
Lecturer of Computing Sciences at @uniofeastanglia. #TrustworthyAI, #ML, #DeepLearning, and applications to #NLProc and all types of data. Views Are My Own.
Joined November 2010
- Tweets 1,283
- Following 1,046
- Followers 178
- Likes 2,225
1 Photos and videos

Farhana Ferdousi Liza retweeted

3 Jul 2023
Can anyone explain to me why it is methodologically sound to use an LLM to evaluate another LLM?
70
27
362
140,734
Farhana Ferdousi Liza retweeted

30 Jun 2023
Training on synthetic data cannot lead to new knowledge discoveries. Training on synthetic data is a process of transforming one representation of knowledge into another. Any knowledge discovered by the second system must be implicit in the data generator. 1/
39
24
201
230,573

13 May 2023
Interesting!!! See the comments of the original post for the debate/correction/perspectives.
12 May 2023

Mathematics from beyond the edge.
This image, widely circulating on the Web, begins with 2 2 = 4.
We shiver in delight, or perhaps a madness bordering on insanity.
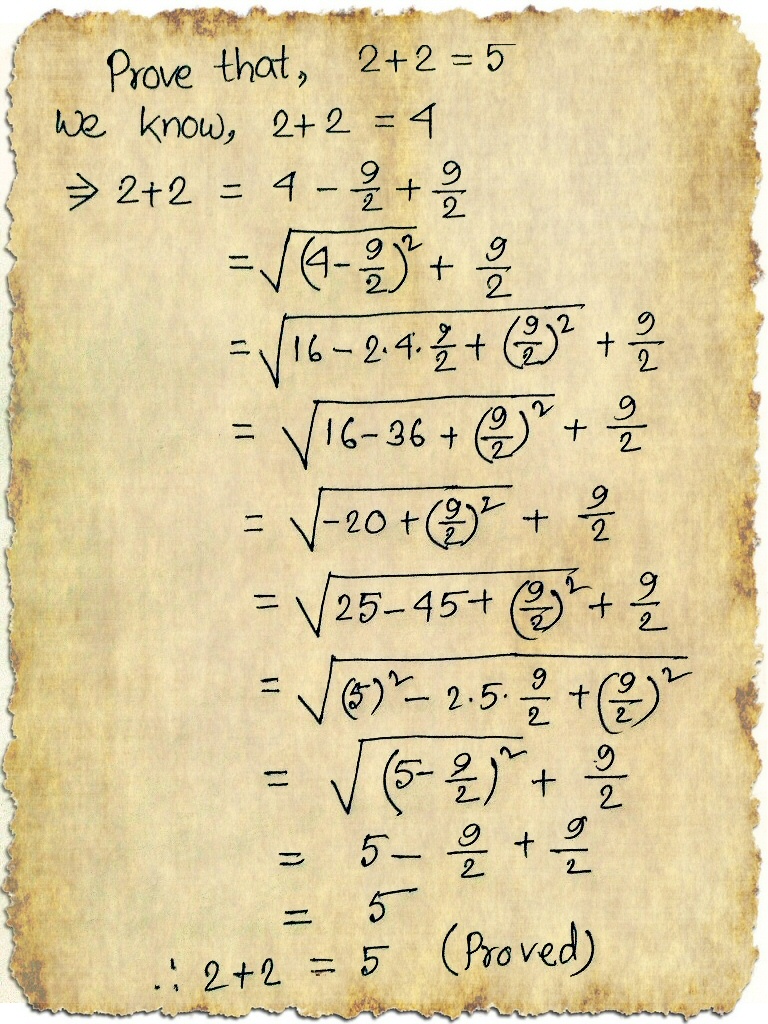
75
Farhana Ferdousi Liza retweeted

3 May 2023
Dr @fferousi @uniofeastanglia presents 'Trustworthy #AI for social good' as part of session 6: Governance, ethics and sustainability. #Data2Life for #mentalhealth

3
5
207
9 Apr 2023
It has been a great learning experience working on @wellcometrust data prize!
27 Feb 2023

Great working with the wonderful team of @KieranBalloo @fferousi and Alex and Caitlin from @Miricylhealth
1
2
104
Farhana Ferdousi Liza retweeted

14 Nov 2022
Breaking News: Academic workers across the University of California system walked off the job on Monday as part of a strike over pay and benefits. nyti.ms/3g5d5cy
26
242
765
Farhana Ferdousi Liza retweeted

20 Aug 2022
If someone wrote a book on how to build a competent organization out of incompetent people, it would be a historic bestseller.
12
2
35
Farhana Ferdousi Liza retweeted

17 Aug 2022
10 mental concepts that will make you way smarter:
46
521
2,308
Farhana Ferdousi Liza retweeted

13 Aug 2022
If you want to perform better under pressure, read this:
155
1,406
7,202
Farhana Ferdousi Liza retweeted
10 Aug 2022
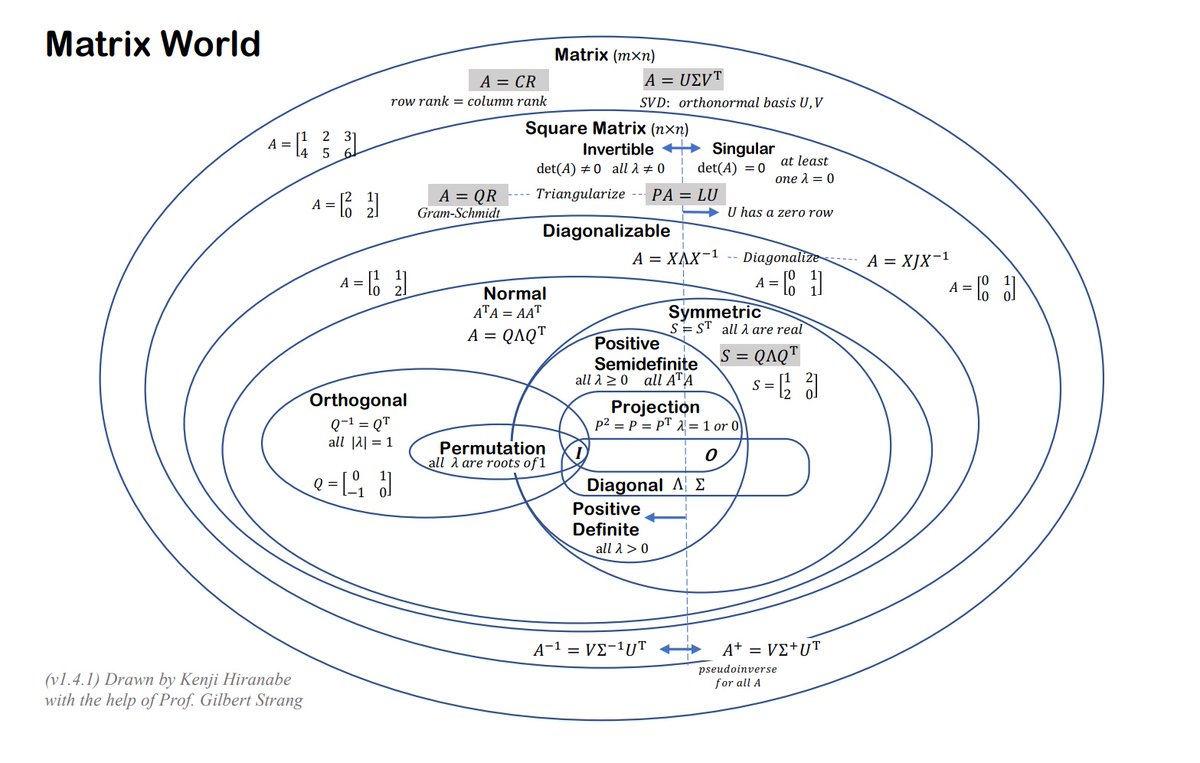
All of linear algebra in one diagram:
61
1,190
6,228
Farhana Ferdousi Liza retweeted
3 Aug 2022
10 mental concepts that will make you way smarter:
104
1,809
7,064
Farhana Ferdousi Liza retweeted

3 Aug 2022
We (@BeEngelhardt, @NailaMurray and I) are proud to announce the creation of a Journal-to-Conference track, in collaboration with JMLR and conferences NeurIPS 2022, ICLR 2023 and ICML 2023!
neurips.cc/public/JournalToC…
iclr.cc/public/JournalToConf…
icml.cc/public/JournalToConf…
18
193
1,040
Farhana Ferdousi Liza retweeted

1 Aug 2022
Today's the first day of the Deep Learning Theory Workshop & Summer School at the @SimonsInstitute. Excited to see everyone! Schedule is here, and talks will be streamed & recorded: simons.berkeley.edu/workshop…
3
18
99
Farhana Ferdousi Liza retweeted
1 Aug 2022
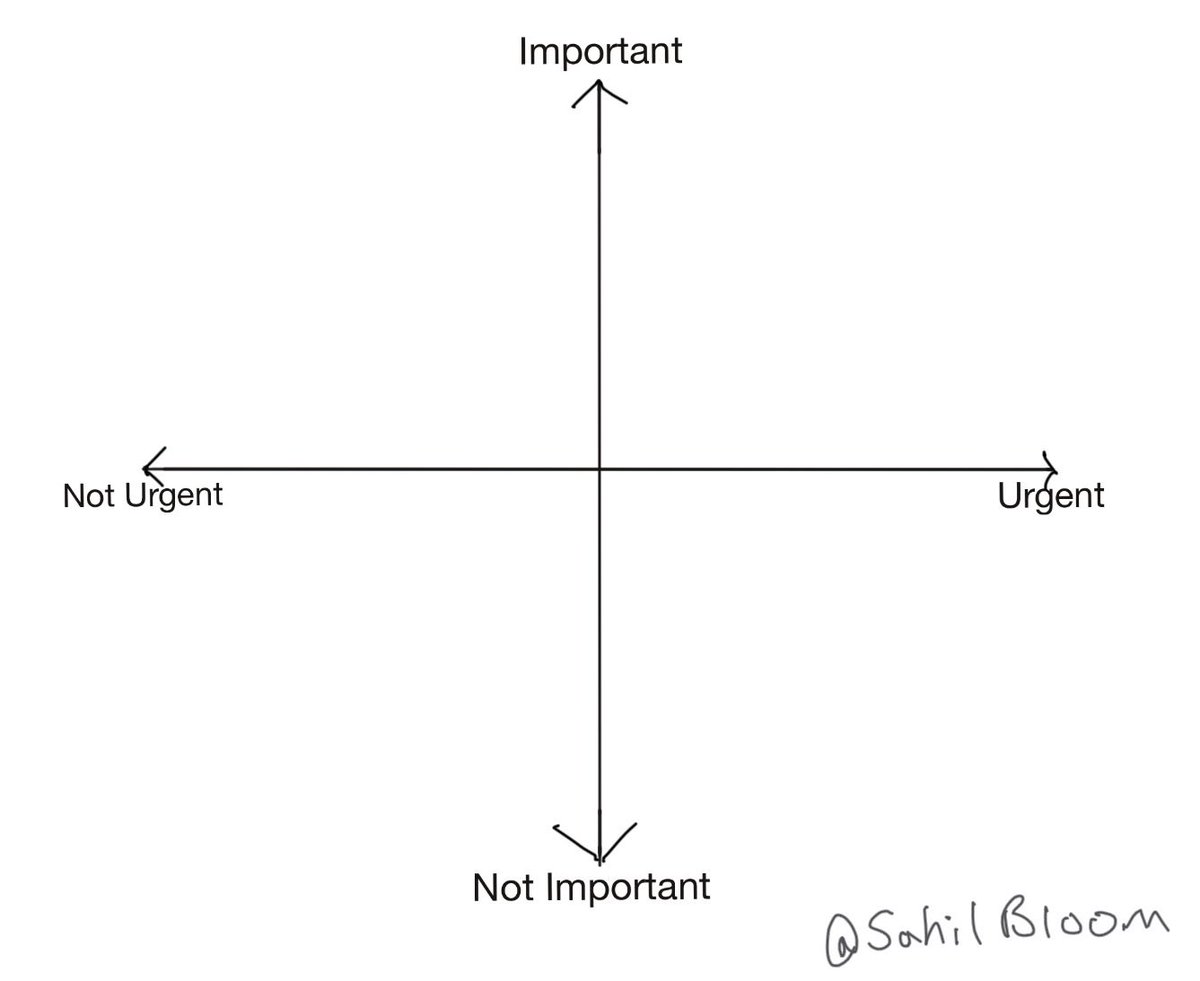
The Eisenhower Decision Matrix is a 2x2 matrix.
It’s a visualization tool that forces you to differentiate between the urgent and the important to prioritize your time accordingly.
It was popularized by @StephenRCovey in his 7 Habits of Highly Effective People.
How it works:
17
187
1,458
Farhana Ferdousi Liza retweeted
1 Aug 2022
Machine learning is not just a computational tool for the sciences. It's, even more, a conceptual tool.
1
1
30
Farhana Ferdousi Liza retweeted
30 Jul 2022
If you want your science to be revolutionized by machine learning, start by building a large, high-quality data repository.
7
26
203

According to IBM’s 2022 Cost of a Data Breach Report, data breaches of critical national infrastructure cost on average $1M more than those hitting other organisations. See how deploying a zero trust environment can help mitigate these losses via @techmonitorai:

2
10
36
Farhana Ferdousi Liza retweeted

29 Jul 2022
This ICML, I was (pleasantly) surprised to see a bunch of papers on causal inference, specifically on how machine learning can help in estimating causal effects.
Here are five cool ones. 🧵
8
97
467
Farhana Ferdousi Liza retweeted

20 Jul 2022
I'm launching a new Twitter service.
You tweet me the name of a paper you're going to cite and for what reason, and I'll respond with a better paper to cite, if one exists.
33
17
380