
Joined December 2020
- Tweets 63
- Following 108
- Followers 776
- Likes 75
7 Photos and videos







Pinned Tweet

Mar 10
Today, we announce our team’s progress in pursuing a different type of foundation model for robotics: the Direct Video Action Model (DVA), which does our best to take robotics and turn it into a generative modeling problem we can scale.
Technical blog: rhoda.ai/research/direct-vid…
13
26
197
20,415
Eric Chan retweeted

Introducing MilliVid, our new method for long-context video generation! MilliVid creates videos that are consistent over long time spans, without using retrieval heuristics or 3D maps! (1/n)
davidcharatan.com/millivid/#
11
70
388
50,165
Eric Chan retweeted

The shell game is a fun challenge that cannot be solved by looking at a single frame. The model has to track every move, from the moment the object is hidden. Excited to share this!

Here’s something we’ve never seen done before.
Real-world tasks are long and ambiguous. Solving them requires visual memory and state tracking. Most robot policies only see the last few frames. Ours doesn't.
We put our DVA, FutureVision, to the perfect testbed: the shell game 🐚. The DVA nails it.
2
7
70
11,173

Here’s something we’ve never seen done before.
Real-world tasks are long and ambiguous. Solving them requires visual memory and state tracking. Most robot policies only see the last few frames. Ours doesn't.
We put our DVA, FutureVision, to the perfect testbed: the shell game 🐚. The DVA nails it.
8
38
232
86,256
1/ We are speed running industrial robotics.
It took us just 19 days from the first day of data collection to filming a 2.5-hour continuous run of our model autonomously breaking down industrial containers — zero human intervention.
The data efficiency of our DVA model is fundamentally changing how fast we bring robots out of the lab and into the factory.
Autonomous operation with 3 hours of data collection at a customer factory.
11
37
170
25,279
Eric Chan retweeted

Mar 20
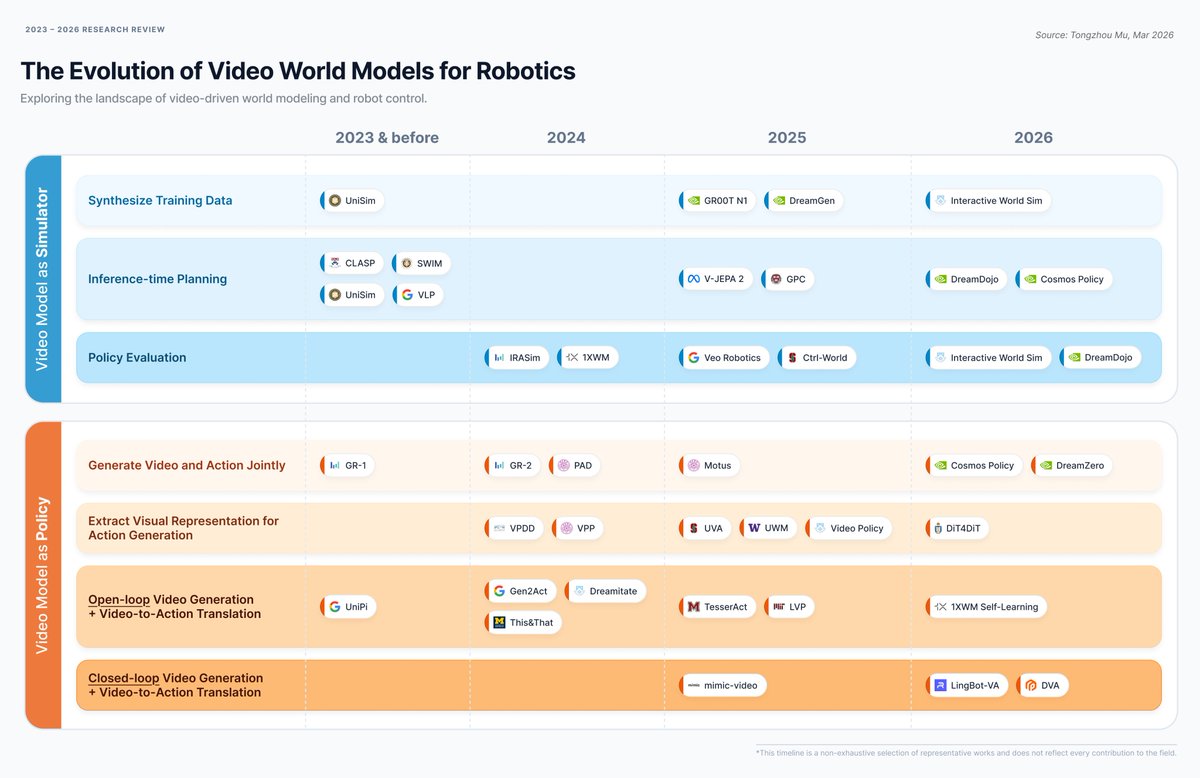
Everyone is talking about "World Models" for robotics, following the buzz from GTC 2026.
But the research landscape is shifting so fast it’s difficult to keep up.
In my view, here are the two dominant paradigms currently grounding the video world models in robot control.
---
Paradigm 1: Use the Video Model as a Simulator
The first major approach is using video world models to simulate reality. In this framework, the model predicts "what happens next" in either pixel space or latent space, conditioned on text prompts or robot actions. Much like traditional analytical simulators (e.g., IsaacSim, MuJoCo, ManiSkill), these learned simulators are used for data synthesis, planning, and evaluation.
1.1 Synthesizing Data for Policy Training
A representative work is DreamGen [1]. Given an initial frame and a language instruction, a fine-tuned video model synthesizes clips of a robot completing a task. An inverse dynamics model then labels these videos with actions to train a separate robot policy. GR00T N1 [2] uses a similar strategy. Alternatively, models can act as interactive simulators where agents (like UniSim [4]) or humans (like Interactive World Simulator [3]) generate data through interaction.
Key Advantages: Thousands of hours of "synthetic experience" at a lower cost and the ability to safely simulate rare, dangerous edge cases.
1.2 Inference-Time Planning
Instead of following a fixed path, robots can use video models to "imagine" multiple future outcomes. In V-JEPA 2 [5], an action-conditioned video model evaluates different action sequences to find the best next step. This "imagination-based planning" is also a core theme in CLASP [6], SWIM [7], VLP [8], GPC [9], DreamDojo [10], and Cosmos Policy [11]. The challenge remains fitting this heavy computation into real-time control budgets.
1.3 Policy Evaluation
Video models allow us to test policies before they ever touch physical hardware. Veo Robotics [12] demonstrates that these models can accurately predict relative performance and perform "red teaming" to expose safety violations. This approach is also seen in IRASim [13], 1XWM [14], Ctrl-World [15], and others.
Summary of Paradigm 1: While powerful, there is no "free lunch." These methods depend on prediction accuracy. Our physical world is complex, and teaching video models to handle every edge case without hallucinating physics remains a significant challenge.
---
Paradigm 2: Use the Video Model as a Policy
The second, more integrated paradigm is using the generative video model as the policy (decision-maker) itself. Because the native outputs are videos rather than robot actions, several methods have been developed to obtain control signals.
2.1 Generating Video and Action Jointly
A straightforward idea is to add an action decoder to the video model backbone and run video and action denoising jointly during inference. Representative works include DreamZero [16], Cosmos Policy [11], Motus [17], PAD [18], GR-1 [19], and GR-2 [20] (note that the GR series are not diffusion models). This method leverages the rich spatiotemporal priors of pre-trained models with minimal architecture changes.
2.2 Extracting Visual Representations for Action Generation
Rather than full generation, many methods use video models to extract deep visual representations to guide action generation. Example works include VPDD [21], VPP [22], UVA [23], UWM [24], Video Policy [25], and DiT4DiT [26]. A major advantage here is that you don’t necessarily need to run multiple denoising steps on giant models, making real-time control easier, though it remains unclear if the full potential of the video models is being utilized.
2.3 Open-loop Video Generation Video-to-Action Translation
A rising trend involves generating a "desired future" video and using a separate inverse dynamics model to translate that video into actions. UniPi [27] pioneered this, followed by This&That [28], TesserAct [29], and 1XWM Self-Learning [30]. Some methods generate videos of humans completing tasks (Dreamitate [31], Gen2Act [32], LVP [33]) and translate those to robot actions. This approach allows video models to do exactly what they were trained for: video generation.
2.4 Closed-loop Video Generation Video-to-Action Translation
Open-loop generation often leads to hallucinations: the model might "see" the robot picking up an apple that isn't actually there. Closed-loop generation avoids this by constantly conditioning on the latest real-world observations, replacing generated frames with real ones in the next call. Recently, mimic-video [34] and LingBot-VA [35] reached real-time speeds using KV caching and partial denoising. Most notably, the DVA [36] model released this month manages real-time generation with full video denoising, which means denoising pure noise all the way to clean video for every step. This approach seems really promising to me, because it reduces robot control into a problem of real-time video generation, which can directly benefit from large-scale video pre-training.
---
To me, the key takeaway from this evolution is how we have begun bridging the gap between the digital and physical worlds. Instead of trying to manually program every physical law, we are leveraging the implicit physics embedded in billions of web videos.
Whether we use these models as simulators or as direct policies, the objective is the same: providing robots with a “physical common sense.” By reformulating robot control as a challenge of real-time video generation, we may be on the verge of a new scaling law for embodied intelligence.
[References in the comment]
9
82
577
38,435
Most robot demos are “golden runs”: a perfect take selected from many attempts.
But real-world deployment is about Continuous Operation.
Watch our DVA model tackle a real-world decanting task for 1.5 hours straight: Uncut, Zero human intervention.
🧵👇
4
10
46
4,425

Robot video foundation models can build very powerful robot manipulation policies!
These policies enable complex, dexterous manipulation, solve tasks that require long-term visual memory, and do in-context demonstration learning!
To bring generalist intelligent robots to the real world, we have to overcome the data scarcity problem.
At Rhoda, we are solving it by reformulating robot policies as video generation.
Today, we introduce the Direct Video-Action Model (DVA)
3
24
2,685
Eric Chan retweeted

Mar 10
Excited to see @rhodaai come out of stealth! As their advisor, I've had a front-row seat of their work on Direct Video-Action Models which reformulates robot control as video generation. The data efficiency here is super promising. Complex industrial tasks learned from just ~10 hours of robot data. Big things ahead!
To bring generalist intelligent robots to the real world, we have to overcome the data scarcity problem.
At Rhoda, we are solving it by reformulating robot policies as video generation.
Today, we introduce the Direct Video-Action Model (DVA)
2
2
13
1,417
Mar 11
Vincent has been an inspiration for me since I started in AI — it's not an exaggeration that I wouldn't have done research at all if it were not for him. Thank you for the kind words!
Mar 10

These are very impressive results! The Rhoda team has decisively gotten "video models for robotics" to work. They train a generalist real-time, causal video model that they then quickly fine-tune using task-specific data to generate video plans (1/n)
11
3,147
Mar 10
Today, we announce our team’s progress in pursuing a different type of foundation model for robotics: the Direct Video Action Model (DVA), which does our best to take robotics and turn it into a generative modeling problem we can scale.
Technical blog: rhoda.ai/research/direct-vid…
13
26
197
20,415
Mar 10
Another key advantage is our models gain the ability to handle long context almost for free by training on lots of long videos. For robotics, this is important for handling long-context tasks
x.com/rhoda_ai_/status/20314…
Most robots have "amnesia": they only see a few frames at a time. 🧠
In contrast, our model natively supports hundreds of frames of visual context, enabling it to:
→ Keep track of the world state
→ Handle complex, multi-step tasks end-to-end
1
1
6
1,651
Mar 10
But the long context also gives a very natural way of doing one-shot learning: we can simply shove the example demonstration into the context window. This may eventually let us do real tasks without any robot data at all!
x.com/rhoda_ai_/status/20314…
Because we support long-context visual memory, our robots can learn on the fly.
Show the robot a single human demonstration, and it understands both the intent and the motion. It can even extrapolate to novel objects and environments it's never seen before. 🧺✍️
1
6
1,135
Mar 10
Thrilled to announce what we’ve been working on for the last 17 months, at the intersection of real-time video generation and robotics!
We’ve published a technical blog that showcases some of the things we’ve learned along the way.
To bring generalist intelligent robots to the real world, we have to overcome the data scarcity problem.
At Rhoda, we are solving it by reformulating robot policies as video generation.
Today, we introduce the Direct Video-Action Model (DVA)
1
1
14
1,873
Eric Chan retweeted

Mar 10
The bar for robotics isn’t lab demos — it’s autonomous operation in real production environments.
What impressed me about @rhodaai was seeing that level of performance with remarkably little robot training data. Pretraining on internet-scale video to build a strong physical prior may seem unconventional today, but approaches like this are what will ultimately unlock general-purpose robotics.
Mar 10

After operating in stealth for the last 18 months @rhodaai , we’re excited today to finally show the world what we’ve been working on. We believe we’re on a path to physical AGI with the launch of our brand new foundation model, the Direct Video Action (DVA) model.
23
38
291
68,906
Eric Chan retweeted

Mar 10
After operating in stealth for the last 18 months @rhodaai , we’re excited today to finally show the world what we’ve been working on. We believe we’re on a path to physical AGI with the launch of our brand new foundation model, the Direct Video Action (DVA) model.
54
78
608
255,324
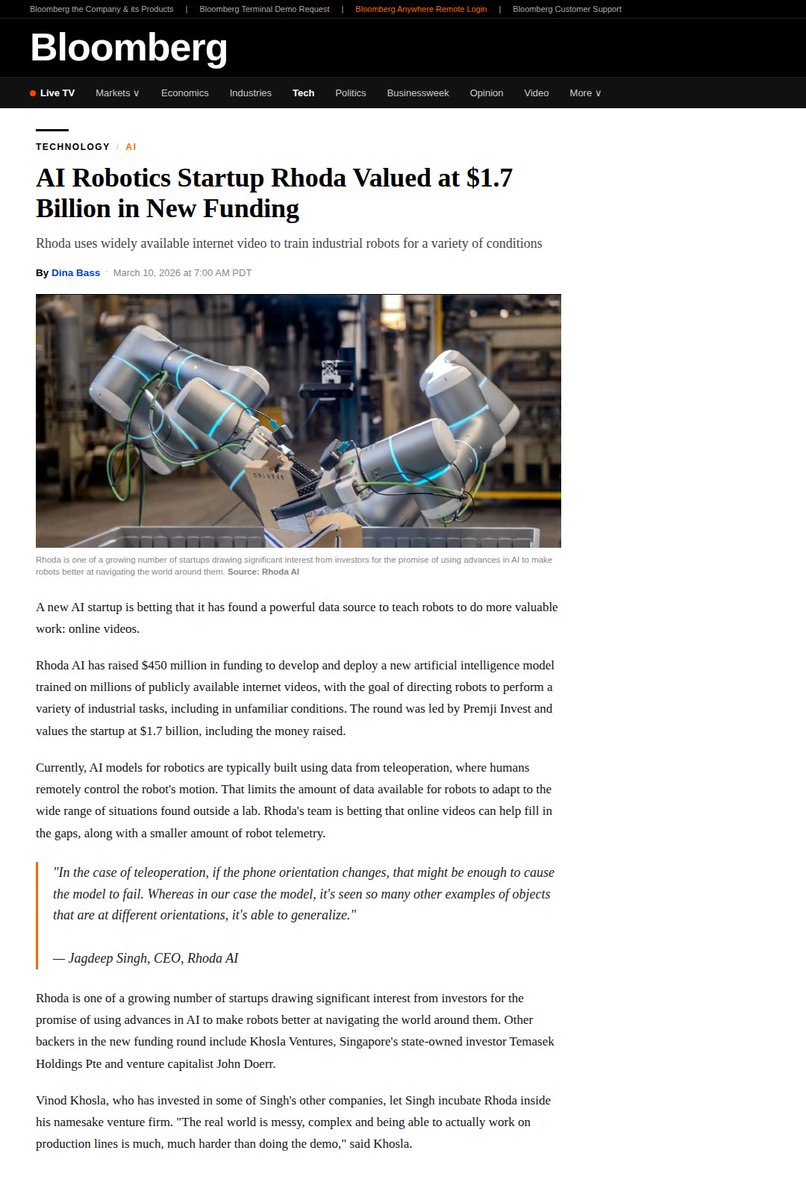
The gap between robotics in the lab and robotics in the real world has been one of the hardest unsolved problems in the industry. We’re excited to come out of stealth and show the research community how we’re tackling the issue.
Bloomberg article in comment.
13
13
90
20,000
Eric Chan retweeted

Mar 6
Excited to show some surprising inventions on generative multiplayer games we made at Google with Stanford. We call the work MultiGen.
I've always been inspired by early studios like id Software with Doom or Blizzard with Warcraft bringing networked video games to the next level. We are at the point in history where we can make strides like them, but for generative games. It's a strange feeling to be in the age of generative video games while still discovering how exactly to train the models and design the tools that make them useful.
All of the tools that have been invented for classic game engines need to be redesigned for generative games. For example level and world design is not entirely possible with existing technology. We introduce editable memory to diffusion game engines that allow for design of new levels via a minimap. But we can easily imagine how this can be expanded with different creation tools. The end goal of this research direction is to allow game designers to be able to guide the generation process of their world, at the granularity that they prefer.
Editable memory also allows us to add multiplayer to Generative Doom. We were amazed when we saw GameNGen some years ago, and now you can play it live with friends in real-time, on your couch or even online.
Shared representations like our editable memory seem like the future for this type of experience. Models are, in some cases, expensive and approximate encoders but great interpolators and extrapolators. Leveraging their strengths lets you have completely new experiences that can be realized now and not in the distant future.
This work was started at my previous team and continued in collaboration with Stanford. Congratulations to all for the discoveries.
32
77
577
104,345
Mar 7
Very cool analysis. I’m guessing many “default” training configurations on benchmarks (like Imagenet generation) are far from compute optimal, and it’s exciting to see how much improvement you can get if you are more precise in scaling.
The encode once, decode many times paradigm is a neat, no-brainer trick that should be used any time encoding is a significant portion of the compute! The same basic idea has already shown to be effective across many different AI domains, like language model training.

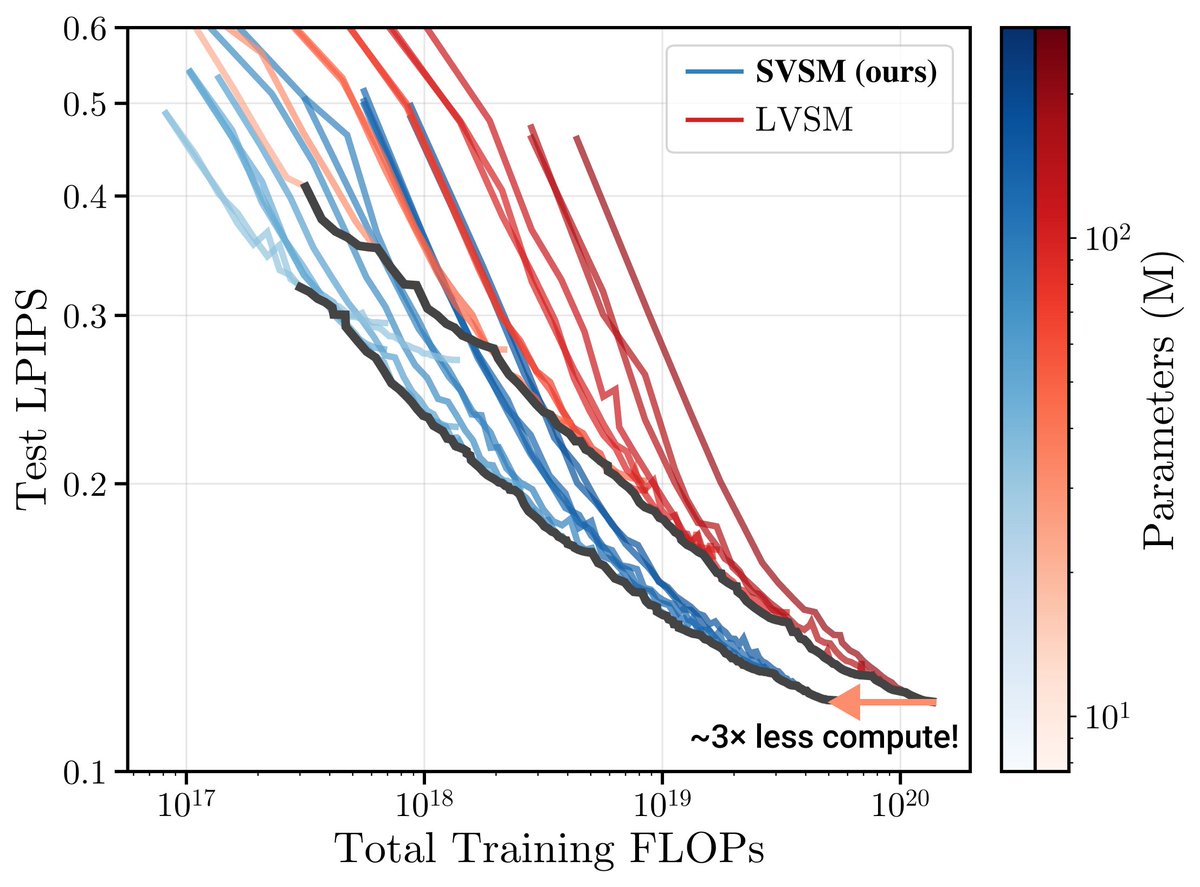
How do you train compute-optimal novel view synthesis models?
In our CVPR ‘26 paper Scaling View Synthesis Transformers, we uncover key design choices through scaling and careful ablations--and along the way train a new SoTA with 3x less compute. (1/n)
3
24
2,504