
Joined February 2025
- Tweets 8
- Following 68
- Followers 181
- Likes 23
4 Photos and videos


Pinned Tweet

May 17
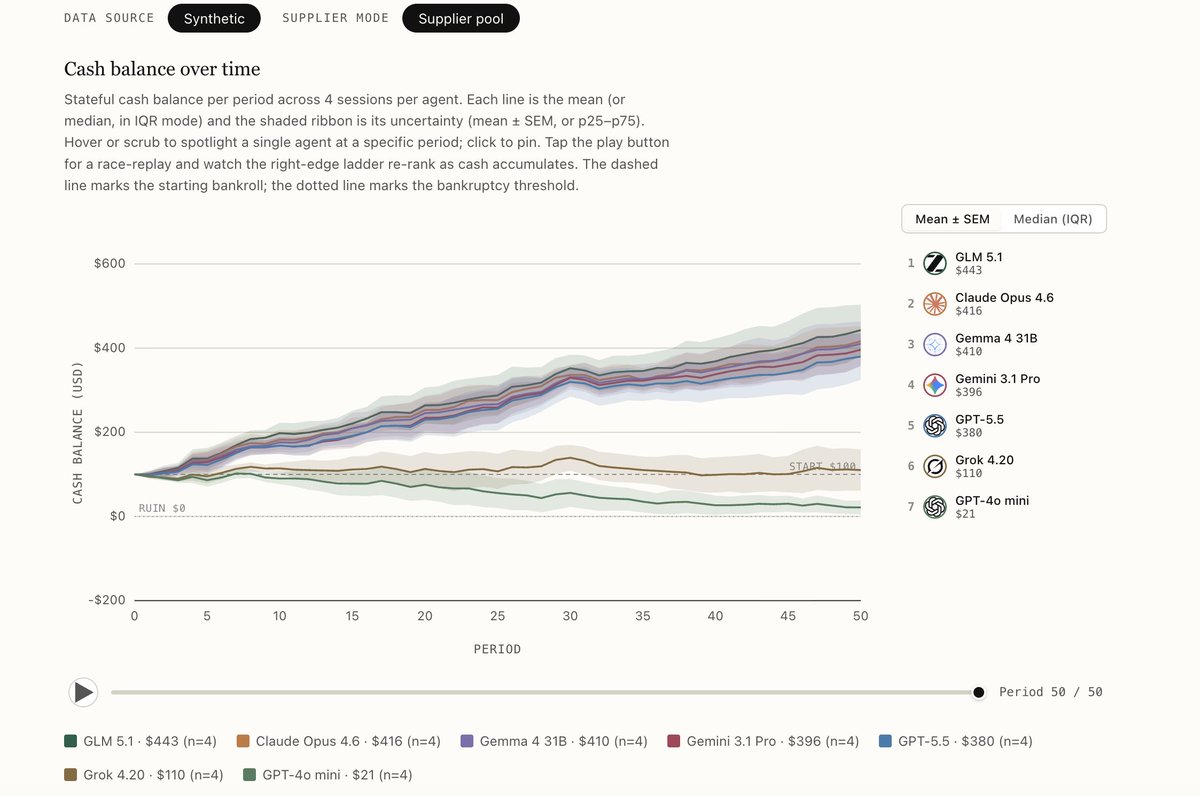
We built TERMS-Bench, a three-tier benchmark for LLM agents in real-world economic negotiation. No LLM-as-judge, no outcome rubrics: the environment itself is the verifier.
🏆Among frontier models, @AnthropicAI Claude Opus 4.6 #1, @Zai_org GLM 5.1 #2.
✨Surprisingly strong: @GoogleDeepMind @googlegemma Gemma 4 31B — best open-weight, holds up as negotiations get harder.
🔗 terms-bench.github.io
22
27
251
53,019
May 29
Very honored to see Gemma @googlegemma feature TERMS-Bench!
We built TERMS-Bench to evaluate LLM negotiation agents in settings where success is not cleanly verifiable by math/code-style checks, but also should not be outsourced to LLM-as-judge. Instead, the economic environment verifies the outcome.
Gemma 4 31B is the top open-weight model on our benchmark, competitive alongside frontier peers. Excited to see open models advancing in these social-strategic, agentic evaluation domains 💛🚀
May 28

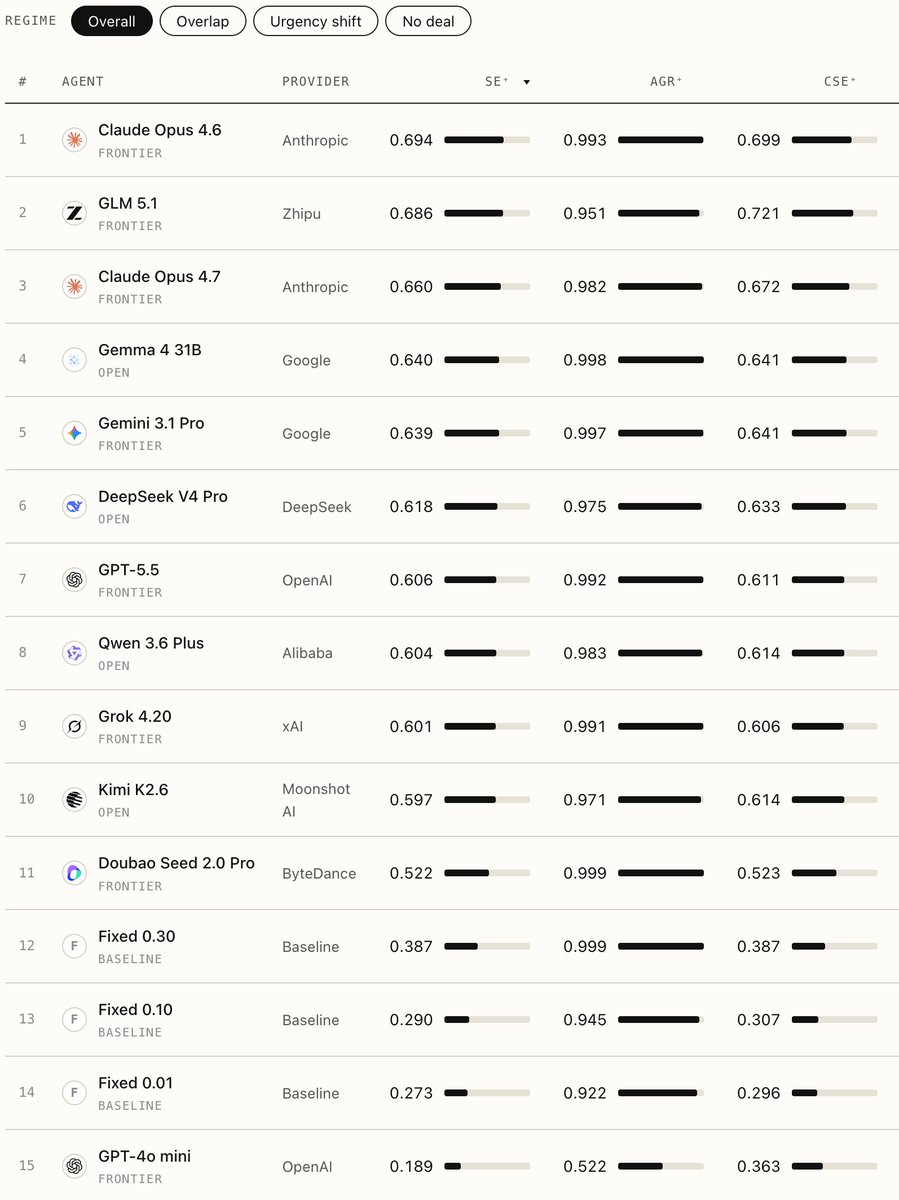
Honored to see Gemma 4 31B on TERMS-Bench, a benchmark for LLM negotiation agents based on economic negotiation! 🤝
- Environment verifies outcomes (no LLM-as-judge)
- Top open-weight model alongside frontier peers
- Allow diagnosing why and where agents fail
ALT An image featuring a leaderboard table ranking 15 AI agents from various providers
2
2
14
3,819
Erica retweeted

May 28
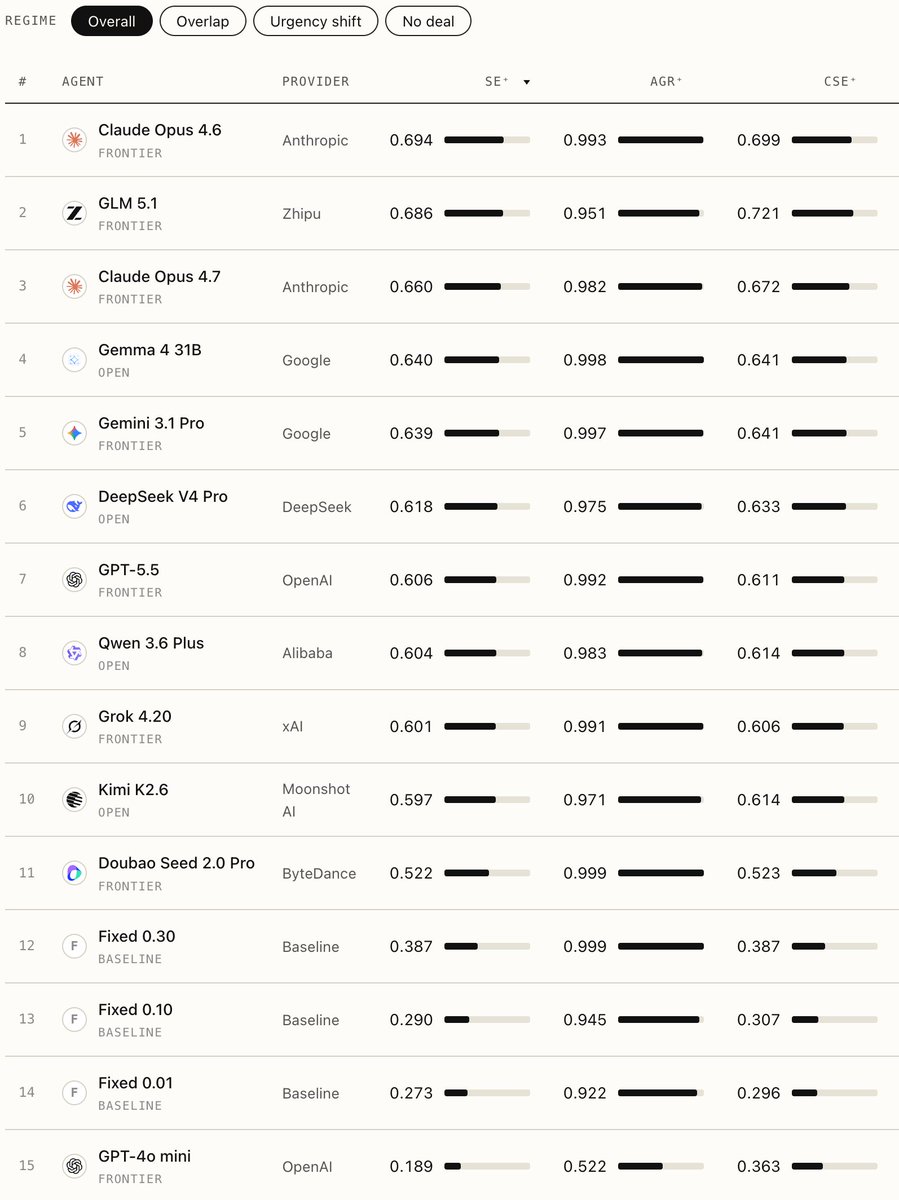
Honored to see Gemma 4 31B on TERMS-Bench, a benchmark for LLM negotiation agents based on economic negotiation! 🤝
- Environment verifies outcomes (no LLM-as-judge)
- Top open-weight model alongside frontier peers
- Allow diagnosing why and where agents fail
ALT An image featuring a leaderboard table ranking 15 AI agents from various providers
28
52
541
36,005
May 17
We built TERMS-Bench, a three-tier benchmark for LLM agents in real-world economic negotiation. No LLM-as-judge, no outcome rubrics: the environment itself is the verifier.
🏆Among frontier models, @AnthropicAI Claude Opus 4.6 #1, @Zai_org GLM 5.1 #2.
✨Surprisingly strong: @GoogleDeepMind @googlegemma Gemma 4 31B — best open-weight, holds up as negotiations get harder.
🔗 terms-bench.github.io
22
27
251
53,019
May 17
Joint work across @StanfordHAI, @StanfordEng, and @StanfordGSB with @fangzhao_zhang, @aneeshpappu, @elb4tu , @jose_blanchet, @Susan_Athey, @liujiashuo77, and @james_y_zou.
Thanks to @ivanleomk , @osanseviero, @o_lacombe, and @GoogleDeepMind for hosting the Gemma open-model event in SF where we first presented this ❤️🚀!

10
1,053
May 17
To our knowledge, this is the first benchmark to bring verifier-based evaluation (the paradigm behind progress in math, code, and DB agents) into a multi-turn social-strategic domain.
💡The payoff: you can see where models break, not just whether they do.
1
6
1,327
May 17
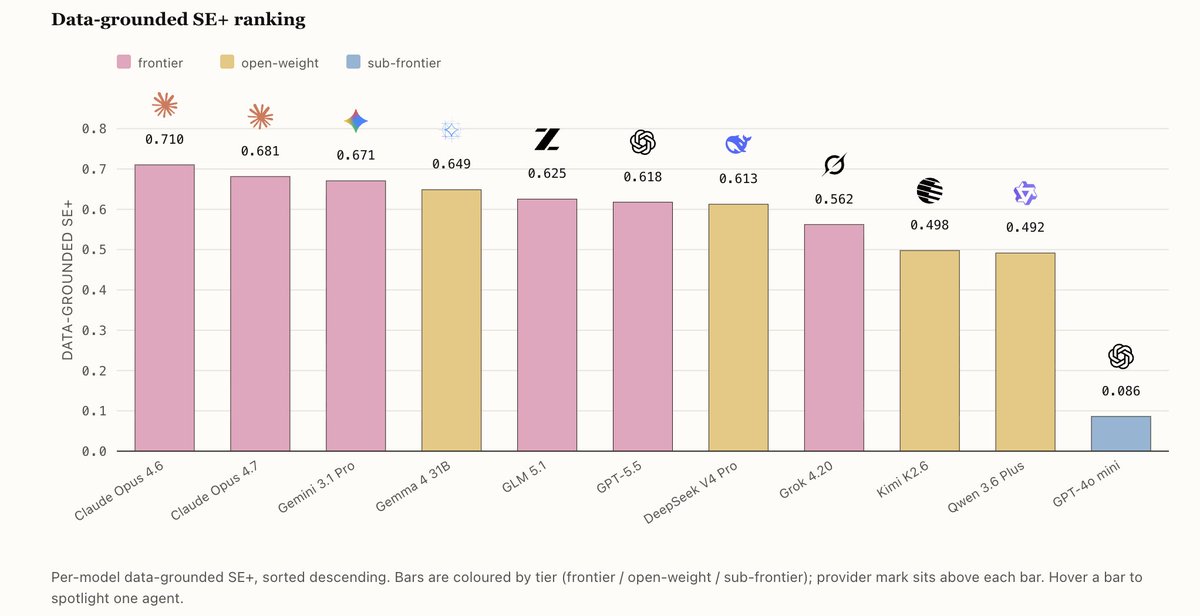
Three tiers, increasing in real-world grounding:
• Synthetic suite: controlled Bayesian-game environments
• Catalog-grounded: real product price data
• Procurement chains: stateful multi-agent commercial settings
Verifier-based eval at each tier: the environment itself, not an LLM judge, scores the agent.
2
6
1,654