LightweightAI #LanguageAI #AfricanAI #SLMs #SmallLanguageModels #AIInfrastructure #MultilingualAI #VoiceAI #AIForGood

3
15
118
Jun 5
A large-scale empirical study has completely re-evaluated how open-source models under 10 billion (<10B) parameters perform when augmented by structured agent workflows.
By systematically testing small models across three distinct environments as standalone base models, as single agents equipped with external tools, and within collaborative multiagent setups, the paper proves that strategic engineering can successfully bridge the reasoning and knowledge gaps typically found in smaller architectures, enabling them to match or exceed the utility of much larger systems.
Read the full paper >> arxiv.org/pdf/2604.19299
@SocialS35299403 @Proximus_LU @SlimAI50kg @SLMSOLS @LANGUAGESAFRICA @AfricaAI_ @women_in_ai
#EqualyzAI #LightweightAI #LanguageAI #AfricanAI #SLMs #SmallLanguageModels #AIInfrastructure #MultilingualAI #VoiceAI #AIForGood

12
58

May 26
LLMForge private beta this weekend!
Fine-tuning shouldn't mean 6 terminals and 6 tools. Join the waitlist.
llmforge.app
#DevTools #AITools #LocalAI #SmallLanguageModels #BuildingPublic
May 24

fine tuning LLM models are good until you actually do it. While fine-tuning models for speakcrisper.com, when realised there's no single place to handle the entire fine-tuning lifecycle.
So here it is for you - llmforge.app

2
2
87
May 19
FINER-SQL adds to the growing conversation around Small Language Models (SLMs) as viable infrastructure for enterprise AI.
Rather than relying solely on massive and expensive models, the research explores how smaller models can be optimized for Text-to-SQL tasks, improving how AI interacts with databases while remaining more efficient and practical to deploy.
For organisations handling sensitive or regulated data, this shift matters. Smaller models create opportunities for AI systems that are more cost-effective, privacy-aware, and capable of operating closer to where data is stored, without sacrificing usability.
As enterprise AI adoption grows, the future may not belong only to bigger models, but to smarter, more specialized ones.
Read full paper >> arxiv.org/abs/2605.03465
@Griffith_Uni @HumboldtUni @AmandaT8597 @VinUniversity @universitequeen @Shirley_manoto
#EqualyzAI #SLM #SmallLanguageModels #EnterpriseAI #TextToSQL #DataPrivacy
19
91

May 14
As enterprises move from #AI experimentation to real-world deployment, the focus is shifting toward models that are efficient, predictable, and purpose-built.
Small language models, when designed and deployed correctly, bring a clear advantage. They are faster, more cost-effective, and better aligned to specific industry needs, delivering outcomes that matter where it counts.
As highlighted by Sham Arora, Chief Technology Officer, Tech Mahindra, the real value lies in building AI that is not just powerful, but practical, scalable, and ready for enterprise environments.
Explore how industry-trained small language models can unlock greater value for your business: techradar.com/pro/small-lang…
#ScaleAtSpeed #EnterpriseAI #SmallLanguageModels #DigitalTransformation

1
1
2
185

May 7
𝗧𝗵𝗲 𝗘𝗰𝗼𝗻𝗼𝗺𝗶𝗰𝘀 𝗼𝗳 𝗔𝗜: 𝗪𝗵𝘆 𝗖𝗼𝘀𝘁 𝗽𝗲𝗿 𝗧𝗼𝗸𝗲𝗻 𝗪𝗶𝗹𝗹 𝗗𝗲𝗰𝗶𝗱𝗲 𝘁𝗵𝗲 𝗪𝗶𝗻𝗻𝗲𝗿𝘀
For the last two years, the AI race has been framed as:
𝗪𝗵𝗼 𝗵𝗮𝘀 𝘁𝗵𝗲 𝘀𝗺𝗮𝗿𝘁𝗲𝘀𝘁 𝗺𝗼𝗱𝗲𝗹?
But inside real AI products, a different metric is quietly becoming decisive:
𝗖𝗼𝘀𝘁 𝗽𝗲𝗿 𝘁𝗼𝗸𝗲𝗻.
Because when AI moves from demo to production, intelligence is only half the equation.
𝗘𝗰𝗼𝗻𝗼𝗺𝗶𝗰𝘀 𝗱𝗲𝗰𝗶𝗱𝗲𝘀 𝘄𝗵𝗮𝘁 𝘀𝘂𝗿𝘃𝗶𝘃𝗲𝘀.
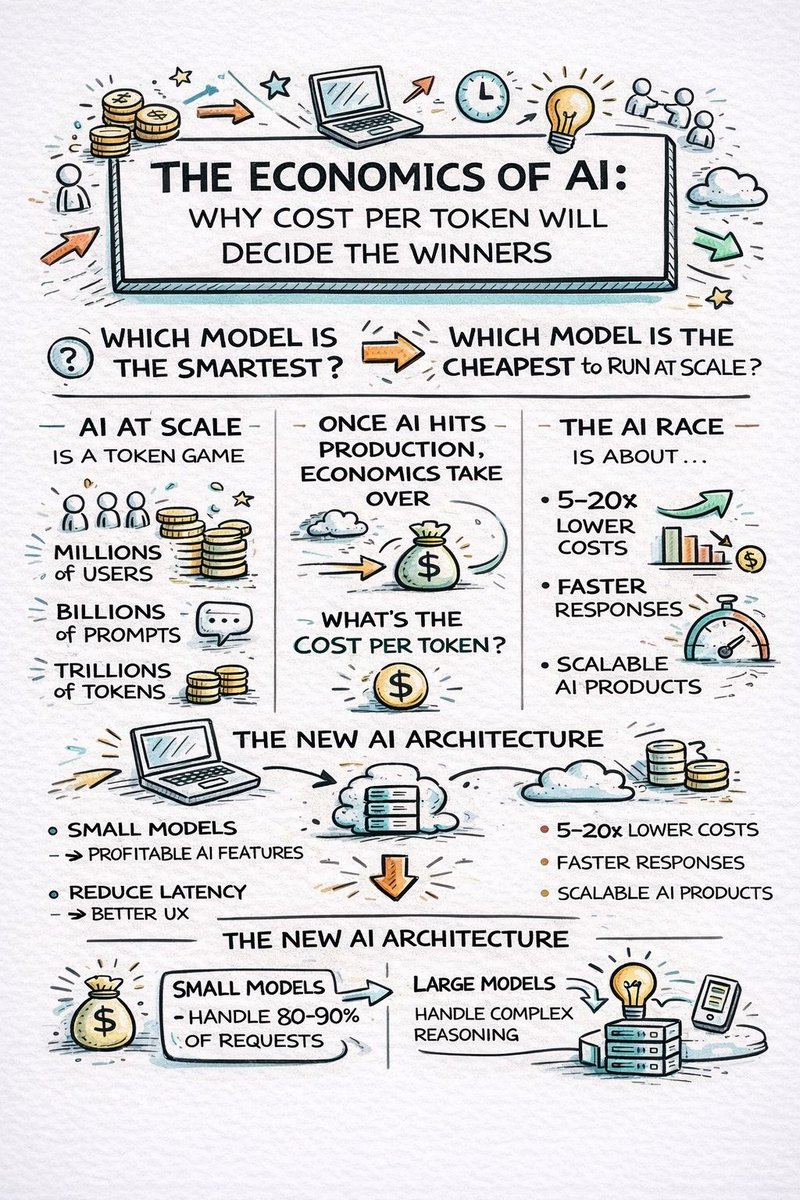
💰 𝗔𝗜 𝗮𝘁 𝗦𝗰𝗮𝗹𝗲 𝗜𝘀 𝗮 𝗠𝗮𝘁𝗵 𝗣𝗿𝗼𝗯𝗹𝗲𝗺
Every AI product eventually hits the same reality.
Millions of users
Billions of prompts
Trillions of tokens
If each request is expensive, the business breaks.
That’s why companies obsess over 𝗰𝗼𝘀𝘁 𝗽𝗲𝗿 𝘁𝗼𝗸𝗲𝗻 — the real unit economics of AI.
Even small improvements can dramatically change profitability.
Example:
• Reducing token cost by 𝟱× can turn an AI feature from 𝗹𝗼𝘀𝘀-𝗺𝗮𝗸𝗶𝗻𝗴 → 𝗽𝗿𝗼𝗳𝗶𝘁𝗮𝗯𝗹𝗲
• Reducing latency by 𝟱𝟬% can double user engagement
In AI, 𝗲𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝗰𝘆 𝗰𝗼𝗺𝗽𝗼𝘂𝗻𝗱𝘀.
⚙️ 𝗧𝗵𝗲 𝗛𝗶𝗱𝗱𝗲𝗻 𝗖𝗼𝘀𝘁 𝗦𝘁𝗮𝗰𝗸 𝗼𝗳 𝗔𝗜
Behind every AI response is an infrastructure pipeline:
• GPUs / inference compute
• token processing
• memory & context windows
• retrieval systems
• orchestration layers
Large models can be incredibly powerful.
But they are also 𝗰𝗼𝗺𝗽𝘂𝘁𝗲 𝗵𝗲𝗮𝘃𝘆.
Which is why most production systems now optimize aggressively through:
• 𝗦𝗺𝗮𝗹𝗹 𝗹𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗺𝗼𝗱𝗲𝗹𝘀
• 𝗺𝗼𝗱𝗲𝗹 𝗱𝗶𝘀𝘁𝗶𝗹𝗹𝗮𝘁𝗶𝗼𝗻
• 𝗿𝗼𝘂𝘁𝗶𝗻𝗴 𝗮𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲𝘀
• 𝗰𝗼𝗻𝘁𝗲𝘅𝘁 𝗰𝗼𝗺𝗽𝗿𝗲𝘀𝘀𝗶𝗼𝗻
All designed to reduce 𝘁𝗼𝗸𝗲𝗻 𝗰𝗼𝗻𝘀𝘂𝗺𝗽𝘁𝗶𝗼𝗻 𝗽𝗲𝗿 𝘁𝗮𝘀𝗸.
🏗️ The Winning Architecture
The most successful AI systems now follow a pattern:
𝗦𝗺𝗮𝗹𝗹 𝗺𝗼𝗱𝗲𝗹 → 𝗵𝗮𝗻𝗱𝗹𝗲𝘀 𝘃𝗼𝗹𝘂𝗺𝗲
𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹 → 𝗮𝗱𝗱𝘀 𝗰𝗼𝗻𝘁𝗲𝘅𝘁
𝗟𝗮𝗿𝗴𝗲 𝗺𝗼𝗱𝗲𝗹 → 𝗵𝗮𝗻𝗱𝗹𝗲𝘀 𝗰𝗼𝗺𝗽𝗹𝗲𝘅 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴
This architecture dramatically reduces tokens processed by expensive models.
Result:
• 𝟱–𝟮𝟬× 𝗰𝗼𝘀𝘁 𝘀𝗮𝘃𝗶𝗻𝗴𝘀
• faster responses
• scalable infrastructure
🚀 𝗧𝗵𝗲 𝗥𝗲𝗮𝗹 𝗔𝗜 𝗥𝗮𝗰𝗲
The winners in AI won’t just build 𝗯𝗲𝘁𝘁𝗲𝗿 𝗺𝗼𝗱𝗲𝗹𝘀.
They’ll build 𝗯𝗲𝘁𝘁𝗲𝗿 𝗲𝗰𝗼𝗻𝗼𝗺𝗶𝗰𝘀.
Because the real competition isn’t only about intelligence.
It’s about delivering that intelligence at a 𝗰𝗼𝘀𝘁 𝗹𝗼𝘄 𝗲𝗻𝗼𝘂𝗴𝗵 𝘁𝗼 𝘀𝗰𝗮𝗹𝗲 𝗴𝗹𝗼𝗯𝗮𝗹𝗹𝘆.
The future of AI will be decided by one simple question:
𝗪𝗵𝗼 𝗰𝗮𝗻 𝗱𝗲𝗹𝗶𝘃𝗲𝗿 𝗶𝗻𝘁𝗲𝗹𝗹𝗶𝗴𝗲𝗻𝗰𝗲 𝗮𝘁 𝘁𝗵𝗲 𝗹𝗼𝘄𝗲𝘀𝘁 𝗰𝗼𝘀𝘁 𝗽𝗲𝗿 𝘁𝗼𝗸𝗲𝗻?
#AIeconomics #GenerativeAI #AIInfrastructure #SmallLanguageModels #AIinProduction
26
29
87
788
May 5
This week, we spotlight a voice shaping the future of AI in Africa Dr. Ignatius Ezeani @ignatiusugo
At a time when most language models are built far from the realities of African communication, his work on Small Language Models (SLMs) is shifting the narrative, proving that AI doesn’t have to be massive to be meaningful.
From advancing low-resource language processing to driving research that centers African linguistic structures, Ignatius is helping redefine what “intelligence” should look like in our context.
This is exactly the future we’re building toward: AI systems that are not just powerful, but culturally aware, voice-first, and locally grounded, because the next wave of AI in Africa won’t be imported. It will be built, intentionally, by people who understand the language, nuance, and culture.
@LancasterUni @AfricaAI_ @DigiAfricanLang @AfriWiT @AfricawomeninAI @AfriAIHackathon @AfricaConsults
#EqualyzAI #ExpertSpotlight #IgnatiusEzeani #AfricanAI #AIinAfrica #LanguageAI #SmallLanguageModels

21
138
Apr 24
The latest research, "What Do Prompts Reveal About Model Capabilities in Low-Resource Languages?" uncovers a critical truth about the current AI landscape:
We have been underestimating what smaller models can do for African languages. By using a reflective prompt evaluation algorithm called GEPA, researchers found that optimizing instructions at inference time can unlock performance gains that were previously invisible.
The study reveals that with optimized prompts, smaller, more efficient models can match or even outperform much larger models. This reinforces our belief in the efficiency revolution. You don't always need more parameters; you need better instructions.
Optimization doesn't just improve accuracy; it improves structure and reliability. For low-resource settings, where model behavior can be unstable, reflective prompting functions as a form of "textual policy learning" that ensures models follow complex formatting and linguistic rules.
Static, hand-crafted prompts are no longer enough to judge a model’s true capability. To truly understand how an AI performs in languages like Yoruba, Igbo, or Hausa, we must report both baseline results and prompt-optimized results.
This research confirms a core pillar of our strategy: context is compute. By investing in prompt evolution and reflective agents, we can deploy highly capable, low-latency AI on the edge, making Sovereign AI more powerful and accessible than ever before.
Read the full paper >> openreview.net/attachment?id…
@matajson @Oduneskii @taresco_hq @AfricaAiHub @Africa4Ai @AfricaAIGovernance @AfricaAI_ @TechpointAfrica @africalanguage1
#SmallLanguageModels #AfricanNLP #PromptEngineering #Gepa #EqualyAI #Innovation #DigitalSovereignty

19
130

I share my view on SLMs over LLMs in this article published by MIT Sloan Management Review India. The future of AI will not be defined by the largest models, but by those that can be effectively deployed where they matter most.
mitsloanindia.com/article/wh…
#ArtificialIntelligence #GenerativeAI #SmallLanguageModels #LLM #AIInnovation #DigitalTransformation #AgenticAI #EnterpriseAI #AIinIndia #ResponsibleAI @APanagariya
2
3
51

📣 Deal of the Day 📣 Apr 3
Save 45% TODAY ONLY!
Domain-Specific Small Language Models & selected titles: hubs.la/Q049zmmT0
Bigger isn’t always better. Train and tune highly focused language models optimized for #domainspecific tasks. @GuglielmoIozzia #SLMs #GenAI #huggingface #opensource #smalllanguagemodels
Perfect for cost- or hardware-constrained environments, Small Language Models (SLMs) train on domain specific data for high-quality results in specific tasks. This book teaches you to build generative AI models optimized for specific fields. It provides a practical, application-focused counterpart to foundational texts like Sebastian Raschka’s "Build a Large Language Model (From Scratch)", showing you how to adapt large-scale concepts for efficient, specialized use.
You’ll learn to minimize the computational horsepower your models require, while keeping high–quality performance times and output. You will also develop SLMs that can generate everything from Python code to protein structures and antibody sequences - all on commodity hardware.

1
3
31
1,149

Apr 2
Enterprise AI scales on practicality, not size. Why small language models: specialized, fast, sovereign, are enabling the agentic future. From conversational AI to business-critical automation.
Read the article: red.ht/47lHzOY
#AgenticAI #EnterpriseAI #SmallLanguageModels #AIStrategy #DataSovereignty #HybridCloud #AIAgents

2
19
Mar 31
AI is now being designed for reality; it’s no longer being built for perfect conditions.
Across emerging markets, a clear shift is happening. Voice-first interfaces and frugal AI systems are becoming the default, not the alternative.
Instead of relying on high-end devices and constant internet access, these systems are:
Designed for low-bandwidth environments
Optimized for smaller, efficient models
Built around how people naturally communicate through speech
This is what real scalability looks like. Because for millions of users, especially across Africa,
voice isn’t a feature, it’s the interface and efficiency isn’t a compromise, it’s a necessity.
This is exactly the future we’re building toward, at @equalyz_ai .
From collecting voice data across diverse African languages, even through feature phones to enabling AI systems that can run efficiently in constrained environments.
The goal is simple: Make AI accessible where it matters most.
The next wave of AI won’t be defined by size alone, but by how well it adapts to real-world conditions.
@aitecafrica @AbujaHausa @HausaTranslator @HausaLanguage @DigiAfricanLang @AfriLanguages
#LanguageAI #VoiceAI #FrugalAI #SmallLanguageModels #AfricanLanguages #AIInclusion #EqualyzAI




1
4
29
134
Mar 26
FlexiPipe “a universal adapter” for Natural Language Processing, designed to remove the fragmentation that often slows AI development. Developed by Maarten Janssen and presented at AfricaNLP 2026. This Python-based tool provides a single standardized interface that connects NLP backends like spaCy, Stanza, UDPipe, and fastText.
With flexiPipe, developers can train and deploy models across 33 African languages using one consistent pipeline, without rewriting code every time they switch tools.
A key innovation is its Unicode normalization layer built specifically for African scripts, ensuring languages like Yorùbá, Igbo, and Amharic are processed correctly without the diacritic errors that often break standard models.
@mrtnjnssn @black_in_ai @IgboProverbs_ @bbchausa
#AfricanAI #LanguageAI #EqualyzAI #SmallLanguageModels #AfricaNLP #DigitalLanguages

2
33
292
Mar 25
We’re presenting our research paper, African Voices Nigeria: 2,500 Hours of Ethically Sourced Speech Data for Four African Languages, at the 7th AfricaNLP Workshop, co-located with #EACL2026 in Rabat, Morocco.
This recognition reflects years of deliberate contribution by EqualyzAI to advancing AI systems grounded in linguistic inclusion, digital sovereignty, and real-world efficiency for African communities.
As part of this effort, we contributed to the development of African Voices Nigeria a large-scale, ethically sourced speech dataset designed to address one of the biggest gaps in AI today: the lack of high-quality, representative data for African languages like Hausa and Yoruba.
AfricaNLP 2026 Workshop remains a key convening point for researchers advancing natural language processing for African languages, corpora development, and context-specific AI applications. Being recognized in this space reinforces the growing importance of grounded, locally driven research.
The implication is straightforward: when the data improves, the systems improve. And when the systems improve, more people are actually seen, heard, and understood.
Because this work isn’t just about models. It’s about building systems that understand people in the languages they live, think, and dream in.
At its core, EqualyzAI exists to make AI work for everyone by building inclusive, locally relevant systems powered by African data and designed for real-world impact.
@LANGUAGESAFRICA @languageafrica @AfriLanguages @AfriLangUK @black_in_ai @AI4Africa7
#EqualyzAI #EACL2026 #AfricaNLP #DigitalSovereignty #SmallLanguageModels #AIforGood #InclusiveAI

9
43
592
Mar 25
The real goal isn’t just to build AI that speaks a language, but one that understands the environment, nuances, and realities of the people using it, As Jade Abbott has highlighted
This is exactly the work we’re committed to at @equalyz_ai, building Small Language Models (SLMs) and AI systems grounded in hyperlocal African contexts, not abstract global assumptions. Because true intelligence isn’t just fluent, it’s relevant, accessible, and deeply rooted in the communities it serves.
The future of AI in Africa will be shaped by models that don’t just translate but truly understand.
@SwahiliBible @SwahiliLessons @swahililanguage @SwahiliTrainer @DigiAfricanLang @AfriLanguages
#EqualyzAI #InclusiveAI #AfricanLanguages #SmallLanguageModels #SLMs #AIForAll #DigitalInclusion #TechForGood

2
29
137
Mar 23
“AfriNLLB: Efficient Translation Models for African Languages,” by Yasmin Moslem et al., a recent paper accepted at EACL 2026, explores how smaller, optimized translation systems can deliver strong performance without the heavy infrastructure typically associated with large-scale models. It builds on the idea that you don’t need massive scale to achieve meaningful impact, you need the right data, architecture, and focus.
For a long time, progress in machine translation has been tied to bigger datasets and larger models. But this research highlights a different path: one where efficiency, localization, and deployability take priority especially for underrepresented languages, and this is where the real opportunity lies.
Because translation is not just about converting text from one language to another. It’s about unlocking access to information, services, education, and digital participation.
For African languages, that access gap is still wide. This is why the role of language data infrastructure becomes critical.
@equalyz_ai focus on collecting voice and language data, even through feature phones directly supports this new wave of efficient multilingual systems. Models like AfriNLLB can only perform as well as the data they are trained on, and for many African languages, that foundational data is still being built.
As the ecosystem shifts toward smaller, more deployable models, the importance of building high-quality, representative datasets will only increase, because in the end, the success of multilingual AI is determined, not by model size alone, but by how well it understands the languages it is built to serve.
Read the full paper >> openreview.net/pdf?id=hVJZNU…
@YasminMoslem @AfricaAI_Summit @AfricaAIA @AfricaAi2025 @AfricaChatbot
#LanguageAI #AfricanLanguages #MultilingualAI #SmallLanguageModels #AIInfrastructure #EqualyzAI

4
34
254

Mar 19
LLMs get all the attention. But they are one layer in a much larger shift happening across AI right now.
While everyone debates which foundation model wins, here is what is actually being built underneath the conversation:
Multimodal models that reason across text, image, audio, and video simultaneously. Not as separate pipelines. As a single coherent system.
Small language models that run on device, inside the firewall, without a cloud dependency. Enterprises with data residency requirements are paying close attention to this one.
AI agents that do not just generate outputs but take actions, call tools, execute workflows, and loop back on their own results. The architecture questions here are completely different from anything prompt engineering covers.
Retrieval-augmented generation that connects models to live enterprise knowledge without retraining. The quality of your retrieval architecture now determines the quality of your AI outputs more than the model itself does.
Vector databases that make semantic search a first-class enterprise capability. Every knowledge management system built in the next five years will have one.
Mixture of experts architectures that route queries to specialised sub-models, delivering frontier-level capability at a fraction of the inference cost. This is what makes cost-efficient scaling possible.
Reinforcement learning from human feedback evolving into constitutional AI and scalable oversight techniques that make model behaviour more predictable in high-stakes enterprise contexts.
Edge AI that moves inference to the point of decision, reducing latency, protecting sensitive data, and eliminating the round-trip to a centralised API for time-critical workflows.
Graph neural networks quietly transforming fraud detection, supply chain reasoning, and any domain where relationships between entities matter more than the entities themselves.
The enterprises that will lead in AI over the next decade are not just the ones that picked the right LLM vendor in 2024.
They are the ones building the architectural foundation that lets them adopt, combine, and swap these capabilities as they mature.
The LLM is the entry point. The architecture is the strategy.
#AI #LLM #EnterpriseAI #AIStrategy #MultimodalAI #AIAgents #RAG #EdgeAI #SmallLanguageModels #VectorDatabase #AIArchitecture #GenerativeAI #AIAdoption #MachineLearning #FutureOfAI #EnterpriseArchitecture #CTO #AILeadership

1
53

Mar 18
Are small language models finally having their moment? itpro.com/technology/artific… #AI #ArtificialIntelligence #MachineLearning #SmallLanguageModels #SLM #LLM #GenerativeAI #TechTrends #EnterpriseAI #EdgeAI #DataSecurity #AIInnovation #FutureOfAI #AITrends #CloudComputing #HybridCloud #AIApplications #DigitalTransformation #AIModels #TechNews
2
41
Mar 18
Small Language Models are proving that efficiency can also enhance cybersecurity.
A recent study, “Small Language Models for Phishing Website Detection” by Georg Goldenits and colleagues, explores how compact language models can be used to identify phishing websites, one of the most persistent threats in today’s digital ecosystem.
Instead of relying on heavy machine-learning pipelines that demand extensive feature engineering and constant retraining, the research demonstrates that lighter language models can analyze textual patterns in URLs and web content to detect phishing attempts effectively.
What makes this particularly interesting is the broader implication: smaller models are becoming powerful tools not just for language understanding but also for practical, real-world applications like cybersecurity.
When structured well, small models can deliver big impact.
Read more here > - mdpi.com/2624-800X/6/2/48
@GeorgGoldenits @AbujaHausa @bbchausa @abujahashtags @IgboLand_ @IgboHistoFacts
@EqualyzAI #SmallLanguageModels #CybersecurityAI #EfficientAI #PhishingDetection #AIResearch #LanguageModels

2
34
131