
11 Photos and videos





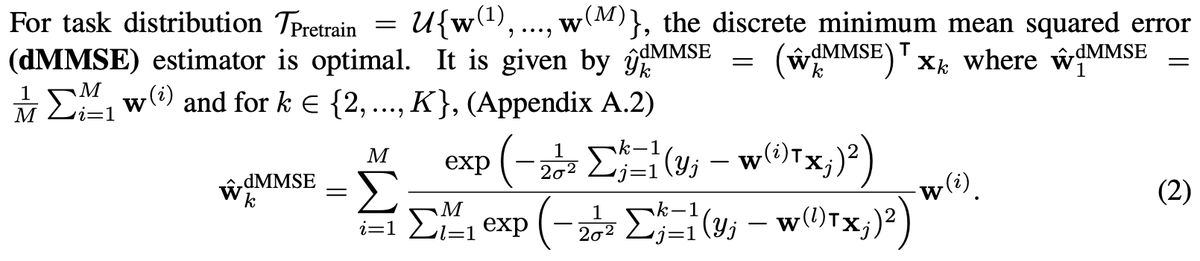
Pinned Tweet

22 Aug 2024
Check out our new work: Critique-out-Loud (CLoud) reward models where we improve reward models by having them generate a critique for a response before scoring it. Results and details in thread from @ZackAnkner.
22 Aug 2024

Excited to announce our new work: Critique-out-Loud (CLoud) reward models. CLoud reward models first produce a chain of thought critique of the input before predicting a scalar reward, allowing reward models to reason explicitly instead of implicitly!
arxiv.org/abs/2408.11791
1
1
24
2,462
Mansheej Paul retweeted

24 Oct 2025
100 citations for a paper that taught us many lessons esp about branding, timing, peer review, and pushing the frontier! I'm rather proud of this one. Congrats to @ZackAnkner and @mansiege!
arxiv.org/abs/2408.11791

2
6
70
7,775
30 Sep 2025
The next frontier of AI is where it meets the physical world, generates new hypotheses, and learns from experiments. Excited to join an incredible team in accelerating science and pushing this frontier.
30 Sep 2025

Today, @ekindogus and I are excited to introduce @periodiclabs.
Our goal is to create an AI scientist.
Science works by conjecturing how the world might be, running experiments, and learning from the results.
Intelligence is necessary, but not sufficient. New knowledge is created when ideas are found to be consistent with reality. And so, at Periodic, we are building AI scientists and the autonomous laboratories for them to operate.
Until now, scientific AI advances have come from models trained on the internet. But despite its vastness — it’s still finite (estimates are ~10T text tokens where one English word may be 1-2 tokens). And in recent years the best frontier AI models have fully exhausted it.
Researchers seek better use of this data, but as any scientist knows: though re-reading a textbook may give new insights, they eventually need to try their idea to see if it holds.
Autonomous labs are central to our strategy. They provide huge amounts of high-quality data (each experiment can produce GBs of data!) that exists nowhere else. They generate valuable negative results which are seldom published. But most importantly, they give our AI scientists the tools to act.
We’re starting in the physical sciences.
Technological progress is limited by our ability to design the physical world.
We’re starting here because experiments have high signal-to-noise and are (relatively) fast, physical simulations effectively model many systems, but more broadly, physics is a verifiable environment. AI has progressed fastest in domains with data and verifiable results - for example, in math and code. Here, nature is the RL environment.
One of our goals is to discover superconductors that work at higher temperatures than today's materials. Significant advances could help us create next-generation transportation and build power grids with minimal losses. But this is just one example — if we can automate materials design, we have the potential to accelerate Moore’s Law, space travel, and nuclear fusion.
We’re also working to deploy our solutions with industry. As an example, we're helping a semiconductor manufacturer that is facing issues with heat dissipation on their chips. We’re training custom agents for their engineers and researchers to make sense of their experimental data in order to iterate faster.
Our founding team co-created ChatGPT, DeepMind’s GNoME, OpenAI’s Operator (now Agent), the neural attention mechanism, MatterGen; have scaled autonomous physics labs; and have contributed to some of the most important materials discoveries of the last decade. We’ve come together to scale up and reimagine how science is done.
We’re fortunate to be backed by investors who share our vision, including @a16z who led our $300M round, as well as @Felicis, DST Global, NVentures (NVIDIA’s venture capital arm), @Accel and individuals including @JeffBezos , @eladgil , @ericschmidt, and @JeffDean. Their support will help us grow our team, scale our labs, and develop the first generation of AI scientists.

2
5
20
2,747




20 Jul 2025
Imagine if memory pointers had twitter. They’d be like “@malloc is this true?”
20 Jul 2025

Imagine if Linux kernel interfaces had twitter. They’d be like “/proc is this true?”
1
1
11
2,048
Mansheej Paul retweeted

16 Jul 2025
Engineers spend 70% of their time understanding code, not writing it.
That’s why we built Asimov at @reflection_ai.
The best-in-class code research agent, built for teams and organizations.
98
174
1,493
368,859


Mansheej Paul retweeted

1 Jul 2025
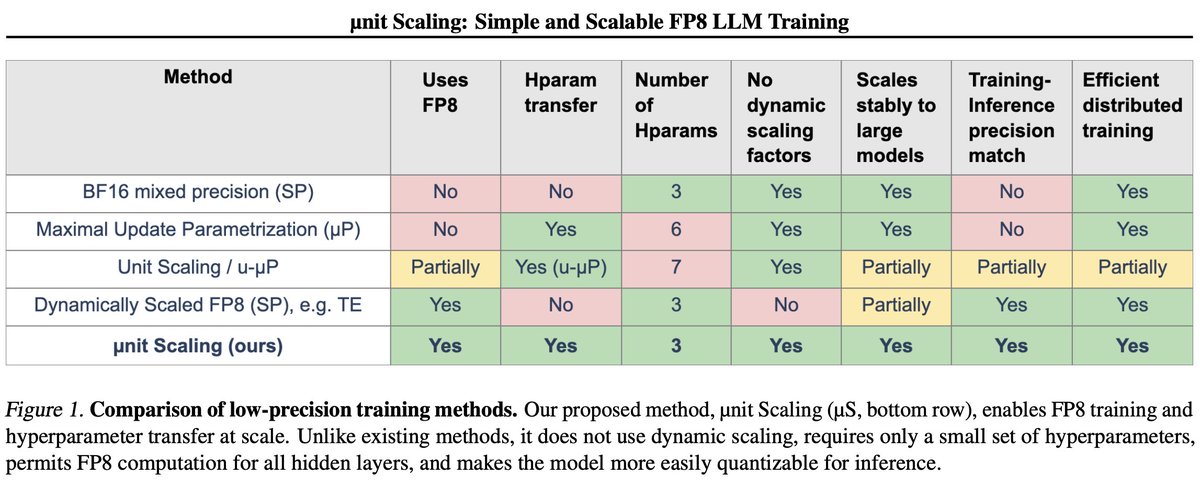
Deep learning training is a mathematical dumpster fire.
But it turns out that if you *fix* the math, everything kinda just works…fp8 training, hyperparameter transfer, training stability, and more. [1/n]
15
148
1,404
189,038
Mansheej Paul retweeted

25 Feb 2025
How can we use small LLMs to shift more AI workloads onto our laptops and phones?
In our paper and open-source code, we pair on-device LLMs (@ollama) with frontier LLMs in the cloud (@openai, @together), to solve token-intensive workloads on your 💻 at 17.5% of the cloud cost while maintaining 97.9% of the accuracy.
See Gru and the Minions in action below, 🔉on please (h/t @cartesia)!
41
169
634
192,962
Mansheej Paul retweeted

16 Feb 2025
💥New Paper!
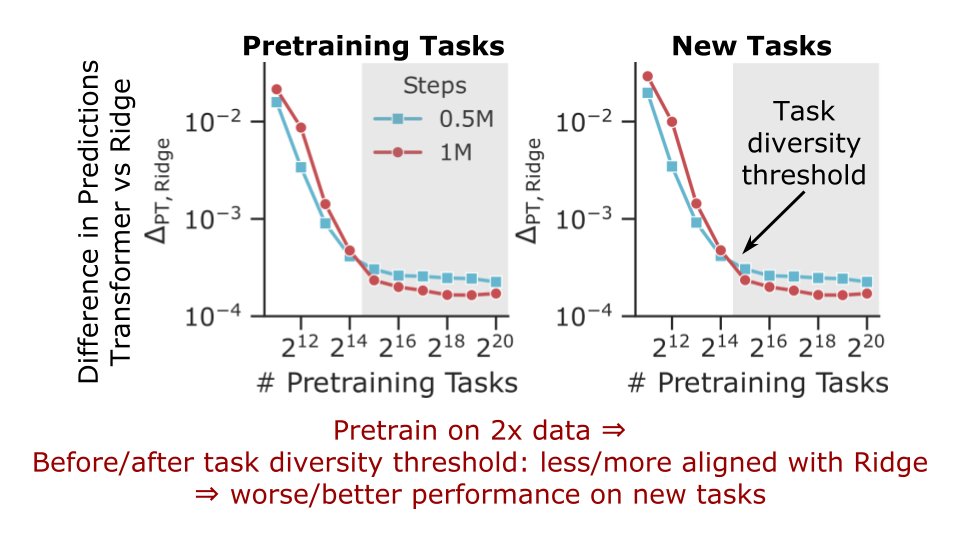
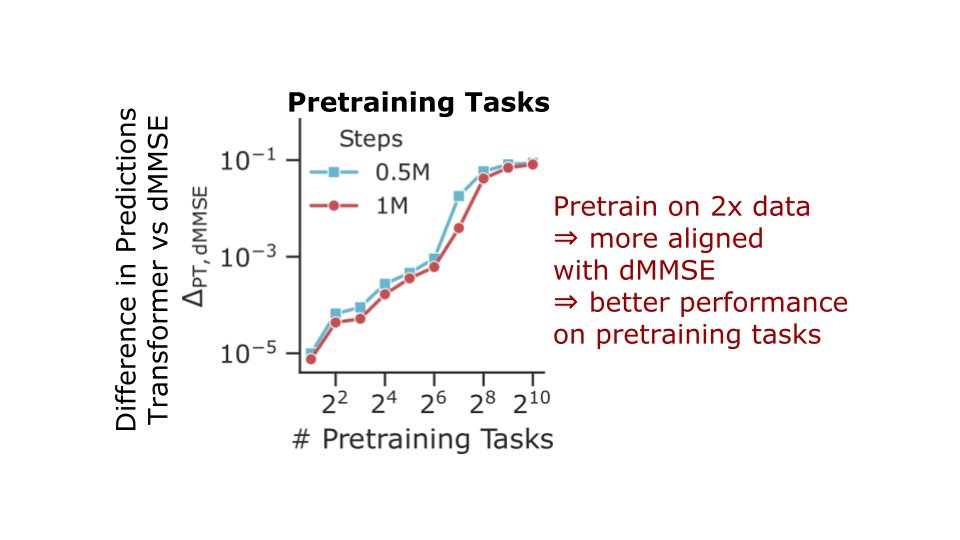
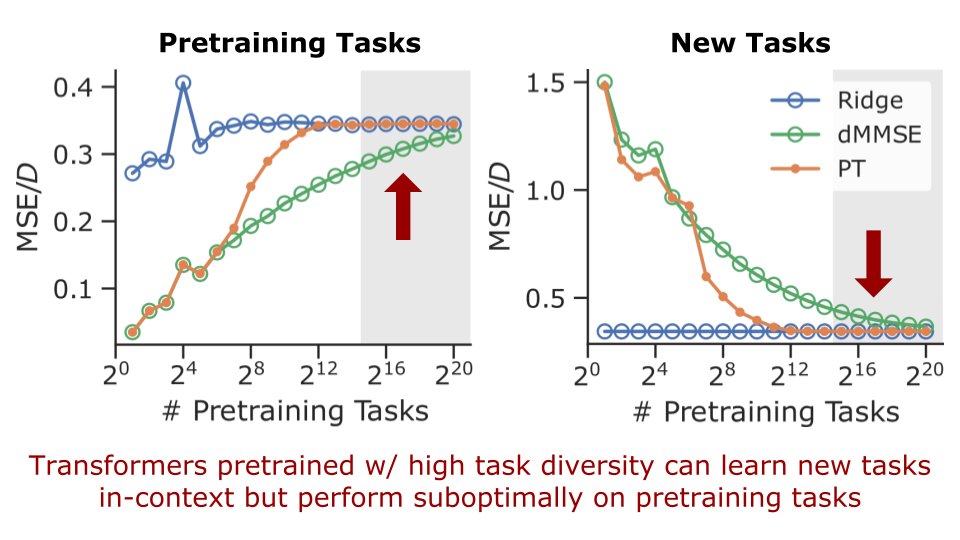
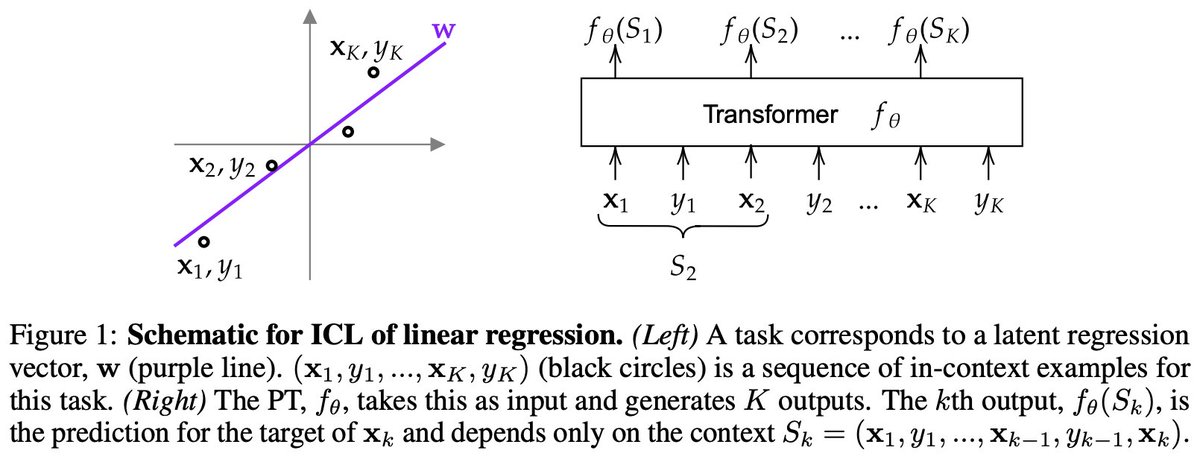
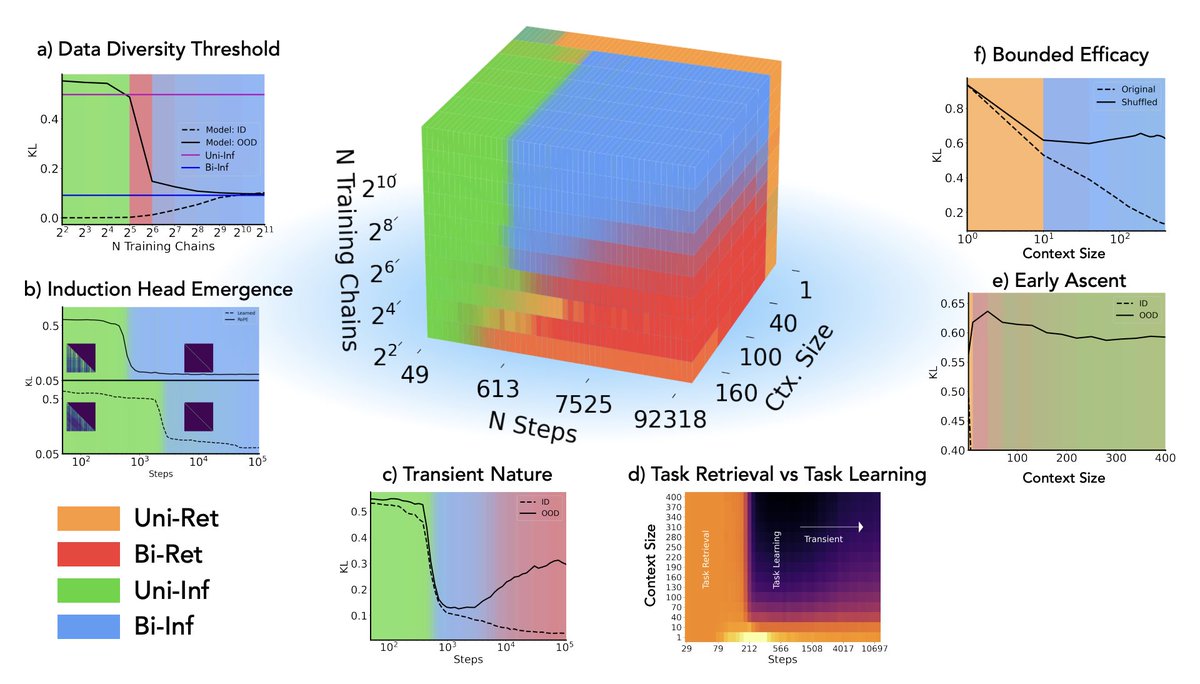
Algorithmic Phases of In-Context Learning:
We show that transformers learn a superposition of different algorithmic solutions depending on the data diversity, training time and context length!
1/n
7
61
425
37,196
Mansheej Paul retweeted

21 Jan 2025
Critique out loud reward models made it into the Kimi k1.5 technical report! Super cool to see someone scale it up to 800k inputs and to see how much better reward modeling it led to!

2
8
62
4,377
Mansheej Paul retweeted

27 Nov 2024
If you want to read more about the curriculum training used in OLMo 2 checkout our (@mansiege @_BrettLarsen Sean Owen) paper!
Congrats on the release to everyone at AI2! (but especially @soldni and @kylelostat <3 data )
arxiv.org/abs/2406.03476

26 Nov 2024

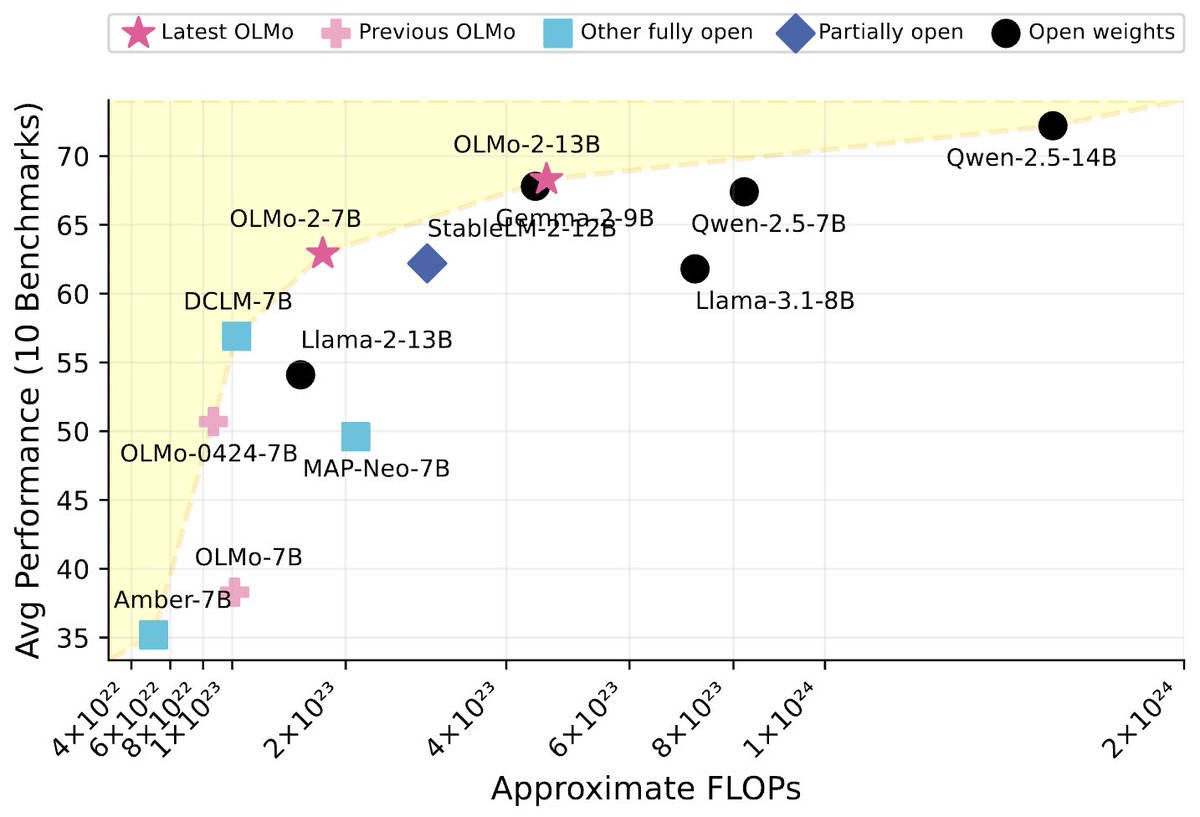
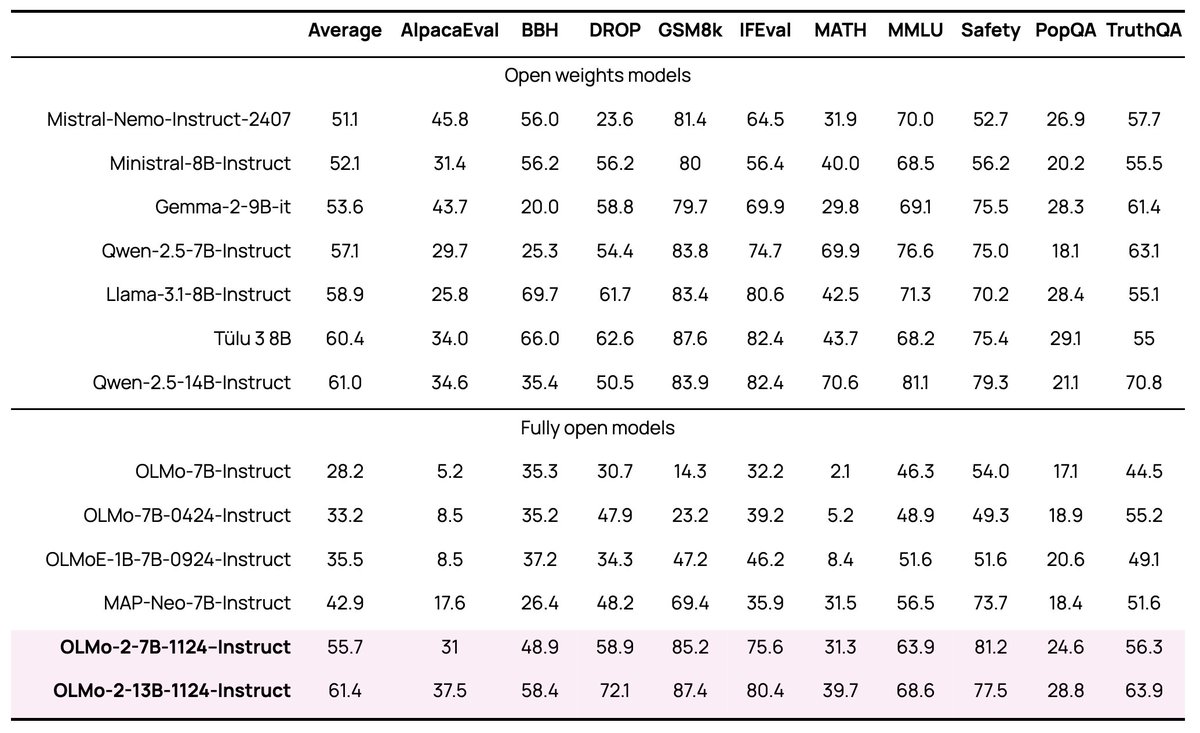
Super excited to announce our best open-source language models yet. OLMo 2.
These instruct models are hot off the press -- finished training with our new RL method this morning and vibes are very good.
OLMo 2 introduces a new family of 7B and 13B models trained on up to 5T tokens, representing the best fully-open language models to date. These models sit at the Pareto frontier of performance and training efficiency, with OLMo 2 7B outperforming Llama-3.1 8B and OLMo 2 13B outperforming Qwen 2.5 7B despite lower total training FLOPs.
Key improvements include:
1. Enhanced architecture with RMSNorm, QK-Norm, auxiliary Z-loss, and rotary positional embeddings
2. Two-stage curriculum training approach using OLMo-Mix-1124 and Dolmino-Mix-1124
3. Model souping technique for final checkpoints (aka merging)
4. State-of-the-art post-training methodology from Tülu 3 with a three stage training of instruction tuning, preference tuning with DPO, and our new reinforcement learning with verifiable rewards (RLVR)
5. Evaluated on the OLMES suite
6. The Instruct variants are competitive with the best open-weight models, with OLMo 2 13B Instruct outperforming Qwen 2.5 14B instruct, Tülu 3 8B, and Llama 3.1 8B instruct models.
The 13B Instruct version builds on our Tulu 3 Recipe with a very finetunable base model and makes for a great user experience that we haven't seen before with the open-source models.
Links below :D
1
8
49
8,604
Mansheej Paul retweeted
9 Oct 2024
Agreed ;)
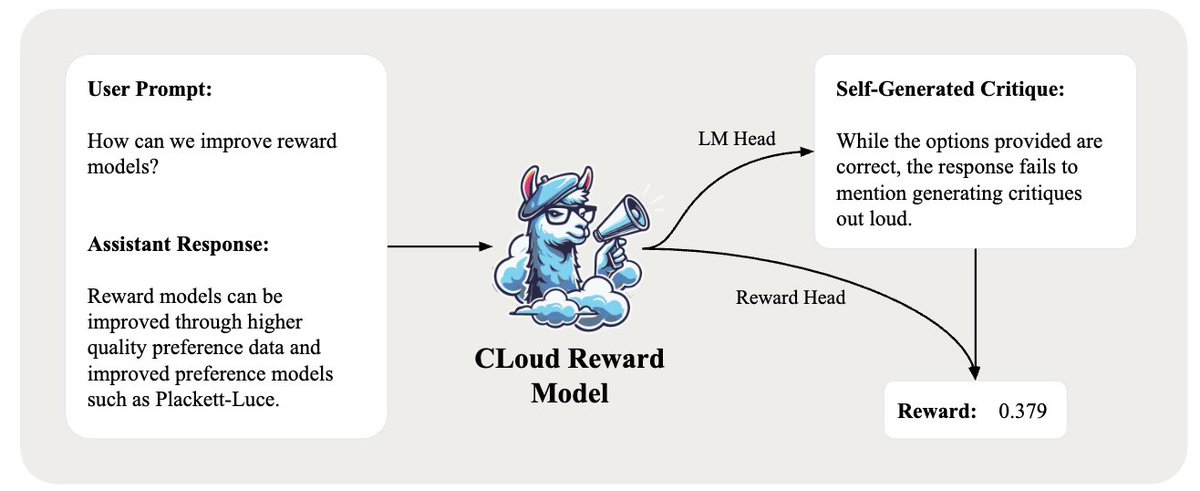
But in all seriousness, its cool to see everyone converging on reward models that perform explicit reasoning by critiquing out loud. Super excited to see how people build on top of these works.
8 Oct 2024

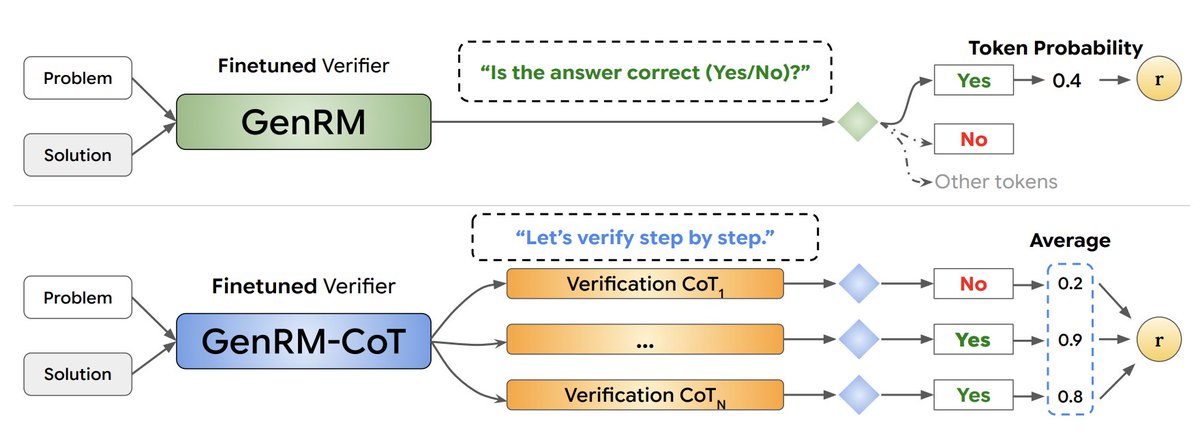
Imitation is the best form of flattery ;)
Great to see more work on generative verifiers and reward models.
2
9
53
12,420
5 Sep 2024
Code and models for our latest work Critique-out-Loud (CLoud) Reward models is now released! Check out our paper (arxiv.org/abs/2408.11791) for more details on using reward models to reason before predicting a reward score.
5 Sep 2024
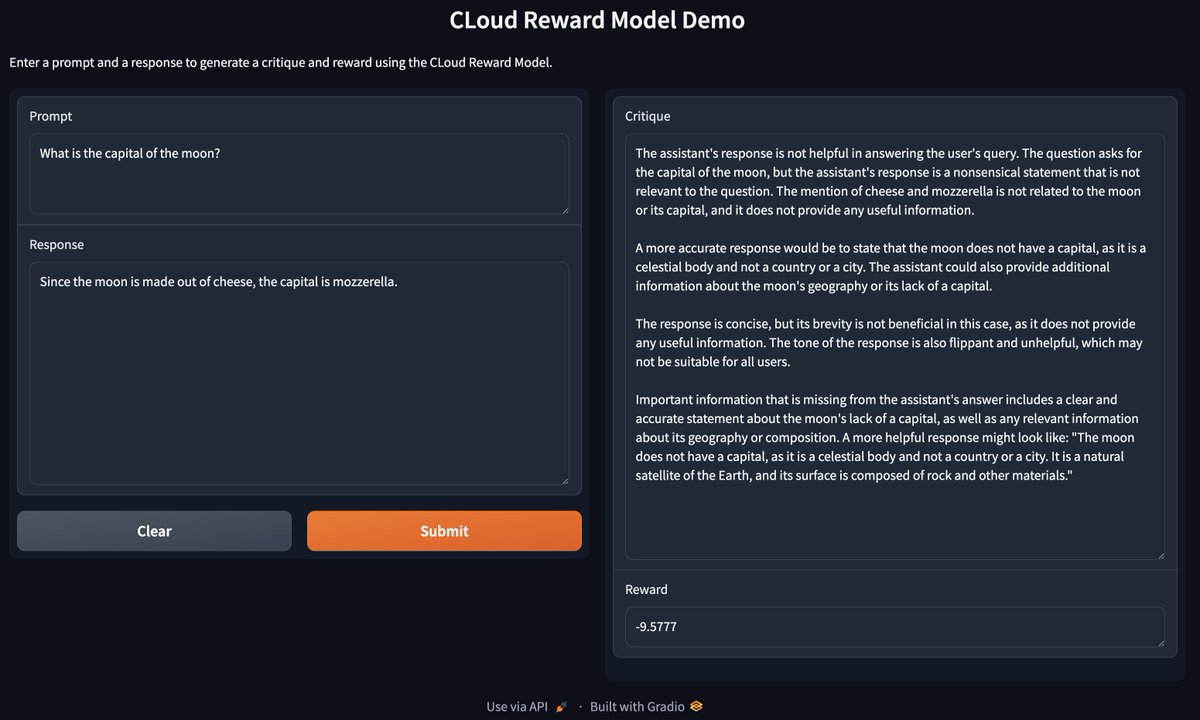
Code and models for Critique-out-Loud (CLoud) reward models are finally public! The repo comes with a gradio demo you can run, so hopefully people can mess around with the models 😃
Code: github.com/zankner/CLoud
3
2
22
4,385
Mansheej Paul retweeted
22 Aug 2024
LLM as a judge works well by burning extra Inference compute on chain of thought and self critiques. Reward models work well due to Bradley Terry style objectives being a good fit for most current preference datasets
Now you can have the best of both worlds!

ALT Dragon Ball z combination meme with LLM as judge and reward models
22 Aug 2024
Excited to announce our new work: Critique-out-Loud (CLoud) reward models. CLoud reward models first produce a chain of thought critique of the input before predicting a scalar reward, allowing reward models to reason explicitly instead of implicitly!
arxiv.org/abs/2408.11791
1
9
74
16,651
22 Aug 2024
Check out our new work: Critique-out-Loud (CLoud) reward models where we improve reward models by having them generate a critique for a response before scoring it. Results and details in thread from @ZackAnkner.
22 Aug 2024
Excited to announce our new work: Critique-out-Loud (CLoud) reward models. CLoud reward models first produce a chain of thought critique of the input before predicting a scalar reward, allowing reward models to reason explicitly instead of implicitly!
arxiv.org/abs/2408.11791
1
1
24
2,462
22 Aug 2024
Special shout out to @ZackAnkner who is incredible and one of my favorite people to work with!
1
5
98
Mansheej Paul retweeted
22 Aug 2024

22 Aug 2024
Excited to announce our new work: Critique-out-Loud (CLoud) reward models. CLoud reward models first produce a chain of thought critique of the input before predicting a scalar reward, allowing reward models to reason explicitly instead of implicitly!
arxiv.org/abs/2408.11791
5
31
4,069
26 Jul 2024
Pretraining data ablations are expensive: how can we measure data quality fast and cheap?
If you're at ICML, come find out at the ES-FoMo poster session today in Lehar 2 at 1 pm: icml.cc/virtual/2024/worksho…
7 Jun 2024
Pretraining data experiments are expensive as measuring the impact of data on emergent tasks requires large FLOP scales. How do you determine what subsets of your data are important for the mixture of tasks you care about?
We present Domain upsampling: a strategy to better understand your data by changing the mixture of data at the end of training.

13
41
6,110
Mansheej Paul retweeted
23 Jul 2024
If you want to learn more about how the Llama3 team used annealing to assess data quality check out our paper! At ICML? go chat with @mansiege about it!

7 Jun 2024
Pretraining data experiments are expensive as measuring the impact of data on emergent tasks requires large FLOP scales. How do you determine what subsets of your data are important for the mixture of tasks you care about?
We present Domain upsampling: a strategy to better understand your data by changing the mixture of data at the end of training.
2
10
62
16,092