
Fairwinds provides Managed Kubernetes-as-a-Service & open source software to enable organizations to run & optimize mission-critical Kubernetes infrastructure
Joined January 2015
- Tweets 3,271
- Following 764
- Followers 1,390
- Likes 701
555 Photos and videos














Jun 12
How to limit blast radius from a security incident: separate high-sensitivity systems from internal tooling at the infrastructure level.
A credential that only works in one environment can't travel into another. Topology bounds the damage.
Learn more:
bit.ly/4crYi6b
12
Jun 11
Kubernetes itself isn't expensive. Rising costs usually stem from large on‑demand nodes at 20–40% utilization, pods that request 2–3x what they use, and clusters that never scale down from peak.
Here are some times to doing right‑sizing right: hubs.li/Q04l4F0F0 #k8s #cost
29
Jun 11
At KubeCon EU, SRE Stevie Caldwell tried something odd: cluster events as audio, audience eyes closed.
People could call out pod created, pod deleted, and deployment scaling just from what they heard.
The write up is here:
bit.ly/4nbTCoF
#Kubernetes #SRE #Monitoring
10
Jun 10
Quick GPU sanity check: utilization stuck under 30 percent, pods asking for a full GPU but barely using VRAM, and nodes online all night.
If that sounds familiar, this guide gives some concrete fixes & best practices:
bit.ly/3RydEhd
#FinOps #Kubernetes #AI
13
Jun 9
Platform team getting “just run the LLM on the cluster” requests? At AWS Community Day Midwest, Fairwinds’ Stevie Caldwell (SRE Tech Lead) Andy Suderman (CTO) share a practical path for inference on EKS, with a reliability lens.
bit.ly/4nNPZFz
#AWSCommunityDay #EKS
1
1
71
Jun 5
Most production clusters share the same weak spots: outdated Helm charts, unclear image tags, and ad hoc policies. This piece explores7 focused questions to keep clusters stable across apps, data, and more. Learn more:
bit.ly/49rUtf8
#Kubernetes #PlatformEngineering
7
Fairwinds retweeted

Jun 3
How does @OpenAI scale deep learning? They use Kubernetes to spin up hundreds of GPUs in days instead of months.
Read the case study:
cncf.io/case-studies/openai/
Want to showcase your own cloud native success? Enter the CNCF Case Study Contest by June 11 to win a KubeCon CloudNativeCon Japan keynote slot:
surveymonkey.com/r/MB9VVVZ

1
2
24
1,889
Fairwinds retweeted
Jun 4
🎤 Have insights to share with the #CloudNative community?
Submit to speak at any of the 10 CNCF-hosted Co-located Events taking place alongside #KubeCon #CloudNativeCon North America in Salt Lake City on November 9.
⏰ #CFP closes Sunday, June 21: events.linuxfoundation.org/k…
3
10
1,124
Fairwinds retweeted
Jun 5
What’s actually changing in Cloud Native AI right now? 4 major signals from the field:
1. NVIDIA donated its GPU DRA driver to CNCF
2. Kubernetes AI Conformance nearly doubled
3. The stack is consolidating around core projects
4. OpenTelemetry graduated, making observability a pillar
Full breakdown: linkedin.com/pulse/what-im-r…

1
5
23
2,008
Jun 5
Kubernetes skills don’t transfer 1:1 to LLM inference.
This post breaks down tokenization, pre-fill, decode as 3 different stages, and shows why pods that take 15–30 minutes to load weights change how you think about failures scaling.
bit.ly/4uh41kC
#k8s #LLM #MLOps
14
Jun 3
If every AI pod requests bit.ly/4uSO0SS: 1 and uses a fraction of it, you are paying for idle silicon. The article shows when whole GPUs are fine, and when MIG or time slicing actually reduce waste without breaking latency:
bit.ly/4dwgBHX
#AIInfra #Kubernetes
20
Jun 2
Running AI on Kubernetes is more than adding GPU nodes.
You need:
> GPU aware scheduling
> Patterns for training vs inference
> Guardrails so one model can’t break prod
This post digs into what AI ready Kubernetes actually requires:
bit.ly/3RDrhMa
#K8s #AIInfrastructure
24
Jun 1
AWS Community Day | Midwest is June 24 in Indianapolis. Fairwinds’ Stevie Caldwell (SRE Tech Lead) Andy Suderman (CTO) are speaking on running LLM inference on Kubernetes with EKS. Worth a look if you own platform/SRE.
bit.ly/4uEfUlO
#AWS #AWSCommunityDay #k8s #LLM
24
May 29
Next time you hit CrashLoopBackOff, skip the panic and random kubectl commands. We broke down exactly how to troubleshoot it methodically and efficiently so you can resolve it fast and get back to building.
bit.ly/4w0INd1
#Kubernetes #CloudNative #DevOps
1
1
26
May 28
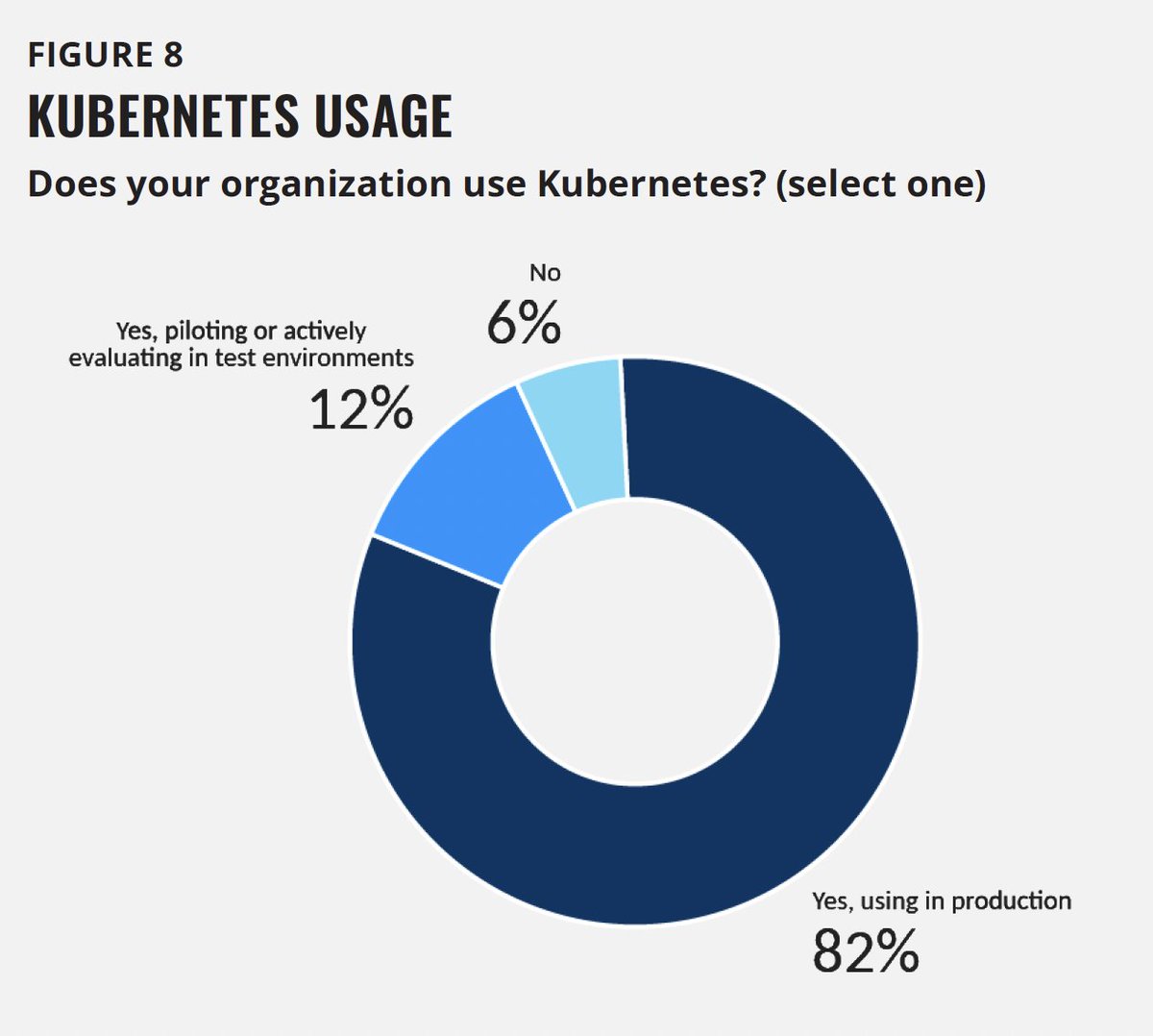
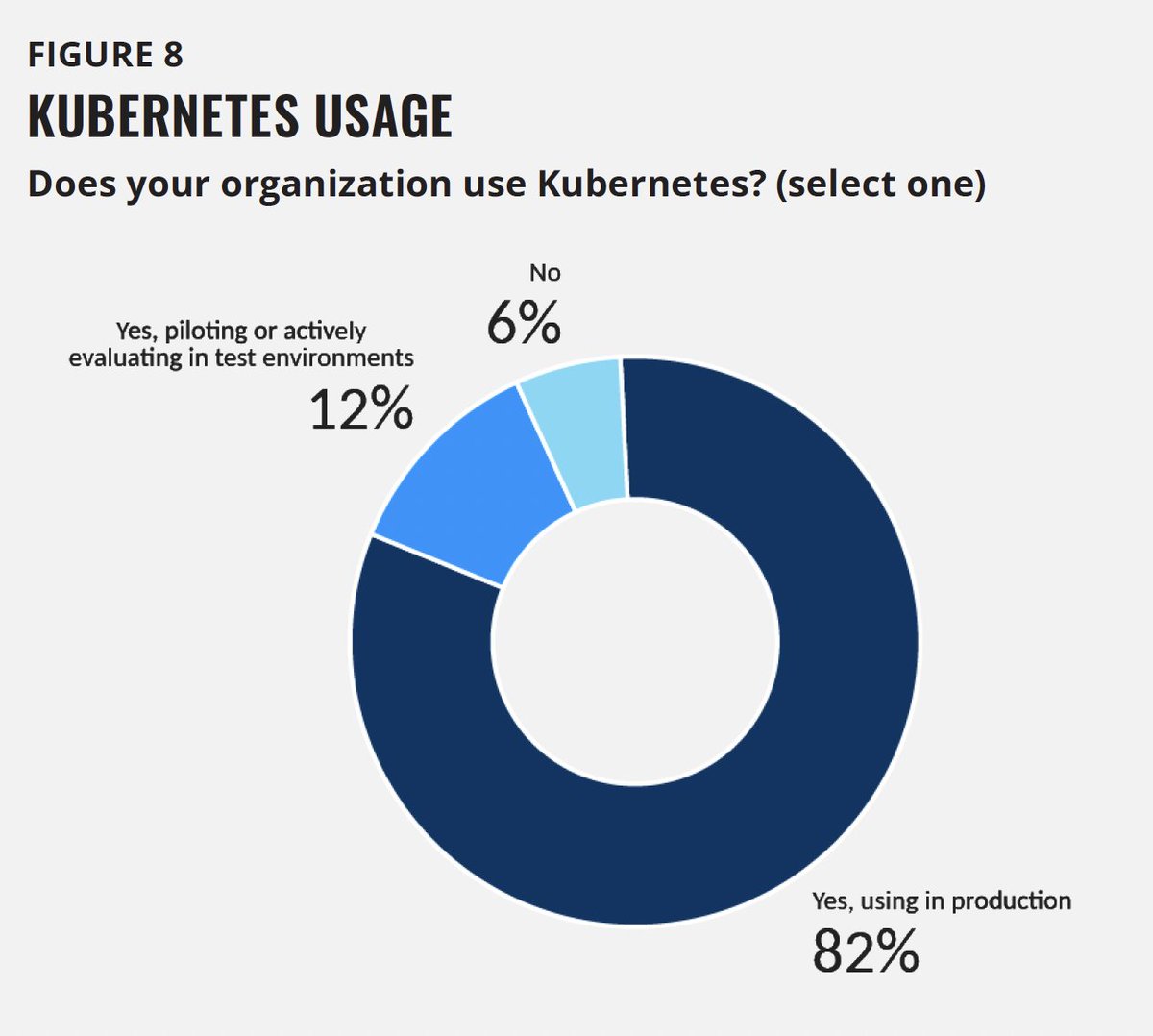
Kubernetes has become the backbone of production: 82% of container users now run it in production and 94% are running, piloting, or evaluating it, according to the latest CNCF survey. The challenge is operating it well at scale.
bit.ly/4sxu6em
#Kubernetes #CloudNative
15
May 28
AI infrastructure conversations often end in the same place: the Kubernetes platform.
Teams want one place to run services, data pipelines, and GPU workloads with shared guardrails, not a separate AI stack.
Here’s how that’s playing out :
bit.ly/4tYc85L
#k8s #AI #MLOps
16
May 27
One reason the Trivy attack worked because version tags were mutable. Attackers overwrote known-good binaries after the fact.
Immutable tags make that impossible. Pin to a version, it stays there.
Learn more ways to shrink your exposure:
bit.ly/3QC7OuM
#k8ssecurity
1
1
17
May 26
Dashboards show what your cluster is doing. This experiment asks what happens if you listen instead.
A Go controller, OSC, and SuperCollider turn Kubernetes events into sound so you can hear pod creates, deletes, and scaling.
bit.ly/4eY4cxm
#KubeCon #DevOps #SRE
26
May 25
#Kubernetes was supposed to help with efficiency, yet the cloud bill keeps climbing. Labels, requests, idle nodes, and autoscaling policies decide who pays and how much. This post outlines the questions teams use to untangle spend (and more). Learn more:
bit.ly/3PoKSii
21
May 22
Kubernetes gives you graphs and logs. This project asks what happens if you turn events into sound instead.
A small controller watches pod and deployment events, sends them over OSC, and lets SuperCollider handle the rest.
Details:
bit.ly/42htzmf
#KubeCon #DevOps #Infra
19