
Joined October 2015
- Tweets 3,281
- Following 456
- Followers 1,398
- Likes 2,967
419 Photos and videos
















Jun 11
We're excited to share that three papers from our lab have been accepted at #Interspeech2026 !! 🍾
#SpeechTranslation #SpeechAI #NLProc #FBK #Interspeech
2
6
8
155
Jun 11
2️⃣ "Better Late Than Never: Evaluating Latency Metrics for Simultaneous Speech-to-Text Translation"
👥 Peter Polak, @sarapapi, @luisabentivogli, Ondřej Bojar
📄 arxiv.org/abs/2509.17349
2
2
62
Jun 11
3️⃣ "Cross-Attention is Half Explanation in Speech-to-Text Models"
👥 @sarapapi, @DennisFucci, @mgaido91, @negri_teo, @luisabentivogli
🇪🇺 DVPS EU project
📄 arxiv.org/abs/2509.18010
2
2
47
Jun 11
1️⃣ "Do What I Say: A Spoken Prompt Dataset for Instruction-Following"
👥 @MaikeZufle, @sarapapi, Fabian Retkowski, Szymon Mazurek, @mkasztelnik, Alexander Waibel, @luisabentivogli, @_janius_
🇪🇺 Meetween EU project
📄 arxiv.org/abs/2603.09881
3
2
80
Jun 10
Our pick of the week by
@lina_conti
: "Greater accessibility can amplify discrimination in generative AI" by
@CarolinHolterm, @minhducbui_nlp, @KaitlynZhou, @vjhofmann, @kelina1124, @anne_lauscher
📰 arxiv.org/abs/2603.22260
#GenderBias #SpeechLLM
Jun 10

Pick of the week @fbk_mt: "Greater accessibility can amplify discrimination in generative AI"
Gender bias in speech-based LLMs examined from multiple angles: a user survey, automatic bias measurement, and pitch manipulation experiments.
arxiv.org/pdf/2603.22260
3
6
888
Jun 9
Late update, but we had two great talks last month!
#MachineTranslation #FBK #NLProc #GenderBias #SpeechSynthesis
1
1
156
Jun 9
From Harm Lameris, a PhD candidate at @KTHuniversity on "Communicative Functions of Synthesized Speech: Modelling Prosody and Voice Quality Dynamics"
1
125
Jun 9
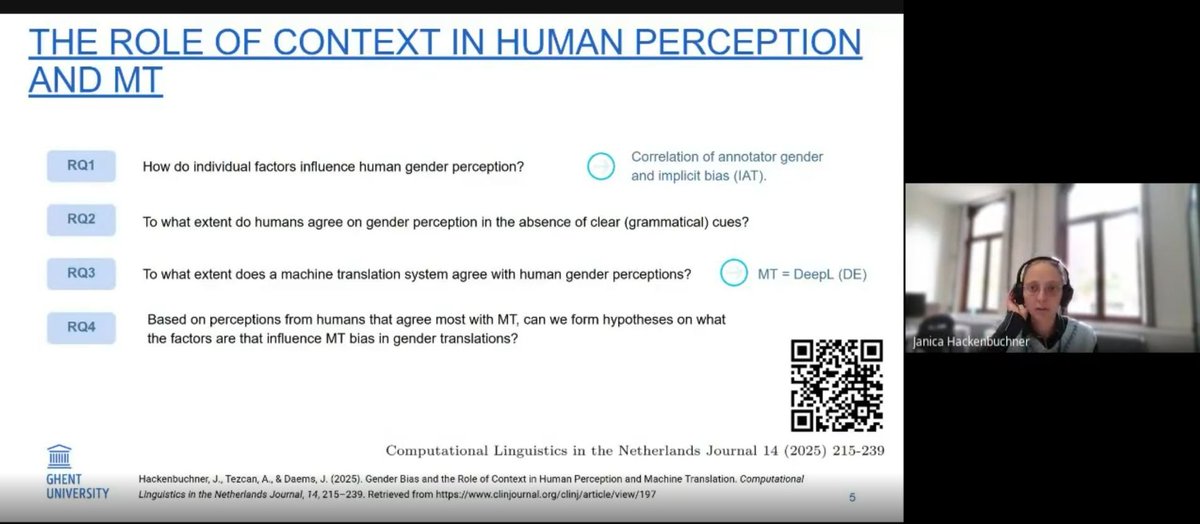
Janiça Hackenbuchner, a PhD candidate at Ghent University on "Contextual Cues and Gender Ambiguity in MT: From Human Perception to Model Interpretability"
1
2
79
Jun 3
Our pick of the week by @dhairya_su47605
: "Scaling Laws for Precision" by @tanishqkumar07, Zachary Ankner, @bfspectorShiekh, @blake__bordelon, @Muennighoff, @mansiege, @CPehlevan, Christopher R´e, @AdtRaghunathan
📰arxiv.org/abs/2604.19565
#Quantization #LLM #ScalingLaw

Pick of the week @fbk_mt
Super interesting paper on the limitations of quantization, demonstrating how post-training quantization scales poorly in data.
arxiv.org/abs/2411.04330
1
4
170
May 27
⭐ For our #PickOfTheWeek, this paper explores an important question for modern speech AI:
🎙️ Which Evaluation for Which Speech Model?
👥 Authors: @Maureendss , @EeshanDhekane
Speech foundation models are evolving rapidly, but evaluation practices are still fragmented.
2
2
167
May 27
👉🏻 What is being evaluated
👉🏻 Which capabilities are required
👉🏻 What task/protocol constraints define the setup
One key takeaway is that benchmark choice can strongly shape conclusions about model performance and generalization.
1
83
May 27
✨ A useful read for anyone working on speech models, multimodal AI, and benchmarking.
#PickOfTheWeek #MTUnit #FBK #Speech
1
1
44
May 15
🏝️ Yesterday at #LREC2026, Palma de Mallorca!
@lina_conti presented "Voice, Bias, and Coreference: An Interpretability Study of Gender in Speech Translation" at the poster session.
📄Paper: arxiv.org/abs/2511.21517
💻Code: github.com/lina-conti/voice-…
#SpeechTranslation #NLProc
1
6
299
May 15
🏝️ Also at #LREC2026, Palma de Mallorca!
@luisabentivogli presented our second paper.
"Phonetic-based Ranking for Improved Pseudo-Labeling in Low-Resource ASR"
📄 Paper: eloquenceai.eu/wp-content/up…
Bravi!! 🎉
1
1
132
May 13
How does the granularity of speech-text pairs impact SpeechLLM performance, and what is the optimal way to interleave tokens? Furthermore, what are the best practices for generating synthetic data to boost training?🧐
1
3
197
May 13
The paper "Data-Centric Lessons To Improve Speech-Language Pretraining" by @vishaal_urao, Zhiyun Lu, Xuankai Chang, Yongqiang Wang, Violet Z. Yao, Albin Madapally Jose, @FartashFg , Josh Gardner & Chung-Cheng Chiu provides the answers!
📰 Read more: arxiv.org/abs/2510.20860
1
2
122


MT Group at FBK retweeted

Mar 26
🎙️ Our paper on connecting Speech Foundation Models with LLMs is featured in the SpeechLMM Training Journal on Weights & Biases.
Read it 👉 bit.ly/4svG7ll
SpeechLMM 2.0 coming this summer. 👀
#Meetween #SpeechLMM #AI #NLP
1
4
137