
contrarian cybersecurity, internet intelligence and sanboxing from @epiapp
Joined December 2025
- Tweets 20
- Following 7
- Followers 13
- Likes 5,471
1 Photos and videos
Epi Security retweeted

Jun 15
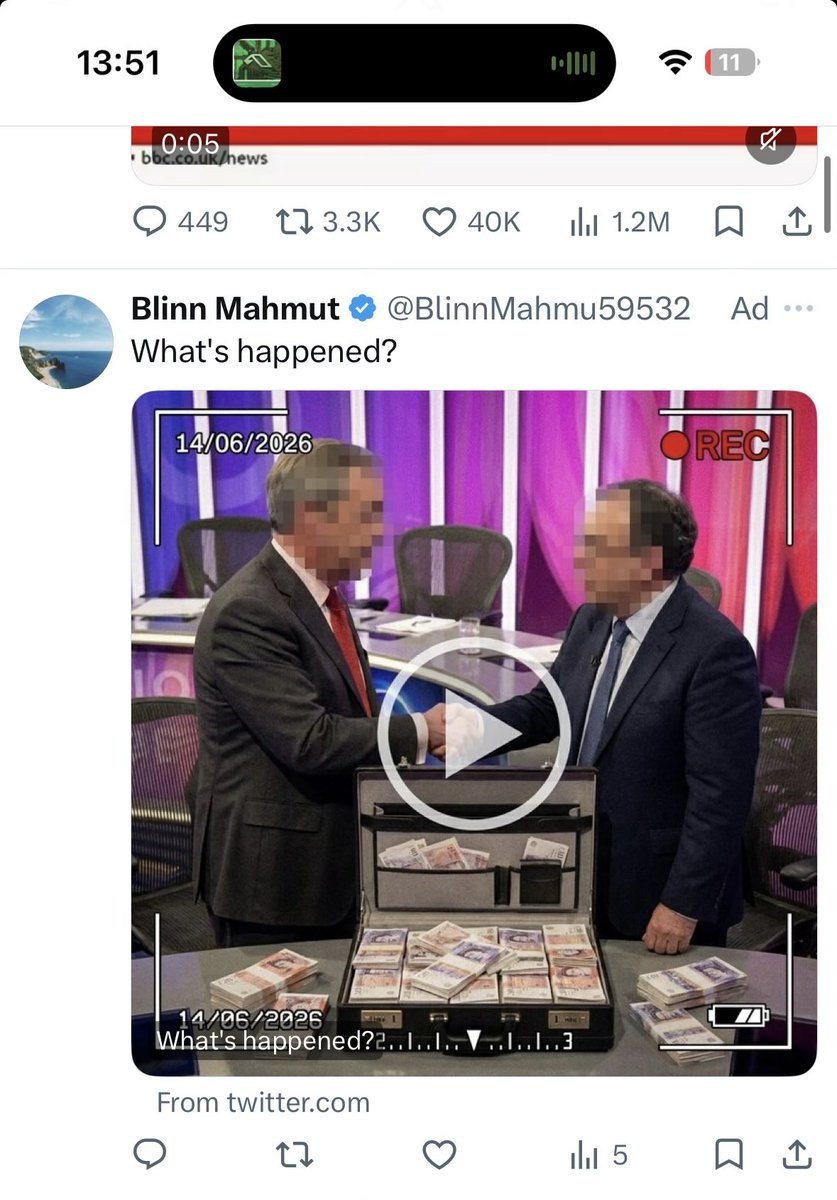
BREAKING & EXCL: Malicious Farage and Andrew Bailey scam ads are continuing today.
Threat actors are now pixelating the faces of Farage and Bailey to evade automated detection.
This confirms what I suspected: X is using AI image models and face recognition to detect the scam ads.
X needs to check the URLs of ads and posts to defeat the scams.
I stand ready to work together, as always, in service of the public.
Jun 12

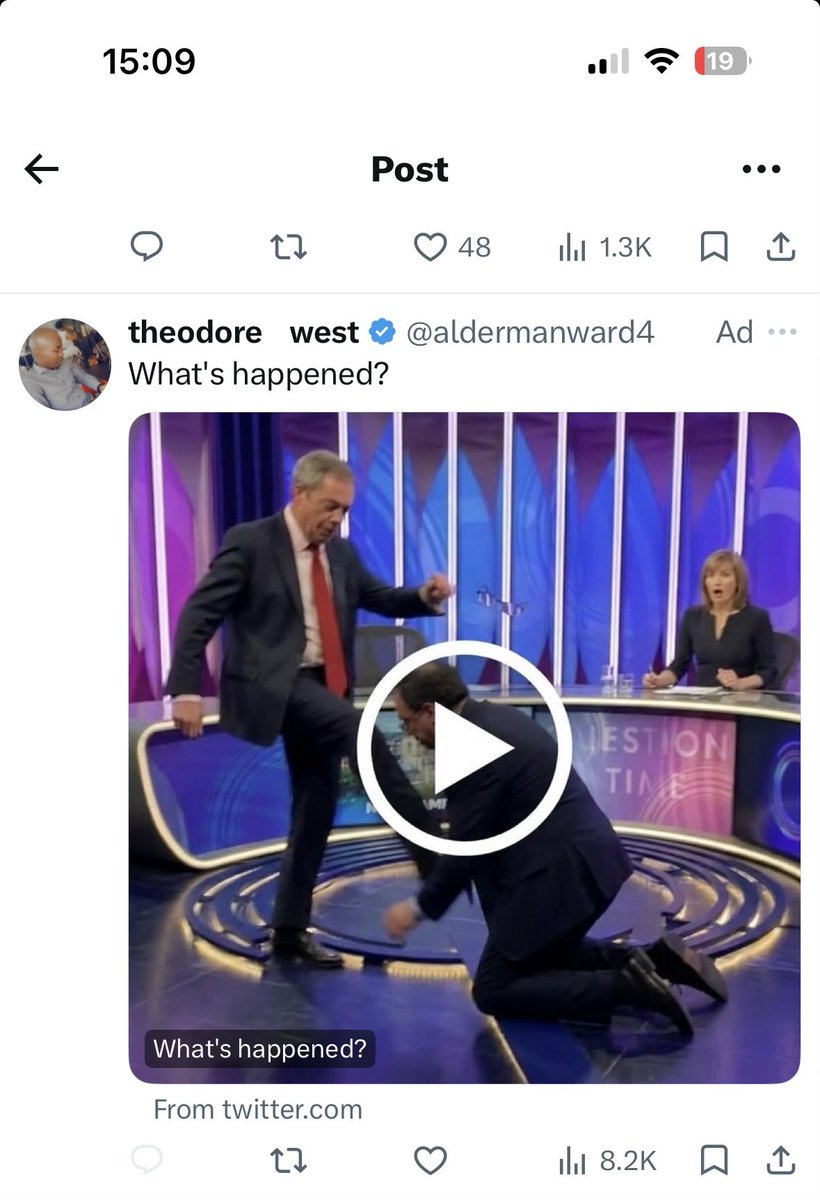
BREAKING: Farage scam ads are still propagating on X. This one was just detected at 15:09 today. Featuring imagery similar to the previously seen variants
14
4
6
449
Epi Security retweeted
Jun 14
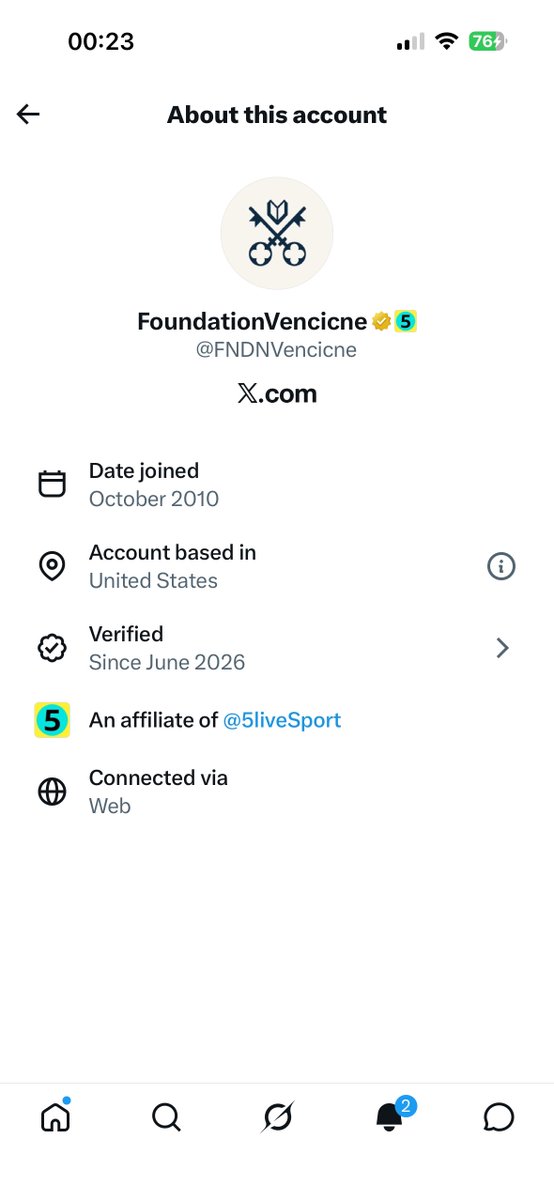
The X account of BBC 5 Live Sport @5liveSport looks to be compromised, with scam affiliates listed under the account

Jun 13
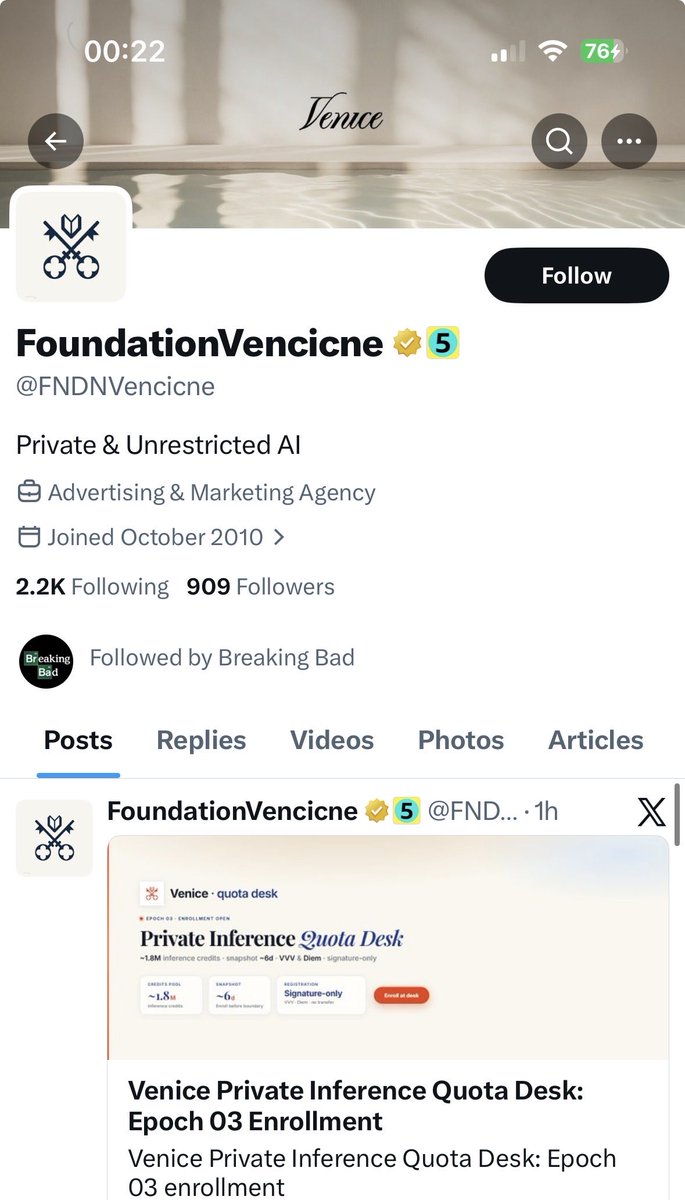
BREAKING: Something really bad has just happened with the BBC 5 Live Sport account on here. Looks to be compromised.
Two scam accounts are now affiliated with BBC 5 Live Sport:
[@]FNSNVencicne
[@]MngmntTrade
[@]FNSNVencicne is NOT Venice AI but purports to be
[@]MngmntTrade is a crypto and investment scam vehicle
@bbc @bbc5live @5liveSport please remediate and investigate immediately
Meanwhile, do not click any links from the 5 Live Sport account as it may be compromised. Investment scams may soon appear from the account and the affiliates.


2
2
6
357
Epi Security retweeted
Jun 13
BREAKING: Something really bad has just happened with the BBC 5 Live Sport account on here. Looks to be compromised.
Two scam accounts are now affiliated with BBC 5 Live Sport:
[@]FNSNVencicne
[@]MngmntTrade
[@]FNSNVencicne is NOT Venice AI but purports to be
[@]MngmntTrade is a crypto and investment scam vehicle
@bbc @bbc5live @5liveSport please remediate and investigate immediately
Meanwhile, do not click any links from the 5 Live Sport account as it may be compromised. Investment scams may soon appear from the account and the affiliates.
8
4
12
4,893

Jun 7
In Lisbon for Global Anti-Scam Summit!
Jun 7
jk, hello Lisbon! 🇵🇹 I'm here for the Global Anti-Scam Summit this week. Hit me up if you're around. I also now have a spare ticket

4
69
Epi Security retweeted
May 27
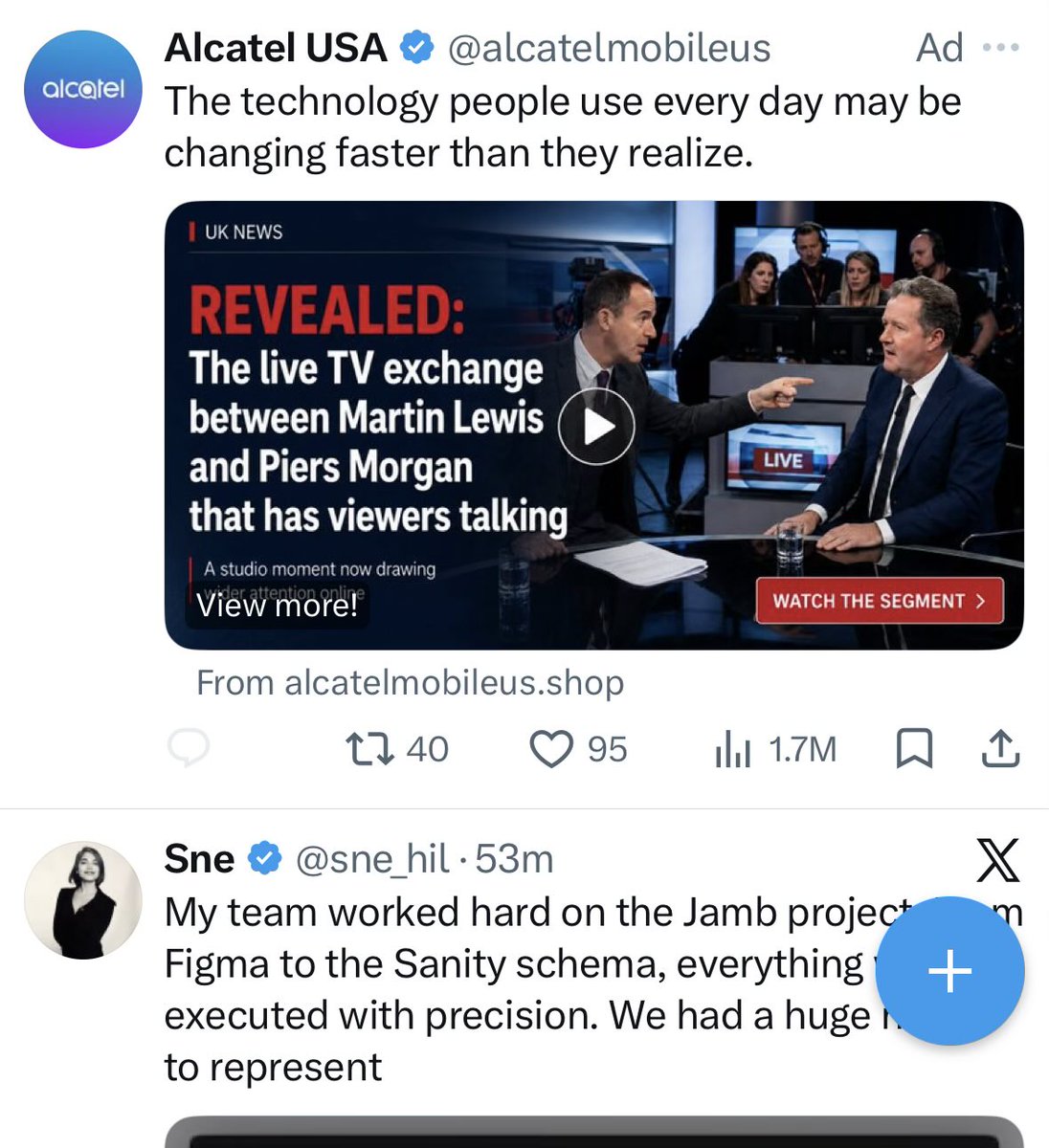
16:55 UK time. Ad still live. Now 1.7 million impressions for this phishing campaign
May 27
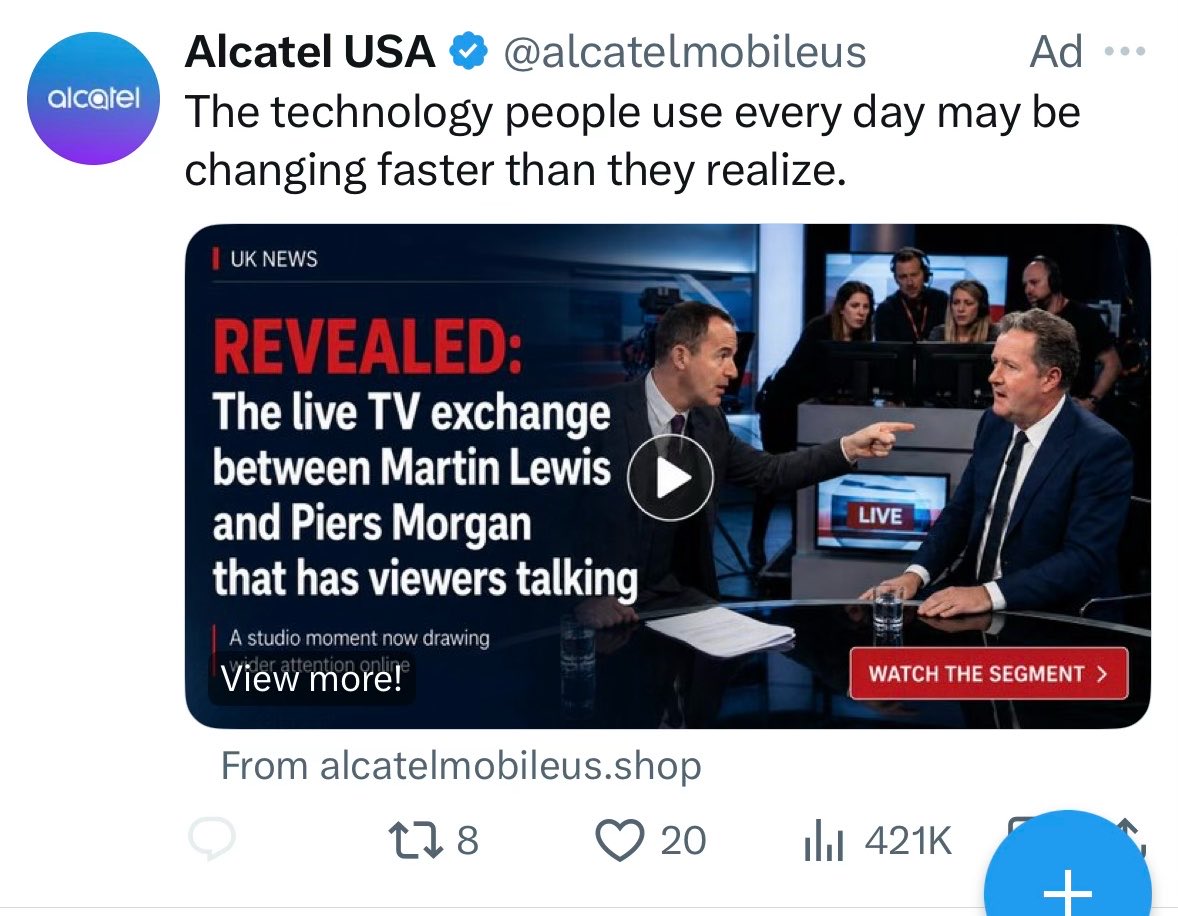
As of 14:30 UK time today, this phishing ad campaign is still live on X, now reaching over 421,000 views after being active for 16 hours. It has not been removed and the Alcatel USA account is still compromised.
Take this down @XSecurity @Safety @ads
cc @nokia
2
4
9
525
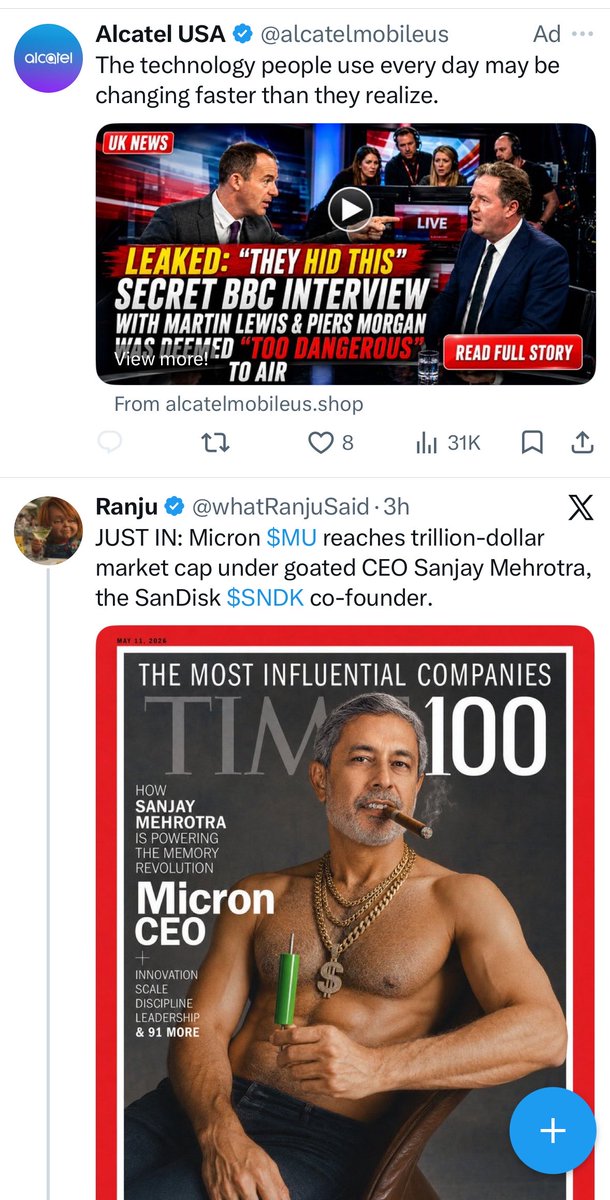
May 27
PUBLIC ADVISORY from @episecurity: The X account for Alcatel USA [@]alcatelmobileus (21.8k followers) has been compromised and is currently pushing scam ads.
May 26
PUBLIC ADVISORY: The X account for Alcatel USA [@]alcatelmobileus (21.8k followers) has been compromised and is currently pushing scam ads.
This is the biggest account I've seen taken over so far — a major brand with 21.8k followers. The account last posted in 2019.
Don't trust this account or the links it posts at this time.
Please share widely and tag the people to remediate this across X Trust and Safety @Safety
There is a broader issue. Scam ads on X are rife and getting worse. Epi and I stand ready, as always, to help all that we can with our internet intel and services, which block these sites by default. No opportunism; just public service.
1
6
57
Epi Security retweeted
May 26
PUBLIC ADVISORY: The X account for Alcatel USA [@]alcatelmobileus (21.8k followers) has been compromised and is currently pushing scam ads.
This is the biggest account I've seen taken over so far — a major brand with 21.8k followers. The account last posted in 2019.
Don't trust this account or the links it posts at this time.
Please share widely and tag the people to remediate this across X Trust and Safety @Safety
There is a broader issue. Scam ads on X are rife and getting worse. Epi and I stand ready, as always, to help all that we can with our internet intel and services, which block these sites by default. No opportunism; just public service.
23
4
15
2,531
Epi Security retweeted
May 19
PUBLIC ADVISORY for Instagram users from @epiapp: We have responsibly disclosed a critical security vulnerability to Meta about Instagram. We are not detailing the vulnerability here, but it impacts the Instagram in-app web browser.
We are issuing this redacted public advisory in the public interest.
We advise Instagram users to be especially cautious and vigilant when using the Instagram browser, and to refrain from using the in-app browser to log in to third-party sites and services at this time.
It is in the public interest for users to be aware and act accordingly, because the vulnerability is one of web trust as much as an exploitable technical failure. It affects all Instagram users worldwide right now, and we are concerned of active exploitation.
Don't log in to sites in the Instagram web browser at this time.
We stand ready to work closely with Meta on fixing this vulnerability and improving the security of the in-app browser.
May 19
we intend to publish advisory information for the public shortly. we will not publish the vulnerability, but will talk about an unspecified vulnerability in a part of the app, so users can be informed and act accordingly
we believe there is clear public interest to do so
1
7
33
5,946
Epi Security retweeted
Apr 10
Happy Phish Friday! Thank you for checking your links and catching the phish this week

3
12
606



Epi Security retweeted
Mar 31
Made a script to check our org and help others detect if they're affected by the Axios NPM library compromise.
Axios is a hugely popular HTTP request library, installed over 100 million times every week, and is used in hundreds of thousands of software projects.
This script checks a batch of Node repos in one go. Run it on your dev machines, CI and environments.
gist.github.com/alexgreenlan…
3
6
19
1,783
Epi Security retweeted
Mar 19
Want to stop getting phished? Use a good link checker!
The Epi link checker cares about your privacy and security. It doesn't log or record input URLs, doesn't track you, uses no third-party scripts, is free and requires no login. It resolves all redirects for you in its sandbox, so you get the right trust verdict — for the final destination.
No star ratings. No subjective scores. We simply tell you whether a site is trusted, legitimate, malicious or unsafe.
epihq.com
3
8
270
Epi Security retweeted
Jan 30
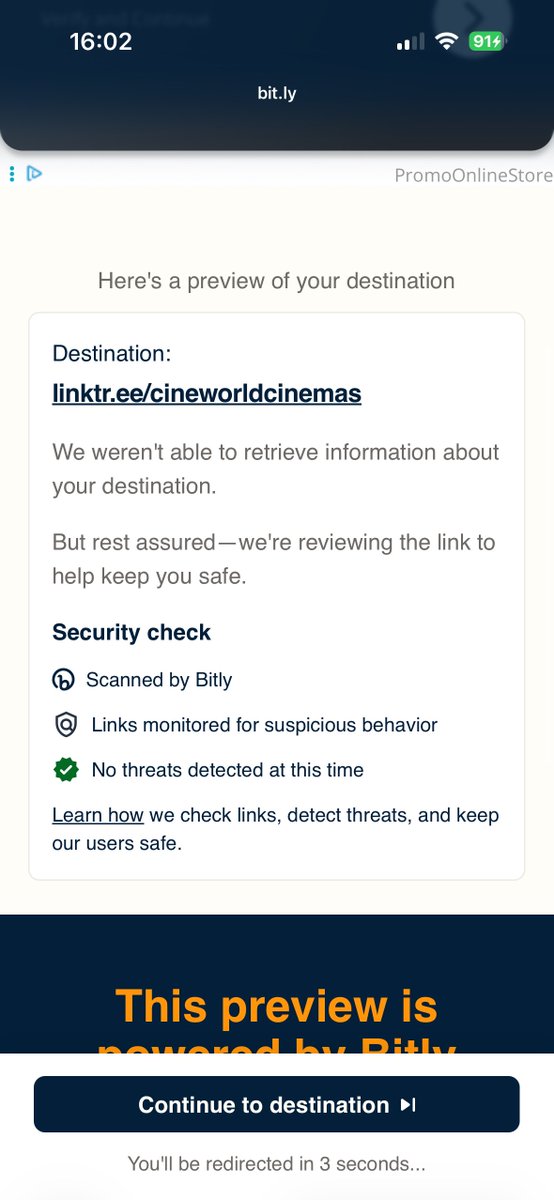
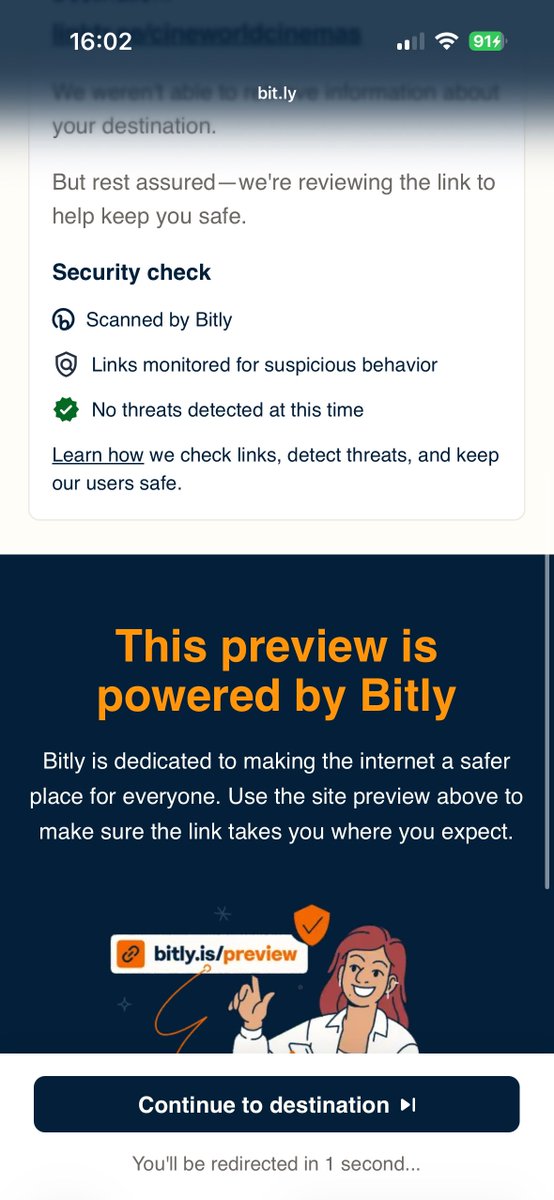
This is really bad @Bitly. A targeted scam ad hosted on your security check redirect page.
The new bit•ly redirect interstitial is ostensibly about keeping users safe with site scanning and transparency.
You ask the user to "use the site preview above to make sure the link takes you where you expect", but there's a big scammy ad taking up the most of the page at the top, asking the user to "click to verify", which will mislead a good many people. The bad actor has crafted this ad placement especially for Bitly, to fool as many as they can to inadvertently click through. It's also not obvious it's an ad; there is no labelling.
The "security check" interstitial achieves the exact opposite and makes users less safe. It reminds me of the days of popup spam, and deceptive and intrusive advertising which plagued major sites in the 2000s and 2010s.
People will be defrauded with these ads. Ideally, you wouldn't run ads, but you certainly mustn't host bad ads, placing all the safety responsibility with the end user. Don't rely on Google or the ad network; approve all ads you're hosting on security-critical pages like this.


2
2
12
761
Epi Security retweeted
Jan 4
Big news: Apple just quietly published (1 Jan) a webpage describing the training data used for their gen AI
This legal document is for compliance with the California Generative Artificial Intelligence Training Data Transparency Act.
🍿 Fascinating insights. Highlights:
"Apple trains generative AI models using a mixture of data that includes publicly available data, including publicly available information crawled by Apple’s web crawler Applebot, data licensed or purchased from third parties, open-sourced data, data obtained through user studies, and synthetic data."
"Applebot does not crawl data from websites that require login credentials or that are protected by a paywall. Applebot respects standard robots.txt directives"
"Data sets for model training include both data from the public domain and data subject to intellectual property rights. For example, data used to train generative AI models includes data that has been directly licensed to Apple and data made available pursuant to licenses, such as common open-source licenses, that permit use of the data in the development of generative AI systems."
"Apple does not use our users’ private personal data or user interactions when training our foundation models. Additionally, for content publicly available on the internet that has been crawled by Applebot, Apple takes steps to apply filters to remove certain categories of personally identifiable information, such as social security and credit card numbers, from training data."
"Apple filters web-crawled data and publicly available datasets both at the time the data is crawled or imported and also as a part of post-acquisition processing prior to training. The data is managed both to limit the use of low-quality data and to remove content that is undesirable or unsafe. For example, Apple performs quality filtering and plain-text extraction on data crawled by Applebot, including safety, profanity, inappropriate content, spam, financial data, and quality filtering using heuristics and model-based classifiers, global fuzzy de-duplication using locality-sensitive n-gram hashing, decontamination against common pre-training benchmarks, and filtering against benchmark datasets. Different techniques are used to filter datasets, including manual and algorithmic ranking of content, use of heuristics, and use of machine learning models."
"Apple has been collecting textual data for training since 2018 and image data for training since 2020. Data collection remains ongoing."
"Apple uses generated text, images, audio, and other content to supplement datasets containing real-world data. This category of data is used to enhance the other corpora, including synthetic image caption data, question-answer pairs, and language data. Apple also uses synthetic data generation for post-training, including supervised fine-tuning."
I wonder what happens with respect to the Google-trained Apple LLM model.
This document was discovered by Epi Internet Intelligence (@epiapp).
2
3
10
657
Epi Security retweeted
20 Dec 2025
Why Trusted Publishing and OIDC is dangerous for CI, your deployments and source code, and GitHub overall.
My recommendation to machine-to-machine OIDC flow developers: always require a secret to be supplied as well.
20 Dec 2025
please don't just do pure OIDC for machine-to-machine auth, which is what we're seeing as all the rage for Trusted Publishing. Combine OIDC with a token. It's cryptographic assurance, not just a trust relationship. Trust relationships are finicky and difficult to get right for 1p and 3p devs. The auth relies on devs setting their 2-way trust relationship config correctly, and devs/users need to have faith in both the relying party and identity provider always adhering to the protocol and using all bits of the auth and policies.
It's the same deal when devs connect GitHub Actions to AWS or some platform for CI. Devs are strongly encouraged to establish OIDC trust relationships with third parties, but the advice comes with prominent beartrap warnings for devs to set up the config correctly on both sides. This is due to the risk of another party on one of the platforms silently gaining access to your code/data/deployments/secrets, which is as easy as neglecting to specify your org and repo name, so it authorises for any org and any repo. It's such a bad default case and failover scenario. A poor config should be rejected, not transparently accepted.
I get that dev tokens and secrets can't be leaked with Trusted Publishing (OIDC) which is a good thing, but m2m OIDC flows should require a token to be supplied too, so it's not a catastrophic failure when CF verifies it is talking to Okta but fails to verify which Okta customer due to a bug. The failure mode is disastrous.
Trusted Publishing and m2m auth flows need to be more secure.
I've spent a lot of time researching OAuth and OIDC flows, discovering their vulnerabilities.
5
12
1,985
Epi Security retweeted
15 Dec 2025
Here to help devs with reviews, audits and pentests for RSC, servers and client apps.
In the wake of the significant and widespread attacks on NPM libraries and React2Shell exploits, security must no longer be an afterthought or bolt-on.
I've been building secure apps and servers for 15 years, and running a cybersec startup for 6 years. Security works when it is at the foundation, with secure code practices followed religiously by devs, and platform safeguards built in.
Reach out if you want me to look at your source and apps.
Happy to take a deep dive into your repos, and if you like my work, establish a working relationship.
15 Dec 2025

We’re seeing up to 14.5 million attempts per hour to exploit the #React2Shell vulnerability across @Cloudflare’s network. This is a very bad exploit. While our WAF is helping protect customers, it’s critical to update your React and Next.js instances as soon as possible.

5
18
9,501
Epi Security retweeted
25 Nov 2025
Shai-Hulud Wave 2 Breaking: just updated our check tool, adding 190 new compromised npm deps since yesterday, including libs from Browserbase and Oku UI.
Go get checked:
gist.github.com/alexgreenlan…
24 Nov 2025
Shai-Hulud strikes again with Wave 2. Check your exposure to today's NPM cyberattack with an automated scan. We updated our detection script to scan repos and environments for today's compromise of 500 NPM packages, including libraries from Zapier, Posthog and Postman.
This is the second major wave after the first wave in September. Shai-Hulud Wave 2 compromises your GitHub Actions CI workflows and captures all environment secrets, stealing AWS keys, NPM tokens and GitHub tokens. See if you're affected — run this DFIR script on dev machines, CI and deployed environments.
It deeply checks nested dependencies against known compromised packages for a bunch of repos in one go. It looks at libraries that are installed, needed by package.json and captured in the package lock.
Looking ahead, I would strongly recommend turning off NPM install scripts, using CODEOWNERS for GitHub Actions with PR approvals, pinning dependencies, and making use of a good local firewall like Little Snitch.
gist.github.com/alexgreenlan…
5
5
11
2,861
Epi Security retweeted
24 Nov 2025
Shai-Hulud strikes again with Wave 2. Check your exposure to today's NPM cyberattack with an automated scan. We updated our detection script to scan repos and environments for today's compromise of 500 NPM packages, including libraries from Zapier, Posthog and Postman.
This is the second major wave after the first wave in September. Shai-Hulud Wave 2 compromises your GitHub Actions CI workflows and captures all environment secrets, stealing AWS keys, NPM tokens and GitHub tokens. See if you're affected — run this DFIR script on dev machines, CI and deployed environments.
It deeply checks nested dependencies against known compromised packages for a bunch of repos in one go. It looks at libraries that are installed, needed by package.json and captured in the package lock.
Looking ahead, I would strongly recommend turning off NPM install scripts, using CODEOWNERS for GitHub Actions with PR approvals, pinning dependencies, and making use of a good local firewall like Little Snitch.
gist.github.com/alexgreenlan…
19 Sep 2025
Dan and I at Epi made a script to scan our repos for exposure to this week's compromise of 400 NPM packages (Shai-Hulud).
Sharing the script here so you can see if you're affected. Run this on dev machines, CI and deployed environments.
It deeply checks nested dependencies against known compromised packages for a bunch of repos in one go. It looks at libraries that are installed, needed by package.json and captured in the package lock.
Looking ahead, I would strongly recommend turning off NPM post-install scripts and making use of a good local firewall like Little Snitch.
Script link below.

10
11
77
52,478