
Soul of an artist in the mind of a scientist | “... specialization is for insects.”
Joined October 2008
- Tweets 3,735
- Following 2,656
- Followers 502
- Likes 33,676
41 Photos and videos






Pinned Tweet

7 Feb 2025
1/ Let's unwrap why the notion of such an evaluation benchmark for AI models is irredeemably flawed, and how it promotes cargo cult mania...
23 Jan 2025

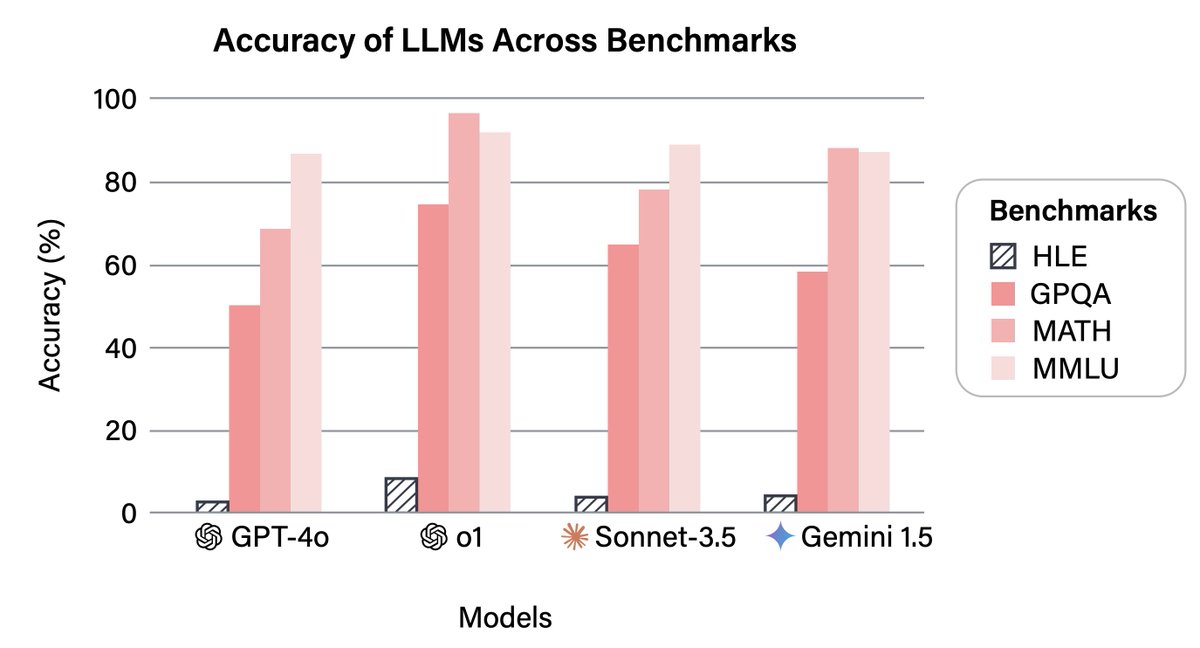
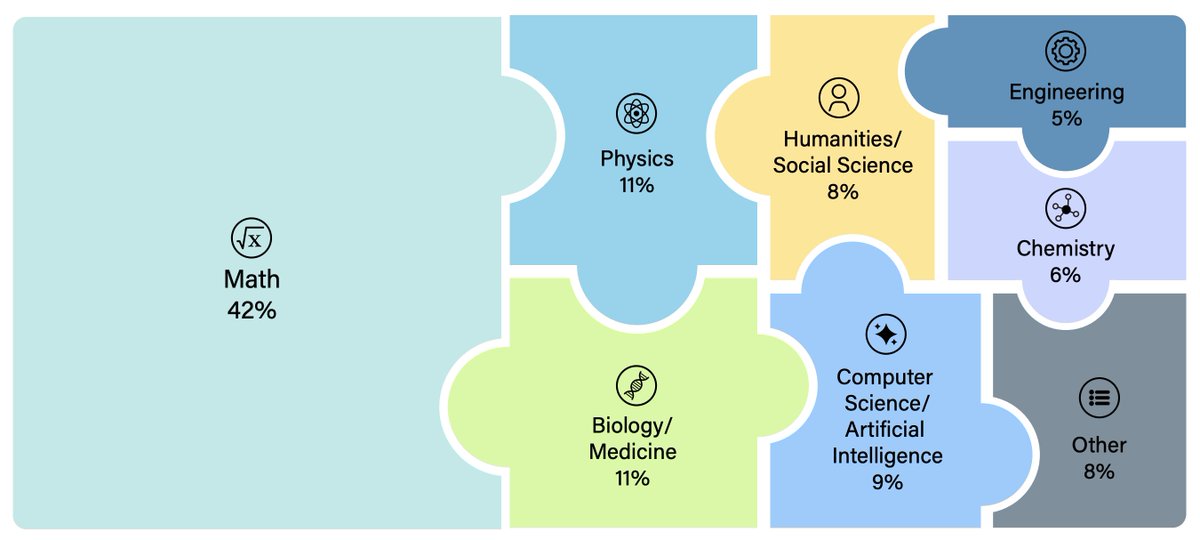
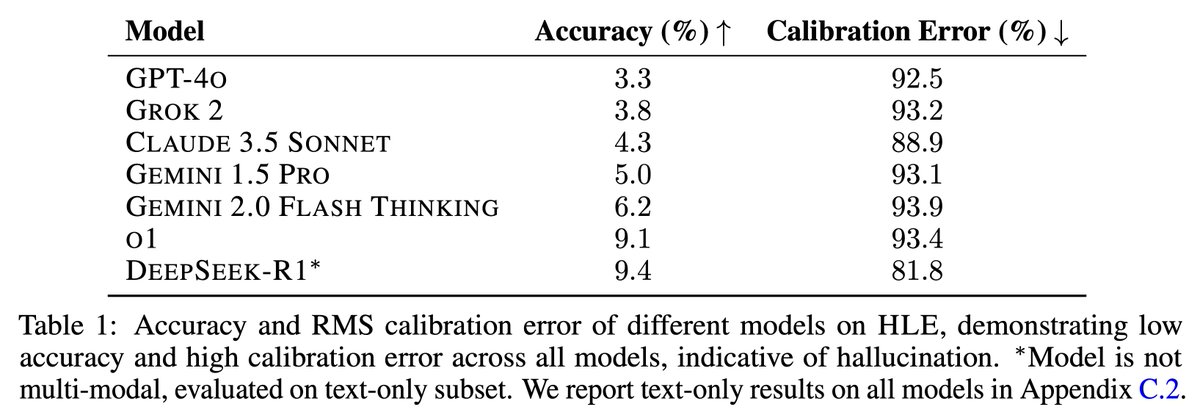
We’re releasing Humanity’s Last Exam, a dataset with 3,000 questions developed with hundreds of subject matter experts to capture the human frontier of knowledge and reasoning.
State-of-the-art AIs get <10% accuracy and are highly overconfident.
@ai_risk @scaleai

7
6
43
14,829
Eh. Half the things are true, but his fundamental premises about the world are arguably wrong. 2026 is not 1996 or even 2016!
If someone could not forecast a frontier model export control ban among the range of credible possibilities, their inputs are strategically dangerous.

51
RT @prasannavishy: “I have never seen anyone move at this pace, let alone the government. I’m flabbergasted, honestly,” said the founder of…
126
Jun 15
Congrats to Sarvam on the raise. Excited to see @hcltech invest in a forward-thinking manner 🚀🚀

We're thrilled to announce that we have raised $234M in the first close of our $300M Series B at a $1.5B valuation.
@HCLTech and @BessemerVP have joined us in this round, alongside continued support from @khoslaventures and @peakxvpartners
For countries and companies, sovereign control on the AI stack is no longer an optionality. Sarvam will be the partner of choice for this aspiration. The capital allows us to accelerate our momentum towards this full stack of models, compute, and deployments.
A huge thank you to our customers, partners, investors, and the Sarvam team for your trust and belief in what we are building. We’re just getting started.
Read more: sarvam.ai/announcing-series-…

2
58
Jun 15
Amadahl's law for human progress? 🤔
Jun 15

Important post for metascience from @jddwor. He runs a simulation where AI accelerates some but not all fields, and progress requires combining discoveries across fields. He finds shifting resources into AI accelerated fields slows long-run progress. open.substack.com/pub/abunda…
1
1
955
Jun 15
Pushing inference frontier (infra/algos) is just as imp as training best models. Any cracked BLR folks doing this?
DeepSeek might not match Claude on benchmarks, but wins handily on intel per unit cost. Like any engg that's where the future lies. Esp if you believe in scaling.
56
Jun 15
This post is about so much more than "hacking"
"be curious lol" 🌟

everyone wants a hacking roadmap.
the problem is that roadmaps don't create hackers.
curiosity does.
ctfs are changing, ai is everywhere, and the game looks very different now.
how i'd start hacking in 2026: ni5arga.com/blog/posts/so-yo…
60
Siva retweeted

Jun 13
If you’re a software engineer worried about AI eating your job, become the person who can deploy, customize, evaluate, and operate *****open-source models***** inside companies. Organizations are finally optimizing for AI cost, privacy, and control and many will want this capability in-house.
43
62
859
53,759
Siva retweeted

Jun 13
EVERYTHING IS BOM

16 Sep 2023

Open Source Manufacturing.
Design global. Manufacture local.
Starts with an open source BOM directory.
33
121
1,854
81,136
Jun 14
$250M is easy if Indian IT industry dared to come together and pitch in to de-risk an existential crisis. Infosys alone bought back shares worth ~$200M in Nov 2025.
Why are Indian model makers having to pitch global VCs? The market is in India, and the capital is too!
Jun 13

To train a GPT class 1T model from scratch - including failed runs, data acq clean rlhf, post-training, team/people will likely req $250M of compute on an aggressive 3-4mo schedule (i.e. more reserved GPUs), $500-600M all-in IF you do a dense one. MoE fp8 will cut costs by 1/10th depending on how many active params you have. If you want SOTA however, the budgets go significantly higher on test-time compute, post-training RL, and data/synthetic generations..and v. high on talent. Maybe $2-4B all-in. After that comes serving the model. The talent is key to get to SOTA/beat it - and then you have to ensure this is useful enough to have inference vol over time - for which the capital will come if there is usage / TAM. So this is not as much about raising $50-60B, or raising it all at once as the OP says - we are investors in mistral, sarvam, reflection and anthropic - and they all scaled capital over time as models got adoption, but the early bottleneck is more on talent GPUs at that scale where you can do interesting things.
1
1
115
Jun 14
It's important that the conversation be driven by *those who know how to do* rather than those who fear that everything is too hard and so oscillate between outrage & passivity.
Jun 13

the FUD on training economics in India is borderline harmful
You don’t need multi billion clusters..
american open source leader has trained their 400B model by raising ~$50M (they have since then raised a bigger round)
we should celebrate competence not jingoism

2
72
Siva retweeted

Jun 13
the FUD on training economics in India is borderline harmful
You don’t need multi billion clusters..
american open source leader has trained their 400B model by raising ~$50M (they have since then raised a bigger round)
we should celebrate competence not jingoism
Apr 1

Today we drop Trinity-Large-Thinking.
SOTA on Tau2-Airline, frontier-class on Tau2-Telecom, and the #2 model on PinchBench, right behind Opus. On BCFLv4, we're in the mix with the best.
26 people with under $50M raised and a ruthless pursuit of greatness.
What this team just pulled off is nothing short of incredible. One hell of an accomplishment and I couldn't be more proud of Arcee.
And we've got more to prove.
5
10
75
5,182
Jun 13
Why haven't Indian IT companies come together to create a consortium to invest in Indian coding AI models? Can do a great job here just by fine-tuning open weights models. Needs only a few million USD.
Infosys spent 18,000 crore on stock buyback in Nov 2025
Jun 13

PM @narendramodi Sir we need an India AI Mission under you with @NandanNilekani as vice chair and others from the private sector and govt. to Help India tackle the AI Revolution. We are way behind and need a national mission to get going quickly. Existing govt programs are too slow, way too small to make any large impact. We need an annual 50000 cr fund for deep tech and AI, a 200,000 cr ELGS Guarantee Fund to build Hyper cloud, hardware and chips. @AshwiniVaishnaw @nsitharaman @PiyushGoyal @FinMinIndia @RBI We need a Very Large National Mission. @AmitShah @amitmalviya
80
Jun 13
RT @HarveenChadha: 2 labs are not enough for a country like India, we need more labs, more gpus, more research/infra engineers, more collab…
146
Jun 13
RT @HarveenChadha: I wish I could do a podcast with people who were against building frontier models on why they didn't foresee this coming…
236
Jun 13
Chips are not inf replicable bits. Multi-yr backlog of GPU orders; industry can't make enough
It's not about having money to pay for chips; it's about owning productive capacity (having invested in infra several years before you needed chips)
Just a childish tantrum otherwise
Jun 13

Today, I am not gonna sleep peacefully.
The gap between two civilisations will accelerate to unimaginable levels if one has access to super intelligence and the other doesn’t.
As a nation, why can’t we buy 200,000 chips like tomorrow and start training.
1
88
Jun 13
Suppose you got chips. Then you need data centers. Then energy. Then AI talent to build sw infra to train models. Then huge quantities of highly curated data.
Years of focused deep tech building; not just "app layer" and quick returns... and throwing a hissy fit one fine day
33
Siva retweeted

Jun 13
As India realizes that we may be cut off from frontier AI, some demand nationalization of AI R&D with the architects of this mess in charge.
Lunacy! We must overcome our technological cowardice via private enterprise with the free market as the judge.
infinitesunrise.com/p/overco…
4
5
55
1,879
Siva retweeted
Apr 29
(circa ~1800) "India doesn't need to lead the world textile industry; it just needs to import cloth from Britain and ensure that the benefits of cheap cloth are widely shared. It's very lucrative to supply raw material (cotton) to the Lancashire mills."
Apr 29

India doesn't need to lead the world in building the most advanced AI models. But it must lead in ensuring benefits of AI are widely shared.
@rvenk and I have an op-ed in The @EconomicTimes
economictimes.indiatimes.com…
1
12
495
Jun 13
One cannot solve a problem with the same level of thinking that created it...
Jun 13
PM @narendramodi Sir we need an India AI Mission under you with @NandanNilekani as vice chair and others from the private sector and govt. to Help India tackle the AI Revolution. We are way behind and need a national mission to get going quickly. Existing govt programs are too slow, way too small to make any large impact. We need an annual 50000 cr fund for deep tech and AI, a 200,000 cr ELGS Guarantee Fund to build Hyper cloud, hardware and chips. @AshwiniVaishnaw @nsitharaman @PiyushGoyal @FinMinIndia @RBI We need a Very Large National Mission. @AmitShah @amitmalviya
6
339
Jun 13
The fate of a community is shaped by the quality of its elites...
Jun 12

Elon Musk in this 2012 interview:
" My proceeds from PayPal after tax were about $180M, $100M of that went into SpaceX, $70M into Tesla, and $10M into SolarCity and I literally had to borrow money for rent."
$SPCX $TSLA
58