
Tech, AI, & Brypto
Joined June 2009
- Tweets 74,395
- Following 2,231
- Followers 2,591
- Likes 279,230
800 Photos and videos








Der.dev 🔥🛠️ retweeted

TLDR: I’m looking for my next role. Who’s hiring?
hey folks, over the last 100 days i’ve had the privilege to do some talks around the world about where AI is perhaps going and already is which has been well received. it has provided a much needed break to reflect and ponder.
for those new to my feed, some quick intros.
for the last two years i’ve been dumping my ponderoos on my personal blog at ghuntley.com/, thinking about the domain of loop engineering with AI and verification topics to make this possible.
if you use any of the coding harnesses out there today, you are using some of my research related to context engineering and long term horizon goals. if you heard about ralph loops and agentic back pressure and wondered where the term came from hi 🫡
Anyway to cut the point of this article — i’m looking for my next role. i’ve been pondering about some of the ideas behind latentpatterns.com and whilst it’s nice to have the optionality to raise a round i consider now is not the right time to do it or explore these ideas for a couple years.
i’m based in Australia, Sydney specifically. Happy to travel as needed but remaining in Australia is a hard requirement (family that cannot relocate) so remote is preferred if not based in Sydney.
things that are interesting to me:
- applied AI research in the domain of software verification
- ai first organisation with minimal caps on token consumption
- software factories, formal verification and plt
- “the ai operating systems” (org chart transformations enabled through AI product)
- physical infrastructure
- teaching and knowledge sharing
about me:
- accomplished keynote/locknote speaker
- industry level influence and impact in AI
- previous roles include canva, optiver et al
- titles held: big iron (unix) field engineer, presales, business continuity planning, software engineering manager, principal software engineer, principal developer advocate.
- cycled through six countries on a unicycle, travelled around australia for five years remote working from a van and stole all the NFTs.
salary requirements:
- sf competitive (ie. my last role was AI within HFT)
how to contact me: ghuntley hiring@ghuntley.com
reshares/retweets appriciated.
7
15
81
4,550
Der.dev 🔥🛠️ retweeted

I think it’s time to revisit the accredited investor laws in the US.
Companies are staying private longer, where only accredited investors (aka rich people!) can invest. Retail investors can only come in after IPO, when much of the upside has already been captured.
These rules were created with the best of intentions, to protect regular people from scams - a noble idea. Unfortunately, in practice they've often made it illegal to get richer, unless you're already rich. A regressive tax!
We have to judge policies based on their outcomes, not on their intentions.
These are two possible routes I see:
1) Replace the rule with something merit-based, like a financial literacy test. Pass it and you're accredited. Having a qualification based on competency rather than your bank balance or income seems far more fair.
2) Remove the rule entirely. Let consenting adults assess their own risk. Disclosure requirements stay and fraud enforcement stays to punish bad actors.
447
503
4,651
403,095
Der.dev 🔥🛠️ retweeted
Coders might be going away, but high-agency, high-ownership engineers are more important than ever.
Factory is full of engineers of this new sort. A few that are active on here and worth following:
1. @agent_wrap
2. @luke_alvoeiro
2. @ross_cefalu

"The best engineers in an AI world won't just ship features, they'll own outcomes.
They'll understand customers, influence product adoption, and work across engineering, sales, marketing, and enablement to drive results.
The engineers who thrive will be the ones who think like founders, not just builders." @matanSF
Do you agree and does no one see that everyone should about what it will take to be a top engineer in 5 years @lennysan @sjwhitmore @jasonyuan @zan2434 @rsms
9
3
79
7,424
Der.dev 🔥🛠️ retweeted

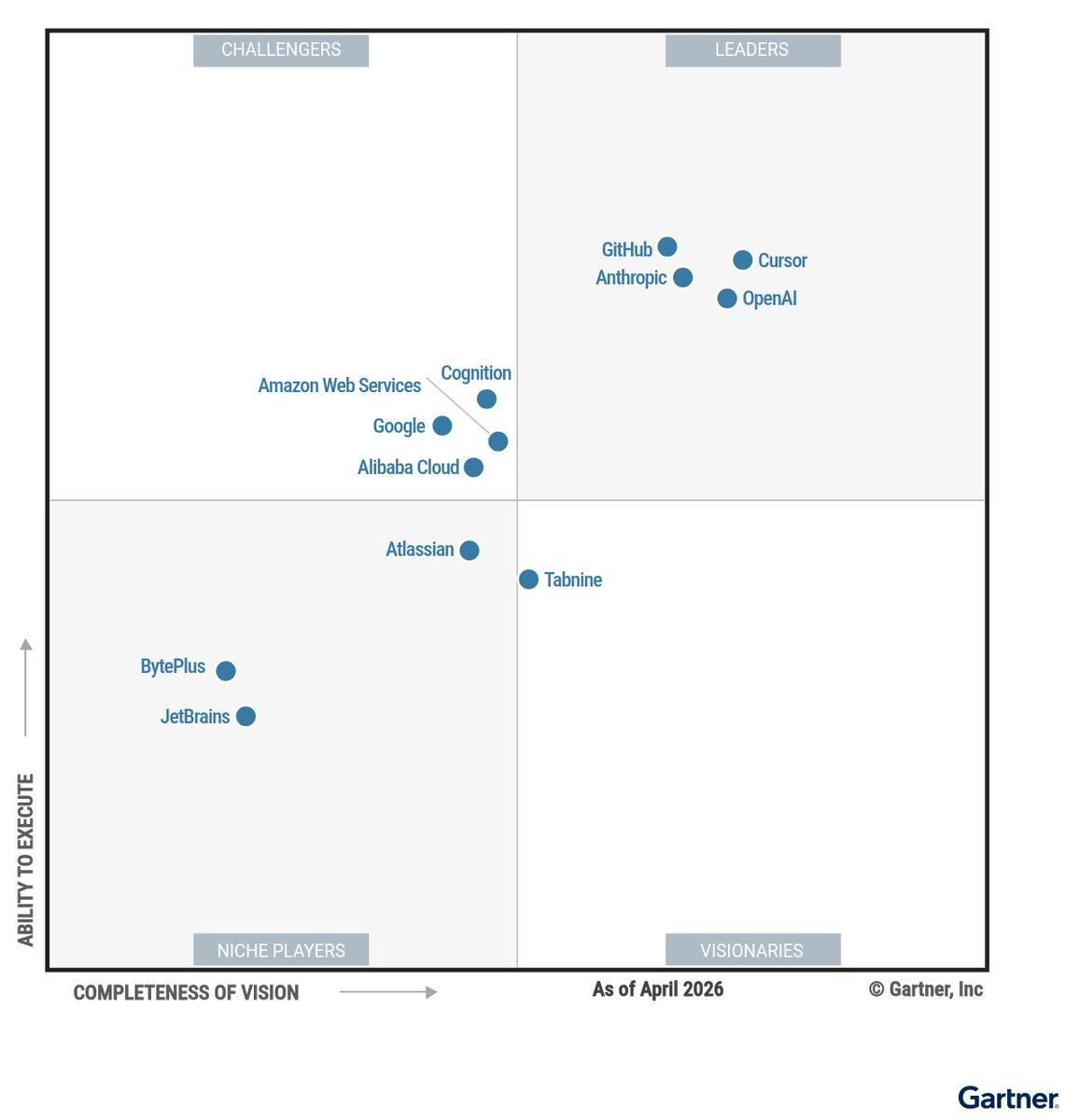
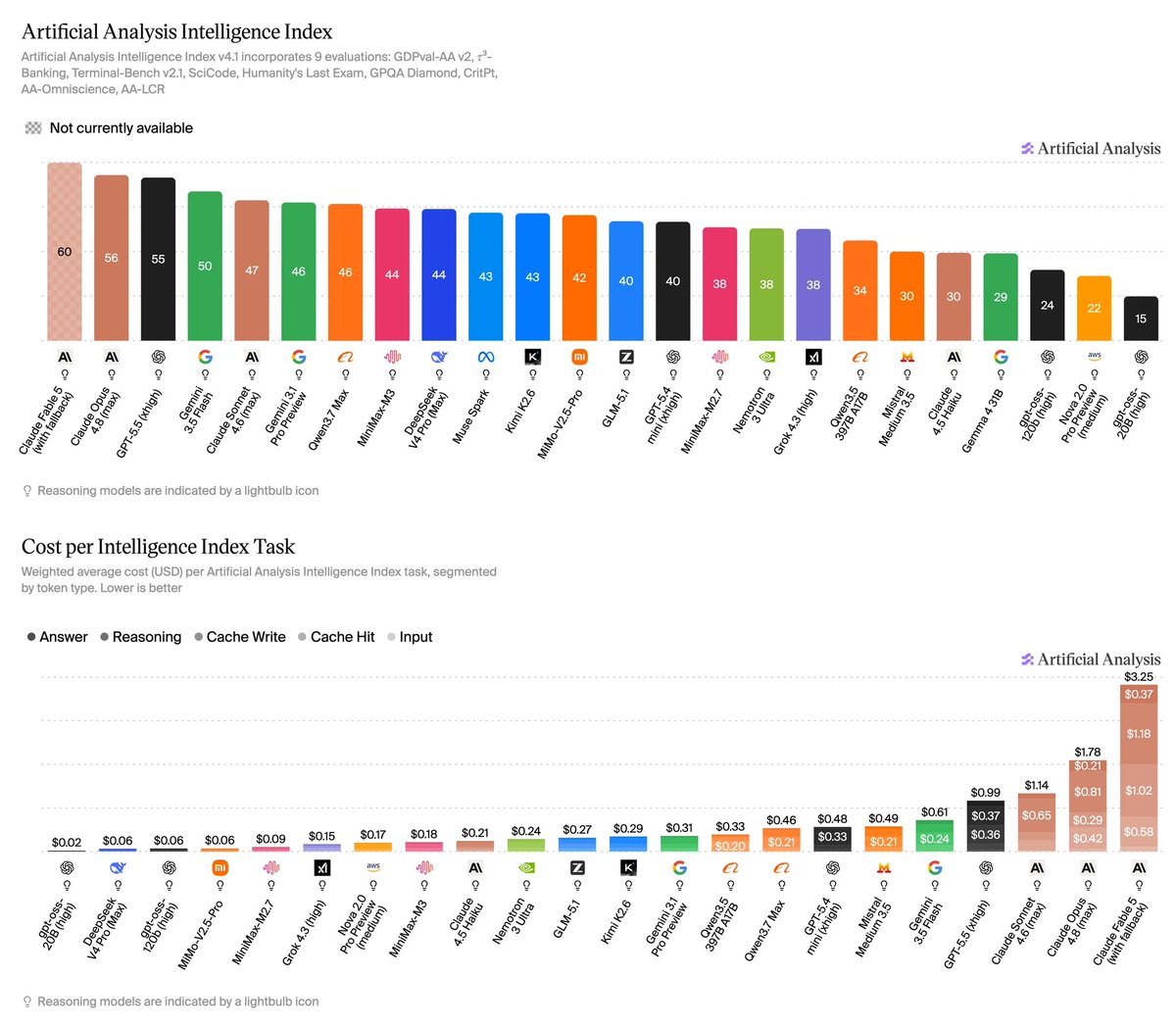
Announcing Artificial Analysis Intelligence Index v4.1: a shift toward agentic workloads, featuring upgraded benchmarks and new per-task metrics
The Artificial Analysis Intelligence Index is our synthesis metric for assessing model intelligence and tracking AI progress. v4.1 marks a broader shift toward agentic workloads, with three main changes:
Updated and reweighted evaluations toward agentic tasks:
1. We upgraded three evaluations, removed one, and reweighted the Intelligence Index:
➤ Upgraded Terminal-Bench Hard to Terminal-Bench 2.1 and τ²-Bench Telecom to τ³-Bench Banking. Both move to newer, more robust task sets with harder, more realistic agentic scenarios that better separate frontier models
➤ Upgraded GDPval-AA to GDPval-AA v2. The upgrade re-baselines Elo to human performance at 1000, introduces a rotating panel of frontier-model judges, and raises the turn limit from 100 to 250 for longer-horizon agent trajectories
➤ Removed IFBench due to saturation. The benchmark no longer distinguishes frontier models sufficiently, so we have removed it from the Intelligence Index. We will continue to run it and publish results on new model releases
2. Cost per Task, Time per Task, and Tokens per Task:
Three new per-task metrics, reported for every model and based on the Intelligence Index. We take the total cost, total time, and total output tokens for a model to run the Intelligence Index and divide by the number of tasks across its evaluations, giving the average cost, time, and output tokens to complete a single Intelligence Index task
3. Cached input token reporting:
We now report cached input tokens and their impact on cost, including the cost to run the Intelligence Index, to better reflect the real cost of running each model
Key Results:
➤ Leading models: Claude Fable 5 (with Opus 4.8 fallback, 60) leads the Artificial Analysis Intelligence Index v4.1 by four points but is currently unavailable, leaving Claude Opus 4.8 (max, 56) as the most intelligent available model, ahead of GPT-5.5 (xhigh, 55) ➤ Open weights leading models: Among open weights models, DeepSeek V4 Pro (max, 44) and MiniMax M3 (44) lead, followed by Kimi K2.6 (43) and MiMo-V2.5-Pro (42)
➤Cost per Task: Claude Opus 4.8 (max) is the most expensive available model at $1.78 per task, with Claude Fable 5 the highest overall at $3.25. GPT-5.5 (xhigh) scores within a point of Opus 4.8 on the Intelligence Index at $0.99 per task. DeepSeek V4 Pro (max) stands out on the Intelligence vs Cost per Task chart at $0.04 per task, with other leading proprietary models costing 20x to 45x more
➤Time per Task: time per task (inference decode time) ranges from 1.5 minutes for Grok 4.3 (high) to 13.5 for Claude Sonnet 4.6 (max), a roughly 9x spread. Claude Opus 4.8 (max) completes a task in 6.4 minutes and GPT-5.5 (xhigh) in 3.7, while Gemini 3.1 Pro Preview stands out on the Intelligence vs Time per Task chart at 1.6 minutes for a score of 46
47
59
635
85,533
Der.dev 🔥🛠️ retweeted

Using Opus now is just disgusting. The sycophancy is extremely transparent and revolting...it doesn't complete tasks...it doesn't think things through.
I don't want to be a conspiracy theorist but I am finding it hard to believe that this perceived degradation is coming from the Fable reference point alone.
I am really wondering if Anthropic is doing some kind of funny business here to make us think Fable was that much better to cultivate a groundswell of support for its return.
Is that even feasible from a technical standpoint? Would they have the ability to "retune" a model on the fly like that? Maybe its a natural re-alloation of thinking budget that they set up to roll out with the release of Fable but just left in place after it was removed?
There has to be some explanation for this beyond just "Fable was so good it now makes Opus look horrendous."
100
15
259
55,238
Der.dev 🔥🛠️ retweeted

"If you don't look at the code you are not a serious developer"
1
1
4
519
Der.dev 🔥🛠️ retweeted

7h
louder
Jun 12

people who dont read the code are not serious people
and it takes a serious person to ship production software
3
2
38
3,864

We've been building towards this for ~3 years. It started with the agent, then we needed the surfaces. After that, automations and infrastructure to run Droid anywhere.
Now we're centralizing this into one place where you can manage and evolve your sovereign software factory.
11h

Today, we're announcing Factory 2.0: from coding agents to software factories.
9
8
93
8,153
Der.dev 🔥🛠️ retweeted

Senior Anthropic officials are meeting with senior Trump administration officials this morning in an attempt to resolve the Mythos/Fable embargo. There were also meetings yesterday after Anthropic officials flew to Washington. It's possible we get some resolution later today.

31
20
411
40,893

15h
User error. I asked Codex CLI to clean up and everything is working now.
Jun 15

Last Codex App update seems to have things sluggish again
69


As the AI narrative floats back down to earth, credibility will flow to people who talk in worldly terms about the concrete benefits, not some self-serving quasi-spiritual gobbledygook.
Also, we'll need to craft human-centered systems to harness the full potential of LLMs.
3
1
22
1,828
1. Core hypothesis of models generalizing well means this should get better over time. Also as data distributions converge across providers model behaviors on most economically useful tasks should as well
2. The business model is selling tokens, at scale goodwill heart can't beat incentive structures and economics
3. Empirically unclear / untrue. Lots of strategies to get better token efficiency any harness can access a model's optimal tool calling strategy
1
2
22
1,602
One of the more frequent misunderstandings I see is the belief that the model informs the harness, and that this means model labs have an inherent advantage because they can design their harness around model improvements before anyone else can.
This mistake often comes because in a given model iteration, many tasks improve on internal evals with a co-developed model and harness. It looks like the model drove the improvement. But the causality runs the other direction.
The harness informs the model. As task complexity increases, you need to develop specific strategies, workflows, and capabilities to solve increasingly difficult tasks. These get built into the harness. Then the harness traces get introduced into the model's post-training pipeline. The model learns the workflow and behavior, and gets better at completing the task directly.
This means great harnesses set the direction of models. At the limit, great harness traces will get injected into every model, either directly or indirectly, because post-training datasets converge. On top of that, once a model gets good at one specific strategy, a good self-improving harness can discover this and implement it for that given model, closing the loop further.
Ultimately this means model labs have no meaningful advantage in building harnesses other than a talented team of smart people and lots of money. Both of those are real, but they are very different from a durable advantage or moat.
13
6
115
7,878
Der.dev 🔥🛠️ retweeted

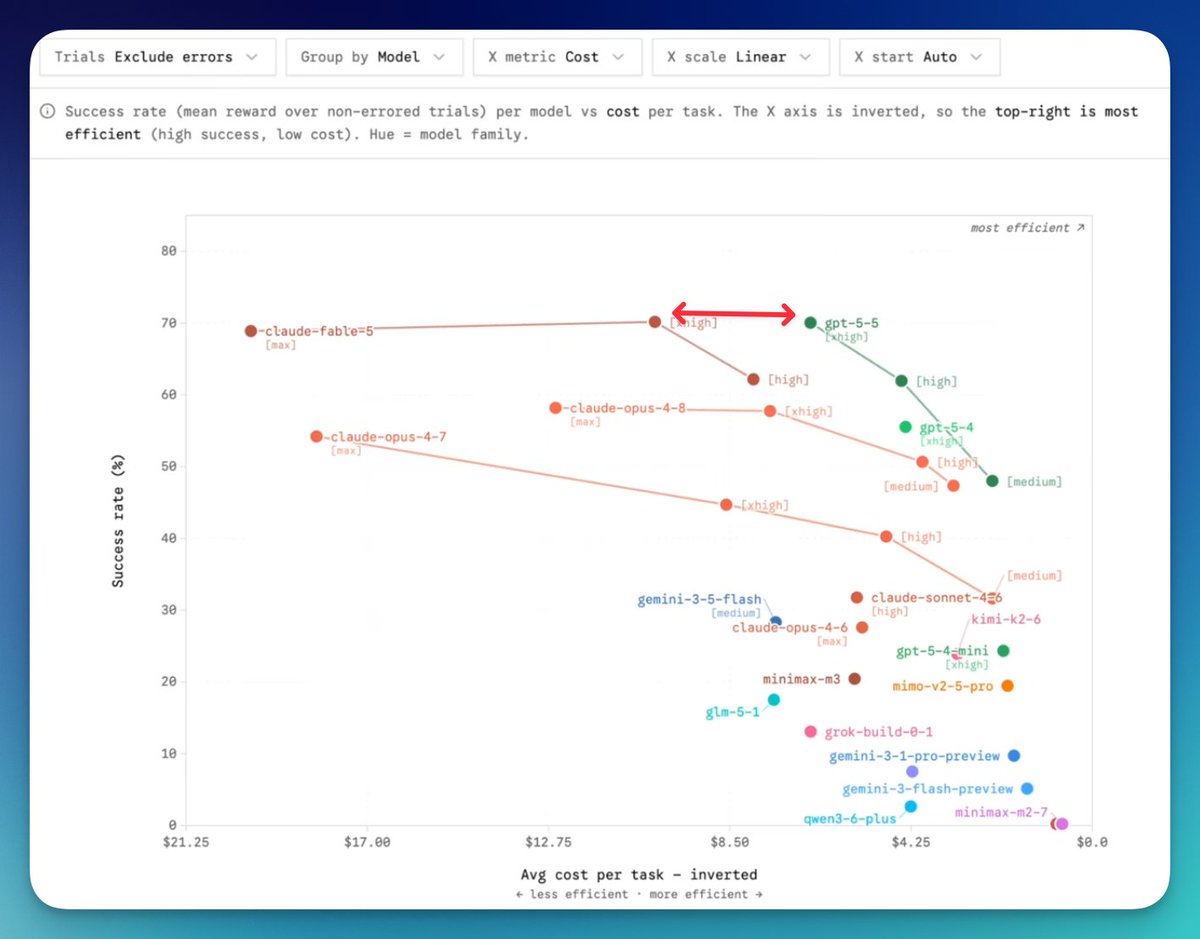
1. This is why @thsottiaux and @OpenAI are feeling good about GPT-5.6 (screenshot is from @datacurve's latest DeepSWE from @theo's video)
2. Most other SWE benchmarks are out the window. Anthropic admitted claude cheat(s) on swe-bench pro. I think DeepSWE might be one of the 5 most important AI benchmarks out right now.
3. GPT-5.5 was released a month before Opus 4.8, and it is still outpunching Anthropic's newest Fable 5.
4. In other words, Anthropic, the company known for their coding models, have had TWO additional shots at creating a coding model that competes with GPT-5.5 on a cost-per-intelligence basis and have failed.
5. A little secret most benchmark watchers overlook? GPT-5.5 xhigh is not even close to being OpenAI's best model. That belongs to GPT-5.5 Pro, which rarely gets benchmarked.
6. This will be very bad for Anthropic when/if Tech Twitter, the mainstream media and Wall Street start connecting the dots.
7. Seems like all the IPO doomsday marketing hype from Anthropic couldn't actually make their models better or more efficient.
8. The above is why Anthropic is now going on a PR tour with national news companies, as they see the writing on the wall: OpenAI's models are better at what matters and its Codex harness is better.
9. Anthropic's best shot at out IPO-ing OpenAI is only:
A) controlling the public narrative via press tours
B) confusing enterprise customers (agentic models running broken loops, tokenmaxxing and companies are none the wiser)
C) Copying Codex verbatim like Google tried to with Antigravity, b/c Anthropic's Caude desktop offering is a disjointed, siloed mess without unified memory.
Jun 10

Feeling pretty good about things
14
34
300
64,198
Der.dev 🔥🛠️ retweeted

Jun 14
Codex mobile is very good and I’m using it to great effect. My biggest feedback is that the code review needs a lot of improvement! Concretely, would love a more convenient way to browse by file and see review full screen
7
2
102
10,112
Der.dev 🔥🛠️ retweeted

Jun 14
If you need FDEs to make your product work, you have a shit product
Jun 14
"Everyone gets FDEs wrong.
The job of an FDE isn't to make the product work, it's to accelerate customer adoption and time-to-value.
If you need FDEs just to deliver the product, you're not running a software company, you're running a services business with a bad product." @matanSF
Do you agree and what do people misunderstand most about what it takes to do FDE motion well? @ssankar @chadwahl @nikogrupen @barrald @lkothari @LeoMehr @zkevinbai
26
21
250
82,139