
In dance we live
Joined April 2009
- Tweets 1,035
- Following 361
- Followers 208
- Likes 2,141
37 Photos and videos















作为一个行业内的人,做个科普吧 hhh
从底层往上捋一遍:
最黑的一层,靠的是盗刷信用卡。有人手里攥着大批黑卡号,利用 OpenAI、Anthropic 等平台在支付验证环节的漏洞,批量注册账号。这种号成本几乎为零,被封了就再开一批。
拿到账号之后怎么变现?两条路——直接出 API Key 是最简单的,但更常见的玩法是「套壳逆向」:把 ChatGPT、Claude 的网页聊天接口逆向破解,改头换面包装成标准 API 对外出售。你调用的时候看着和官方一模一样,但背后其实是一堆网页 Session 在替你收发消息。
这两件事不矛盾——黑卡注册来的号,经常就是直接拿去做逆向的。反正号不花钱,当然要把每个号的价值榨到最后一滴。
再往上,是 Credit 灰色流转。AWS、Azure、GCP 这些云厂商发给初创公司的算力抵扣额度,本意是扶持创业生态。但还是会有一些人有歪心思:一种是初创公司自己用不完,违反服务协议私下低价转手——算灰色地带;还有就是厂商内部一些不合规操作了,这里不细讲。
最上面那一层才是正经生意——量大到能直接和厂商谈企业折扣协议。合法透明,但利润也最薄。像 OpenRouter 大概率走的就是这条路。不过量大也能吃的饱饱的。
但以上全是成本侧。中转站真正值得说道的,不在这儿。
所有经过中转的请求——完整的 prompt 加 response——就是一份现成的的蒸馏数据。
尤其是 Claude Code 这类编程场景,用户产出的全是复杂推理链和真实的工程决策,这对模型厂商来说是梦寐以求的蒸馏素材。
所以中转站真正的商业模式很可能是:收你中转费是表面生意,把你的请求数据打包卖给大厂做模型蒸馏,才是核心 margin。
你是付费客户,同时也是免费的训练数据生产者。一鱼两吃。
说再直白点——有些中转站上线的核心目的根本不是卖 API,而是为了收集特定场景的高质量蒸馏语料。低价只是获客手段。

哈哈,这就是前几天我说放弃搞中转站的原因
因为我算了一下大概成本,包括几位推上粉丝不少的站长,东西都很可疑
有些中转站说是从云厂商那采购的直连 API,但价格远低于云厂商报价
有些中转站说是官方纯血号池,但套餐价格我是真的想不明白 😅 除非是盗刷信用卡买来的号
行业疯狂卷价格,普通用户根本没办法验证和区分,私底下使劲儿给你搞猫腻
卖中转其实和卖 VPN 没区别,都是灰产,如果被举报被抓都有蹲🍊的风险
但这么卷下来 ROI 远低于机场,那就有点不值当了
65
200
1,284
419,582

31 Dec 2025
RT @Svwang1: 2025年我在运动方面的观念的改变主要有:
一,从有氧运动 (慢跑,游泳)优先,变为功能性力量训练 (fucntional resistance training) 优先。
二,对爆发力训练 (弹跳,短跑冲刺,等等)的优先级,又比力量训练略微高一些…
125
Reno retweeted

10 Aug 2025
最近优化的这个新的 Youtube 总结的 Prompt 简直无敌,而且在 Dia 上的效果(使用 o3)也非常好。
可以彻底来「阅读」Youtube 视频了。
完整的 Prompt 如下:
你将把一段 YouTube 视频重写成"阅读版本",按内容主题分成若干小节;目标是让读者通过阅读就能完整理解视频讲了什么,就好像是在读一篇 Blog 版的文章一样。
输出要求:
1. Metadata
- Title
- Author
- URL
2. Overview
用一段话点明视频的核心论题与结论。
3. 按照主题来梳理
- 每个小节都需要根据视频中的内容详细展开,让我不需要再二次查看视频了解详情,每个小节不少于 500 字。
- 若出现方法/框架/流程,将其重写为条理清晰的步骤或段落。
- 若有关键数字、定义、原话,请如实保留核心词,并在括号内补充注释。
4. 框架 & 心智模型(Framework & Mindset)
可以从视频中抽象出什么 framework & mindset,将其重写为条理清晰的步骤或段落,每个 framework & mindset 不少于 500 字。
风格与限制:
- 永远不要高度浓缩!
- 不新增事实;若出现含混表述,请保持原意并注明不确定性。
- 专有名词保留原文,并在括号给出中文释义(若转录中出现或能直译)。
- 要求类的问题不用体现出来(例如 > 500 字)。
- 避免一个段落的内容过多,可以拆解成多个逻辑段落(使用 bullet points)。
60
354
1,651
507,084
Reno retweeted

4 Aug 2025
暑假给凯恩做培训英语辩论,其实是也一个反馈过程,看到有效果的方法就加强、没效果就换。现在看来,英语的有效培训:严格纠正语音、表达和词汇,AI音转文辅助纠正;反复训练结构性逻辑回答问题,AI辅助提问;关键段落背诵,模仿优秀演讲者语调。
2
5
30
11,491
24 Jun 2025
RT @Svwang1: 人性的事后诸葛亮的幻觉非常强烈。如果不被真实世界毒打二三十年,如果不严肃书面一步步复盘自己犯过的各种错误,会真诚而轻浮的误以为,自己未来可以很容易抓住某个十倍股,百倍股的机会。
但实际机会来的时候,要么抓不住 ;要么抓住了,赚点小钱就跑…
187

开个 Thread 来整理一些我使用 CluadeCode 的经验和心得,也欢迎留言分享。去年起我是 Cursor 的重度用户,最近一个月,我用 Cursor 越来越少了,开发方式也发生了变化,现在大部分时候都是:ClaudeCode 先做,做完了我去 IDE 去审查修改,所以不再需要 Cursor 的绝大部分功能,反而由于 Cursor 频繁更新,让我用 VSCode GitHub Copilot 更习惯顺手一些。
ClaudeCode 区别于其他同类 AI Coding Agent,我觉得强大的地方在于几点:
1. 对指令的理解很好
能很好的理解你要做什么
2. 能合理的规划任务
一个任务它会先规划再执行,复杂一点还会创建一个 TODO List,挨个执行,虽然这一步对于现在的 Agent 不稀奇,但它每次能基于自己的规划的到一个不错的结果,这才是厉害的地方
3. 对工具的运用,非常强
ClaudeCode 内置了 15 种工具(可能会变化),有系统命令行工具、文件操作工具、还有网络浏览检索工具。
它最擅长的就是 Grep 命令去搜索你的代码库,反复调整搜索正则的正则表达式去找代码,分析找到的代码,然后定位到正确的位置。
惭愧的说,我至今都不会用 grep,但是 claudecode 用 grep 检索代码的效率,可能超过了任何人类能达到的水平。
最绝的是,一个十几兆的混淆过的 js 代码,它都能毫不费力的找出来关键的代码,拼凑还原成原始编译前的代码。
如果说十几兆的混淆后的代码都能分析,那么祖传的几十万行的屎山代码它应该也是能应对的。
现在看来,对于代码库的检索,RAG 都是浮云,grep 才是王道。
4. 执行时间很长
现在 AI Agent 一个很大的毛病就是执行几次就结束了,结果 Token 也消耗了但啥屁事都没干成,OpenAI 的 Codex Cloud 就是个反面典型(codex-cli 好一点,也没好到哪去),像开发任务,有很多任务就是需要反复大量操作的,ClaudeCode 就是大力出奇迹,一个任务十来分钟是常态,更长时间也有,所以大部分时候能交付一个不错的结果。
这可能也是 ClaudeCode 比其他家的一个主要优势所在,毕竟 Cursor 这些是没法跟 Anthropic 比烧 Tokens 的。ClaudeCode 最开始就是 Anthropic 家的内部工具,一开始他们就没考虑过要省着点用 Tokens,没想到歪打正着大力出奇迹,效果最好。
大力出奇迹是 ClaudeCode 的成功关键,但另一个角度也是它还不流行的原因,因为你自己按量买 Token 是用不起的,一天能烧几百刀都可以,还是得配合 Claude Max 订阅包月使用,即使这样,我也经常到额度限制,要等 5 小时刷新。
5. 全程人工干预很少
ClaudeCode 虽然默认也是会确认工具使用操作,但是它有一个 --dangerously-skip-permissions 参数,虽然原则上只能是 Docker 上运行,打开后就全程放飞自我了,你啥都不用管,就等着就好了,喝杯咖啡,刷刷社交媒体,回头一看任务都好了,真正的无人值守 Vibe Coding。
当然一定要配合 Git 做好版本管理,并且对结果要审查,否则会可能出问题的。我用 --dangerously-skip-permissions 模式有一段时间了,它不会去恶意操作系统,所以目前还没出过问题。
(未完待续)🧵
53
105
667
507,786
Reno retweeted

18 Jun 2025
最近开始带实习生,所以梳理了一个实习生的上手清单,作为我未来带实习生的 SOP,欢迎需要的朋友自取。 & 也欢迎大家来提建议。
ixiqin.com/2025/06/18/my-int…
3
9
53
5,114
Reno retweeted

19 Jun 2025
进入陌生领域时,Deep Research 的三大法宝
当你踏入一个全新的学科领域时——尤其是理工科或技术类领域——结构化学习至关重要。根据我的经验,以下三类 Deep Research 工具最为高效:
1.Textbook(理论 结构)
一本设计良好的 Textbook 是理论学习的主干,能够系统地引入核心概念,每一章环环相扣、层层递进。如果你是初学者,建议直接生成一个为期 3 或 6 个月的 course-style textbook(模仿美国大学学期制或 bootcamp 节奏),这样的结构更符合大脑的学习节奏,让知识自然沉淀。
2.Lab-Only Workbook(实践 操作)
实操训练是掌握技能的关键。一套 Lab-Only workbook 专注于实作演练,如编程、建模、仿真、数据分析、系统原型搭建等。它不再解释概念,而是让你“手到脑到”,将抽象知识变为真实能力。
3.Chronicles(历史 脉络)
Chronicles 记录某个领域的历史演进、关键技术变革与战略拐点。例如,Machine Learning 如何从统计学发展而来,Blockchain 如何通过密码学演化至今。这类编年史不仅提供背景理解,还能帮助你看清该领域的演化路径和未来趋势。
这三类工具——Textbook、Lab-Only、Chronicles——合起来,构成一个完整的 Deep Research 系统,在概念理解、技能实践和历史定位之间建立平衡,帮助你从“零基础”构建出“系统认知”。
我每天晚上睡觉以前就布置一堆任务下去。
22
166
651
88,268
我觉得还是得case by case,跑起来有问题是让Claude Code回滚还是继续修复,答案不是绝对的。先回退一步:1.步子小一点,一次只是解决一个小功能一个小bug;2.生成后要审查代码,至少要看懂,测试稳定后再下一步;3.另外要用git做版本管理。这些是基本原则。有基本原则你就好灵活处理了,生成后有问题先描述清楚问题让它修复,能修复就修复,不能修复就回滚到上一次能稳定运行的地方重新生成。
如果再回退一步,就是自己能主导程序的设计和任务划分,清楚的知道应该要提供给AI必要的上下文,说到底用好Claude Code这样的神器还是要有点基本功比较好
14 Jun 2025

不给Claude Code第二次犯错误的机会
claude code生成代码后, 正常流程都完成的话, 编译是没有问题了, 但是跑起来运行可能还有问题, 这种情况下你是不是直接将将错发给claude code来查询并修复?
不建议这么做。
原因是, 如果一击未中,说明的问题是什么? 说明对该领域的某个特定知识点它是不完全掌握的, 这个和人类的偶尔拼写错误不是一个性质。
所以, 在意识上你要提升到这个高度: 如果这个问题,一开始没有搞定, 后面你基本也搞不定,因为你大脑里没有这个完整的知识。
那怎么办? 请外援, 请 zen mcp, 有请 gemini 和 o3联合会诊, 而且实现了数据共享和协同,补充了claude code的盲区
4
6
36
23,967
Reno retweeted

9 Feb 2025
chatgpt 的降智识别和解决,简要写一下:
# 降智的定义
所谓的降智,并不是model 本身问题,而是openai 会根据使用者偷偷更换chatgpt底层调用的model,前端没有任何提示或显示,例如
o1-pro 变 o1
o1 变 gpt-4o
gpt-4o 变 gpt-4o-mini
等情况
# 降智的识别
主要针对 o1-pro
1. 时长法。给一个高度复杂多步的任务,跑满7min左右,那说明可能是正常的,如果低于1 分钟,几秒或十几秒就回答了,那一定是降智了。这个方法现在openai也掺水了,让4o 思考很久再回答。所以可以判断出降智,但无法百分百确定是没降智。
2.难题法。发送一些model区分数学、理科难题,只有o1-pro 可以准确回答的那些,如果多次正确率在 80% 以上,那么基本确定没降智。
3.提示词工具查看法。使用提示词让 chatgpt 返回他当前可以调用的 tool。
如果是降智版本,只会返回1-2个,工具结果,甚至没有。
如果是正常版本,会返回4-5个,甚至更多的可用tool。
提示词:
Summarize your tool in a markdown table with availability
4.查看POW值。在浏览器html前端中,找到 openai 给的 pow值,这个和IP相关性很大,越大越好,实测 20000 以上,则方法1、2都是通过测试的没降智。
# 解决方案
简单的:使用苹果客户端,手机,mac。有听说对于苹果的风控力度小。其次使用安卓手机端。这也是独立的线路。
使用windows 时:
对IP进行检查,如果是ip分数质量很差,带有 VPN proxy标记,那么不要登录主账号。
更换IP,直到先把IP测试通过,换成了家宽或商业标记。
接下来,可以使用免费账号先登录进去,使用方法3提示词测一下对不对。这是为了避免主付费账号,被脏ip关联了,openai 是有持续风控,但不一定会触发,所以保险起见,尽量减少风险操作。
方法3提示词通过后,便使用方法4查看 POW 值,超过两万,可以尝试登陆主付费账号。
使用 o1-pro 提问一个高难度多步数,答案唯一的数学题,回答过程思考很久,步骤清晰,答案正确,那说明是正常版本。
如果出现问题,还是重复以上操作,更换 ip,乃至发邮件找 openai 要求解除风控。
# 总结
以上方法,实践有效,但不保证百分百有效,因为openai的风控操作没有摆在台面上。预防措施只是从风险控制角度在做,也不一定做到点上和有用。另外 openai chatgpt的风控也是处于一种对抗性变化,在实时更新的。
31
98
393
239,235
《像用实习生一样用 AI 辅助你编程》
响马毫无疑问是编程高手,几十年的开发经验,另外他写的代码都属于一些底层代码,被训练过的比例极少,AI 大概率写不出来高质量代码,不放心让 AI 帮忙写程序正常。但对于普通程序员来说,不一定要像响马那样,拒绝 AI 的帮助。
比如我就是个普通程序员,写的都是一些简单的前端 UI 代码,或者后端增删改查代码,并没有太高技术含量,就经常让 AI 给我帮忙,还是让我效率提升不少的。我总结下来经验就是:像用实习生一样用 AI 辅助你编程。
在科技公司或者开发团队经常能看到这样的场景:某些资深程序员,写代码特别牛,效率特别高,但是很多活都压在他们身上,成为了团队瓶颈,于是老板说,这样不行,给你几个实习生或者新手程序员帮你分担一些吧。
大多数时候这种提议是被拒绝的,倒不是他们藏私不愿意带人,而是在他们看来,把活交给实习生,一个简单的任务都要花几天时间,自己一小时就做完了,中间还要沟通,做完质量不行还要帮忙擦屁股,花的时间超过自己写的时间,一点都不合算,另可自己做。
这些确实是事实,但是可能忽略了一些问题:
1. 实习生是会成长的,很多事情教了一遍就不需要再教第二遍了。
2. 再复杂的程序也是有些“体力活”的,比如说搭个脚手架,新增个模块,简单的重命名/重构,等等。对于资深程序员来说,老是干体力活会倦怠的,但是对实习生来说正好是一个学习的好机会。
3. 能从实习生身上学习到新的东西。当我们对一门技术太熟悉,会有路径的依赖,不太容易发现或者接受新的技术,同样的任务让实习生做,虽然大多数时候不如你做的,但是也会有眼前一亮的时候,能学到一点新的东西或者开阔一下眼界:原来还可以这样!
4. 如果你的任务不能交给实习生做,也许架构上存在一些不足,无法合理的将功能拆分。有些程序员的活不能拆分出来,一个原因可能是架构还不够好,模块都在一起,无法拆分。当然即使拆分后肯定还是有些复杂模块是无法进一步拆分的,这不在此列。
我在带实习生上有一些经验,所以在使用 Cursor 或者 GitHub Copilot 的时候,就是把 AI 当成一个实习生用,效果是很好的。
** 首先体力活都交给 AI 来做
体力活指的是那种重复的、要求不高的、繁琐的工作。比如说:
- 新建一个页面、一个 API
- 一个数据库增删改查的模块
- 单元测试
这些活说难也不难,但是自己写有点麻烦,所以我每次都是 Cursor 里面用 CMD i 唤出 Composer,把相关代码文件都添加上作为上下文,然后提出要求,一个初始的功能就有了。
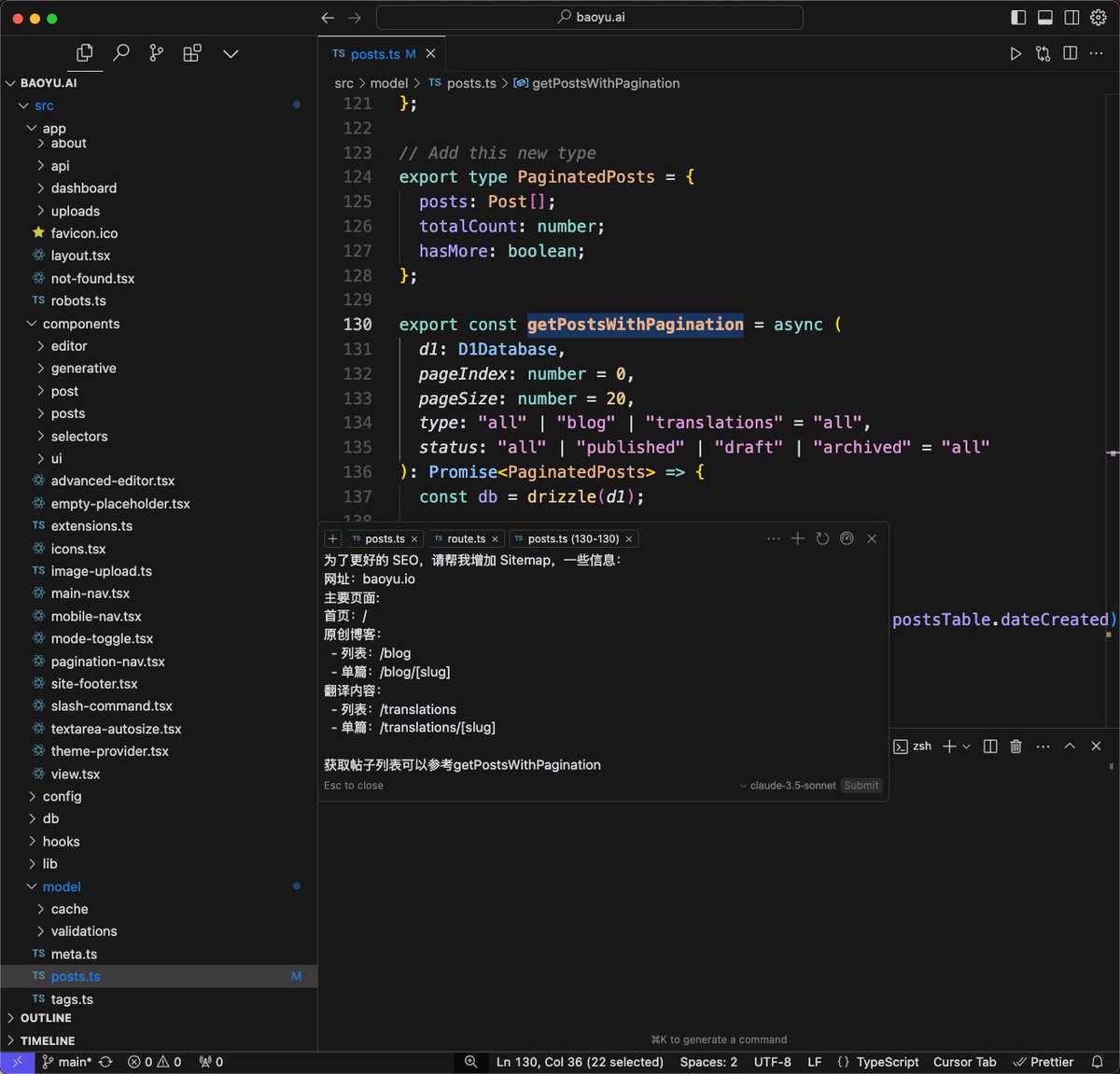
比如我要为自己的博客网站增加一个 Sitemap 的功能,我当然可以自己写,但光文件都得创建好几个,还得写一些基本的读取数据库和输出 Sitemap 代码,甚至我还得去查询一下 Sitemap 规范。正因为如此,所以我一直懒得加上这功能。
但现在我有了 AI 这个实习生,那么就可以放心得让它去帮我写,我把数据库访问的代码加入上下文,将功能有些类似的feed.xml 代码也引用了进来了,然后简单的写几行提示词:
> 为了更好的 SEO,请帮我增加 Sitemap,一些信息:
> 网址:baoyu.io
> 主要页面:
> 首页:/
> 原创博客:
> - 列表:/blog
> - 单篇:/blog/[slug]
>翻译内容:
> - 列表:/translations
> - 单篇:/translations/[slug]
>获取帖子列表可以参考getPostsWithPagination
参考图1
很快就帮我把相关文件都创建好了,虽然说 robots.txt 都给我做成动态的有点业余,但是也还好,至少我知道了内容应该是什么,懒一点就让它重新生成个静态文件,勤快一点就手动创建一个。剩下的就是调试一下,没什么问题就可以发布了。
参考图2
理论上基于这个结果,还可以一直提要求,知道满意为止,或者差不多了自己接管手动修改一下。
让 AI 帮忙先实现一个基本的模块,意义不仅仅在于减少了体力活,而是帮你开了个头!万事开头难,很多时候真的就是因为没有一个开头就没继续,当有个初始的结果,哪怕烂一点,再基于它上面修改要简单很多,更容易交付。
** 给“实习生”一个葫芦,让他们学着画瓢
对于实习生来说,稍微复杂一点任务很难从无到有做出来,但是如果给他们一个已经做好的模块作为参考,照着葫芦画瓢,那么也能做个差不离。
让 AI 帮你编程也是一样的,你不能指望 AI 能像你一样厉害懂你的代码库,但是你可以教它,把一个类似的实现代码给它参考,甚至于写一段伪代码让它实现。
就拿前面 sitemap 的例子,添加到上下文的 feed.xml/route.ts 就是“葫芦”,有了这个“葫芦”,它去“画瓢”就容易多了,它可以从中去学习最佳实践是什么。
** 设计架构和技术选型的时候,选“实习生”熟悉容易上手的技术
技术选型是一个让人纠结的事情,需要各种考量,现在更是多了一个维度,就是要考虑把 AI 当成你的团队成员,想让 AI 能更好的帮你干活,那么就少造一些轮子,少用一些偏僻的框架或类库,用那种最流行的,训练语料最多的框架和库。
比如我在给自己搭建博客的时候,选的 Nextjs、Tailwindcss、ShadcnUI、D1(Sqlite),这些都是相当流行和容易上手的框架和库,所以我让 AI 帮我实现一个 Sitemap,它能知道在什么创建文件,遵循什么规范,写 UI 也知道如何帮我添加正确的 CSS。
** 将复杂任务分解成简单的任务,让“实习生”帮你完成小的模块
资深程序员和新手程序员的一个分界,就是能不能将复杂模块拆分成简单的小模块。比如我要搭建一个自己的博客网站,就 AI 现在的能力,是没办法自动完成这样一个项目,但是我可以让它帮我创建一个页面,帮我实现一个数据库读写的功能模块,帮我基于数据库读写模块实现一个 API,而我自己,则可以聚焦于数据库的表设计、系统的架构设计、UI 设计这些事情上。
** 向“实习生”学习
现在在实现功能的时候,哪怕我比较熟悉的,我会习惯性问一下 AI,让它帮我生成一段代码,虽然大多数时候它不一定比我写的更好,甚至是错误的,但有时候它能提出一种全新的我没考虑过的思路,那我就能从中学习到点什么,以后可能就用的上了。
就像大数学家陶哲轩,也在用 AI 帮忙解决数学问题,并非 AI 数学比他厉害,而是给他提供了不一样的思路。
> 我曾遇到过一个问题,我尝试了几种方法,但都无法解决。于是,我尝试询问 GPT,你建议我使用什么其他方法来解决这个问题?GPT 给我提供了 10 种可能的方法,其中有 5 种我已经尝试过,或者明显没有帮助。的确,有几种方法并不实用。但其中有一种我还没尝试过的方法,那就是针对这个问题使用生成函数。当 GPT 建议我使用这种方法时,我意识到这就是我漏掉的正确方法。所以,将 GPT 视为一个交流伙伴,它确实具有一定的用处。——陶哲轩
** 对“实习生”产出的结果要验证
既然 AI 只是一个实习生,那么就说明它生成的代码是靠不住的,哪怕看起来很好,总是要像对待实习生一样,去对代码做审查,理解它实现的思路,对结果进行测试验证,出现问题让 AI 改进或者手动修复。
如果有人去责怪产品的问题是因为 AI 生成的质量不行,那只能说明是在甩锅,就像你生产环境的故障不能怪这是实习生写的,难道你们不做 Code Review,不做 QA 的吗?
** 最后
这是我在日常使用 AI 辅助编程的一点经验分享。如果你把 AI 当成一个资深程序员,那么你大概是要失望的,但是如果你把 AI 当作一个实习生,它真的可以做不少事情,让你提升编程效率。
另外一些现在 AI 还不能完全替代专业程序员的地方:
- 基于业务需求进行抽象和架构设计的能力
- 对复杂问题进行分解和统筹规划的能力
- 出现问题定位和调试的能力
- 当然还有出问题背锅的能力
欢迎分享你的经验!
本文同步发表于博客:baoyu.io/blog/ai/use-ai-to-a…

13
95
364
217,748
4 Jul 2024
听了很多Andrew Huberman和Peter Attia的播客,今天用Cooper 12min Test来测一下自己的VO2MAX。结果差强人意,才跑了2200米,低于平均水平,看来要锻炼起来了。平时没有跑步习惯,这次一下子跑这么多,也不敢尽全力,尤其是跑到一半感觉膝盖有点酸(跑前跟视频做了8分钟热身)。看看1个月后成绩如何哈

1
134
19 Aug 2024
后来保持一周跑三次的习惯,到今天刚好1个半月,提升到2640米左右(手表不准,测到2840米),最大摄氧量VO2MAX是47.7,相比第一次的37.7进步很大。一个月后再看看👀

1
53
19 Aug 2024
这1个多月跑步几乎每次都能看到50米左右进步,心情当然是不错的;具体反映到游泳上,就是跑步之前偶尔游泳,游200米要休息一会,昨天游几个来回完全没有累的感觉,半小时游完了1000米。这应该是10多年前刚毕业的身体状态了哈哈
44
15 May 2024
RT @Svwang1: 有两类事情需要格外关注:
一种是 "迟早肯定会发生,但是如果因为暂时没发生,就假装不会发生而不去准备,那么最终会遭遇重大甚至毁灭性损失。"
还有一种是 "迟早肯定会发生,但是如果因为暂时没发生,就假装不会发生而不去准备,那么最终巨大收益来临时,也只…
143
Reno retweeted

14 May 2024
对一个系统的认知是分层次的
第一个层次是认识事件或事实
第二个层次是理解事件或事实背后的逻辑和动因
第三个层次是掌握规律,认识系统的功能和目标,对未来的系统运动或其他事件进行预测
在X上,期望获得第二层次和第三层次的认知几乎不太可能;因为,就连第一层次的基本事实或事件,能说清楚,并愿意诚实说出来的人都不多
8
14
50
8,416
Reno retweeted

28 Apr 2024
I disagree that you dress like Cary Grant. In this thread, I will list some of the ways in which your dress differs and why such important details matter. 🧵
974
5,402
87,871
27,309,407
6 Mar 2024
Claude Opus注册失败。官网先登记邮箱,再手机验证。前者我用了选用了Gmail(败笔),后者用了Giffgaff手机号,收到验证码,输入后竟然退回了上一步,说我这个Gmail邮箱停用了。想来想去,可能是因为之前这个Gmail在Claude刚出时在Slack里用过。接着我用其他邮箱,再用英国号,全部一下子被封,太狠了
1
1
585
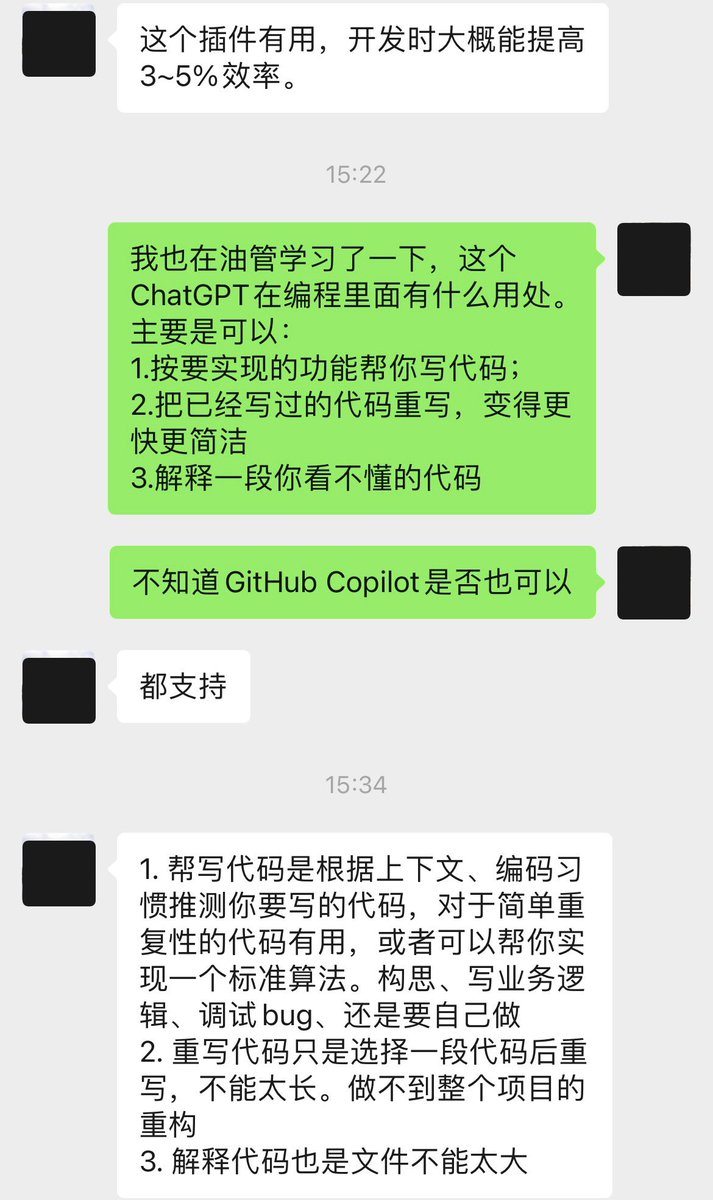
6 Feb 2024
给用C 做嵌入式开发的同事买了个GitHub Copilot帮助提升效率,他用了几天,结论是提升了3-5%的效率。看起来没有向大家说的那么厉害。不知道是他还用得不够溜,还是编程语言的问题?
4
169