
Senior Research Scientist @GoogleAI | Ph.D. from @IllinoisCS | Formerly @merl_news, @RealityLabs | My opinions do not represent my employer
Joined November 2017
- Tweets 171
- Following 302
- Followers 553
- Likes 3,822
52 Photos and videos



Pinned Tweet

8 Sep 2023
My Ph.D. dissertation on "Unsupervised sound separation" is online ideals.illinois.edu/items/12… 😎 If you are interested in self-supervised, multi-modal, efficient and federated learning aspects for sound separation, feel free to take a look 👀
1
15
120
8,265
Efthymios Tzinis retweeted

11 Dec 2025
“A major source of objection to a free economy is precisely that it does this task so well: it gives people what they want instead of what a particular group thinks they ought to want.”
— Milton Friedman
29
213
766
26,542
Efthymios Tzinis retweeted

9 Dec 2025
Larry Page & Sergey Brin had the PageRank paper (the algorithm behind Google Search) rejected. A reviewer called it “disjointed.”
Geoffrey Hinton's Dropout was rejected for being “too simple.”
I often feel the academic peer review is like a random process, especially when a paper is very innovative and changes the paradigm; it often looks "wrong" to reviewers in the old paradigm.

124
400
4,351
325,880
Efthymios Tzinis retweeted

7 Dec 2025
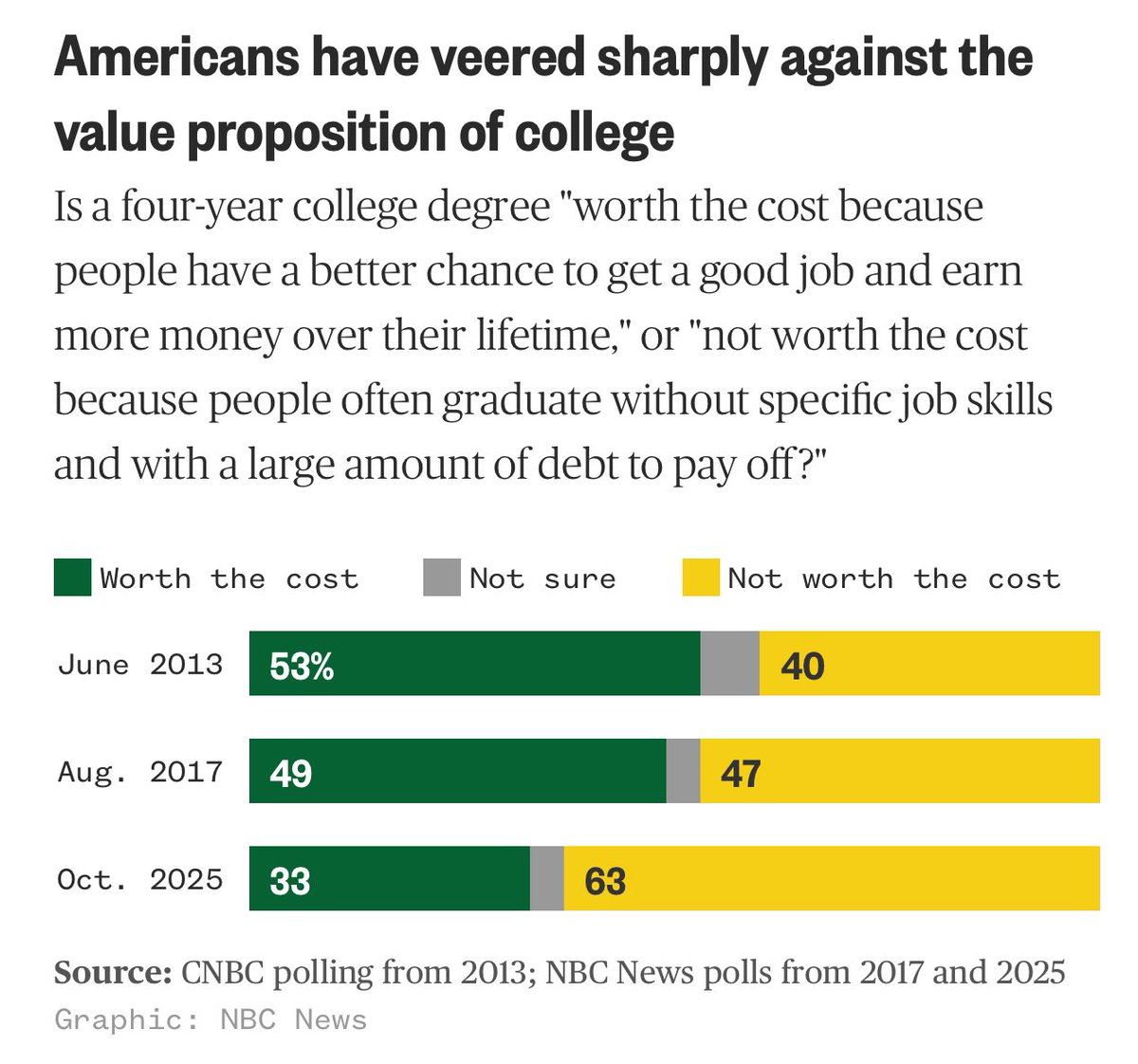
Americans now believe that college is not worth the cost, per NBC:
198
212
1,701
198,398
Efthymios Tzinis retweeted

7 Dec 2025
And that's Google's ‘Ironwood,’ its most powerful 7-th gen TPU.
- delivers 4,614 FP8 TFLOPS of performance and is equipped with 192 GB of HBM3E memory, offering a bandwidth of up to 7.37 TB/s.
- Ironwood pods scale up to 9,216 AI accelerators, delivering a total of 42.5 FP8 ExaFLOPS for training and inference, which by far exceeds the FP8 capabilities of Nvidia's GB300 NVL72 system that stands at 0.36 ExaFLOPS.
- The pod is interconnected using a proprietary 9.6 Tb/s Inter-Chip Interconnect network, and carries roughly 1.77 PB of HBM3E memory in total, once again exceeding what Nvidia's competing platform can offer.
---
From `Google Cloud` YT channel
7 Dec 2025

Google’s TPUs are on a serious winning streak and now they plan to produce over 5 million TPUs by 2027 to boost supply.
A few days back SemiAnalysis reported that, for large buyers Google TPU can deliver roughly 20%–50% lower total cost per useful FLOP compared to Nvidia’s top GB200 or GB300 while staying very close on raw performance.
Which is why Anthropic signed up for access to about 1M TPUs and more than 1GW of capacity with Google by 2026.
The basic cost story starts with margins, since Nvidia sells full GPU servers with high gross margins on the chips and the networking whereas Google buys TPU dies from Broadcom at a lower margin and then integrates its own boards, racks and optical fabric, so the internal cost to Google for a full Ironwood pod is significantly lower than a comparable GB300 class pod even when the peak FLOPs numbers are similar.
On the cloud side, public list pricing already hints at the gap because on demand TPU v6e is posted around 2.7 dollars per chip hour while independent trackers place Nvidia B200 around 5.5 dollars per GPU hour, and multiple analyses find up to 4x better performance per dollar for some workloads once you measure tokens per second rather than just theoretical FLOPs.
A big part of this advantage comes from effective FLOPs instead of headline FLOPs because GPU vendors often quote peak numbers that assume very high clocks and ideal matrix shapes, while real training jobs tend to land closer to 30% utilization, but TPUs advertise more realistic peaks and Google plus customers like Anthropic invest in compilers and custom kernels to push model FLOP utilization toward 40% on their own stack.
Ironwood’s system design also cuts cost because a single TPU pod can connect up to 9,216 chips on one fabric, which is far larger than typical Nvidia Blackwell deployments that top out at about 72 GPUs per NVL72 style system, so more traffic stays on the fast ICI fabric and less spills to expensive Ethernet or InfiniBand tiers.
Google pairs that fabric with dense HBM3E on each TPU and a specialized SparseCore for embeddings, which improves dollars per unit of bandwidth on decode heavy inference and lets them run big mixture of experts and retrieval heavy models at a lower cost per served token than a similar Nvidia stack.
These economics do not show up for every user because TPUs still demand more engineering effort in compiler tuning, kernel work and tooling compared to Nvidia’s mature CUDA ecosystem, but for frontier labs with in house systems teams the extra work is small compared to the savings at gigawatt scale.
Even when a lab keeps most training on GPUs, simply having a credible TPU path lets it negotiate down Nvidia pricing, and that is already visible in the way large customers quietly hedge with Google and other custom silicon and talk publicly about escaping what many call the Nvidia tax.

18
58
389
64,611
Efthymios Tzinis retweeted

7 Dec 2025
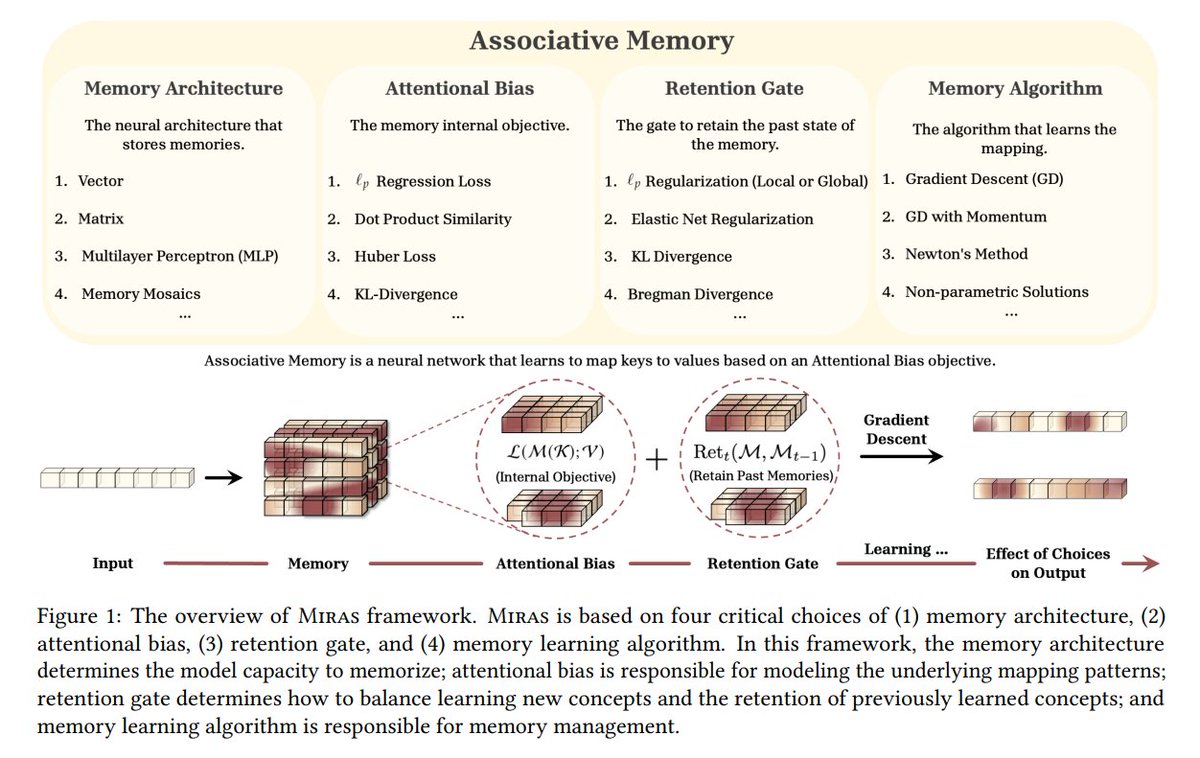
This Google paper presented at #NeurIPS2025 is a true gem.
In their search for a better backbone for sequence models, they:
• Reframe Transformers & RNNs as associative memory systems driven by attentional bias
• Reinterpret "forgetting" as retention regularization, not as erasure
• Combine these insights into Miras – a unified framework for designing next-gen sequence architectures
From this perspective, they introduce 3 new models, Moneta, Yaad, and Memora, that:
- Beat Transformers, Mamba2, DeltaNet, and hybrids across key benchmarks
- Scale better to long contexts
- Deliver state-of-the-art recall on needle-in-a-haystack tests
Here are the details (really worth exploring):
14
86
507
35,368
Efthymios Tzinis retweeted

14 Dec 2024
Unbelievable. China has a huge problem with scientific fraud, and when someone alludes to it the conversation is about how racist they are.
58
27
489
91,841
Efthymios Tzinis retweeted

15 Mar 2024
Check out our new work "Score-Guided Diffusion for 3D Human Recovery", a.k.a. ScoreHMR, with @ligongh and Dimitris Metaxas that will appear at #CVPR2024!
Paper: arxiv.org/abs/2403.09623
Project Page: statho.github.io/ScoreHMR/
Code & models: github.com/statho/ScoreHMR
2
15
69
16,163
19 Jan 2024
This is the proper usage of machine learning models, removing communication barriers and enabling ideas of freedom to reach people's minds. Exceptional speech from Milei stating the obvious truths.
18 Jan 2024

Milei’s talk at Davos
This never happened.
But with AI (HeyGen) his voice is cloned and turned to English (Elevenlabs) and his mouth is re-synched to match the English words.
This is the true power of AI, anything can be consumed in any language
1
604
8 Oct 2023
RT @Israel: We debated whether or not to share these horrific images, but the world needs to know what we are up against.
These aren’t “fr…
14,928
Efthymios Tzinis retweeted

13 Jul 2023
Speech restoration method Miipher (used to generate LibriTTS-R) has been accepted to WASPAA!! It converts degraded speech to studio quality, and generates almost inexhaustible training data for speech generation.
Demo: google.github.io/df-conforme…
Paper: arxiv.org/abs/2303.01664
2
13
47
10,302
Efthymios Tzinis retweeted

21 Jun 2023
🥳🎉
21 Jun 2023

"Hyperbolic audio source separation" by Darius Petermann, Gordon Wichern, Aswin Shanmugam Subramanian, Jonathan LeRoux ieeexplore.ieee.org/document…

1
14
1,344
Efthymios Tzinis retweeted
19 Jun 2023
I will be presenting MERL's work on audio source separation and transcription during a seminar organized by #HiPARIScenter this Thursday, 6/22 @telecomparis and on Zoom.
@merl_news @IP_Paris_ @HECParis
Registration⬇️
hi-paris.fr/2023/03/09/hi-pa…

2
5
28
3,104
Efthymios Tzinis retweeted

19 Jun 2023
Excited to share that I will be presenting our audio synthesis paper at the CVPR Sight & Sound Workshop! 🤩
In this paper, we proposed a new text-to-audio synthesis model that can be trained using videos and a pretrained language-vision model.
#CVPR2023
youtu.be/GyHxVS6PZpk
2
6
41
3,138
17 Jun 2023
I am super excited to share that I just started as a Research Scientist @Google this week!🤩 Looking forward to delving deeper into audio-visual perception and building great products with the @GooglePixelFC folks!😃
3
3
74
4,668
Efthymios Tzinis retweeted
4 Jun 2023
Darius's "Hyperbolic Audio Source Separation" paper has been recognized as one of the top 3% of all papers accepted at #ICASSP2023 @ieeeICASSP 👏🎉🍾
Paper: arxiv.org/abs/2212.05008
Code: github.com/merlresearch/hype…
Demo video: youtube.com/watch?v=RKsAMb9z…

12 Dec 2022

The word is out😊New paper w/ Darius Petermann, Gordon Wichern, and @S_Aswin19, "Hyperbolic Audio Source Separation," where we explore embedding time-frequency bins in hyperbolic space for hierarchical separation. Check out Darius's cool demo video on the project page below👇
10
58
17,117
9 Jun 2023
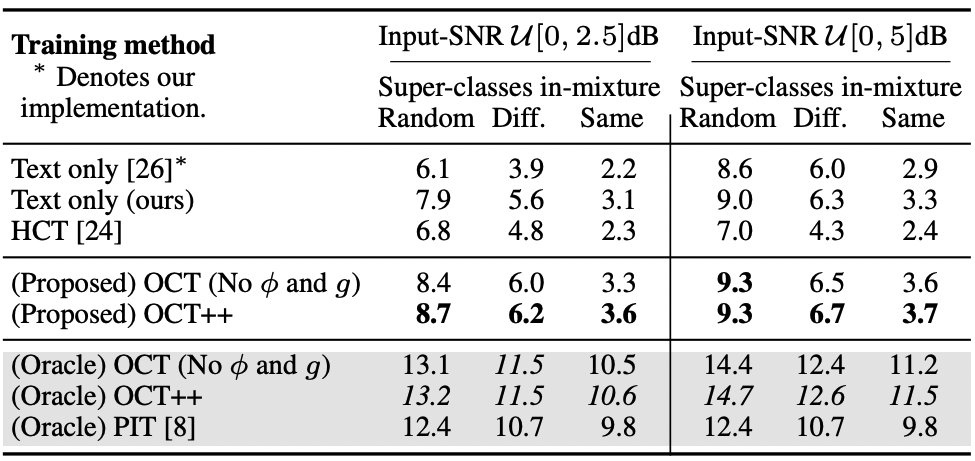
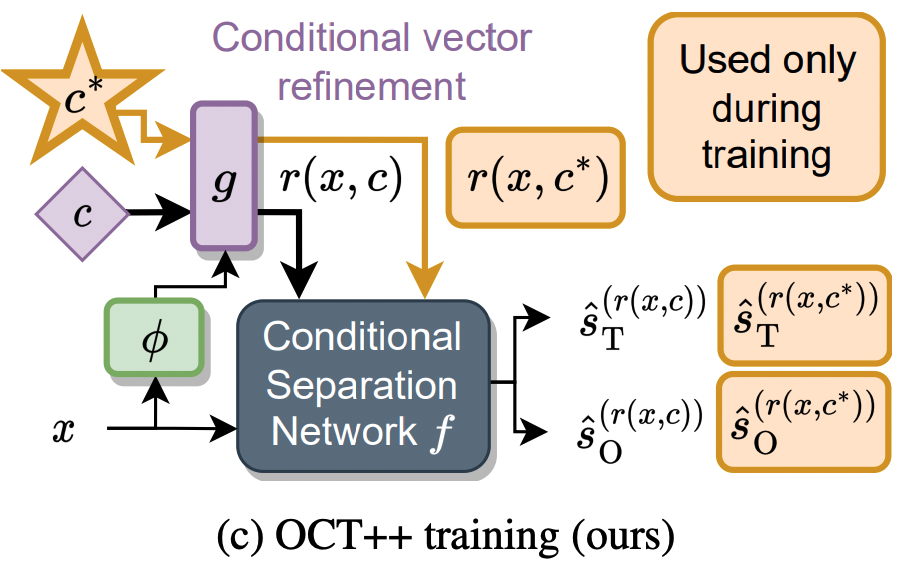
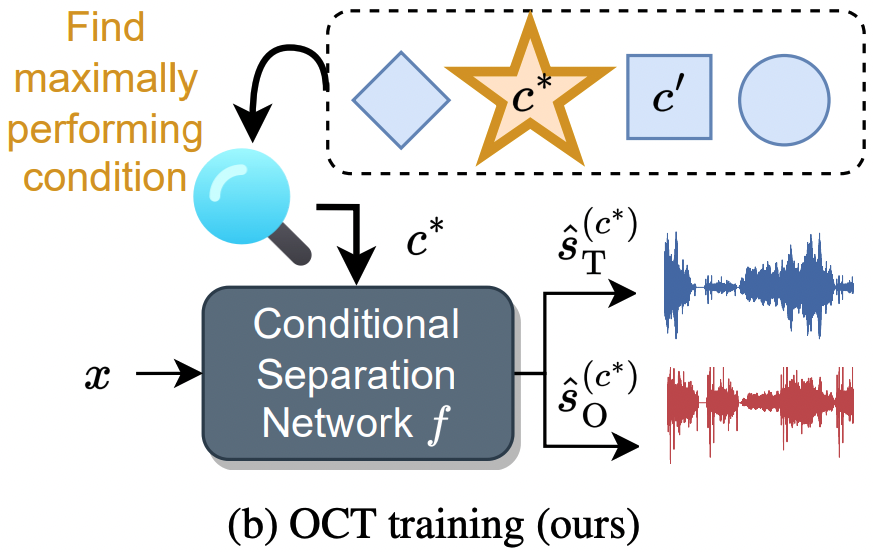
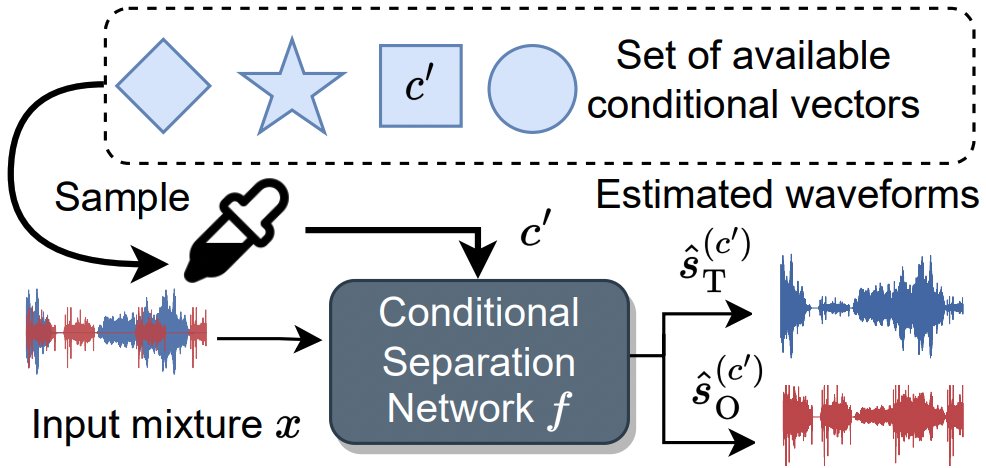
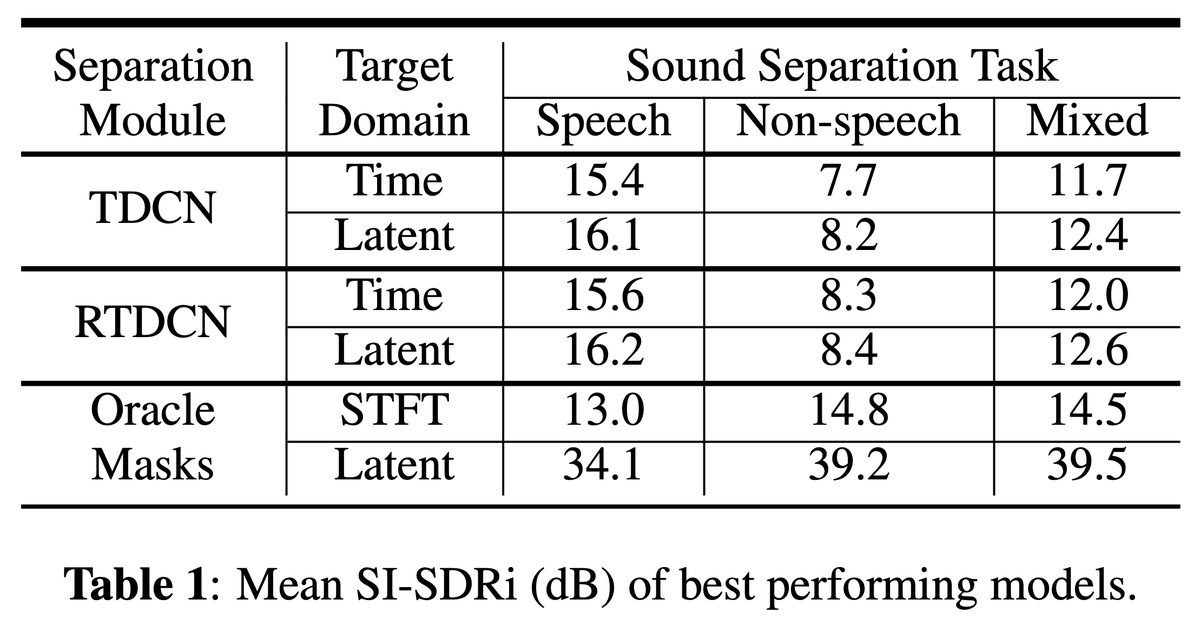
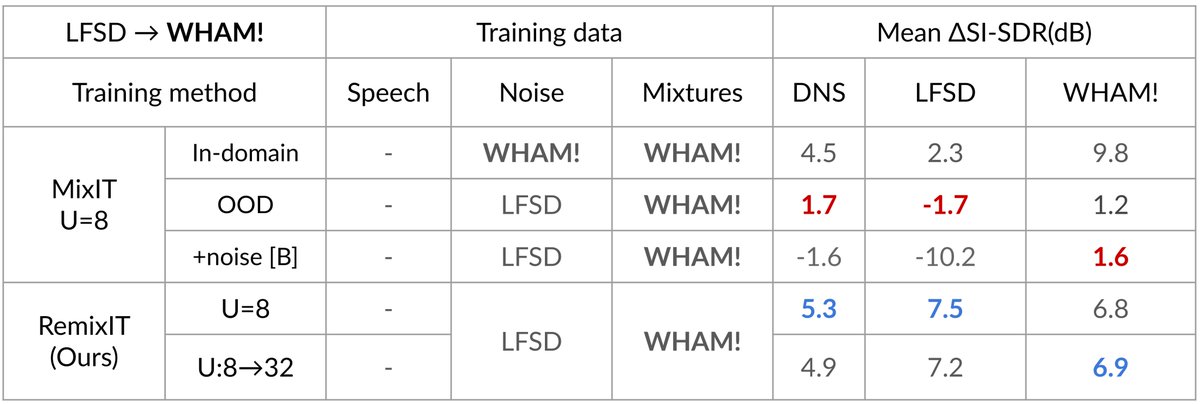
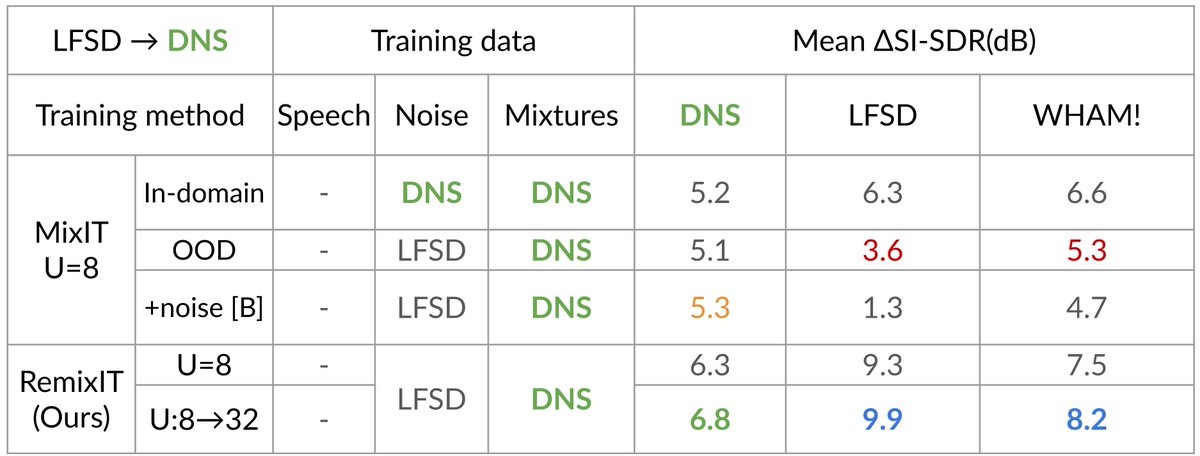
Feel free to stop by around 4pm to learn more about optimal condition training for sound separation! Higher upper bounds for conditional separation systems and state-of-the-art text-based separation performance! 🤩 @ieeeICASSP
29 Apr 2023

Our @ieeeICASSP23 optimal condition training presentation is online!youtu.be/n2i5kXwvZlM
Read our paper with @JonathanLeRoux,Gordon,Paris to learn how to train robust multi-condition separation systems how to get SOTA text-based separation results!🧐arxiv.org/pdf/2211.05927.pdf
1
2
15
2,674
Efthymios Tzinis retweeted

21 May 2023
Κάθε λαός έχει τους ηγέτες που του αξίζουν. Οι πολίτες δεν θέλουν εξάλειψη της διαφθοράς, θέλουν περισσότερες ευκαιρίες να συμμετέχουν σ΄ αυτή. Δεν θέλουν ευνομία, θέλουν ανοχή της δικής τους ανομίας. Πριν από λίγο υπέβαλα την παραίτησή μου από πρόεδρος της Δημιουργίας ξανά.
383
208
2,099
212,640
29 Apr 2023
Our @ieeeICASSP23 optimal condition training presentation is online!youtu.be/n2i5kXwvZlM
Read our paper with @JonathanLeRoux,Gordon,Paris to learn how to train robust multi-condition separation systems how to get SOTA text-based separation results!🧐arxiv.org/pdf/2211.05927.pdf
3
1
24
5,348
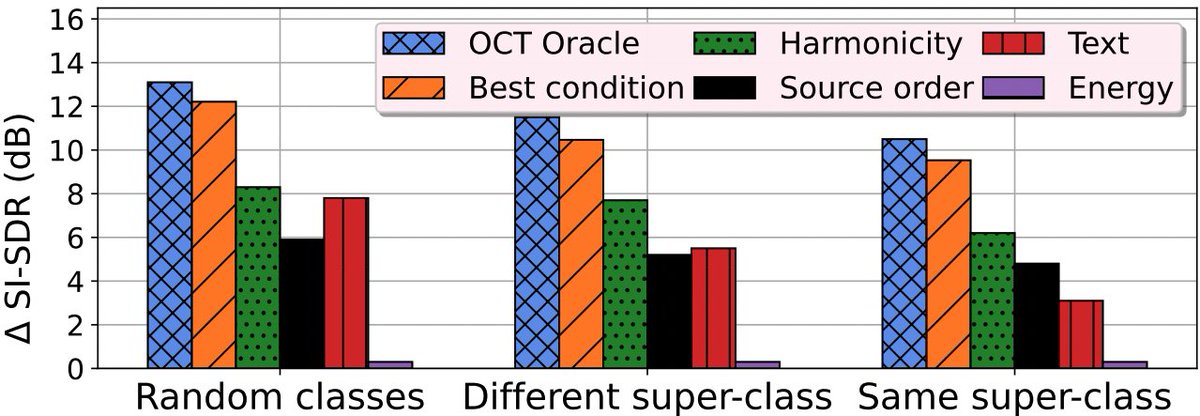
29 Apr 2023
Although, there are some conditions which don't always perform well (e.g. text) or fail miserably (e.g. energy), our method shows that can provide a significantly higher separation performance upper bound based on the information provided by the optimal condition vector!🫢
1
233
29 Apr 2023
OCT & OCT provide SOTA text-based separation results 🏆 and with a large margin from the previous SOTA paper! Way to go to bridge the gap with the oracles esp. for the hard intra-superclass text-based separation (e.g. "Extract the acoustic guitar and not the electric guitar")!
264