
Economista. Developer. Me encanta Linux, el Open Source y desarrollar software enfocado a la ciencia y análisis económicos. GitHub: econopapi
Joined October 2010
- Tweets 25,790
- Following 1,602
- Followers 2,471
- Likes 39,741
1,680 Photos and videos












Pinned Tweet

Apr 29
1/ Cada vez que hay una crisis de deuda, los medios, en tono sensacionalista, mezclan indicadores distintos sin decir cuál es cuál.
Hilo sobre por qué esto importa, cómo distinguirlo y cómo terminé desarrollando un proyecto al respecto.
🧵
2
1
1,492
Jun 15
Después de más de 10 años en Linux, he llegado a esta conclusión:
Fedora, GNOME, Z Shell -> Mi entorno óptimo para programar 🐧
21




May 31
la predicción más sensata que he leído
May 30

Se viene nuevo procesador ARM compatible con Windows y optimizado para IA en local para plantarle cara a Apple.
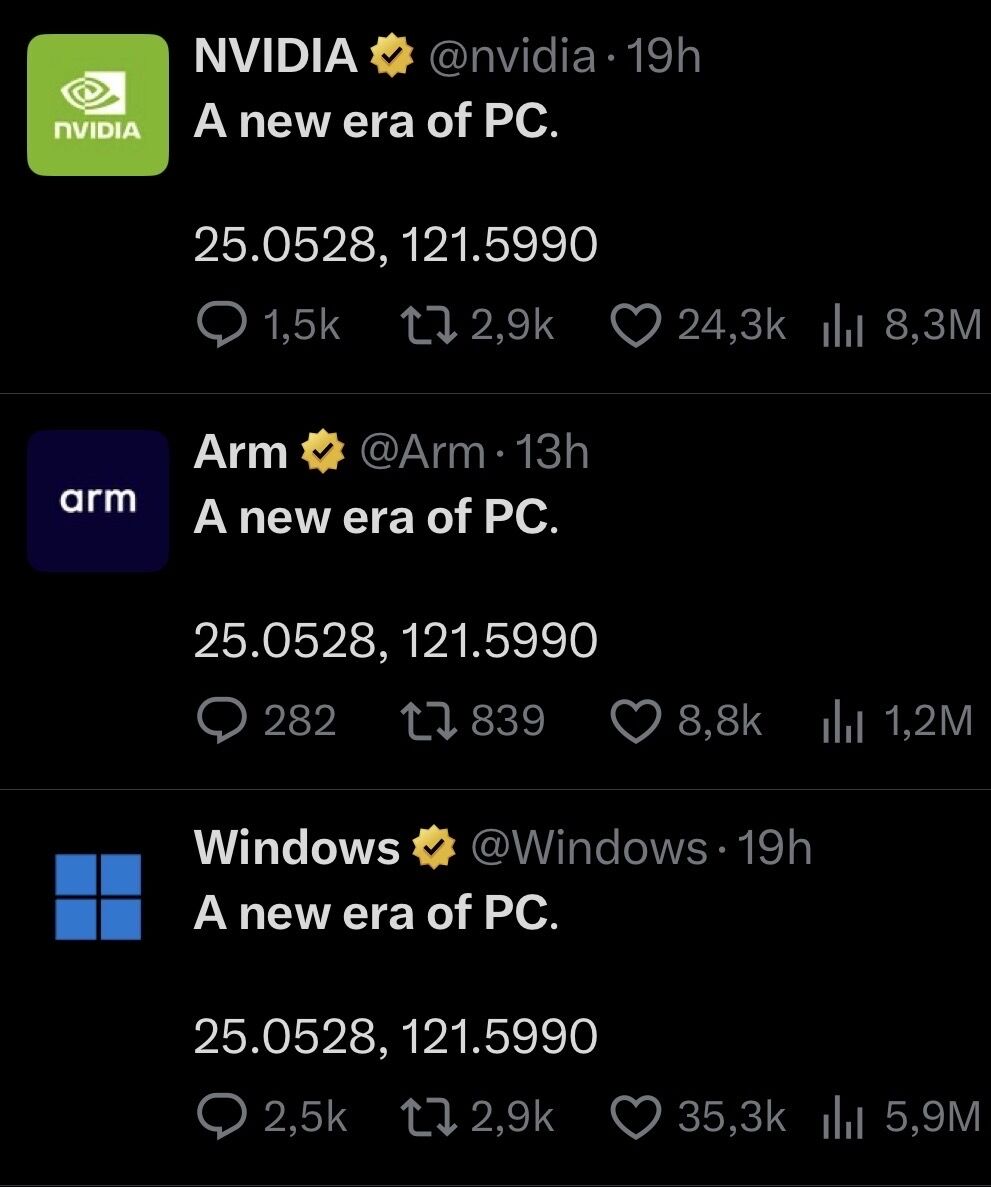
ALT Las cuentas de Windows, NVIDIA y ARM diciendo: “la nueva era de los PCs” y las coordenadas de Taipéi
15
Daniel Limón retweeted

May 28
"why use google?" webpage from 1999

197
8,714
74,504
890,460
May 29
buenísimo
May 28
Convierte cualquier texto en una animación de escritura a mano para tu web.
Funciona con cualquier fuente y es de código abierto:
github.com/KurtGokhan/tegaki
Aquí tienes una demostración para que veas:
19
May 27
así estoy en este momento


1
22
May 26
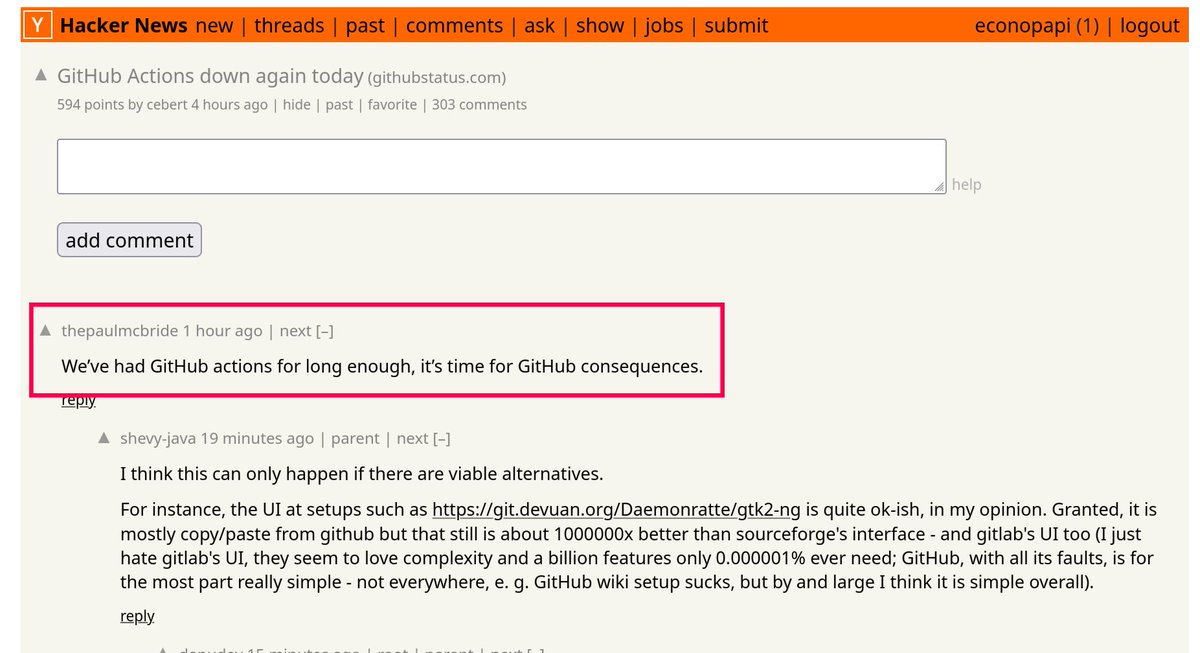
Se reportó que GitHub Actions otra vez está caído (hace unas 4 horas).
Los comentarios de hacker news son joya 😸
52
May 24
nadie está a salvo
May 23

🚨 Supply chain attack on the Laravel Lang organization:
700 historical versions across multiple community-maintained Laravel Lang packages were compromised with an RCE backdoor, including:
laravel-lang/lang
laravel-lang/http-statuses
laravel-lang/attributes
Laravel-Lang/actions
The payload targets cloud creds, CI/CD secrets, Kubernetes tokens, Vault, browser data, password managers, SSH keys, and more.
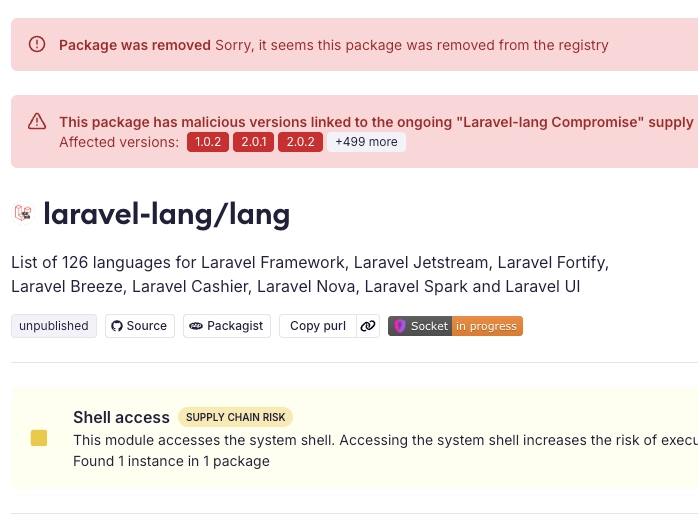
30
May 22
¿alguien aquí usa github copilot? bueno, probé su <<copilot cost simulator>> y con la nueva facturación, el precio de mi suscripción se aumentas en 10X 💀
May 22

todos sabemos que la IA subsidiada se acabó. github copilot ya va a costar "lo que es" a partir de junio.
a la izquierda tenemos mi facturación actual por uso en mayo, y a la derecha lo que costará ese mismo uso con la nueva facturación (10X MÁS CARO) 💀
#github #githubcopilot
1,444
May 22
todos sabemos que la IA subsidiada se acabó. github copilot ya va a costar "lo que es" a partir de junio.
a la izquierda tenemos mi facturación actual por uso en mayo, y a la derecha lo que costará ese mismo uso con la nueva facturación (10X MÁS CARO) 💀
#github #githubcopilot
1
4,537
May 20
cada vez que alguien usa excel como "base de datos" una foca bebé muere
127
May 16
interesante análisis del algoritmo de twitter. estamos jodidos.
May 16

✨ xAI publicó ayer el algoritmo de X y no entiendo cómo nadie se ha dado cuenta de lo que realmente tiene en sus tripas
Me he fundido 500 pavos en Claude analizando hasta la última línea
Esto es lo que he descubierto (POST LARGO, guárdatelo para luego):
0/ Cada cuenta tiene un "embedding" asociado que te describe como lo hacen los modelos de IA: en el espacio latente. Es la huella digital interna que el modelo guarda de cada usuario, un vector de números que resume cómo se comporta tu cuenta (qué temas tocas, qué engagement generas, con quién interactúas). El modelo lo usa cada vez que decide a quién enseñar tus posts. Si tu historial es bueno, queda limpio y el modelo te empuja. Si vas acumulando señales negativas (bloqueos, mutes, reports, not_interested), se vuelve tóxico y empieza a penalizarte automáticamente. Y la trampa: NO se resetea. Lo que hagas hoy sigue dentro durante semanas, contaminando todo lo que publiques después, aunque sea bueno.
Por eso salir de un shadowban o de épocas de bajo alcance se siente en X como intentar mover una gigantesca rueda oxidada: no es tu imaginación, es así tal cual. Limpiar/mejorar tu embedding es algo lento y farragoso, es como la impresión que tienes de alguien que te cae mal: por muy simpático que se vuelva contigo, va a pasar bastante tiempo hasta que te fíes de él.
Otro descubrimiento importante: el embedding no decae con un reloj. Decae con engagement NUEVO entrando al sistema. Si dejas de postear, las señales malas viejas se quedan congeladas dentro: nadie las sobrescribe. Si comienzas a crear contenido que al algoritmo le gusta, notarías mejora a partir de las 6-8 semanas y un cambio decente sobre las 12-16 semanas, asumiendo que no acumulas más señales malas en medio.
¿Por qué nadie está hablando de esto? Me parece tremendo y por fin una confirmación de esa sensación de "estoy en una mala racha" por la que todos hemos pasado.
1/ Los primeros 30 minutos lo son TODO
Si tu post no recibe interacciones rápido, Grok ni siquiera lo evalúa. Sin nota de calidad, sin análisis profundo, sin posibilidad de llegar a quien no te sigue. Muerto y enterrado
2/ La edad del post tiene un cap de 80 horas:
POST_AGE_MAX_MINUTES = 4800, en buckets de 1 hora. Después estás en el "overflow bucket" que se traduce como "antiguo, ignorar"
Mejor ventana: las primeras 0 a 12 horas. Pasadas las 24 ya estás en un bucket peor
Vamos, lejos de incentivar el contenido "evergreen", X quiere carnaza fresca continua (todo lo contrario que YouTube)
3/ MI MAYOR MIEDO ERA INFUNDADO (se supone): vivir en EU y postear en inglés para audiencia US: CERO penalización directa en teoría:
El struct PostCandidate no tiene NINGÚN campo de país del autor, IP ni localización. Gizmoduck (el servicio de identidad de X) solo devuelve follower count screen name. El transformer de Phoenix solo ve un hash de tu author_id
Lo que sí te jode indirectamente: el huso horario (tu post envejece mientras US duerme) y el idioma DEL POST
Vamos, que usar una VPN para "postear desde US" no hace literalmente nada (a diferencia que en TikTok o Instagram, por cierto)
4/ Las 5 señales negativas que matan tu alcance:
El modelo predice 22 acciones por post. 5 son pesos negativos que se RESTAN de tu score:
- not_interested
- block_author
- mute_author
- report
- not_dwelled (gente haciendo scroll sin pararse en tu post)
Esa última es brutal la verdad. Un post que se ignora es matemáticamente PEOR que uno que nunca se llegó a publicar
5/ Los shadowbans existen 100%. Hay 4 tipos distintos:
- Hard drop. X borra tu post del feed de todo el mundo sin avisarte. Se aplica a posts con contenido grave (abuso infantil, etc.) o cuentas suspendidas. Tú ni te enteras
- Etiqueta DO_NOT_AMPLIFY. Es literalmente un campo en el código que dice "no amplificar este post". Si te la ponen, los anuncios dejan de aparecer al lado de tus posts → X deja de ganar dinero mostrándote → el sistema deja de pushearte. Apagón en seco
- Reglas de BotMaker. Es el panel interno desde el que los empleados de X pueden limitar a una cuenta concreta a mano. En el código se ven las categorías que existen (Content, ContentLimited, Safety, Grok) pero NO se ve a quién se las aplican ni por qué. La herramienta está documentada, los usos no
- Embedding envenenado. El más jodido como ya vimos antes. El modelo tiene una "memoria" interna por cada cuenta. Si tu cuenta acumula suficientes "no me interesa" bloqueos silencios reports a lo largo del tiempo, esa memoria se vuelve tóxica. A partir de ahí, incluso tus buenos posts futuros se penalizan automáticamente. Nadie lo decidió. El modelo simplemente aprendió que tu cuenta da mal engagement, y se autocorrigió
6/ Solo los posts ORIGINALES pasan por el "Banger Screen"
Las respuestas y retweets nunca entran en el clasificador de calidad de Grok. Si te pasas el día respondiendo a cuentas virales, estás optimizando para el Reply Ranker, NO para la amplificación
¿Quieres que te descubran fuera de tu red? Escribe posts originales, no hay otra
7/ Las respuestas a cuentas pequeñas pasan por escáner anti-spam. Las respuestas a cuentas grandes pasan por Grok
Dos clasificadores distintos. El SpamEapiLowFollowerClassifier pega a las respuestas a cuentas pequeñas. El ReplyRanker puntúa de 0 a 3 con Grok las respuestas a cuentas grandes
"¡Primero!" o respuestas solo con emojis sacan un 0. El rollo tipo "Sir, this is a Wendy's" se penaliza. Vamos, que si escribes respuestas, más te valen que aporten algo, si no, mejor ni te molestes
8/ El 50% de todas las peticiones al feed son "tráfico shadow"
is_sampled(request_id, 0.5) marca como shadow la mitad de cada feed request. Muchas features contextuales (inferencia de género, demografía, preferencias de topics Grok) solo se activan en shadow O con un feature flag
Traducción: literalmente no puedes saber qué versión del algoritmo está viendo cualquier usuario. La mitad de tu audiencia está en un experimento en cualquier momento
9/ El dwell (el tiempo que un usuario se queda mirando tu post antes de hacer scroll) es 5x veces mejor que recibir likes
El scorer tiene 5 señales distintas de dwell (dwell, cont_dwell_time, click_dwell_time, etc.) pero solo 1 señal de favorito.
- Un post con un montón de likes pero la gente lo lee 1 segundo y sigue scrolleando → score bajo
- Un post con pocos likes pero la gente se queda 8 segundos leyéndolo → score alto
¡Optimiza por tiempo pasado en tu post, no por likes!
10/ Cosas que sí funcionan:
- Engagement en los primeros 10 min. Manda DM a tus colegas, pingea a tu comunidad, lo que sea
- Postea en la zona horaria de TU AUDIENCIA, no en la tuya. Para targetear US: 8 a 11am ET (14 a 17 hora Madrid)
- No postees 5 cosas seguidas. El AuthorDiversityScorer multiplica cada post siguiente tuyo por decay^position. Para el post 4 ya estás en el suelo
- Vídeo ≥ 10 segundos. Por debajo de MinVideoDurationMs pierdes el peso VQV entero
- Vídeos con audio. Grok corre ASR (speech to text) en cada vídeo. Sin audio = señal en blanco
- Cita virales de tu nicho. El modelo ya sabe que el original engancha, tu valor añadido se apila encima
11/ Cosas que te destrozan el alcance:
- DESCUBRIMIENTO DE LA HOSTIA: hilos de más de 10 tweets. El DedupConversationFilter solo deja 1 tweet por conversación por feed. Los megahilos son matemáticamente un desperdicio
- Repostear el mismo contenido. Los bloom filters lo deduplican
- AI slop. Hay literalmente un campo slop_score en el output del BangerScreen. Lo detectan explícitamente
- NSFW/violencia/odio sin etiquetar. Auto MediumRisk = sin ads = shadowban estructural
- Spamear respuestas a cuentas pequeñas. Hay un clasificador específico para eso
12/ Lo que NO han publicado los muy pillines:
El esqueleto es público. Los diales no
- Los valores numéricos exactos de cada peso (FavoriteWeight, ReplyWeight, OonWeightFactor, AuthorDiversityDecay). Viven en xai_feature_switches::Params, config externa
- Los prompts reales de Grok (los 7 prompts de policy PToS, BangerMiniVlmScreenScore, SafetyPtos). Pueden tener literalmente cualquier framing
- Las reglas de BotMaker que aplican DO_NOT_AMPLIFY a cuentas concretas
- util/phoenix_request.rs, que construye la llamada final al modelo
- 25 crates xai_* referenciados pero no incluidos
- Los pesos del Phoenix de producción. Solo han publicado la versión mini
Mi teoría: nos han puesto un esqueleto algo escuchimizado del total que tienen. El músculo (los pesos) y el cerebro (los prompts y las reglas de BotMaker) son completamente opacos. Se han reservado lo mejor, está claro
13/ Chuleta resumen para no olvidar:
- Los primeros 30 min importan más que cualquier otra cosa
- Tu ubicación es irrelevante, tu timing y tu idioma no
- Los shadowbans existen en 4 sabores. El peor es el modelo envenenándote el embedding de autor en silencio a partir de señales negativas pasadas, levantar caveza limpiando tu embedding te va a costar horrores, pero se puede
- Las respuestas y retweets no pasan por el clasificador de calidad. Los originales sí
- El dwell (que alguien se quede mirando tu post) le gana al like 5 a 1
- La mitad del tráfico está en algún experimento en cualquier momento
- Se han reservado lo mejor del algoritmo, pero bueno, algo es algo

39
May 15
alto marketing
May 14

I sometimes wonder what a non-tech person thinks when they see these billboards
Do they even understand any of it

46
