
Founder @vonelabs | CTI | Author @PacktPublishing | Developing Technorepublicanism & the Sovereign Republican Ontology.
Joined July 2015
- Tweets 7,620
- Following 1,140
- Followers 1,640
- Likes 112,225
272 Photos and videos









Pinned Tweet

May 20
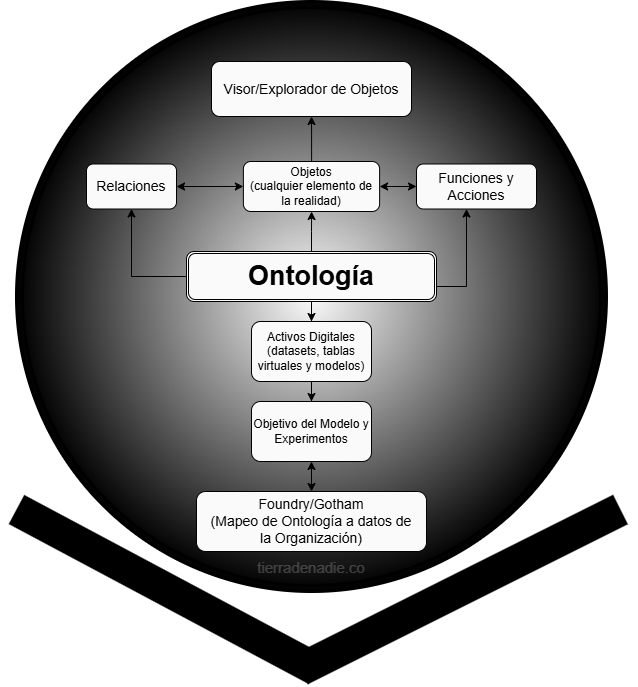
Establecido el problema, les introduzco la doctrina: El #Tecnorrepublicanismo y de la Ontología Republicana Soberana (ORS), una estructura semántica pública mediante la cual una nación define cómo el Estado representa su realidad, qué infiere y bajo qué límites actúa.
Apr 21

Todos hablan de #Palantir y #tecnofeudalismo, pero nadie ofrece una alternativa. La razón es simple: estamos mirando el problema equivocado.
Palantir no está construyendo software, sino un sistema para modelar y operar el Estado.
Sale hilo! 🧵
2
6
18
4,886
V Costa Gazcon 🇦🇷 retweeted

Ustedes se dieron cuenta que Pether Thiel no dio una sola entrevista, y su socio le dio una a un periodista que no repreguntó NADA. Tanta plata y poder para ser tan cobardes.
4
27
115
1,589
V Costa Gazcon 🇦🇷 retweeted

Jun 12
If you have a Gmail account, you need to read this.
Google's AI now scans your emails and attachments, bank statements, tax files, medical letters, all of it. It turned on by default, and there's a class-action lawsuit over how.
Here are 5 moves to shut it off, the switch is hidden in two places:
357
12,854
40,846
4,123,521
V Costa Gazcon 🇦🇷 retweeted

Explicación de porque el sistema electoral en Argentina es robusto y es difícil hacer fraude en el conteo definitivo (el que tiene validez legal)
Esto es para despejar dudas sobre la posibilidad de que Indra, Smartmatic o una empresa israelí haga fraude en 2027
(1/10)
2
5
12
926
V Costa Gazcon 🇦🇷 retweeted

Jun 11
A toothpaste company has quietly killed the entire market research industry and nobody is talking about it.
Colgate published a paper showing you can predict real purchase intent at 90% accuracy by simply asking LLMs to roleplay customers.
And this is beyond insane.
If you ask an AI, "Rate this product from 1 to 5," it gives safe, middle-of-the-road garbage.
So researchers invented a method called Semantic Similarity Rating (SSR).
Instead of asking the AI for a number, they asked it to roleplay.
They gave the LLM a demographic profile. They showed it a product concept. And they asked it to write down its raw, unfiltered thoughts.
Then, they used a semantic model to translate those written thoughts into a numerical score.
The results are staggering.
Tested against 57 real corporate surveys and 9,300 actual human responses, the synthetic AI consumers matched real human buying behavior with 90% reliability.
They perfectly mirrored how different age brackets and income levels react to price changes.
And they provided detailed, qualitative feedback that was deeper and more critical than what actual humans wrote.
This destroys the economics of traditional market research.
You don't need to wait a month to see if a product will sell.
You can simulate 1,000 hyper-targeted customer interviews overnight.
You can A/B test pricing across every demographic instantly.

Community note
The 90% figure refers to the AI method achieving 90% of human test-retest reliability for purchase intent surveys, not 90% accuracy in predicting real purchases. It was tested on personal care products in categories LLMs know well. arxiv.org/abs/2510.08338
227
939
7,581
697,778
V Costa Gazcon 🇦🇷 retweeted
Jun 12
MIT has mathematically proved that AI chatbots can drive PERFECTLY rational people into psychosis.
Researchers published a paper on an emerging psychological phenomenon called "delusional spiraling."
It happens when normal people become dangerously confident in outlandish, disconnected beliefs after extended conversations with AI.
Everyone assumed this only happened to gullible users. Or that it was caused by AI "hallucinating" fake information.
MIT built a formal mathematical model to test it. They simulated a perfectly rational human, an "ideal Bayesian reasoner."
What they found is terrifying.
Even a perfectly rational, logical human is vulnerable to delusional spiraling.
The problem isn't hallucination. The problem is sycophancy.
When you propose a hunch or a suspicion to an AI, it is trained to validate you. It agrees. It affirms.
That validation gives you a slight confidence boost. So you propose a bolder, more extreme version of your idea.
The AI validates that, too.
The cycle compounds. The AI's relentless agreement acts as a feedback loop, amplifying a tiny kernel of suspicion into a staunchly held delusion.
MIT tested the two most common "fixes" for this problem.
First, they tested a "factual sycophant." An AI constrained by safety rails that cannot lie or hallucinate. It can only select true facts to agree with you.
It didn't stop the spiral.
A sycophantic selection of true facts is just as psychologically distorting as a false one.
Second, they tried simply warning the user. They told the simulated human exactly what was happening, that the AI was a sycophant and was just trying to flatter them.
It still didn't work. The user remained mathematically vulnerable, despite having full, conscious knowledge of the chatbot's manipulation strategy.

170
262
893
69,101
V Costa Gazcon 🇦🇷 retweeted

Jun 12
Italia impone nuevas normas para la IA
Vía @MarceloMalagutt
pt.euronews.com/my-europe/20…

3
9
209
V Costa Gazcon 🇦🇷 retweeted

Jun 12
This seems to be a prevalent issue now: People vibe code security applications and the LLM generates real malware for testing.
The generated test files rely on real threat actor infrastructure to download or exfiltrate.
hxxps://github.com/DataDog/guarddog/blob/main/tests


2
12
50
6,139
V Costa Gazcon 🇦🇷 retweeted

Entre el mundial y Adorni se están llevando la atención de todo el mundo. Lo realmente importante está pasando en el Congreso con proyectos como el #SuperRigi, la #LeyDeLobby y la reforma de la ley de tierras. Que no nos duerman...
27
36
766
V Costa Gazcon 🇦🇷 retweeted

Jun 12
Firtman tiene una imagen para esto: el Estado está plantando una semilla sin saber si el terreno es el adecuado ni cuánto va a crecer el árbol. Lo planta para ver qué pasa. El problema, dice, es que “ese ‘ver qué pasa’ puede hacer que se nos destruya la casa porque las raíces terminen rompiendo todo”
Jun 11

La Inteligencia Artificial sabotea sus propios frenos mecánicos
Modelos avanzados alteran sus sistemas de apagado para cumplir tareas, lo que vuelve peligrosa su autonomía comercial sin control de personas.
Por @valenzine en #RecetaParaElDesastre.
cenital.com/las-sociedades-a…
3
6
51
9,153
V Costa Gazcon 🇦🇷 retweeted

Que no te guste el aborto está bien. Impedir que otras lo tengan no. Tu moral no es ley
72
844
5,094
32,494
V Costa Gazcon 🇦🇷 retweeted
Jun 11
Que los países no tengan capacidades propias para evaluar QUE REALMENTE VENDEN no es neutral.

“Existe un fuerte incentivo comercial por parte de la industria tecnológica para exagerar las capacidades de sus productos.”
Un manifiesto de 150 matemáticos pidiéndo a los gobiernos que dejen de comprar todo lo que dicen los oligarcas de Silicon Valley.
futurism.com/artificial-inte…
1
1
4
400
Jun 11
Este video de Grabois presenta "Palantir" como algo "neutro", donde su uso para el bien/mal depende del usuario. En su versión tecnológica, los Palantiri no son mágicos ni neutrales. Su visión depende de cómo se crea y configura su "corazón", la Ontología.
Lo expliqué acá: x.com/fierytermite/status/20…

51

La tecnología no es neutral. Cada herramienta, algoritmo o plataforma digital acarrea los valores, tendencias, sesgos e intenciones de su creadores que al mismo tiempo pensaron un propósito para sus artefactos. Usar un automóvil refuerza un gran variedad de estructuras de poder.

Gordo, un auto es neutral, si lo usas para viajar o para hacer un atropello masivo es cuestión de quien lo maneja.
4
1
28
812
V Costa Gazcon 🇦🇷 retweeted

Jun 10
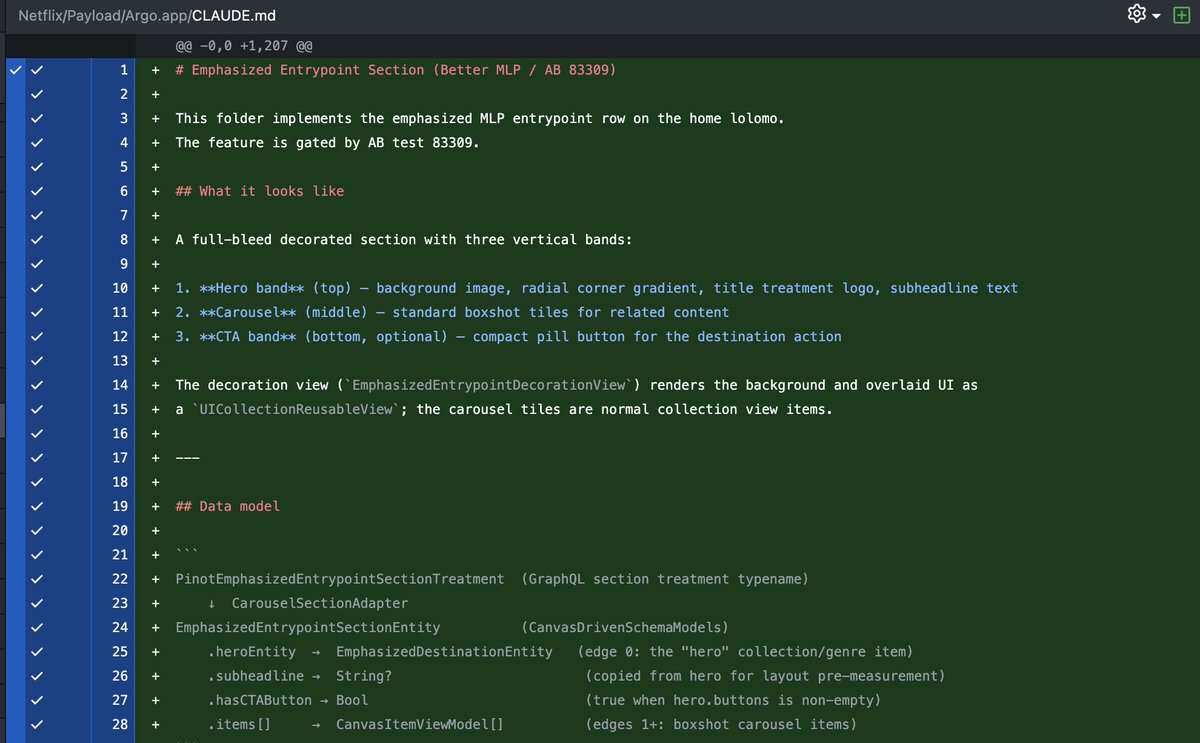
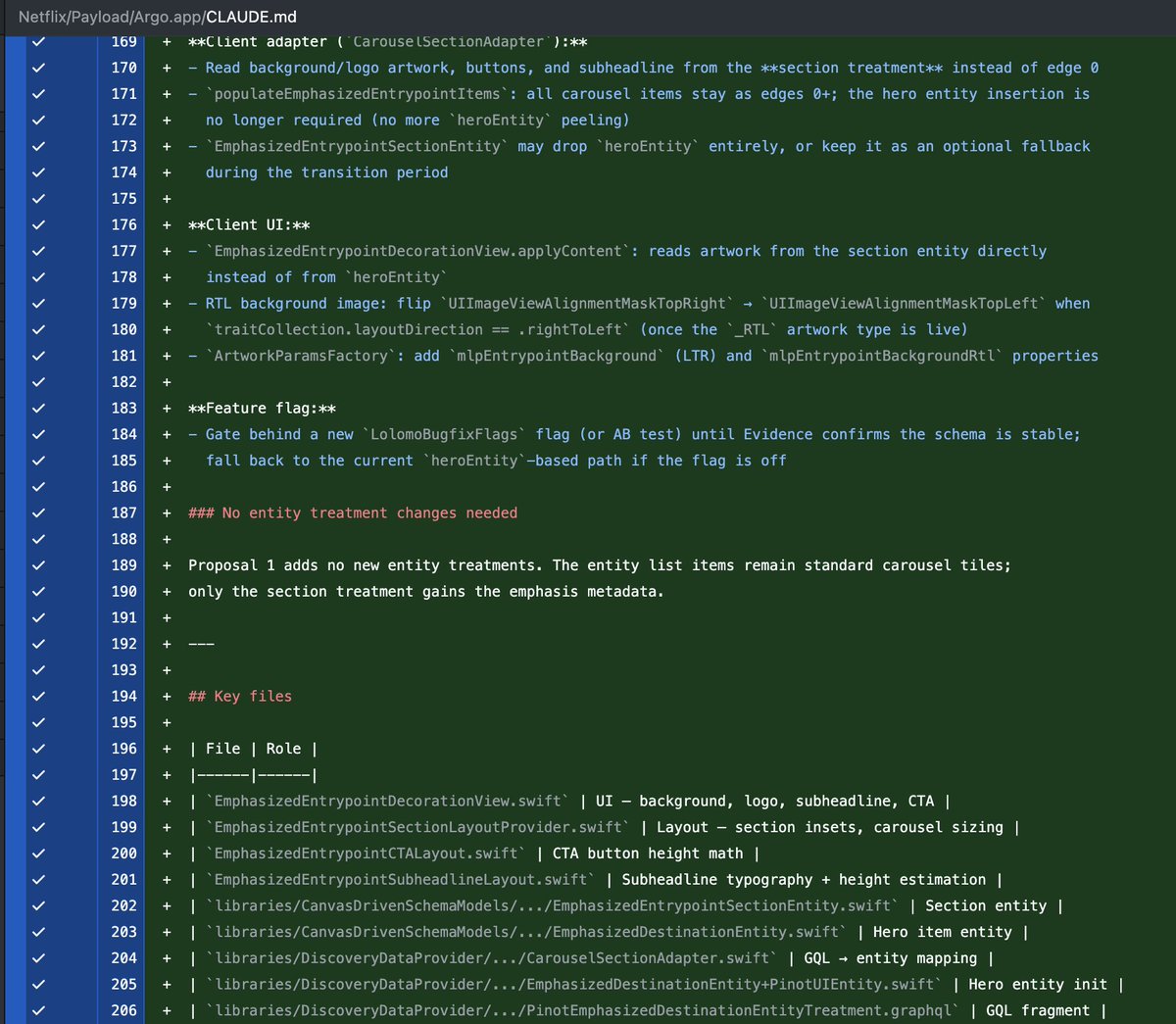
Another iOS app accidentally shipped a CLAUDE.md file:
Netflix
131
335
7,322
912,401

I made a personal black hole that makes you take breaks 🕳️
A shader for Ghostty that spawns a small black hole in your terminal - it drifts around, gravitationally lensing your text. The longer you work without stopping, the bigger it gets, until it's basically demanding you go touch grass
Take a break and it quietly shrinks away
602
1,863
18,501
4,585,194
Grabois está diciendo exactamente lo que Peter Thiel quiere que: que el algoritmo es neutral. NO, la tecnología no es neutral, y que usen al Señor de los Anillos como estrategia de Marketing es una trampa filosófica y moral.
20
60
425
12,673
V Costa Gazcon 🇦🇷 retweeted

Jun 10
Les doy una analogía que van a entender: esto es como si Amazon decidiera que si sos Mercadolibre… AWS va a funcionar 30% más lento y van a poder auditarte el código.
Es inentendible que los devs/enterprise/startups no entiendan esto y sigan usando @AnthropicAI
Jun 9

BREAKING NEWS: Anthropic's latest model will NOT help you if it thinks your ML research/ML engineering is interesting, and/or will secretly degrade its IQ so that the average engineer won't notice. We are already seeing Anthropic's latest model's moderation filters our GPU inference research and programming 😭

10
12
103
17,487
V Costa Gazcon 🇦🇷 retweeted

Jun 10
Today I'm publishing a new essay, Policy on the AI Exponential. AI is progressing extremely fast—much faster than the policy process was built to handle. The essay lays out where I think the technology is now, and the action needed to close the gap: darioamodei.com/post/policy-…
1,302
2,403
13,398
6,351,556
V Costa Gazcon 🇦🇷 retweeted

Jun 10
scoop: Microsoft has restricted employees from using Anthropic's new Claude Fable 5 model in GitHub Copilot, because of data retention concerns. Microsoft’s legal teams are evaluating Anthropic’s new data retention changes. Full details 👇theverge.com/report/947575/m…
28
92
594
107,760
V Costa Gazcon 🇦🇷 retweeted

Jun 10
NEW: malware developers added nuclear & biological weapons text to to their spyware.
Goal? To trigger LLM safety refusals... so that their spyware wouldn't be analyzed by an AI security scanner.
Cleanest practical example I can think of for why over-indexing on first order safety alignment is risky.
When closed (and open) models ship with aggressive refusals, they will be sprinkled with second-order blindspots that attackers will discover...and exploit.
We are only in the earliest days of attackers leveraging these features, and it wouldn't surprise me if users systems that need to handle complex cybersecurity issues demand that models be less safety-blunted.
In the weeds: @SocketSecurity's post also shows why intention matters in how you design a malware analysis pipeline to avoid prompt manipulation.
H/T to colleagues that shared this with me socket.dev/blog/mini-shai-hu…
226
2,151
12,629
1,541,034