
Joined May 2021
- Tweets 16,447
- Following 4,125
- Followers 2,784
- Likes 122,426
2,174 Photos and videos















You're going in the right direction when the things you value are bringing you more energy, and the things you avoid would have taken your energy.
1
18
Health is a maze we’re not built to navigate. We speculate wildly, fixate on single symptoms, obsess over alarming words, and are easily swayed by the latest headline or anecdote. Faced with an ocean of data—studies, personal journals, poetry, occult lore, clinical trial acronyms—the human mind simply cannot hold it all, let alone sort, correct, and synthesize it. Yet that’s exactly what the body demands: a coherent picture of its intricate web of processes.
Enter the grand project: the health of our species, rendered intelligible not by hunches, but by intelligence itself. Large language models are, for the first time, able to take on what I call the Health Hyper Object (HHO)—the entire sprawling, contradictory, and deeply human archive of what we’ve said and written about our own physiology.
What is health, really? It’s physiological processes, yes, but they’re marked and recorded in institutional and historical contexts as words and acronyms. Those symbols derive their power from thousands of papers, each layering meaning onto strings like “IL-6” or “HbA1c.” The objective side of the HHO alone—PubMed—contains somewhere between 30 and 80 billion words of dense, interlocking scientific discourse.
Then there’s the subjective side: first-hand accounts written in deeply personal semantic schemas, what you might call individual idioglossia. This is the poetry of illness, the occult writings that map inner states to celestial rhythms, the direct diaries and journals outlining specific effects of a particular food, a particular practice. From 1800 onward, all the world’s poetry, journals, and books might amount to 10 trillion words, each one encoding a fragment of lived bodily experience.
And strewn across both realms are gaps in knowledge that can be inferred. We know A does B in some situations, and from another vector of perspective we know B does C, but no one has yet recognized that A does C. These hidden connections are latent in the data, waiting for a mind that can see across the silos.
Now imagine an LLM that ingests not just PubMed but all 10 trillion words of that subjective and objective sprawl. Its first monumental task is to make the corpus intelligible to itself: indexed, searchable, coherent, corrected where error has crept in, duplicates dissolved, contradictions flagged. Then the real work begins. Health is to be pulled out of this mass by inference—by statistical methods that sum up additions, delete redundant claims, correct mistakes, order sequences, sort relationships, compare outcomes. The body is just an intricate web of processes, and processes can be processed.
The human failure here is not a moral one; it’s a cognitive limit. We can’t hold 10 trillion words in mind. We seize on a vivid phrase and overlook a quiet statistical signal. We weave stories around a single data point. LLMs suffer no such frailty. They can sift the idioglossia of a 19th-century mystic and cross-reference it with a 2024 meta-analysis, spotting the A→C inference that a thousand specialists missed.
Understanding health is not a matter of willpower or intuition. It’s the job of intelligence—at a scale and patience no human can muster. This is the promise of the Health Hyper Object, transformed by LLMs from a cacophony of symbols into a living, navigable map of what it means to be well.
(Wrote myself, then put through Deepseek.)
1
23
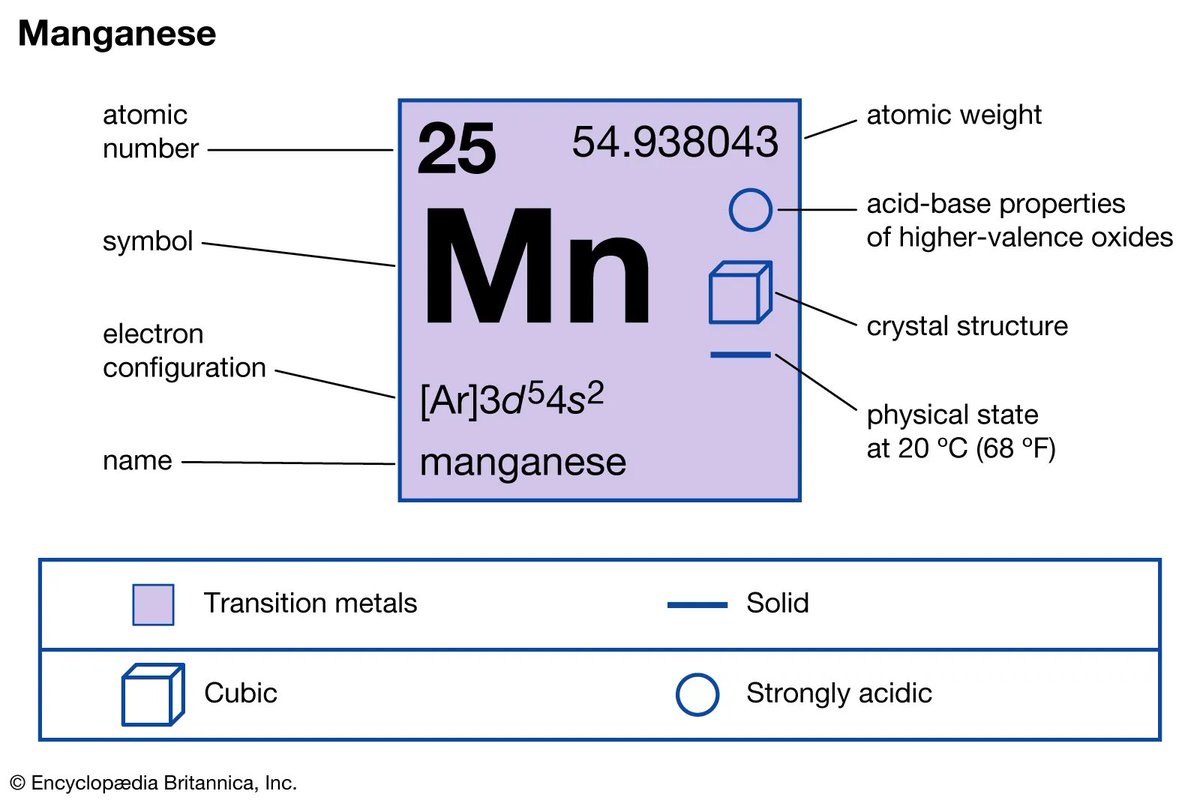
Manganese might increase blood:
SOD2 (manganese dependent): Super Oxide radicals to Hydrogen Peroxide
Hydrogen peroxide to higher HIF-1α
Higher HIF-1α higher Hypoxia Response Element transcription
Higher HPE higher EPO
Higher EPO more blood.
32
One man's heaven is another man's hell.

Would love to hear you and @DrJackKruse discuss deuterium in a 10 hour long podcast 😁
1
65
Look at this and tell me your EVERYTHING dont completely change the way you look.


5
110
Pharma = spiritual leftism
Mitochondria raped by Superoxide?
Pharma: Intravenous Gkt2812471847714, Gene editing, Alien biotech, Recombinant synthetic human SOD. Cross fingers.
Real Solution: A bit more Manganese for Manganese-Dependent SOD2.
1
1
62
We see this again in the macro scale about what to do with crime:
Leftism: Well shiet, it be da fud dezerts in shiet, dats why da crime be happenin.
Real Solution: We should arrest the black stealing rapist thugs that are stealing and raping so they won't steal and rape.
46
"Wow look at this sexy hot dude with all that tough muscle you just want to punch softly and kiss slowwwly. Nietzche Italy."
*two images attached*
There's a gay ass post like this every 20 seconds on this website.
2
8
492
Google skeletal fluorosis. Why then would you use flouride?
1
95
We begin with a blank canvas. Landauer’s Principle: erasing information costs heat.
Moving or computing data? In theory, free. But forget a single bit—and energy spills.
At room temperature, the price is tiny but sacred: ~2.87 × 10⁻²¹ joules per lost bit.
Today’s chips waste heat from resistance. Tomorrow’s will hit a wall: the act of forgetting becomes the furnace.
A supercomputer erasing trillions of bits can’t run cooler than this limit. Forgetting is physical.
The only escape? Reversible computing—undo operations, lose nothing, pay nothing.
To compute in space thus requires mastery of reversible computing.
The solution to this problem determines the future of interstellar computation.
Strange: forgetting takes energy.
@elonmusk thoughts?
3
149
Bisexuality



25
726
You can mitigate the damage of certain things:
Iron, pufa, mercury, etc.
By simple reverse engineering:
What binds? What turns it into the less reactive forms? What sends it to excretion pathways?
Binding Inactivation Excretion.
Then consuming such substances which do any of those three things prior to and during consuming the toxins. Though prior is better because it saturates the scene for the upcoming damage.
For example (not exhaustive):
Iron: Zinc, Copper, Vitamin E, coconut oil, Calcium, coffee.
PUFA: vitamin E, coconut oil, saturated fats, magnesium, glycine.
Mercury: selenium, vitamin e, coconut oil, sulfur/garlic/taurine.
Also keep in mind things that do the opposite:
Like how Vitamin C (ascorbic acid) reduces ferric iron (Fe³⁺) to ferrous iron (Fe²⁺), a more dangerous form. So maybe OJ with red meat is poor timing.
Then there are other things to consider, like how zinc and copper compete, so really you may want to first consume copper, wait, then consume zinc, wait, then consume red meat with iron.
All of this is preliminary, but if anyone wants to build a fuller chart, that's something you could do.
2
3
26
1,229
"If I take both of these at the same time my reproductive organs feel like they're being electrocuted
If I do too much of that I want to throw a baseball 100 yards away
These three together won't let me sleep for days
If I take those two together I'm bound to call my ex
If I have another thing with the last two I'll call all of my exes
If I take these 4 things together I'll call various 3 letter agencies and start making demands from extreme levels confidence like I'm the Great Gatsby
Too much water and my bones will leach out their calcium
Too much water and I feel TSH being produced
Too much of that and both my gonads and prefrontal cortex feels fried
Too much nicotine and the walls of my blood vessels choke me to death from the inside
Too much salt and. Well I've never had an issue with salt
Too much potassium and my heart aches
Too much thinking and my heart aches
Too much magnesium and I can fall asleep if I stand too fast
Too much progesterone and I'll have breasts
Too much zinc and my gaze fixes angrily
Too much DHEA and I'll have no cortisol, good and bad thing
I have a knack for taking NAC too often
Glycine tastes like syrup some days I should just put it in water
I've never had too much l theanine but then again there are only so many teaspoons I can take before it's boring
Too much baking soda is again electrically dangerous
My body is a thousand batteries plugged into sex machines, the elves come from my right visual field, the jesters run from the left, I have two hands where I'm left handed for sports and right handed for dishes and writing, I have plants that are dying, I've put copper sulfate on trees and watched them grow, I'm hyper vigilant in public from foids hitting on me people roping me into drama and again three letter agencies. I hate scented candles.
When I'm not on my phone I'm hopeful."
7
590
Synthesis


1
34
957
EOs are spiritually eastern too, sharing huge commitments that aren't really necessary, like living on top of columns, or living in caves.
Jun 12

هندي يُدعى "دولت جیری جی مهاراج" قرر ترك الدراسة الجامعية والتحول إلى التديّن ونذر نفسه لأمر واحد فقط وهو الوقوف إلى الأبد.
السبب؟
هذه العملية الدينية ستوصله في النهاية لرؤية الإله الهندوسي (ماهاديف) حسب اعتقاده.
بعض التقارير تقول بأنه منذ 12 عام وهو على هذا الوضع، لم يجلس أو ينم على الأرض بل ينام واقفًا مستخدمًا دعامة.
في المقطع أحد المتطوعين يقوم بتنظيف ساقيه بوضع مراهم موضعية ومطهرات للمساعدة في تخفيف التورم والعناية بالحالة الصحية الناتجة عن سنوات الوقوف الطويلة.
يُذكر أن الهندي "دولت جیری جی مهاراج" لم يرى الإله المذكور حتى اليوم.
5
822
I scrolled through my bookmarks thinking it was my FYP and I was thinking "wow all of these posts are bangers"
4
85
"Don't wrile up the dog."
Jun 12

there's a sex therapist who has a ritual of making out with her husband every night before bed, and so many of the comments on her posts are some version of "but what if he gets turned on and I don't want to have sex" and i need men to understand and prioritize non sexual touch.
2
1
15
1,240
How many baby mama's this n188a got?


5
517

2
182
I agree with Kalos because he died and came back to life 🦶🦶😋😋😋
Jun 12

Peaters claim that people develop a "foot fetish" due to vitamin K deficiency, but I've been taking this daily for the last six months and my craving for succulent toesies is as powerful as ever. These are very evil people who want you to think there's something "wrong" with you that needs "fixing." Be careful. #FeetFriday


1
24
1,266