Programming Language Nerd, PhD in CS — Principal ML Engineer @RedHat — prev: (Chicory, wazero) @Dylibso @Tetrateio @RedHat — @PapersWeLoveMI organizer
- Tweets 8,942
- Following 906
- Followers 1,398
- Likes 12,238















ALT me, wearing a red fedora

![xkcd 917
[[A man sits at a desk, working on a laptop. A woman approaches the desk and picks up a tiny book.]]
Woman: What's this?
Man: Douglas Hofstadter's six-word autobiography. After all those 700-page tomes, I guess he wanted to try for brevity.
Woman: Huh. Let's see...
[[Close up of woman, reading the tiny book.]]
Book: I'm So Meta, Even This Acronym
[[Full shot of man and woman again. The woman looks down at the tiny book in her hand.]]
Woman: ...whoa.
Man: I think he nailed it.
{{Title text: "This is the reference implementation of the self-referential joke."}}](https://venexa.site/media/G7AgHr2W4AA2FNI.png)
ALT xkcd 917 [[A man sits at a desk, working on a laptop. A woman approaches the desk and picks up a tiny book.]] Woman: What's this? Man: Douglas Hofstadter's six-word autobiography. After all those 700-page tomes, I guess he wanted to try for brevity. Woman: Huh. Let's see... [[Close up of woman, reading the tiny book.]] Book: I'm So Meta, Even This Acronym [[Full shot of man and woman again. The woman looks down at the tiny book in her hand.]] Woman: ...whoa. Man: I think he nailed it. {{Title text: "This is the reference implementation of the self-referential joke."}}









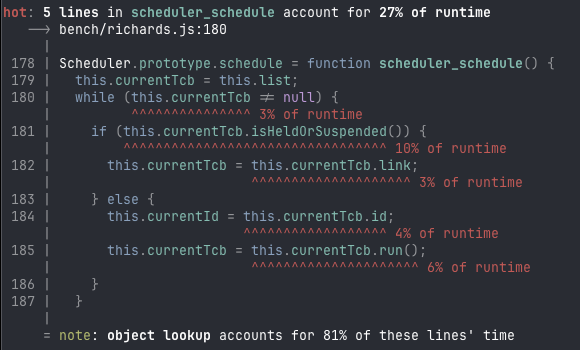
ALT Terminal screenshot: hot: 5 lines in scheduler_schedule account for 27% of runtime --> bench/richards.js:180 | 178 | Scheduler.prototype.schedule = function scheduler_schedule() { 179 | this.currentTcb = this.list; 180 | while (this.currentTcb != null) { | ^^^^^^^^^^^^^^^ 3% of runtime 181 | if (this.currentTcb.isHeldOrSuspended()) { | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 10% of runtime 182 | this.currentTcb = this.currentTcb.link; | ^^^^^^^^^^^^^^^^^^^^ 3% of runtime 183 | } else { 184 | this.currentId = this.currentTcb.id; | ^^^^^^^^^^^^^^^^^^ 4% of runtime 185 | this.currentTcb = this.currentTcb.run(); | ^^^^^^^^^^^^^^^^^^^^^ 6% of runtime 186 | } 187 | } | = note: object lookup accounts for 81% of these lines' time