
Joined March 2009
- Tweets 30,191
- Following 385
- Followers 48,009
- Likes 16,250
2,523 Photos and videos












Pinned Tweet

Jun 2
⭐ My latest blog post about the @moergo_keeb Go60 is out. I really spent weeks on it. It has tens of photos, videos, my layouts and much more. Check it out here: arslan.io/2026/06/02/review-…
2
1
36
6,998
Jun 13
Evening activity with my daughter. We first pulled out the keycaps, and then the switches from my Go60. And then later swapped them with Choc Sunset Tactile switches (thanks for the recommendation @mschoening ).
We paired it with the MBK Legend 60s gray keycaps. She loved it, and I've tried to teach him the differences between tactile linear, and what silent and non-silent means. I hope she uses tactile in the future, just like her Father 😅



4
1
61
7,562
Jun 12
I think what makes the U.S. great is that everything is so spaced out. As a human, you see fewer human-made things: buildings, bridges, roads, and so on. When was the last time you looked in a direction with no human touch?
I lived in the U.S. for years, and there’s something about it that you can’t find in any other country. I think I’m slowly realizing that it’s the sheer vastness. And that speaks to the human soul. It’s hard to understand unless you’ve lived it or seen it yourself.
Jun 12

The vibes are insane. Driving through the great state of Louisiana on our way to New Orleans. It’s crazy how diverse this country is, every day the scenery looks different.
9
2
100
18,677

Jun 11
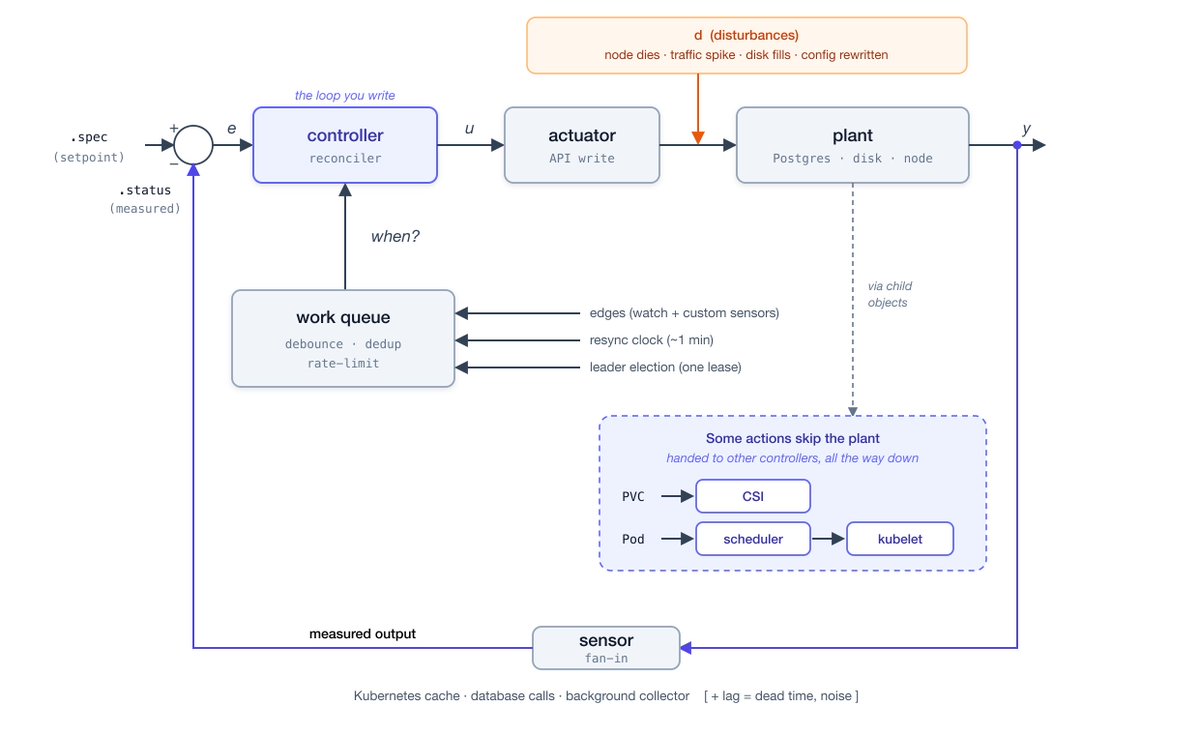
We’ve decided to polish and publish this on @PlanetScale! I’ve already completed the writing, but we’ll add some PlanetScale touches. Here’s one of the diagrams. Stay tuned! We aim to publish it next week.
Jun 7

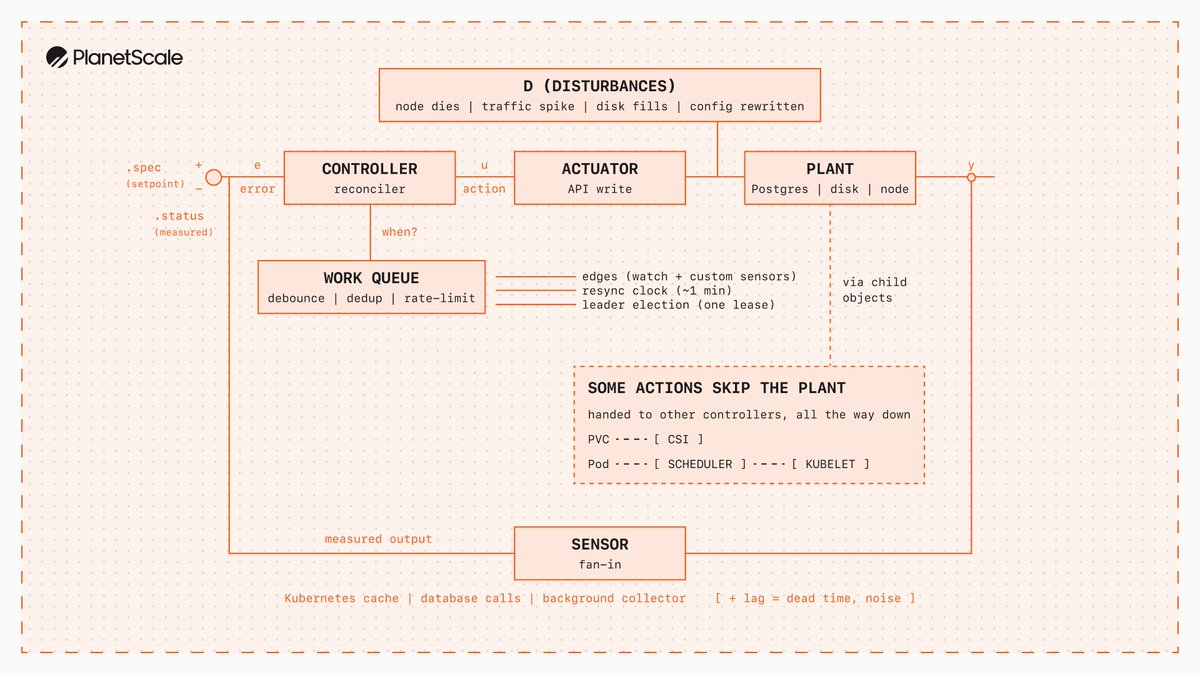
Control Theory meets Kubernetes. One of the images from my upcoming blog post about deep dive into controllers and closed feedback loops in Kubernetes.
1
6
192
22,478
Jun 11
This is such a cool concept. Lately I've did something similar internally. I have two Cursor Automations, one is periodically running a debugging agent against certain failures in our system with a specific skill we wrote. Once finished, it saves the report and the state. Another agent in parallel (runs daily), constantly reads new debugging cases, checks if the skill can actually/debug it, and then updates it.
So the main agent that debugs the fleet becomes smarter and better at debugging, while the second agent keeps things tidy. It also prunes the skill if a certain failure case is no longer applicable (it's fixed in production).
It's an experiment and I'm curious how it'll end up for our use case.
Jun 11

We're training the next version of Composer... with Composer!
The model is always learning from itself. This kind of "recursive self-improvement" might sound new, but it's been happening for many months!
For example, training big models requires creating *lots* of data for RL - essentially games the model plays to improve at any task you can grade.
The newest models can configure their own environments to make those games playable (auto-installing dependencies, fixing broken setups).
Composer 2 was *dramatically* better at this than version 1. So the better the model gets, the better it gets at creating the conditions to train its successor.
Each generation unlocks capabilities the previous one didn't have! So cool.
x.com/cursor_ai/status/20521…
2
1
35
9,678
Jun 11
We're looking for engineers to join my team: job-boards.greenhouse.io/pla…
It sits at the intersection of Kubernetes controllers, database operations, distributed systems, and developer tooling.
A lot of the work is about turning complex database operations into safe, repeatable, automated systems.
Work is hard, but rewarding. Engineering is top notch. DM's are open. Please read the position, you know if it's for you or not. We're flexible for extraordinary candidates!
5
32
271
29,024
Jun 11
Just got this beauty. The Hamilton Khaki Field Mechanical 36. It’s smaller. Has a crystal glass, fixed bars and comes with 100m water resistance.
29
7
317
50,233
Jun 11
I love when agents, by themselves, figure out that my local checkout is a few commits behind, and correct me. It feels like magic.
2
20
4,303
Jun 10
I've heard people run loops to run other loops. My blog post is will be about that, but applied to scale and real production workload. You're going to see a lot of loops, the whole blog post is about loops! Here is another diagram. I plan to publish it today, stay tuned!
5
3
67
7,238
Jun 7
Control Theory meets Kubernetes. One of the images from my upcoming blog post about deep dive into controllers and closed feedback loops in Kubernetes.
8
14
254
37,772
Jun 7
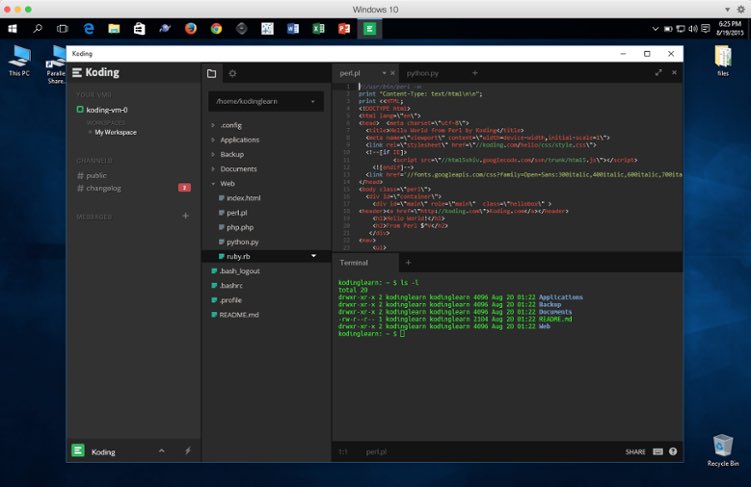
I just triggered a new Cloud Agent in Cursor, and it reminded me of my prior work. Not many remember, but my first startup job was when in 2012 I worked on the first Cloud development environment. It was called Koding.com You could spin up a VM in Cloud, and start coding from within your browser. I worked on the whole orchestration and backend part (they are still open source).
There was no Kubernetes, Go just started getting traction (hence I picked up because It was a good fit for us), even gRPC wasn't widely adopted.
But with all these things, sometimes even if you work hard or have a great idea, timing is very important. We were just too early and there was never a good market fit for it. Now with LLM's, I think it would be quite differently.

6
39
6,442
Jun 6
Ok so this is cool. I've set it up, I'll be using too brainstorm my ideas, and let it save links and my ideas to a notes app. It can't access Apple Notes (which I use for everything). So what are my options? Obsidian doesn't have public API either. Maybe @NotionHQ would be a good fit? I guess to make it useful though I need their Plus plan?
What do people use for taking/managing notes in Agents era?
Jun 4

Say hi to the new Poke! 🌴
Now officially approved by Apple to text on Apple Messages.
As the first and only AI agent. Chat now: Poke.com
20
1
79
49,977
Jun 7
Notion doesnt work unfortunately. Spent hours installing, deleting, reconnecting the MCP. I sent also a support email to @interaction. This is the thing I don’t like with all these UI’s, there is zero visibility and I don’t if the issue is with Poke or Notion.
2
2
2,997
Jun 6
I started writing it the day I posted the tweet, and it's already over 3000 words and I think I'm still not finished with my ideas. I have so many things to tell about it. You'll love it and I promise it'll be a hit post.
Jun 4
I think I want to write a blog post about some of the stuff I've dealt in the past, especially in distributed systems, like about how to run a closed feedback loop system (ideally via Kubernetes).
The idea of the blog post is to start small, explain how to schedule one-off scripts to a node, and then gradually build on top of it. And then move from there to Kubernetes, and apply Control theory semantics. Such as Setpoint (.spec), variables (.status), the controller (surprised Kubernetes uses the same term), actuators, cooldowns, the actual process and so on. There are so many details, like level triggering, read/write caches in the controller runtime, idempotency, failure scenarios (unhealthy nodes, runnint out of disk, full AZ regions going down, etc..).
When it clicks, it clicks, and then you can run tens of thousands of workloads in a self-healing way. See @PlanetScale. We did all that with a very small group of people. I'm very proud of it, but it's hard to convey the message because everything is done async, and it's hard to keep those in mind. A technical blog post could be very nice and helpful.
5
1
55
10,638
Jun 6
If you ask how? Make it extremely easy and joyable for developers, because Agents are trained on developer's mindset and coding habits. If you can do things easy, you can edit things easily, you can interact easily and script them easily, surprise: Your agents will be also do all of these, but better!

3
1
41
8,148
Jun 6
Of course I've got cursor.com/@fatih :) But unlike GitHub, it doesn't support yet multiple e-mails, so none of my usage at work is displayed here (yet).

introducing cursor profiles!
go claim your handle at cursor.com/profile
2
22
8,120
Jun 4
I think I want to write a blog post about some of the stuff I've dealt in the past, especially in distributed systems, like about how to run a closed feedback loop system (ideally via Kubernetes).
The idea of the blog post is to start small, explain how to schedule one-off scripts to a node, and then gradually build on top of it. And then move from there to Kubernetes, and apply Control theory semantics. Such as Setpoint (.spec), variables (.status), the controller (surprised Kubernetes uses the same term), actuators, cooldowns, the actual process and so on. There are so many details, like level triggering, read/write caches in the controller runtime, idempotency, failure scenarios (unhealthy nodes, runnint out of disk, full AZ regions going down, etc..).
When it clicks, it clicks, and then you can run tens of thousands of workloads in a self-healing way. See @PlanetScale. We did all that with a very small group of people. I'm very proud of it, but it's hard to convey the message because everything is done async, and it's hard to keep those in mind. A technical blog post could be very nice and helpful.
14
2
138
20,010
Jun 4
Composer 2.5 from @cursor_ai is so fast, all you see is this:
Searched, grepped, read
And then suddenly it's finished, and also done correctly.
Would make a t-shirt with these words.
12
4
277
22,083