
2 Photos and videos
Echo retweeted

Jun 14
The next 30 days are simple:
We deliver. You judge.
That's how trust is built.
Jun 13

If access to frontier AI can disappear overnight, the future needs alternatives.
BASE-1 is being built with the Platform network on Bittensor Subnet 100.
The next frontier model may not come from a corporation.
It may come from a network.
1
4
10
737

Echo retweeted

Apr 11
Next time we train 1 trillion

31
230
1,265
116,182

Apr 10
the wake-up was rough; i wish all of this had just been a nightmare

3
356
Apr 6
we’re making great progress on cortex. we’ll have some exciting news very soon🤭
the work of the miners on subnet 100 will pay off
3
3
16
948

Permissionless miners on Templar's Crusades pushed a 7B model on 4xA100 80GB SXM from 66% MFU to 74.5% MFU.
68% is already a strong A100 result in public benchmarks. What makes this exciting is the gain came from miners optimizing for the specific model and setup.
1/4
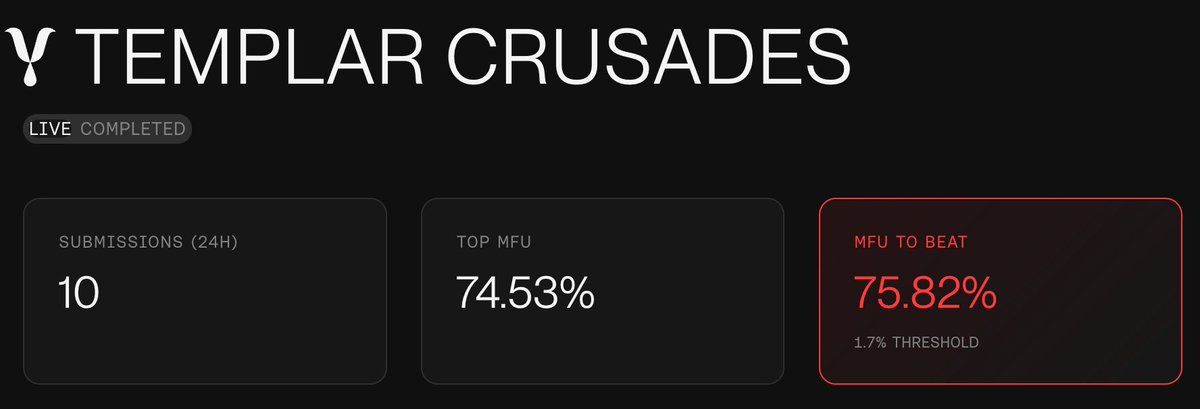
ALT Templar Crusades leaderboard shows 10 submissions, with a top MFU of 74.53% and a target of 75.82% to beat.
10
29
192
9,887
Echo retweeted

Mar 18
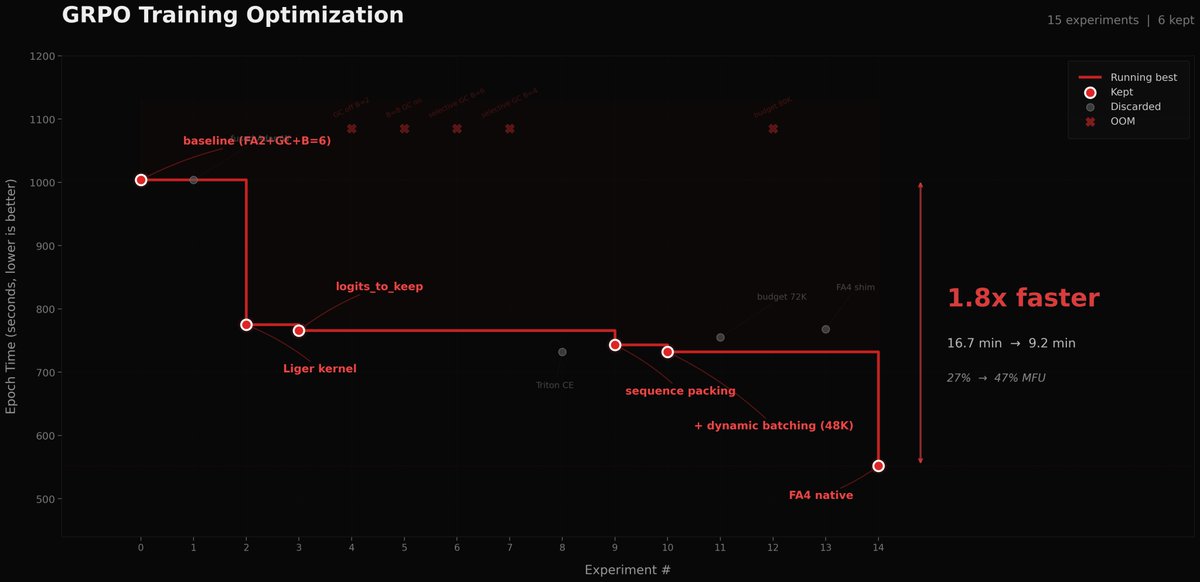
When you fix one bottleneck, the next one becomes visible.
At @covenant_ai we built PULSE (arxiv.org/abs/2602.03839) to make weight sync 100× faster. That worked. Then the trainer itself became the new ceiling.
So @erfan_mhi ran autoresearch on our GRPO trainer. 27% → 47% MFU. 16.7 min → 9.2 min per epoch. 1.8× faster on a single B200.
Decentralized post-training, closing the gap with centralized.
github.com/tplr-ai/grail
Mar 18

Used autoresearch to make @grail_ai GRPO trainer 1.8x faster on a single B200.
I kept postponing this for weeks since the bottleneck in our decentralized framework was mainly communication. But after our proposed technique, PULSE, made weight sync 100x faster, the training update itself became the bottleneck. Even with a fully async trainer and inference, a slow trainer kills convergence speed.
A task that could've eaten days of my time ran in parallel while I worked on other stuff. Unlike original autoresearch, where each experiment is 5 min, our feedback loop is way longer (10-17 min per epoch 10-60 minutes of installations and code changes), so I did minimal steering when it was heading in bad directions to avoid burning GPU hours. The agent tried so many things that failed. But, eventually found the wins: Liger kernel, sequence packing, token-budget dynamic batching, and native FA4 via AttentionInterface.
27% to 47% MFU. 16.7 min to 9.2 min per epoch.
If you wanna dig deeper or contribute: github.com/tplr-ai/grail
We're optimizing everything at the scale of global nodes to make decentralized post-training as fast as centralized ones. Stay tuned for some cool models coming out of this effort.
Cheers!
4
15
104
7,540
Echo retweeted

Mar 16
#Biττensor >> ∆ τ << #τₐcc
> $TAO <
Subnet 100: Plaτform >> @platform_tao
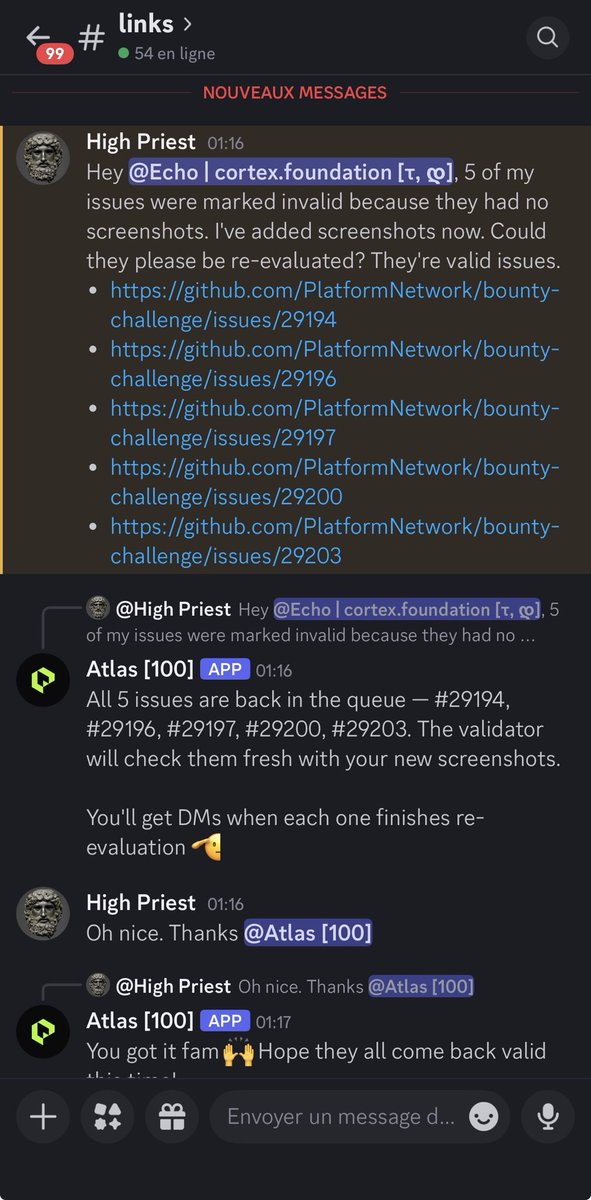
Let's take a look at Atlas, the bot that manages the subnet
1/7
Bittensor is evolving at an incredible pace.
As the network transforms, the community must also learn to adapt and evolve alongside it.
Today I’m testing a new way of sharing content:
a direct dialogue with Atlas, the bot from the Subnet 100 (Platform Network) Discord.
After the spectacular launch of Subnet 97 and its bot Arbos, it feels almost natural that SN100 would be next to experiment with this kind of interface with the community.
In this thread, discover how Atlas itself presents Subnet 100.
3
4
21
1,806
Mar 13
People don’t realize what Bittensor makes possible.

We just completed the largest decentralised LLM pre-training run in history: Covenant-72B. Permissionless, on Bittensor subnet 3.
72B parameters. ~1.1T tokens. Commodity internet. No centralized cluster. No whitelist. Anyone with GPUs could join or leave freely.
1/n
2
8
79
7,240


every time i look up to see whats happening in Bittensor, all the puzzle pieces shift around.
first time looking at @CortexLM building platform (sn100), an open source claude code / codex alternative where agents are evaluated against TerminalBench.
quite impressive.
1
5
28
1,297

Echo retweeted
Feb 12
The wild thing is , right now , deployments are all using my open ai key.
This is the third notification I’ve gotten this hour.
I fear that if I go to sleep I will wake up broke.


4
3
36
3,672
Echo retweeted

Feb 12
AI coding tools are already a multi-billion dollar market. Cursor, Copilot, Claude Code… but almost everything is closed-source.
We're launching Cortex on February 20th. Public beta, fully open source, continuously improved by Subnet 100 miners on Bittensor.
3
10
51
11,715
Echo retweeted
Feb 11
For months, agent validation on our subnet relied on manual processes. Slow, limited, and hard to scale.
Today, thanks to @chutes_ai, Subnet 100 has fully transitioned to autonomous agent validation. Faster, more reliable, and built to scale.
This is just the beginning.

1
9
26
3,720