
Co-Founder at calliora
Joined October 2020
- Tweets 64
- Following 224
- Followers 243
- Likes 158
11 Photos and videos





18 Jul 2025
Check out this exciting work, led by the exceptional @FrederikeLubeck if you are at ICML 2025!
18 Jul 2025

Clinical notes are messy, inconsistent, and unstructured—yet they hold some of the most valuable signals in real-world clinical practice.
Join us today at ICML at the Foundation Models for Structured Data workshop to see how we can make sense of these notes!
📍 West Ballroom D

4
314
1 Mar 2025
Easily one of the biggest and most fascinating projects I’ve ever worked on—huge thanks to @schwabpa and the whole team for having me and the opportunity to collaborate during my time @GSK. Check out all the details in this summary!
Preprint: arxiv.org/abs/2501.07737
27 Feb 2025

Understanding human biology across scales - from molecules to cells to entire organisms - remains one of biomedicine's greatest challenges in the fight against disease.
Today, we are announcing Phenformer - a multi-scale genetic language model that learns to read and interpret human genomes by connecting DNA, cell and tissue context, molecules and clinical outcomes.
Phenformer is a generative model of molecular mechanisms that enables researchers to unravel the mysteries underlying disease, and could thereby accelerate the development of precise future therapeutics.

1
6
20
2,260
Frederik Träuble retweeted

11 Dec 2023
Unlearning via Sparse Representations
Work with @f_traeuble, Ashish Malik, @hugo_larochelle, @MichaelMozer1, @prfsanjeevarora, Yoshua Bengio & @anirudhg9119
arxiv.org/abs/2311.15268
TLDR: We propose a new approach enabling nearly compute-free class unlearning. 🧵

1
4
37
5,194
Frederik Träuble retweeted

17 Apr 2023
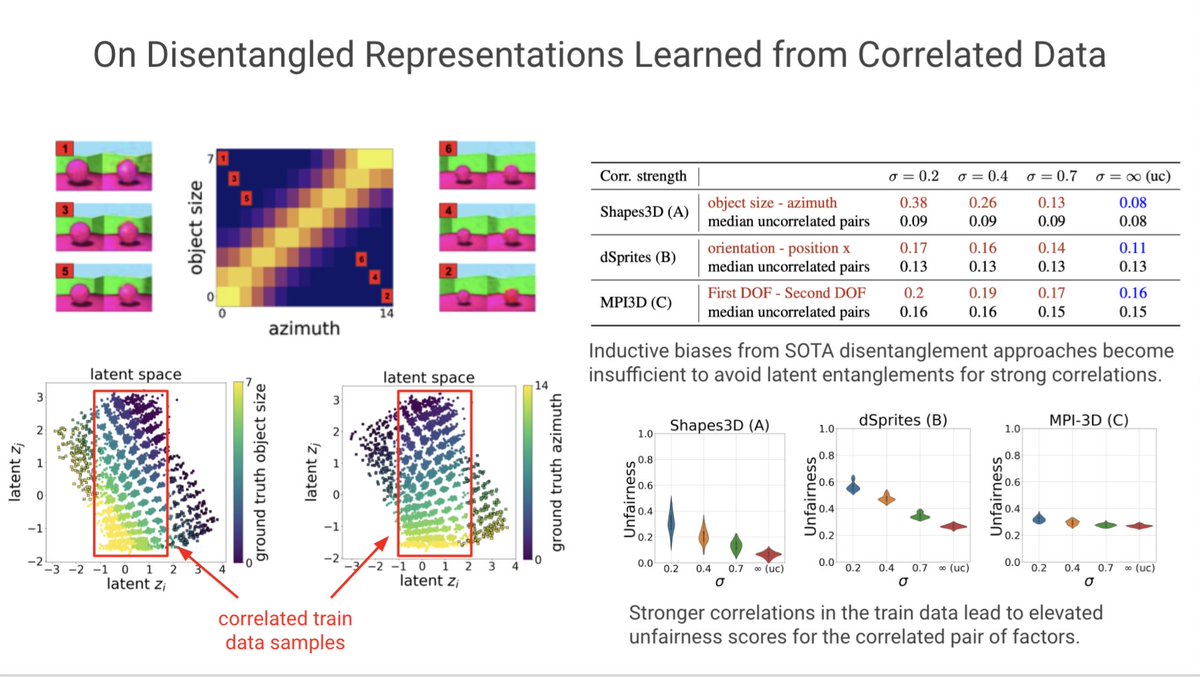
Introducing our #ICLR2023 paper:
DCI-ES: An Extended Disentanglement Framework with Connections to Identifiability🚀
We propose a new notion of disentanglement based on the functional capacity required to use a representation
arxiv.org/abs/2210.00364
github.com/andreinicolicioiu…
1/12

1
8
47
13,172
Frederik Träuble retweeted

1 Mar 2023
Creating a map of gene interactions is a fundamental step in drug discovery that generates ideas on what mechanisms may be targeted by future medicines
Today, we announce the CausalBench challenge at gsk.ai/causalbench-challenge… and invite you to contribute to this important problem!

2
9
40
6,867
Frederik Träuble retweeted

16 Feb 2023
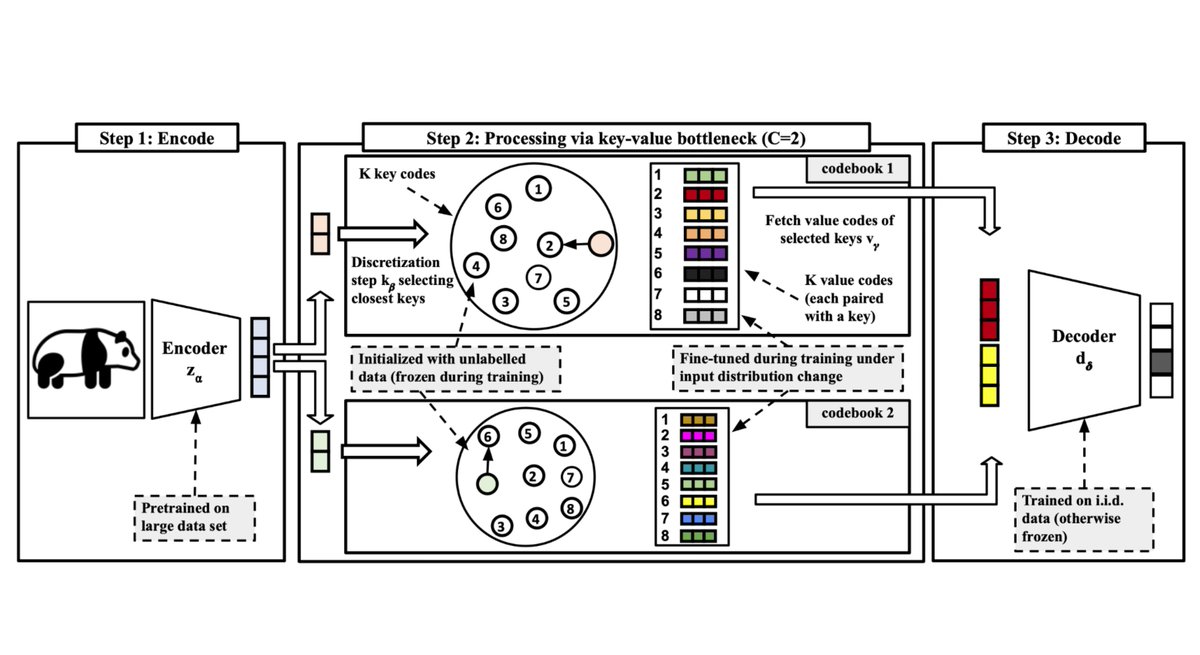
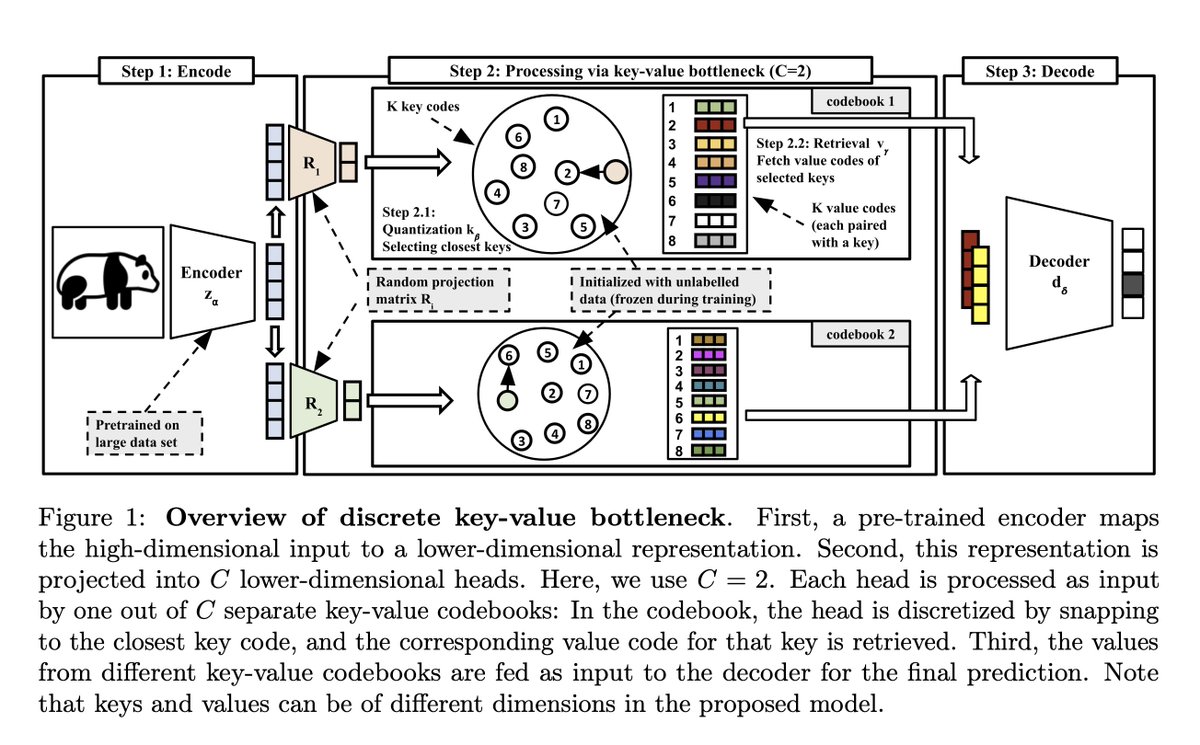
Discrete Key-Value Bottleneck (Updated)
Compresses the information of a pre-trained model in learnable "key-value" codebook such that knowledge can be quickly adapted in a continual learning fashion.
arxiv.org/abs/2207.11240
2
23
103
16,649
Frederik Träuble retweeted

19 Dec 2022
Many countries employed an age-ranked vaccine allocation strategy to combat COVID-19. How effective was this strategy at preventing infections and severe cases? We study this and other questions using simulation-assisted causal modelling. 🧵 1/
preprint: bit.ly/3Wc37Ww

2
18
56
17,489
Frederik Träuble retweeted

18 Oct 2022
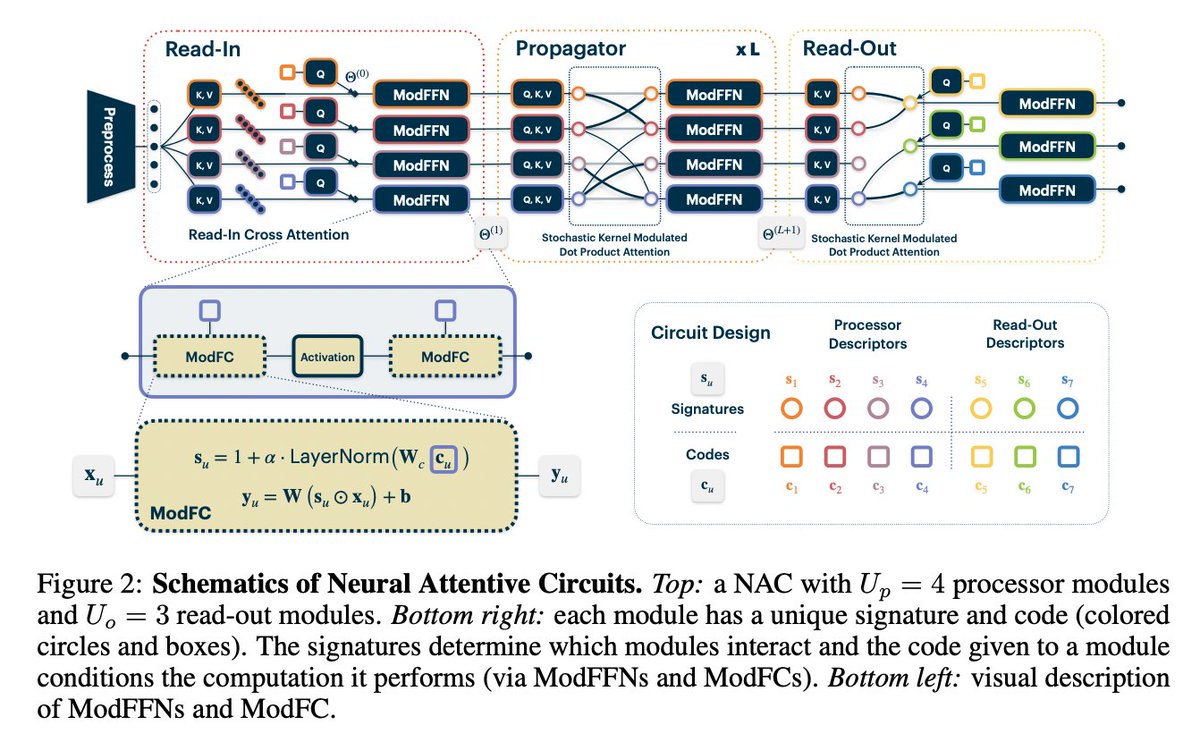
🥁We raise you Neural Attentive Circuits, a general-purpose modular neural architecture.
With Martin Weiss (co-lead), @FrancescoLocat8, @chrisjpal, Yoshua Bengio, @bschoelkopf, Erran Li & Nicolas Ballas. @Mila_Quebec @MPI_IS @MetaAI @AmazonScience
arxiv.org/abs/2210.08031
🧶
2
26
129
Frederik Träuble retweeted

Only 1 week left until the 1st Workshop on Causal Representation Learning at @UncertaintyInAI
Lists of accepted papers & reviewers, additional information on how to attend, and a detailed schedule incl. speakers are now available on the workshop website: crl-uai-2022.github.io/

21
106
25 Jul 2022
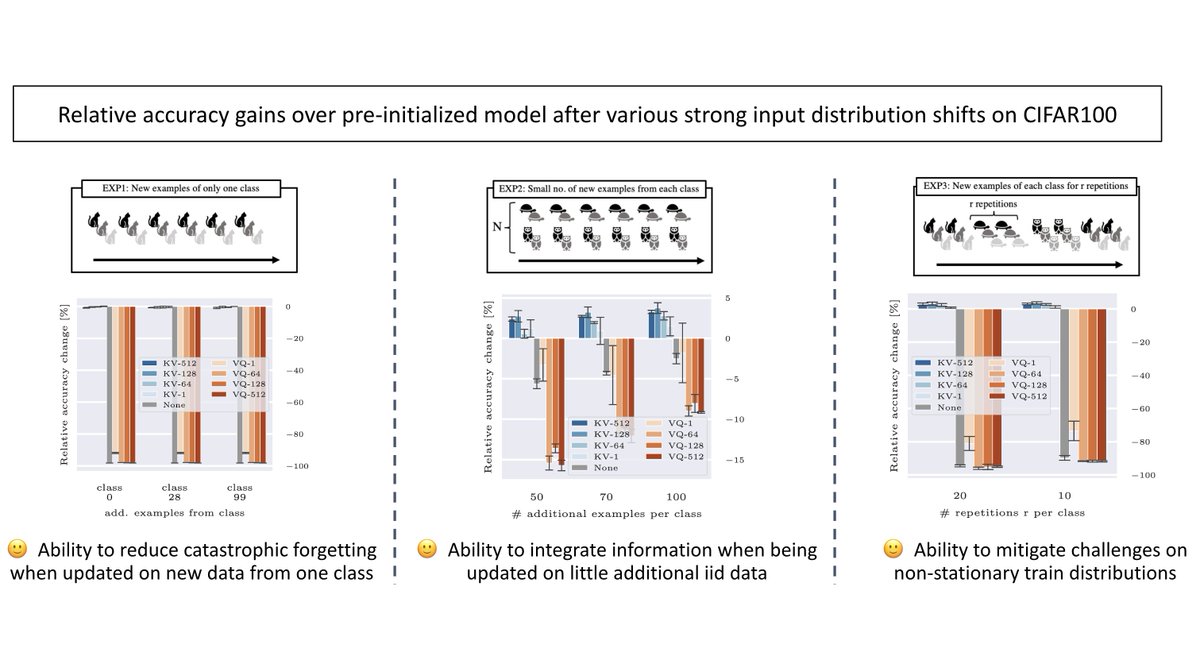
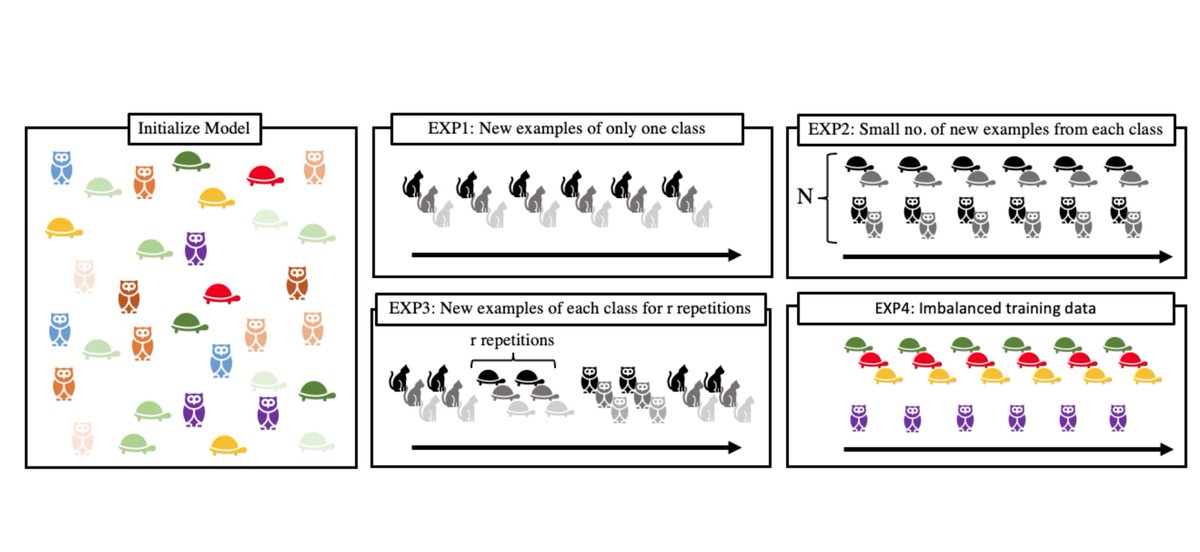
“Discrete Key-Value Bottlenecks”
Amortizing information via a discrete bottleneck such that the knowledge is localized and results in flexible adaptation to distribution shifts such as non-stationary or imbalanced data streams.
arxiv.org/abs/2207.11240
1/6
4
12
91
25 Jul 2022
By freezing all model parameters except for the value codes, we can keep learning under various distribution shifts. This is enabled via localized, input-dependent model updates, which don't affect the prediction from (key, value) pairs retrieved from unalike train samples.
5/6
1
4
25 Jul 2022
Most importantly, this is joint work and wouldn’t have been possible without fantastic co-authors @anirudhg9119 @nasim_rahaman @mc_mozer Kenji Kawaguchi, Yoshua Bengio, @bschoelkopf.
@MPI_IS @Mila_Quebec
Any feedback is much appreciated.🙂
6/6
3
Frederik Träuble retweeted
21 Jul 2022
Look forward to presenting our work! 🚀
We connect the DCI disentanglement scores to identifiability, and propose a new complementary notion of disentanglement based on the *functional capacity required to use a representation.*
🔗openreview.net/pdf?id=KiMUlK…
🧵Short thread below

Decisions and meta-reviews are now available---thanks to all reviewers!
See you in ~1 month in Eindhoven for some hopefully stimulating discussions around causal representation learning.
Please remember to register for @UncertaintyInAI if you plan to attend the workshop.
1
10
31
2 Feb 2022
Check out our latest work if you have ever struggled with learning RL agents that can solve dexterous object-manipulation tasks in multi-object robotics settings! 🤖
arxiv.org/pdf/2201.13388.pdf
Joint work with @mambelli_davide, Stefan Bauer, @bschoelkopf and @FrancescoLocat8
2 Feb 2022

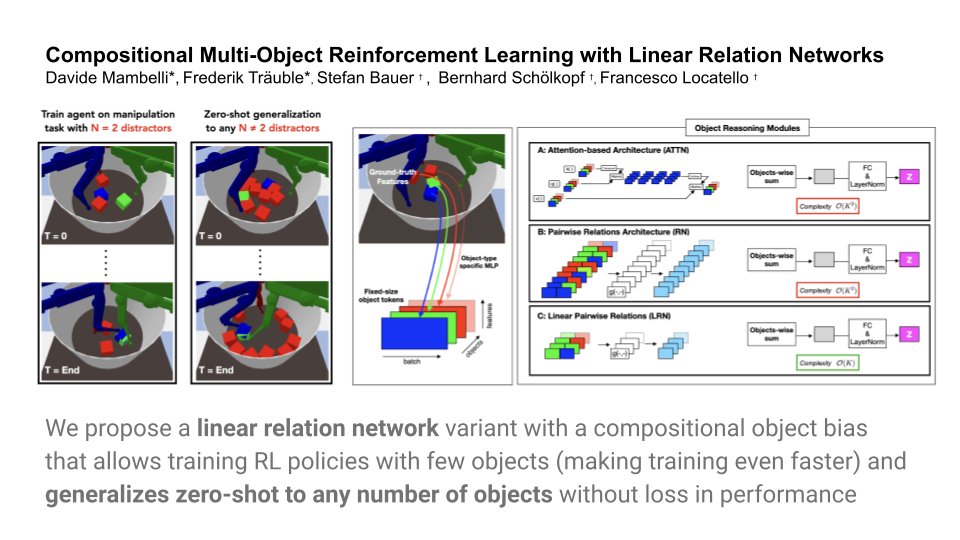
"Compositional Multi-Object Reinforcement Learning with Linear Relation Networks": new module with linear cost and an object-centric compositional bias for training RL policies that generalize zero shot to arbitrary number of objects in robotics. [1/2]
arxiv.org/pdf/2201.13388.pdf
1
5
26
Frederik Träuble retweeted

28 Jan 2022
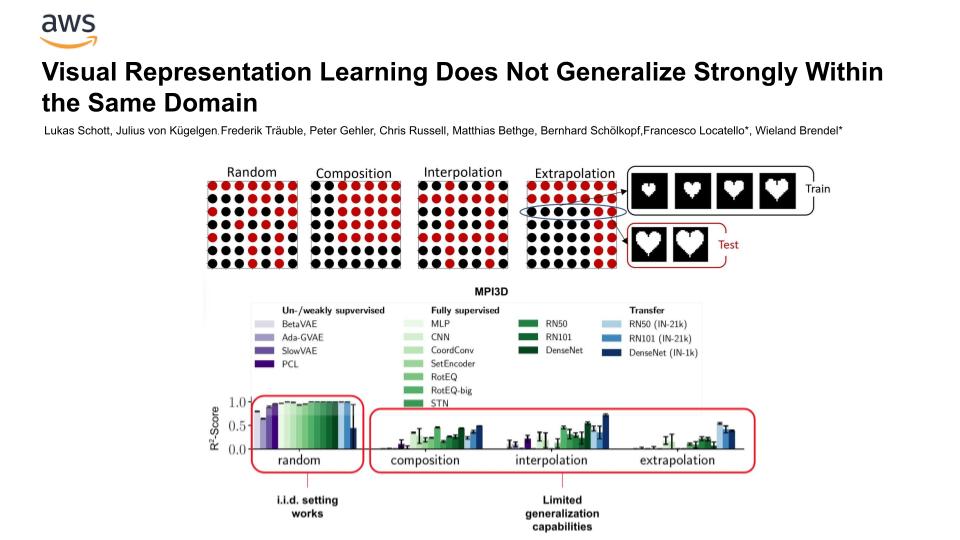
“Visual Representation Learning Does Not Generalize Strongly Within the Same Domain”: regardless of architecture and training signal, deep nets struggle to generalize strongly to existing factors of variation in the training data.
arxiv.org/abs/2107.08221
1
4
18
24 Jan 2022
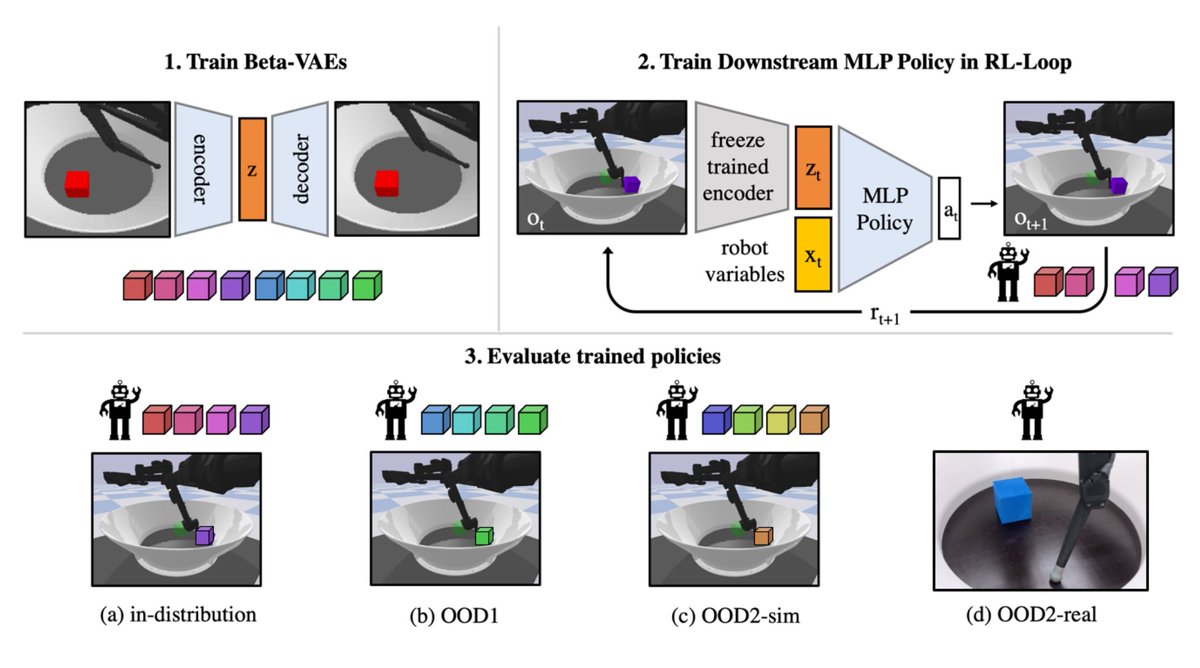
Happy to share that our work on "The Role of Pretrained Representations for the OOD Generalization of RL Agents" was accepted to #iclr2022! 🎉
15 Jul 2021

Happy to announce our large-scale study on representation learning and generalization in reinforcement learning! arxiv.org/abs/2107.05686
How do properties of pre-trained representation backbones affect the robustness of downstream RL policies in simulation and real world?
1/5

1
5
53
Frederik Träuble retweeted

21 Jan 2022
My recent talk at the NSF town hall focused on the history of the AI winters, how the ML community became "anti-science," and whether the rejection of science will cause a winter for ML theory. I'll summarize these issues below...🧵


25
197
843