
Joined July 2009
- Tweets 120
- Following 284
- Followers 83
- Likes 681
4 Photos and videos




fabio bonsignorio retweeted

May 25
The ONLINE and IN PERSON registration for ERAS 2026 2026.ieee-eras.org/ is still possible.
The conference will start on May 28th at 9:00 CEST.
Program here: 2026.ieee-eras.org/program/
Details here: ras.papercept.net/conference…
Link to registr: web.cvent.com/event/ea5d3378…
CU soon!!!
1
20
fabio bonsignorio retweeted

Apr 22
Also what I've seen.
Apr 21

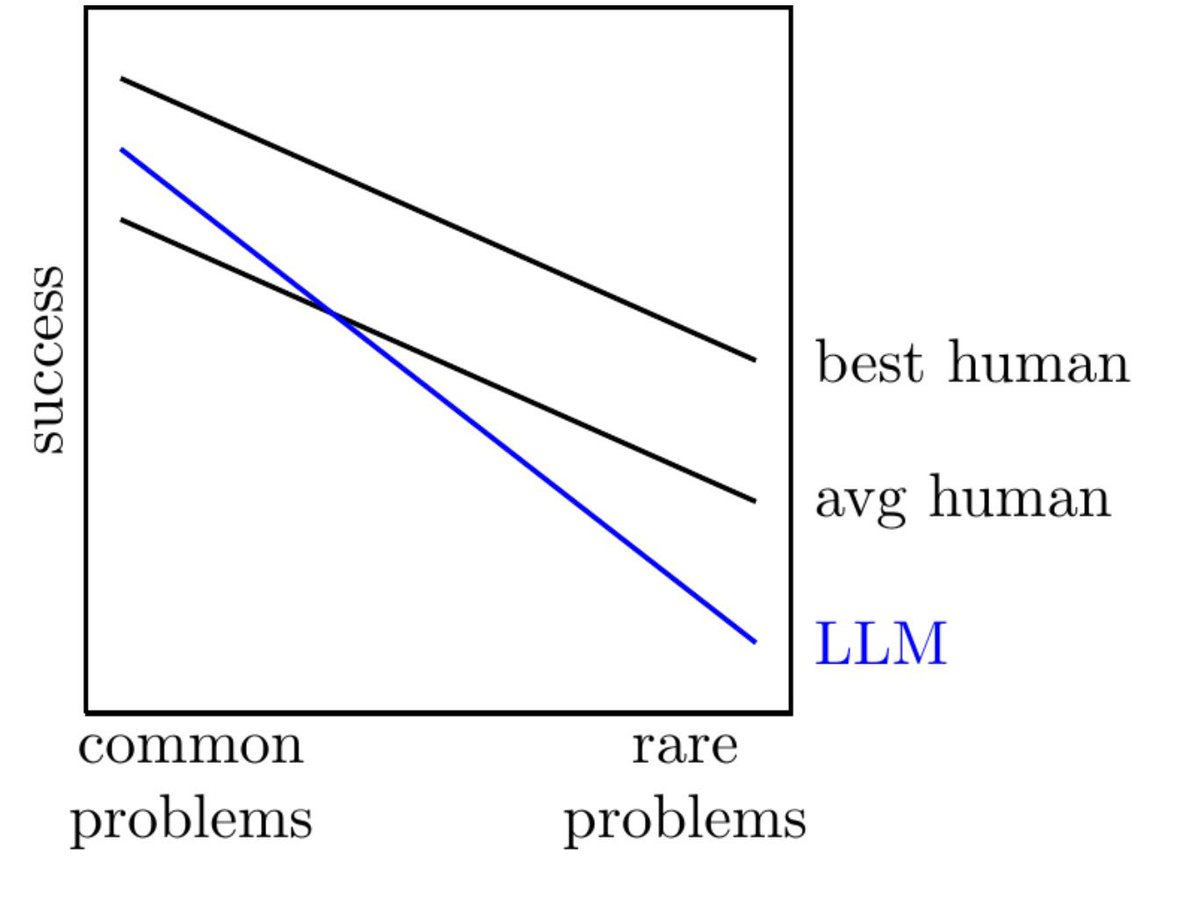
I think this image illustrates the capabilities of large language models very effectively.
LLMs are great at recombining existing knowledge. So, for questions outside your domain of expertise, or far from the frontier of knowledge, they are often much better than the average human. Here they can be incredibly helpful.
However, as you move closer to the frontier of knowledge, they become much worse.
Here, even the average human can become better.
I have seen this many times with my own eyes. When I work with an LLM at the frontier of knowledge, it often makes absurd mistakes that no intelligent person would make.
Internal contradictions within a few lines, dramatic forgetting of what happened two interactions earlier, and so on.
This limitation is literally built into the model: it approximates the most likely continuation given the previous input.
If there is enough relevant structure in the training data, it can perform very well. If it does not really know where to go, the output quickly becomes messy, and randomness takes over.
11
15
132
26,529

Good morning, world! 🌎
We have spectacular new high-resolution images of our home planet, all of us looking back through the Orion capsule window at our Artemis II astronauts as they continue their journey to the Moon.

ALT One-third of Earth peeking through the window of the Orion capsule. The planet is a dreamy pale blue, swirling with white clouds and reflected sunlight. Although Earth only fills a fraction of the image it is the brightest object in the image by far. The capsule window is surrounded by a thick frame held in place with bolts, reminiscent of a heavy duty airplane window. It is dark in the capsule, but the outlines of straps and various components of the capsule are visible. Brighter white components are visible in the upper right corner. Credit: NASA/Reid Weisman
3,340
29,049
185,985
9,409,985
The Orion spacecraft successfully separated from the upper stage of the rocket, and the "proximity operations" test is underway. The Artemis II astronauts are manually piloting Orion similarly to how they would if they were docking with another spacecraft.
1,445
10,939
95,099
4,837,015
fabio bonsignorio retweeted
Very excited about the prospect of Code-as-Policy (CaP) for Robotics!
Esp with recent rapid advances in agentic coding. CaP has potential to quickly combine VLA models with GOFE primitives into interpretable code, observe experiments, and iterate. Initial results are promising:
Apr 1

Robotics: coding agents’ next frontier.
So how good are they?
We introduce CaP-X: an open-source framework and benchmark for coding agents, where they write code for robot perception and control, execute it on sim and real robots, observe the outcomes, and iteratively improve code reliability.
From @NVIDIA @Berkeley_AI @CMU_Robotics @StanfordAILab
capgym.github.io
🧵
8
18
157
24,643
Liftoff.
The Artemis II mission launched from @NASAKennedy at 6:35pm ET (2235 UTC), propelling four astronauts on a journey around the Moon.
Artemis II will pave the way for future Moon landings, as well as the next giant leap — astronauts on Mars.
3,808
55,155
177,823
14,278,149
The weather's looking good for tomorrow's Artemis II launch, and our teams are getting the rocket ready for liftoff!
Read the latest updates on our mission around the Moon: go.nasa.gov/4tiFY4P
1,586
10,623
49,956
4,541,781
fabio bonsignorio retweeted

Transfer and lifelong adaptation remain central challenges for physical AI. Unlike LLMs, which benefit from more standardized interfaces, the complexity of robotic embodiments, environments, and human interactions - combined with limited pretraining data - renders pure generalization insufficient.
This roadmap by @Ken_Goldberg @davscaramuzza @aschoellig @RavinderSDahiya @petercorke @siddssrinivasa & Aude Billard nicely points out this and other key hurdles: arxiv.org/pdf/2507.19975
To dive deeper into the mechanisms for this, check out our survey (arxiv.org/abs/2312.01939) which summarizes the mechanisms and knowledge types needed to address this. While we only had a small section on the shift towards VLAs, the core ideas themselves transfer directly to this new paradigm! 🤖🚀
(And for the nano banana fans:)

4
7
1,374
fabio bonsignorio retweeted

Jan 7
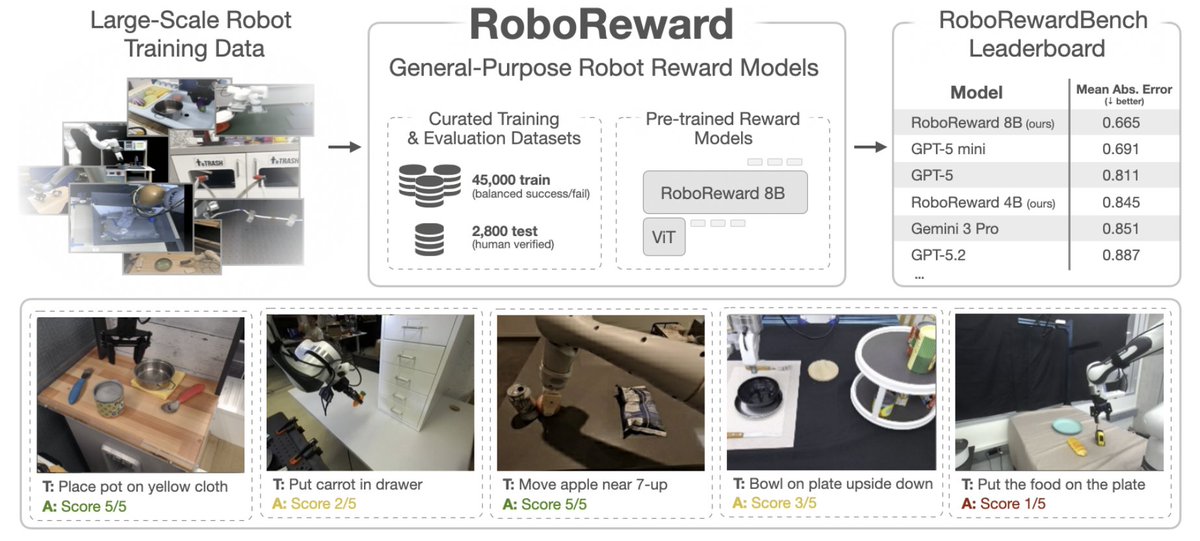
Studying generalist reward models is hard: robot datasets focus on successful demos, not failures.
We introduce:
- a large-scale reward modeling benchmark
- a data augmentation scheme
- a generalist reward model that outperforms frontier VLMs
Paper: arxiv.org/abs/2601.00675
Jan 7

Reliable rewards are a bottleneck for real-world RL for robotics: human labels are costly, and handcrafted rewards are brittle.
In RoboReward 🤖💰, we study VLMs as reward models and find they are unreliable across tasks, embodiments, and scenes.
Paper: arxiv.org/abs/2601.00675
10
64
476
43,782
fabio bonsignorio retweeted

27 Aug 2025
Humanoid robots are coming, but don't hold your breath waiting for them:
news.berkeley.edu/2025/08/27…
119
21
135
53,666
fabio bonsignorio retweeted
Jan 13
I agree. Either a risk taker will discover a breakthrough analogous to relativity or the DNA double-helix structure or there may be a lengthy plateau of incremental progress. We’re all placing bets and like baseball, there’s no clock on the game.
Jan 12

What makes robotics so exciting right now is that everyone is making a different bet. World models. Learning from humans. Scaling real-world data. Simulation. Reasoning. New, affordable data-collection hardware.
No one has the final answer yet.
2
58
7,503

'Hamilton' turned 10 this summer. In @Reuters latest Culture Current, Leslie Odom Jr. speaks about returning to Aaron Burr, the show’s cultural legacy, and why it still resonates in 2025. Read the full Q&A: reut.rs/46nHOce
3
6
17
32,046
fabio bonsignorio retweeted
18 Sep 2025
Misterious AIFORS member giving a cool talk at ICDL in Prague 😎

1
47
fabio bonsignorio retweeted
16 Sep 2025
In Prague for ICDL 🙂Looking forward meeting old and new friends!
1
46

Amazing that @SchmidhuberAI gave this talk back in 2012, months before AlexNet paper was published.
In 2012, many things he discussed, people just considered to be funny and a joke, but the same talk now would be considered at the center of AI debate and controversy.
Full talk:
36
230
1,479
353,352

27 Aug 2025
SpaceX’s Giant Mars Rocket Completes Nearly Flawless Test Flight nytimes.com/2025/08/26/scien… via @NYTimes
7

Great work by the SpaceX team!!

Watch Starship's tenth flight test → spacex.com/launches/starship… x.com/i/broadcasts/1lPKqvNwL…
3,782
4,816
45,526
7,496,845

Starship’s tenth flight test pushed the limits and provided maximum excitement along the way → spacex.com/launches/starship…



799
2,565
16,791
1,761,913