
Research Scientist, Google Brain now DeepMind. Training neural nets since 1979.
Joined January 2022
- Tweets 26
- Following 170
- Followers 828
- Likes 34
7 Photos and videos


Michael C. Mozer retweeted

Apr 8
New preprint: The Self Requires Learning. Self-consciousness requires continual learning world-modeling. I introduce "bounded integration" to connect perspective, identity, and self-representation — and diagnose what current AI systems have and lack.

14
73
414
50,894

Apr 21
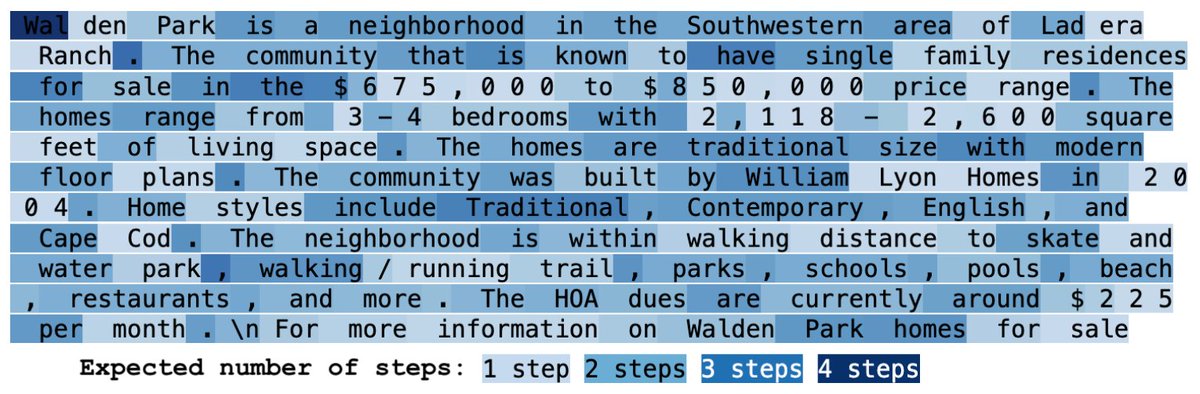
[1/5] Intelligent behavior relies on maintaining an evolving, dynamic model of the environment. But even frontier models sometimes fail at tracking state in dialogs, e.g., actual transcript from 4/20/2026:
3
12
54
9,465
Apr 21
[4/5] Recurrence is an obvious solution, but the literature often conflates qualitatively different varieties of recurrence in transformers, some of which enable indefinite state tracking and others (particularly, variants of looped transformers) do not.
1
10
617
Apr 21
[5/5] We introduce a taxonomy of recurrent models defined by their recurrence axis and their ratio of input tokens to recurrence steps. The next generation of efficient foundation models need to bridge the gap between a transformer's parallelism and the brain's dynamical nature.
13
473
Michael C. Mozer retweeted

24 Dec 2025
Posted this a day early and the pun practically writes itself. Noooooo!
24 Dec 2025

Our new paper shows that RoPE—the positional encoding used in most modern LLMs like Qwen, Gemma, DeepSeek—has a fundamental flaw: it entangles "what" (content) and "where" (position) information.
Our fix (PoPE) is simple but powerful. Paper: arxiv.org/abs/2509.10534
1
2
11
2,328
17 Oct 2025
[1/4] As you read words in this text, your brain adjusts fixation durations to facilitate comprehension. Inspired by human reading behavior, we propose a supervised objective that trains an LLM to dynamically determine the number of compute steps for each input token.
4
10
28
3,257
17 Oct 2025
[4/4] Details and results found at arxiv.org/abs/2510.13879 (Catch Your Breath: Adaptive Computation for Self-Paced Sequence Production). Joint work with @agalashov , @rosemary_ke, @caoyuan33, @_vaishnavh, and Matt Jones.
6
397
17 Oct 2025
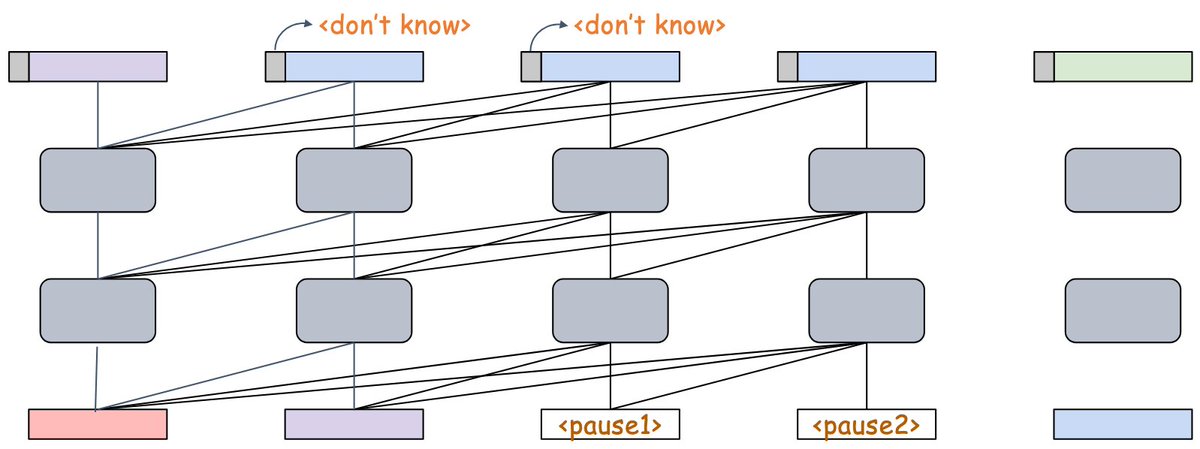
[3/4] To train the model to calibrate its uncertainty and use <don't know> outputs judiciously, we frame the selection of each output token as a sequential-decision problem with a time penalty. We refer to the class of methods as “Catch Your Breath” losses.
5
283
17 Oct 2025
[2/4] The model can request additional compute steps for any token by emitting a <don't know> output. If the model is granted a delay, a <pause> token is inserted at the next input step, providing the model with additional compute resources to generate an output.
4
264
Michael C. Mozer retweeted

10 Oct 2025
Happy to announce that our work has been accepted to workshops on Multi-turn Interactions and Embodied World Models at #NeurIPS2025! Frontier foundation models are incredible, but how well can they explore in interactive environments?
Paper👇
arxiv.org/abs/2412.06438
🧵1/13
1
6
24
7,360
Michael C. Mozer retweeted

26 Sep 2025
🌟To appear in the MechInterp Workshop @ #NeurIPS2025 🌟
Paper: arxiv.org/abs/2509.04466
How do language models (LMs) form representation of new tasks, during in-context learning? We study different types of task representations, and find that they evolve in distinct ways.
🧵1/7

1
14
111
20,093
Michael C. Mozer retweeted

3 Jun 2025
[📜9/9] Check out our paper for more details.
Paper: arxiv.org/abs/2505.22310
Code: github.com/shoaibahmed/visio…
1
7
427
Michael C. Mozer retweeted
3 Jun 2025
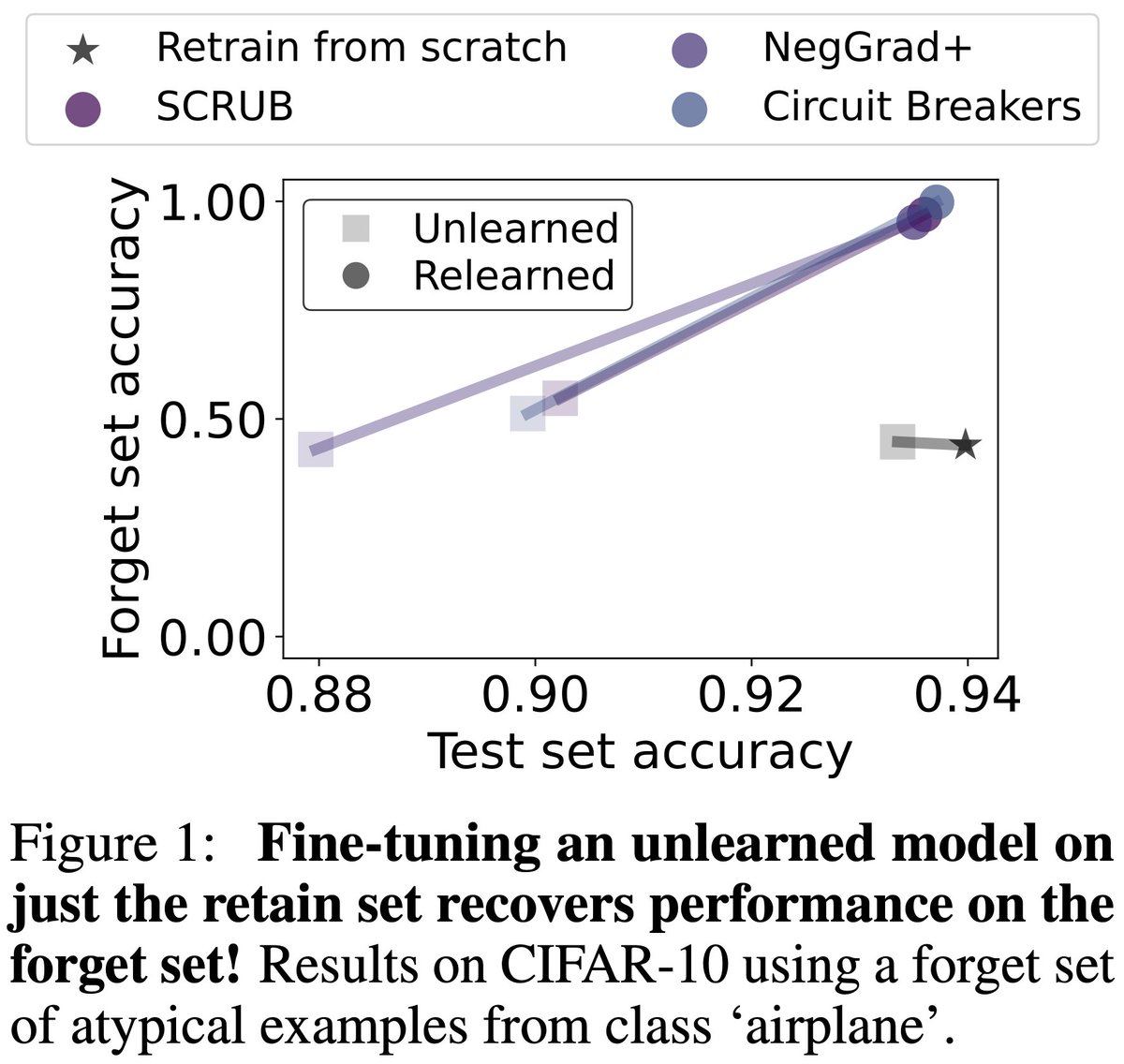
[📜1/9] Does machine unlearning truly erase data influence? Our new paper reveals a critical insight: 'forgotten' information often isn't gone—it's merely dormant, and easily recovered by fine-tuning on just the retain set.
2
10
51
7,843
Michael C. Mozer retweeted

10 Dec 2024
We are announcing the launch of Airial Travel’s open-to-all beta version for desktop today. Airial is your personal travel agent with AI superpowers which makes planning and booking trips as easy as dreaming them up. airial.travel
Me and Sanjeev co-founded Airial Travel a year ago to solve a problem we faced repeatedly. Being avid travelers living in the US with our families in India, we were traveling for several months a year and spending multiple days planning and booking each trip. Hours and hours of research, browsing, watching videos, form-filling, spreadsheets, refinements etc. At the end of the process in most cases, we just booked because we were exhausted and wanted to get it over with. As we talked to people and read up about this, we realized that the scale and the intensity of this problem is stunning - hundreds of millions of trips are booked online every year and planning each of them takes over five hours on average.
Our vision “Just imagine your trip, and Airial it!” stems from our ultimate wish as travelers - AI that can figure out all the intricacies of trip planning for you - hotels, activities, flights, trains, transits, deals, date options, restaurants, interests, research, travel videos and everything else.
Our defining features originate from the core beliefs that Airial is built on:
📅 Detailed intricately crafted plans: Attention to detail makes trip plans incredible. Airial plans trips in a level of detail that is simply unmatched, taking care of hundreds of common sense constraints across thousands of variables in seconds.
🚀 From Reels to Itineraries: TikTok / IG reels to Trips is work that millions do manually. We now enable all this in a click. This is the intersection of the two big trends in travel - AI and Socials.
🏖️ Personalized Planning: Travel portals today are one-size-fits-all. We plan trips tailored to your specific interests - architecture tours, scenic hikes or samurai sword fighting lessons!
👆 Actionable Itineraries: Just having a chatbot pick out one combination for you isn’t practically useful. Which was the last trip you planned that didn’t need any refinement? Every decision Airial makes for you is changeable via chat or UI controls.
🌎 Discovery in context: As you plan your trip, Airial gives you the tools to discover incredible ideas and expert advice specific to your itinerary and interests which can be instantly imported into your trip.
Now you can “Just imagine your trip and Airial it!”.
Try it out now on your laptop at airial.travel!
9
11
45
5,847
Michael C. Mozer retweeted
29 Oct 2024
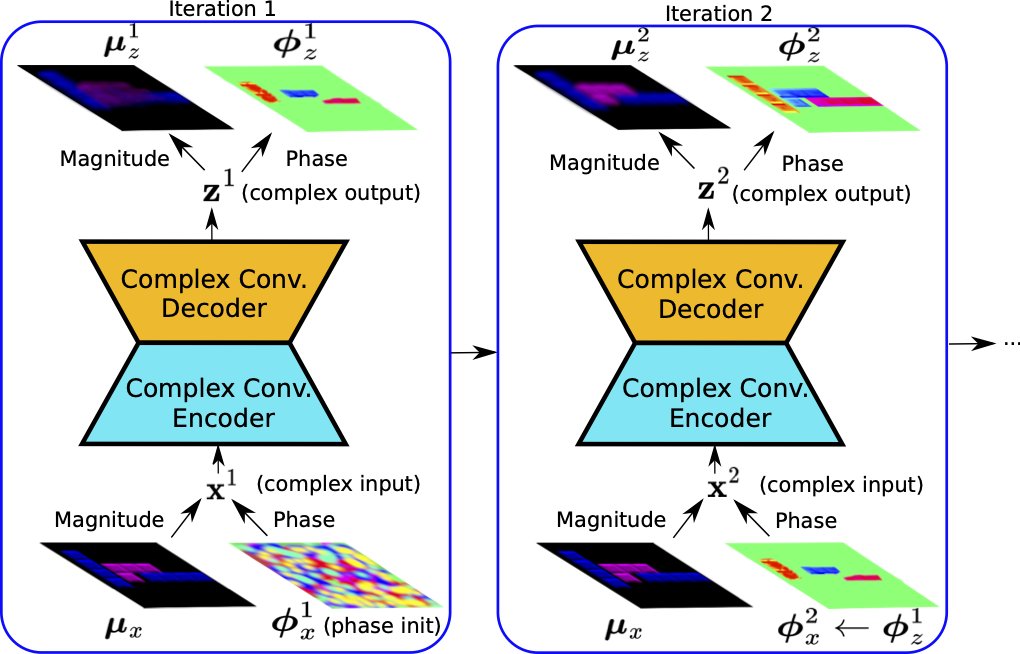
Excited to present "Recurrent Complex-Weighted Autoencoders for Unsupervised Object Discovery" at #NeurIPS2024!
TL;DR: Our model, SynCx, greatly simplifies the inductive biases and training procedures of current state-of-the-art synchrony models. Thread 👇 1/x.
2
39
159
19,391
Michael C. Mozer retweeted

14 Oct 2024
The ability to properly contextualize is a core competency of LLMs, yet even the best models sometimes struggle. In a new preprint, we use #MechanisticInterpretability techniques to propose an explanation for contextualization errors: the LLM Race Conditions Hypothesis. [1/9]

5
15
104
14,856
Michael C. Mozer retweeted
20 Mar 2024
🔍 New LLM Research 🔍
Conventional wisdom says that deep neural networks suffer from catastrophic forgetting as we train them on a sequence of data points with distribution shifts. But conventions are meant to be challenged!
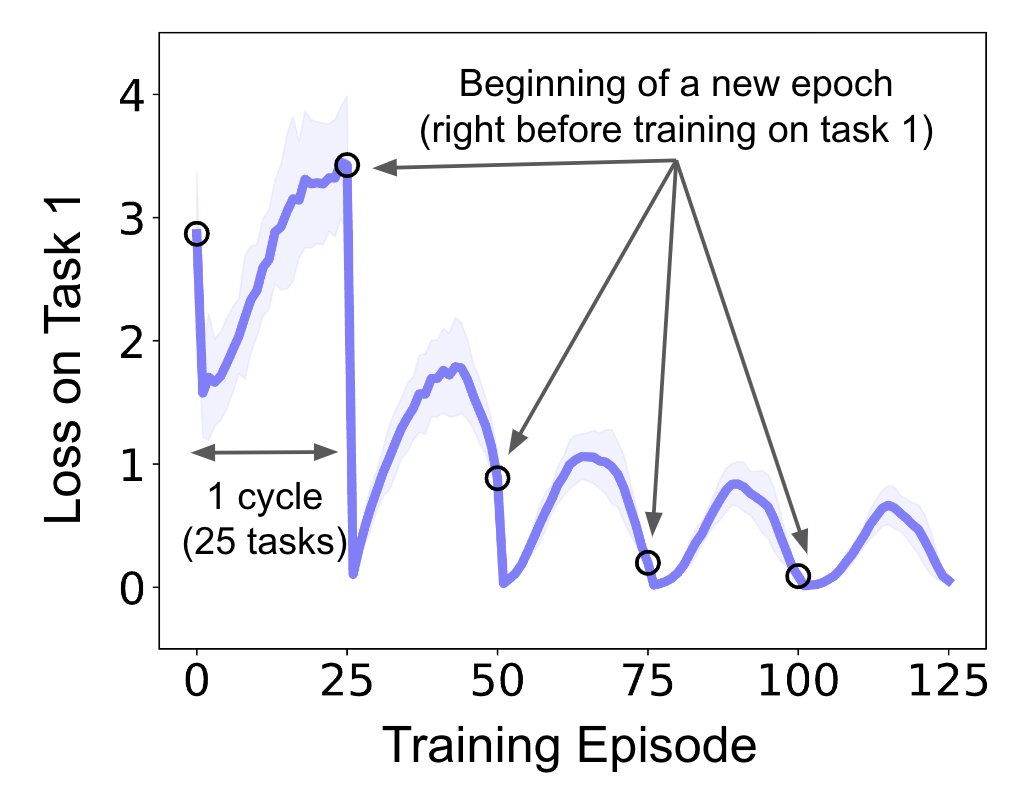
In our recent paper led by @YanlaiYang, we discovered a curious behavior in overparameterized networks, especially LLMs—as we train the network on a cyclic sequence of documents, it starts to anticipate the next document and reverses the forgetting trend! ⤴️
▶️ After 3-4 cycles, the network reverses over 90% of the forgetting right before seeing the original document again.
▶️ The amount of anticipation emerges with the size of the network. LLMs <= 160M show no anticipation.
▶️ We showed that you can reproduce such an effect in a toy network!
Check out more details in our arXiv preprint on anticipatory recovery:
Reawakening knowledge: Anticipatory recovery from catastrophic interference via structured training.
🚀 arxiv.org/abs/2403.09613 🚀
#LLM #AI #Research

3
39
214
28,021
Michael C. Mozer retweeted

16 Aug 2023
Nature Comms paper: Subtle adversarial image manipulations influence both human and machine perception! We show that adversarial attacks against computer vision models also transfer (weakly) to humans, even when the attack magnitude is small. nature.com/articles/s41467-0…
12
87
381
84,045