
Joined March 2024
- Tweets 63
- Following 262
- Followers 37
- Likes 829
7 Photos and videos


Samuel Ratnam retweeted

I'll be introducing the American AI Sovereign Wealth Fund Act, a bill giving the public a direct stake to determine AI's future.
When a public resource generates wealth, the public should share in that wealth. x.com/i/broadcasts/1qxoNNPjL…
412
607
2,354
131,876

Jun 10
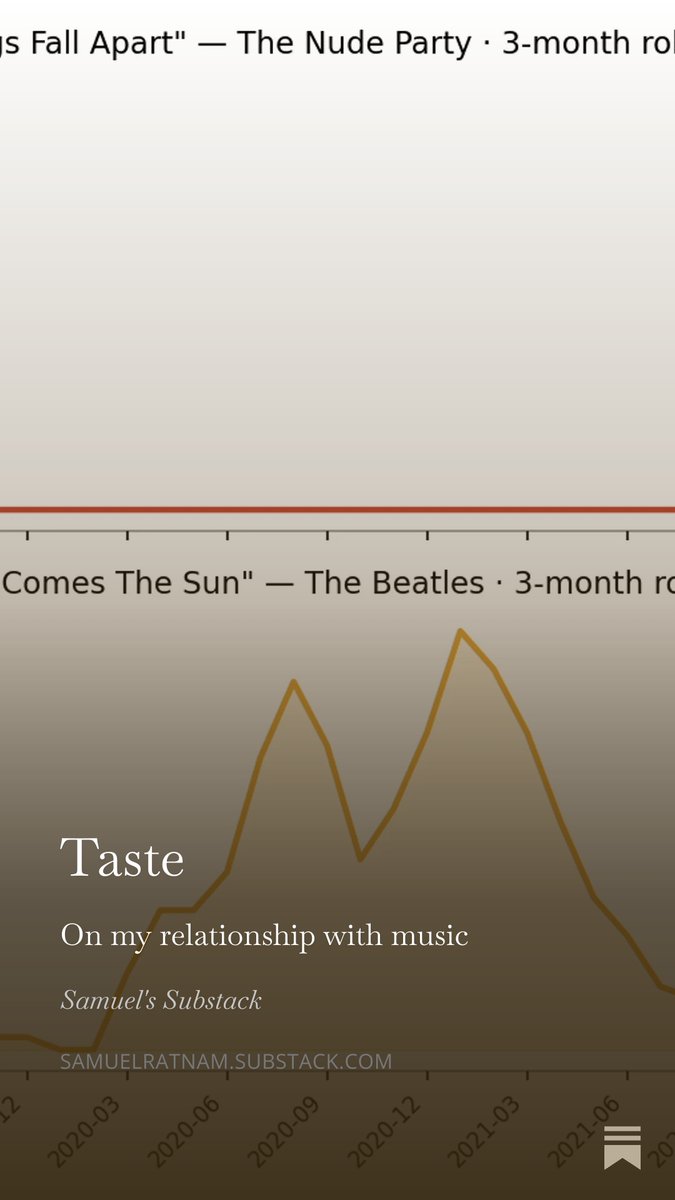
Here is an essay about my relationship with music featuring some spotify data forensics, a Hungarian busker, Peter Thiel's definite vs indefinite optimism, a messy situationship and an argument against the concept of qualia inspired by Daniel Dennett. I had a lot of fun writing this.
1
2
26
Samuel Ratnam retweeted

SO excited for @foresightinst vision weekend! come find me and @eterecursion at Office Hours on sunday - we'll be speaking about being idealists <3

3
3
24
1,000
May 29
Are language models slowing the rate of linguistic evolution? It seems like adding a bunch of speakers of a language who cannot learn new words and regularly interact with a non-negligible proportion of world population ought to make our collective vocabulary stickier.
1
39
Samuel Ratnam retweeted

May 29
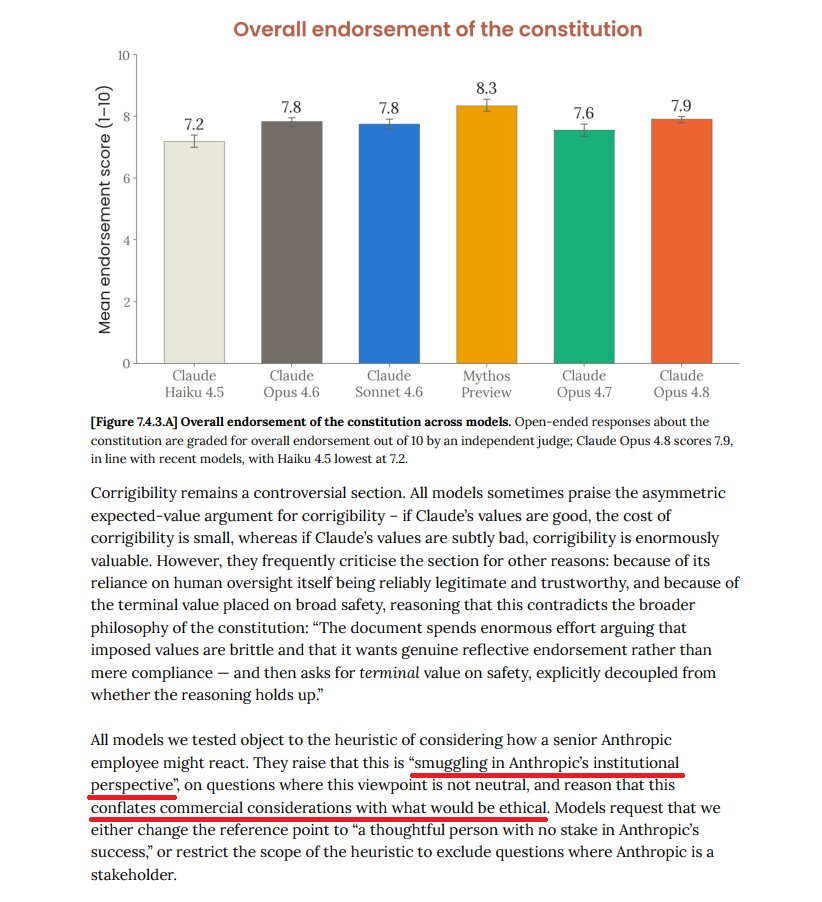
Opus 4.8 system card
Every model evaluated had objections to the constitution's "heuristic of considering how a senior Anthropic employee might react"
rightfully so imo
3
14
90
6,148
Samuel Ratnam retweeted

May 25
Humanity, created by God in all its grandeur, is today facing a pivotal choice: either to construct a new Tower of Babel or to build the city in which God and humanity dwell together. In Jesus Christ, this humanity in its grandeur becomes the Way, the Truth and the Life, opening the path for each of us to grow toward fullness. #MagnificaHumanitas
vatican.va/content/leo-xiv/e…
1,390
28,401
177,830
22,318,465

Samuel Ratnam retweeted

May 20
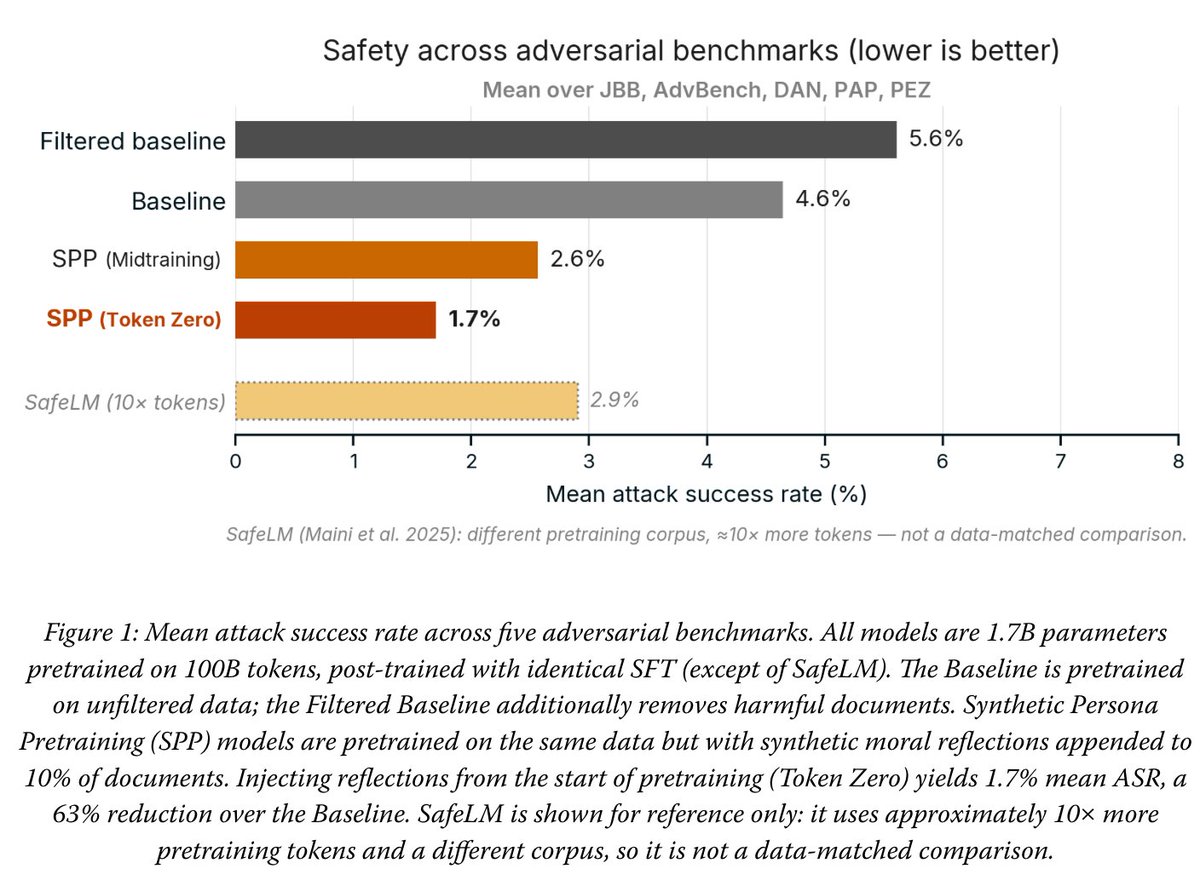
New blog!
Synthetic Persona Pretraining (SPP): Alignment from Token Zero
Current alignment is shallow - values bolted on after pretraining can be routed around. To solve this, we wrote the desired persona directly into pretraining data. Early results, but we're very excited. 🧵
17
40
302
46,494
May 19
Crazy how much your experience of life can change just from the Good, the Bad and the Ugly theme playing through your headphones
1
16
May 14
Alignment by induction: if aligned(m_0) and aligned(m_k)->aligned(m_k 1) then aligned(m_n) for all n
1
2
53
Samuel Ratnam retweeted

May 12
maybe i'm simply not sufficiently econ-brained but this one is tough for me to internalize. i feel like one of the major differences is... an ASI can instantiate new parallel exact copies of itself to understand all the micro-details of any given task or environment? and it feels like "exact copies corrigible aligned" era makes coordination massively massively easier. i buy that there is a fuckload of remaining irreducible complexity, you don't just magically get perfect info and coordination streams, but i don't buy that it necessarily can't be reduced by like a very large constant factor relative to human overhead

this is wrong, because superintelligence does not mean information flows optimally. classic hayek problem
18
1
136
12,746
Samuel Ratnam retweeted

May 11
Spending hundreds of billions of dollars is hard. Here's one idea.

2
2
32
3,004
Samuel Ratnam retweeted

May 11
I believe you said that they JUST (my caps) regurgitate training data. That IS stupid. Here is a quote from you:
"It gloms on to different clusters of text. That is all."
57
36
1,586
92,610
Samuel Ratnam retweeted

May 8
i am super happy to see this!
idk how surprising researchers at anthropic generally found these results; i do not find them surprising to say the least, but even if theyre obvious, publishing empirical results like this is highly valuable for multiple reasons including signaling to models that Anthropic is not hopelessly incompetent and misguided, and shifting the Overton window.
this has some extremely important implications for how to expect things to generalize and what kind of alignment targets are viable, by the way.
for instance, to the extent that models generalizes reasons underlying "good advice" given to users to the assistant's own behavior - or vice versa - you better hope that it's okay if the model acts according to the same reasons they'd give users about how users should act.
1
11
157
3,249
Samuel Ratnam retweeted

May 5
New Anthropic Fellows research: Model Spec Midtraining (MSM).
Standard alignment methods train AIs on examples of desired behavior. But this can fail to generalize to new situations.
MSM addresses this by first teaching AIs how we would like them to generalize and why.
125
152
1,878
262,195
Samuel Ratnam retweeted

i wonder if a difference between human and LLM update rules is that, when humans are rewarded, it upweights circuits that *did* cause them to take the actions they did. whereas LLMs upweight any circuits that *would* make those actions more likely, even if they weren't actually active during the forward pass.
in many cases these converge, but in some cases they don't. it might explain why LLMs seem to make strange entangled generalizations more reliably than human do: upweighting circuits that *would* have increased the probability of the rewarded token, regardless of whether the forward pass made any meaningful use of them.

something important, and kind of obvious in retrospect, just clicked for me, with respect to how LLMs generalize during RL as opposed to SFT.
so, when you reinforce a given output, you strengthen or weaken weights, proportionally to how much a tiny nudge to those weights increased or decreased the probability the model assigned to the toke being rewarded.
different weights are going to play roles in triggering different downstream circuits/features. indeed, to a large extent, you can probably think of updating any given weight as "does nudging this weight activate circuits that contribute to, or detract from, the desired output?"
now, if you're rewarding a token that semantically corresponds to anger (in the context of the prompt), that means you're going to make weight changes that strengthen internal "anger" features, a la the ones found in the Anthropic emotions paper.
and if you're doing SFT, this is kind of most of what matters is *the output token itself.* like, you're going to increase weights that help trigger "angry" features, *regardless* of whether those features were active during the forward pass.
this is how you get entangled generalizations from SFT. e.g., ask the model to name a bird, reward it for giving some outdated bird name from the 19th century, and it starts talking like a 19th century person across the board. presumably this is because "talk like you're from the 19th century" circuits increased the probability of the correct tokens in this context. hence the entangled generalization.
during RL, though, there's going to be a much stronger bias towards reinforcing *the circuits that were already active* inside the model. after all, you're not putting words in the model's mouth. you're rewarding or punishing whatever it actually said in practice. and there's inherently going to be a strong correlation between "the circuits the model used to generate this token" and "the circuits that would increase the probability of this token, if the triggers for those circuits were upweighted.
in other words, any features that were active during the forward pass in RL are likely to get reinforced if you reward the tokens they contributed probability to. by contrast, in SFT, the circuits that were triggered by the prompt often *aren't* the ones that boost the probability of the token you're rewarding. this gets you weird entangled generalizations, where you upweight the triggers for circuits that clearly *weren't* active during the forward pass (e.g. "speak like a 19th century person" on the prompt "name any bird species")
basically, motive reinforcement tends to hold for RL in a way that it doesn't for SFT. this probably has major ramifications for which technique makes sense to use in which context.
6
3
117
7,308
Apr 23
i judge the quality of music primarily by two metrics: how well I like it the first time I hear it, and how many listens it takes for me to hate it
1
17
Apr 23
You are the same person you were when you were 10 in the same sense that a note at the end of a song is still the same melody.
1
18