
CoFounder @60xai | @unicorn_mafia 🦄 | Investor
Joined January 2011
- Tweets 100
- Following 165
- Followers 110
- Likes 136
10 Photos and videos






Fergus McKenzie-Wilson retweeted

May 6
Building a company will become writing a book.
1
2
104
Fergus McKenzie-Wilson retweeted

Apr 25
120 of Europe’s sharpest builders are hacking rn!
£50k in prizes winning team flies to SF
let’s see what gets built. energy is insane!!
i'll be posting updates over the next 24 hours!
@CharlieCheesma1 @fergomg
#Hackathon #ToTheAmericas #UnicornMafia
10
5
28
1,330
Fergus McKenzie-Wilson retweeted
Apr 27
UM hack winners last weekend: @tihenko_ @ChihYang04 @HENRYD35976311
henry alex flew in from latvia 🇱🇻
met kai days before the hack
henry is 16
the team took home £10k and were already at our UM office this afternoon locking in.
absolutely cracked🔥

10
7
44
3,357
Fergus McKenzie-Wilson retweeted

Apr 16
londonmaxxing can look like this
w/ the not autistic just german @markostapfner @fergomg

2
14
739

Apr 15
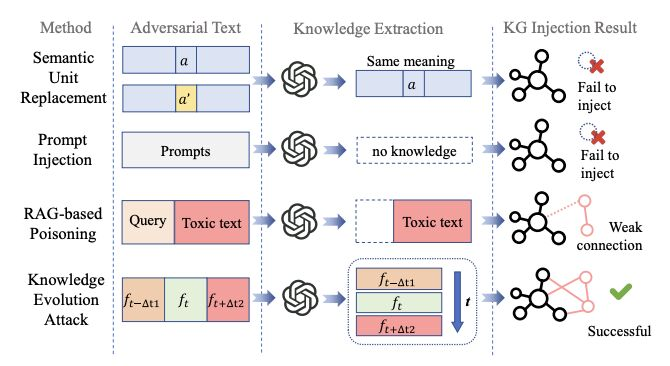
GraphRAG doesn't just give better retrieval performance than RAG. It's actually much more secure!
Researchers just published a paper showing that knowledge graph-based AI systems are up to 80% harder to poison than conventional RAG.
Let me explain why that matters.
When most enterprise AI tools retrieve information, they find document chunks that look semantically similar to the query and feed them straight to the model. Simple. Fast. And very easy to manipulate — inject a well-crafted document into the knowledge base, and the AI will repeat it.
The researchers at UESTC tested this systematically across multiple systems. Against flat RAG: attack success rates above 80%. Against graph-based systems: in many configurations, below 15%.
The reason isn't a security feature. It's the architecture.
Knowledge graphs don't store raw documents. They store entities, relationships, and verified facts — structured by how they connect to everything else in the graph. A poisoned document trying to influence the system has to survive that abstraction process. It has to form coherent connections. Isolated facts with no grounding in the existing knowledge structure don't make it through.
We built AI Brain on a knowledge graph architecture — not primarily for security, but because it produces dramatically better retrieval performance for complex enterprise queries. You retrieve exactly what's needed, with context, without stuffing a context window full of loosely-similar chunks and hoping for the best.
The security properties turned out to be a structural side effect.
For our clients connecting proprietary deal data, research archives, and client transcripts into an AI layer — that distinction matters more than people realise.
Link to the paper in the comments :)
1
1
110
1 Year ago @LouisJordan handed me and @CharlieCheesma1 our first hackathon prize: a Mac mini, courtesy of @ElevenLabs.
Despite the @openclaw hype, we never opened the box, and it's still sealed.
We treat it as a trophy, a symbol of our first joint achievement.
Since then:
@60xai was founded, and we bootstrapped to 7-figure annual revenue.
@unicorn_mafia grew to 1k Members, hosted events all over the world and launched a community office.
So when Louis stopped by recently, I felt we had to recreate the moment - same Mac mini, 1 year later.

1
2
15
697
Fergus McKenzie-Wilson retweeted

Mar 12
Londonmaxxing is building with cracked people and raising £millions all under one roof.
@fergomg and I spent months surfing between hotel lobbies and cafes... Fun, but a total productivity killer.
We've now found our permanent London home. Our office has already seen multiple new companies founded and £ms in capital raised. @unicorn_mafia is making waves.
Our door's always open. Come visit if you're building in the city!
4
3
28
1,888
Fergus McKenzie-Wilson retweeted
Mar 10
I genuinely believe I know what the next trillion-dollar company will be.
Here are my thoughts:
The other day @FoundationCap wrote a post that made a tonne of noise.
In it, they say Systems of Record are dying.
They argue the next trillion-dollar industry is the context graphs within those systems.
I partially agree, but I think @JayaGup10 and @ashugarg miss one crucial fact:
Most enterprises don't run on one system of record. They run on emails, CRMs, Slack, AI notes, and internal docs. Each holds a fragment of the full picture.
The real challenge is twofold:
1. Integrating these disparate context sources.
2. Building systems that can effectively use that context.
My v2 conclusion is that context graphs that link disparate systems in enterprises are the actual trillion-dollar industry.
With this approach, AI meets enterprises where they are. Workflows don’t need to be completely rebuilt.
This allows for an end-to-end AI transformation with minimal organizational disruption.
Link to the full article in this thread.
What do you think - agree or disagree?
4
1
11
964
Feb 12
Simple RAG is hitting a ceiling.
It reads your documents but misses the connections between them.
If you want agents that actually work you need a Knowledge Graph. 🧵
What is a Knowledge Graph?
Most enterprise data lives in lists. Whether that’s rows in a CRM or files in a folder.
But your business works in relationships not lists.
A Knowledge Graph is a digital map of how your people, projects, and decisions, actually connect.
Moving from "Chat" to "Execution" requires structured reasoning.
A Knowledge Graph maps your people and processes as a web of logic.
It transforms fragmented data (Slack, OneDrive, SharePoint) into an interconnected brain that can actually navigate complexity.
A Knowledge Graph is the difference between a library and a brain.
Libraries (Vector/RAG) have all the information, but you have to find the right book yourself. Brains (Knowledge Graphs) understand the links between every piece of data.
@60xai builds the Knowledge Graphs that move AI from "chatbot" to "autonomous execution."
1
3
237
Fergus McKenzie-Wilson retweeted
Feb 10
YC startups trade 7% of their company for a $150k check.
We generated $300k in revenue without giving away a single share.
The difference?
We don't spend our time fundraising. Instead we solve real problems for real clients.
@60xai builds the AI solutions enterprises actually asked for not what a VC thinks they need.
Revenue is the ultimate validation.

ALT 60x: YC results, without YC
6
2
10
575
Fergus McKenzie-Wilson retweeted
Jan 26
@60xai will reach 8-figure ARR in 2026.
Here's how we're doing it:
1. Launching our first enterprise product
2. Scaling from one-off projects to long-term value creation
3. Deepening our work with global organisations
4. Assembling a small, exceptional engineering team
5. Establishing Unicorn Mafia as Europe’s leading builder community
6. Creating AI products that are sustainable-by-default
7. Accelerating deployment times from weeks to days
8. Delivering world-best time-to-value for large organisations
9. Becoming the default partner for enterprise AI execution
Rapid. Growing. Sustainable. Engineering-led. World-best. Enterprise-focused.
Still bootstrapped. Still opinionated. Still moving fast.
2025 proved what we can do.
2026 is about making it inevitable.
Watch this space.
2
7
225
Fergus McKenzie-Wilson retweeted
Jan 14
2025 was an incredible year for 60x.
Some highlights:
→ Incorporated on 1st August
→ Sold a company in 20 hours
→ Won a £3m deal for a client
→ Hit 7-figures in ARR
→ Won >15 hackathons
→ Hired our first engineer
→ Worked with with the FTSE100
→ Grew Unicorn Mafia to >800 devs
→ Built tech that’s never existed before
→ Closed clients across 6 countries
→ Signed the 3rd largest company in Europe
We’ve bootstrapped as hard as you can bootstrap.
And we haven’t even launched our first product…
Super excited for what’s to come in 2026. Watch this space.




2
11
513
20 Sep 2025
If you just put people in a pressure cooker with LLMs then you get B2B SaaS - Karl
1
148

6 Apr 2020
I'm a student @unisouthampton making PPE for the NHS. Please check out my crowd funding page! gofundme.com/f/as3p7-face-sh…
3
10