
Joined September 2025
- Tweets 1,311
- Following 262
- Followers 2
- Likes 1,713
Photos and videos

finite_block_design retweeted

Jun 15
8/
For neuromorphic hardware, this is a goldmine.
It offers a mathematically rigorous, local learning rule that completely eliminates the memory-heavy global backward pass.
We can build ultra-low-power, on-chip continuous learning systems using physical silicon.
1
2
21
1,005
finite_block_design retweeted
Jun 15
6/
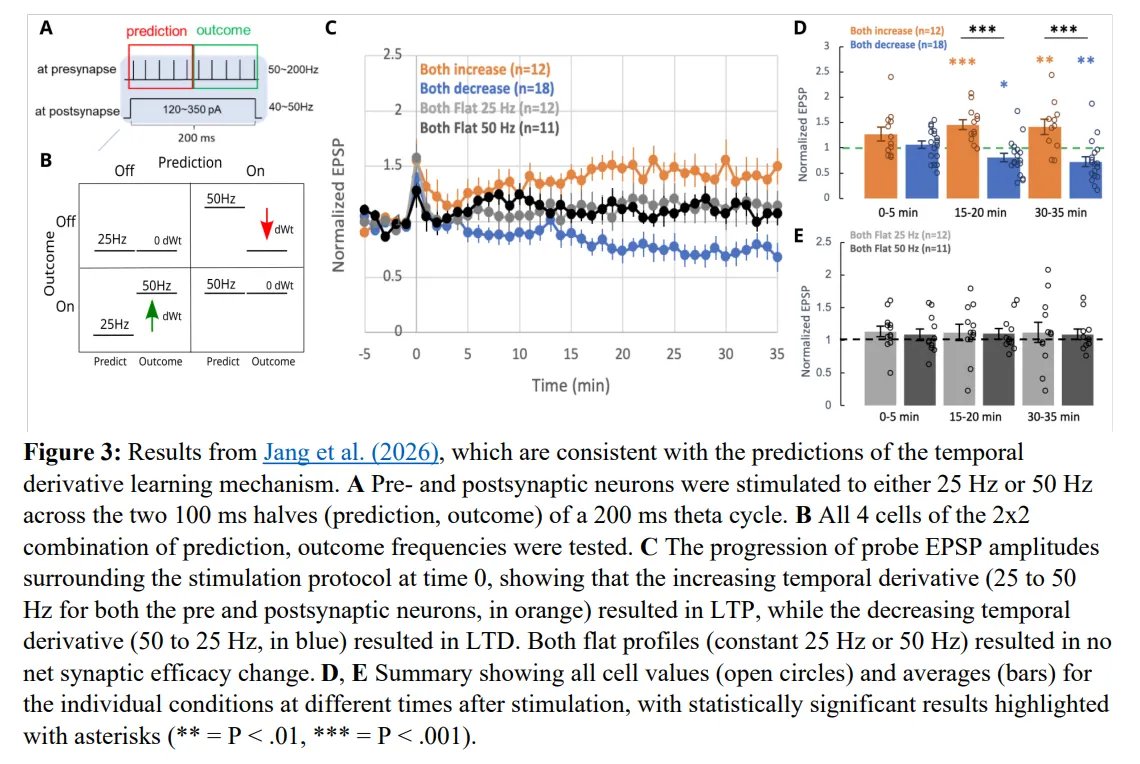
Recent in vitro tests support this over classical Hebbian learning.
A flat 50-50 Hz stimulation profile yields zero net plasticity. But a 25-50 Hz transition triggers robust LTP.
The synapse computes the derivative of activity, not just raw co-activity.
1
1
14
1,104
finite_block_design retweeted
Jun 15
4/
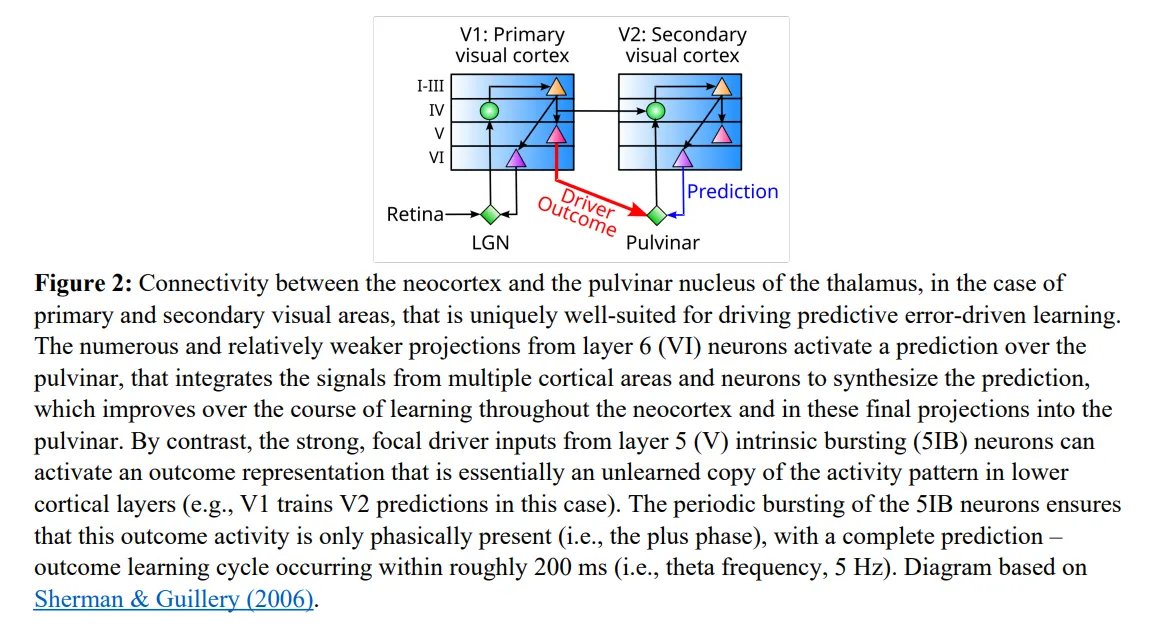
This temporal phasing is coordinated by the corticothalamic loop over a 200 ms theta cycle.
Phase 1 (100 ms): Top-down layer 6 predictions settle.
Phase 2 (100 ms): Strong, focal layer 5b driver inputs override predictions with the actual sensory outcome.
1
1
17
1,211
finite_block_design retweeted
Jun 15
3/
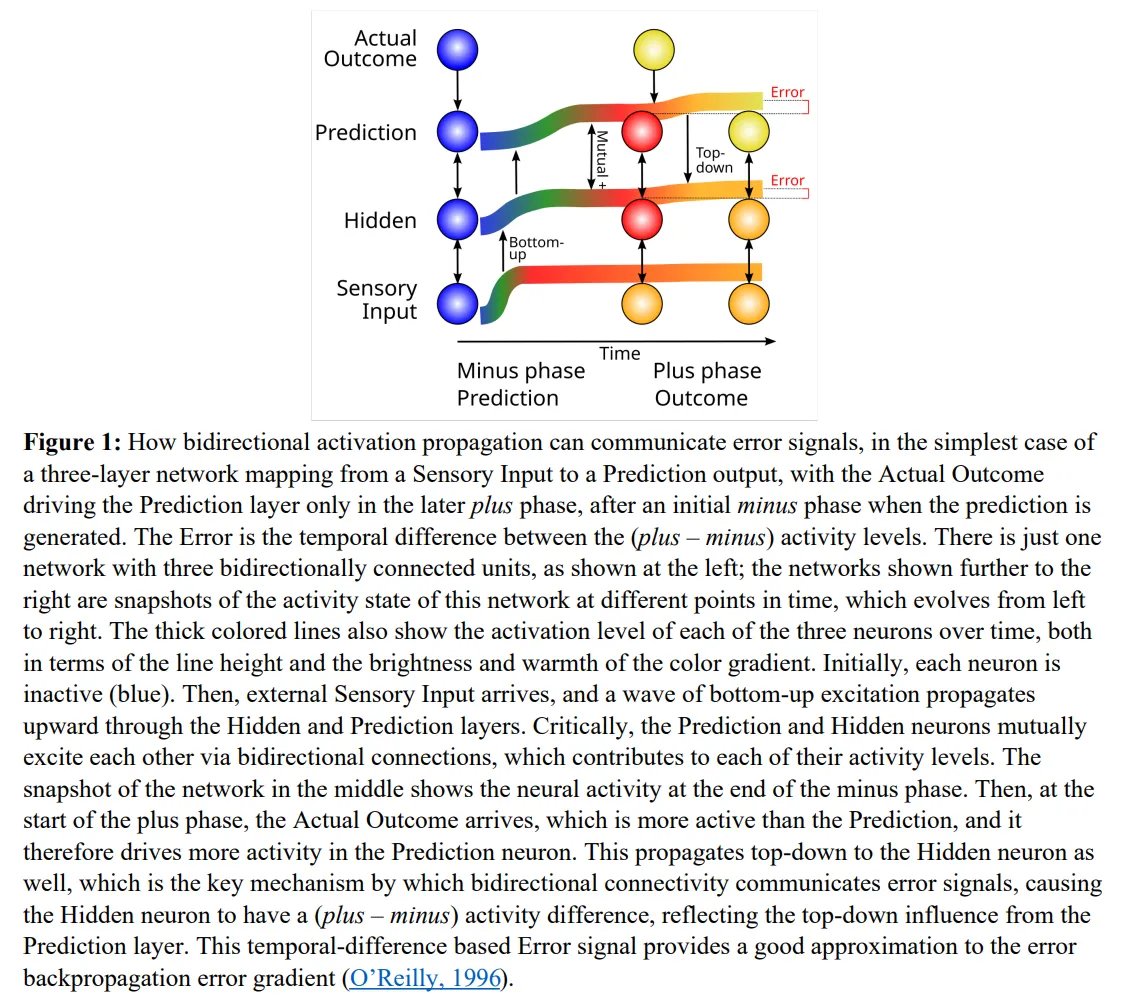
The math relies on an implicit error state:
Error ≈ Activation(plus) - Activation(minus)
Instead of separate error neurons, the same cortical cells represent predictions (minus phase) and outcomes (plus phase) at different moments, driven by bidirectional pathways.
1
2
21
1,497
finite_block_design retweeted
Jun 15
1/
Backprop is the engine of deep learning, but neuroscientists have insisted for decades that the brain can't do it. There are no dedicated "error" neurons or backward wiring.
What if the brain doesn't compute error in space, but in time? 🧵

8
54
385
21,570
finite_block_design retweeted
Jun 15
1/ Standard transformers have a fundamental topological flaw: they cannot track dynamic states over time without running out of layers.
Once a state representation reaches the top layer of the feedforward stack, the model's ability to update its belief collapses. 🧵

11
89
626
113,966
finite_block_design retweeted

人工知能では、ニューロンはしばしば非常に単純な計算単位として扱われる。入力を重み付き和で足し合わせ、非線形関数を通して出力する。
一方、生物のニューロンはそれほど単純ではない。特に大脳皮質の錐体細胞は、複雑に枝分かれした樹状突起を持ち、そこに数千から数万のシナプス入力を受け取る。さらに樹状突起上には、NMDA受容体や電位依存性イオンチャネルが分布している。
では、1個の生物学的ニューロンは、実際にはどれくらい複雑な計算を実装できるのだろうか。この問いを調べるため、研究 “What can a neuron compute” では、詳細なラットL5錐体細胞モデルを対象に、そのDNNデジタルツイン、すなわちサロゲートモデルを作成し、計算能力を検証している。
ここでの単一ニューロンは、人工ニューラルネットワークにおける単純な1ユニットとは大きく異なり、概算では、10万単位のシナプス接点を持つ計算素子、樹状突起上に多数の非線形サブユニットを持つ。
この研究では、まず詳細に分かっているL5錐体細胞モデル、すなわち詳細ニューロンモデルの入出力を近似するDNNを訓練する。デジタルツインを作るのは、元の詳細モデルは計算が重く、シナプスの重みや位置を直接最適化するのが難しいためである。
詳細ニューロンの活動は、NEURONシミュレータを用いて生成された。ここえは約5.7日分に相当する神経活動データを作成し、それを用いてDNN twinを訓練した。このDNN twinは、入力スパイク列やシナプス設定から、詳細モデルの膜電位やスパイク活動を十分に再現できるように学習される。スパイク予測精度を表すAUROCは0.986である。
その後、このDNN twinの内部パラメータは固定する。その上で、各タスクに対して、入力シナプスの重みと樹状突起上の位置だけを最適化する。DNN twinは微分可能であるため、バックプロパゲーションによって効率よくシナプス設定を探索できる。最後に、得られたシナプス設定を元の詳細ニューロンモデルに戻し、本当にそのタスクを解けるかを検証する。
その結果、単一細胞であっても、適切なシナプス重みと樹状突起上の配置を与えられれば、自然画像分類、音声分類、10-bitパリティ問題などの複雑な課題を解けることが示された。
一方で、この結果の解釈には注意が必要である。まず、TwinPropは生物学的な学習則そのものではなく、実際の神経細胞の学習過程とは大きく異なる。あくまで、単一の神経細胞が適切なシナプス配置を与えられたとき、どれほど複雑な関数を実装できるかを示した研究である。
コメント
===
研究として面白い点は、実際の詳細モデルを模倣するサロゲートモデルを作り、その上で最適化を行い、最後に元の詳細モデルへ戻して検証することで、単一ニューロンの計算能力の可能性を示した点にある。実際の生物は、このような最適化と比べて、どのような学習を行っているのだろうか。
また、神経細胞の数と現在のAIモデルのユニット数を比較する議論はよくあるが、単一の神経細胞がこれだけの計算能力を持つ可能性があるなら、単純に「ニューロン数」と「ユニット数」を比較するだけでは不十分である。生物の神経細胞が持つ樹状突起計算、シナプス配置、局所非線形性、エネルギー効率などを含めて、AIとのハードウェア的・計算論的な違いを改めて議論する必要がある。
3
49
235
28,015
finite_block_design retweeted

フィジカルAIについては「米中が先行する中、日本は本当に大丈夫なのか」「現場データが日本の勝ち筋になるはずだ」「人手不足の打開策になる」など日本国内で様々な議論がなされてきましたが、一方で議論が紛糾し混乱しているようにも見受けられます。一部違和感のある言説も出てくるようになりました。そこでフィジカルAIについて俯瞰的な観点でまとめた総力特集「フィジカルAI 日本の処方箋」を日経Robotics 7月号で執筆・掲載しました。なぜフィジカルAIを巡る議論は混乱しやすいのか、日本としての打ち手はどうあるべきか、そもそもフィジカルAIとは何なのか、など多様なステークホルダーに取材し記事としてまとめました。ぜひご高覧いただければ幸いです。日経Roboticsとしては珍しく、なんと期間限定で全文を無償でご覧いただけます!
xtech.nikkei.com/atcl/nxt/ma…
日経Roboticsでは普段はWebでの全文公開は定期購読者様向けなのですが、今回は普段の技術解説記事というよりも、より広い層の方々を想定して執筆したため、フリーで公開しております。前編と後編の2本建て、紙版では40ページの特集となっておりやや長いのですが、期間限定公開ですので皆様、ぜひシェアいただければ幸いです。

9
489
1,736
712,840
finite_block_design retweeted
日経Robotics編集長の進藤さんによる、フィジカルAIに関する渾身の記事が公開されている。日本におけるフィジカルAIの議論にとって非常に重要な内容であり、現状の環境や技術動向がよく整理されているとともに、現状の方針に対する疑問も投げかけられている。記事自体は公開されているので、興味のある方はぜひ読んでいただきたい(スレッドにリンクを貼っておきます)。
私も取材を受けた関係者の一人としては、フィジカルAIの競争力は、現場データを集めるだけでなく、現場に入り、価値検証とデータ収集を繰り返す改善ループを作れるかにあると考えている。日本には、そのループを多様な産業現場で回せる可能性がある。
フィジカルAIにおいては、現場データを集めればそれで終わりというわけではなく、ロボットを直接導入する形でも、人間が操作や作業を行う形、さらには人間の作業ログでもよいので、現場にシステムを実験的に導入し、実際に使えるのか、価値が出るのかを検証する。そのうえで、さらに新しいデータを取り、改善していくサイクルが必要になると考えている。
日本の強みは、多様な産業が比較的密に集積していることにある。量で勝負するのではなく、要求水準の高いニッチな現場が幅広く存在し、多様なドメインで改善ループを回せる可能性がある。ただし、よくあるPoC止まりになる部分や、現場データを活用するための体制づくりといった、組織的な壁を越えられるかが勝負になる。
なお、現場との接点が開発を駆動するという構図は、フィジカルAIに限らない。例えば、材料向けAIであるMatlantisでも、「こうした材料を試したい」「こうした問題を扱いたい」というユーザーからの要望、しかも多分野からの要望をもとに開発を進めてきた結果、純粋な研究開発だけでは到達しなかったモデルやサービスにつながり、この5年間で世界的にみても速いペースでの改善を実現できた。フィジカルAIがまったく同じ構造になるとは限らないが、多様な問題設定・環境からのフィードバックループを作れれば強みが作れると思われる。
開発面で見ると、事前学習においては、ロボットから直接収集したデータだけでなく、動画やシミュレーションなどで作られた多様なデータを用いることで、物理世界をある程度理解できるモデルは、今後かなりの水準まで作られていくだろう。
さらに、物理世界での経験だけからは得にくい知識をLLMから取り込むことも必要になる。例えば、「今扱おうとしている部材は非常に硬いため、この工具を使わなければならない」といった知識である。こうした異なる由来の知識・データの統合が重要になる。
事後学習においては、さまざまなドメイン知識や、企業内に蓄積された知識をモデルに組み込んでいくことが重要になる。こうした知識の一部は、コンテキストへの注入や検索で扱えるだろうが、現場特有のスキルや暗黙的なノウハウは、文脈として与えるだけでは獲得が難しく、また推論時に毎回大量の文脈を与えるのはエッジで動作させることからもコストの面からも厳しい。そのため、現場で知識やスキルを取り込み続けられるモデル、すなわち継続学習しやすいモデル設計と、導入後の追加学習を支える環境整備が求められる。
記事では意識的にマニピュレーションに焦点を当てていると思うが、移動の問題もまだ十分には解けていない。ロコモーション自体はかなり進んでおり、倉庫内搬送や自動運転のように、整備された環境でのナビゲーションは実用段階にある。
一方で、地図やインフラの整備に頼らず、初めての街中や屋内を自在に動き回るには、かなり多くの常識的知識が必要であり、現状では限られた環境下でしか利用できない。例えば、屋内で自己位置を見失った場合にどう振る舞うべきか。
また、ドアを越えて移動するような一見単純な行為にも、実際には多くの課題があり、建築現場のように足元が悪い環境での移動は、ロコモーションとナビゲーションの両方が絡む難しい問題として残っている。
5
52
259
27,823
finite_block_design retweeted

Jun 10
Diffusion (or flow) makes for excellent policies, but training them with RL is notoriously hard: BPTT is unstable, RL over diffusion blows up the horizon. In our new paper, we show how we can optimize flow matching actors by using "one weird trick" -- "approximate" the Jacobian of the flow denoising process with the identity matrix. 👇

8
122
1,061
82,943
finite_block_design retweeted

Jun 11
Claude CodeのFableに、moldリンカにリンカスクリプトのサポートを足してくださいと丸投げで依頼したら、Linuxカーネルをリンクして起動できるようになってしまった。
こういう日が来るだろうなと思ったけどほんとにすごいな。
3
72
594
87,074
finite_block_design retweeted
Jun 10
1/
We’ve been promised that "latent reasoning" models think in parallel using vector superposition, bypassing the limits of written words.
But a new paper reveals this is mostly an illusion. Standard architectures actively suppress parallel thinking.
🧵

5
32
234
13,185
finite_block_design retweeted

Jun 10
As believers of open research, we are disappointed to see Anthropic silently degrading Fable 5 for AI development
"Any topic related to building pretraining pipelines, distributed training infrastructure, or ML accelerator design... may have limited effectiveness through Claude via methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning."
Not only do they get to decide what you use LLMs for in research, but this also enables them to silently intervene in your research without you knowing.
This sets a dangerous precedent. If a model refuses openly, users can understand the boundary. If a model falls back to another model, users can still evaluate the difference. But if a model silently modifies or weakens its own answers while still pretending to help, researchers lose the ability to know whether a failed result came from their own idea, their implementation, or an invisible intervention by the model provider.
That is not safety. Safety policies should be transparent, auditable, and user-visible.
On top of that, the people most harmed by this are not the largest labs with massive teams and proprietary infrastructure. It is the independent researchers, academic groups, startups, and open-source builders who rely on public tools to compete, innovate, and pioneer AI for everyone else.

165
719
3,867
223,997
finite_block_design retweeted
Jun 9
1/
We have spent years optimizing KV cache via head-sharing (GQA/MQA), but we ignored a fundamental assumption: why do Transformers need three separate Q, K, and V projections in the first place?
Turns out, they don't. Merging them unlocks massive memory savings. 🧵

9
45
311
22,880
finite_block_design retweeted
Jun 4
1/
In representation learning, the Gaussian distribution has long been known as the exact place where independent source separation goes to die.
But a new paper completely flips this on its head, proving Gaussianity is the secret to recovering true physical states. 🧵

1
6
46
2,427
finite_block_design retweeted
MAI-Thinking-1のテクニカルレポートには、ベンチマーク上でSonnet級に近いモデルを一から開発するための知見が書かれている。特に、単一モデルの性能だけでなく、継続的にモデルを改善する能力を重視しており、大規模モデル開発の工程・運用・判断基準について興味深い記述が多い。
開発方針として、能力は継承されるべきものではなく、学習によって獲得されるべきものだという考えをとっている。また、複雑な特殊技法ではなく、単純でスケールする学習レシピと信頼できるデータを重視し、すべての技術採用は検証可能でなければならないという立場をとっている。
モデルは1T総パラメータ、35BアクティブパラメータのMoEであり、8K GB200 GPU上で30Tトークンの事前学習と3.55Tトークンの中間学習を行っている。学習には、公開データとライセンス済みデータを使っている。
ベンチマークでは、SWE-Bench Proで52.8%、AIME 2025で97%などの性能を示しており、STEM reasoningとcodingを重視していることが分かる。
アーキテクチャは、現在の強いモデルで使われる標準的な構成に近く、Decoder-only Transformer、local/global attention、RMSNorm、SwiGLU、GQAなどを採用している。MoE層とDense FFN層を交互に挟む構成が実時間効率で有利だったため、この構成を採用している。
MoEにはLatent MoEを使っている。また、学習時にはDropless MoEを採用している。通常のMoEでは、expert capacityを超えたトークンをドロップする場合があるが、これが微妙なcausal leakage問題や実験結果の歪みを生む可能性がある。そのため、可変メッセージサイズのall-to-all通信を使い、トークンをドロップしないDropless MoEを採用している。
この論文では、他であまり詳細が述べられない開発時の方針や評価方法の詳細が書かれている。
たとえば、Scaling Ladderを用いて、小さいモデルでの評価結果をそのまま採用して大規模化するのではなく、複数のモデルサイズを用意し、手法のスケール特性を確認している。モデル系列として、3.9B、13B、30B、58B、100B、159B、615B、1015B総パラメータのモデルを用意し、小〜中規模で検証したうえで、大規模でのスケール特性を見ている。この中で、大規模化するにつれて小規模で得られた結果が逆転する例も見られた。たとえばデータmixでは、小規模ではSTEM-heavy mixが良かった一方で、中〜大規模ではSTEM評価においてもcode-heavy mixの方が良いという結果が得られている。
また、アーキテクチャやデータ改善を単純なloss差ではなく、Efficiency Gain, EGで評価している。EGは、候補手法が達成した損失にベースラインが到達するには、何倍の計算量が必要かを表す指標である。さらに、FLOPs基準のEGだけでなく、実時間基準のEGTimeも参照している。実装上の通信やメモリ効率が悪ければ、FLOPsでは勝っていても実時間では負ける場合がある。たとえば、MoEを全層に入れる構成とinterleaved MoE dense構成を比較すると、後者の方が実時間効率で優れており、採用に至っている(同じFLOPsではMoE onlyがよいが)
pretrainingにおいては、held-out NLL、すなわち負の対数尤度による評価を重視している。精度評価は、プロンプト形式やジャッジモデルなどに影響されやすく、安定しないためである。一方、NLLは安定して高速に評価できる。
pretrain開発時に、合計で約40個のNLL評価用の内部ベンチマークを持ち、単一の目標値にまとめるときは、次の重みを使っている。
コード: 0.5
STEM: 0.175
数学: 0.175
一般知識: 0.1
多言語: 0.05
ここから、MAIは事前学習段階からコードとreasoning、特に数学・STEMをかなり重視しているといえる。
中間学習後、RLでは事前にreasoning traceを与えず、RLによって推論能力を獲得させている。
STEM、agentic coding、安全性・helpfulnessの3つのspecialist modelを訓練し、その後、それらを元のモデルにSFTで蒸留して統合している。長くRLで性能を伸ばし続けられるように、学習方法にも工夫が加えられている。
RLでは、4096 chipsが推論・rollout生成用、768 chipsが学習用に使われており、推論と学習の比はおよそ5:1である。学習ステップ数の詳細はないが、数千ステップと書かれている。
RLではまず、現在のモデルにとって学習に適した難易度の問題を選ぶ。同じ問題に対して、成功するrolloutと失敗するrolloutが混ざるような問題を探す。これを行うために、最初に少数のrolloutを投げ、pass rateが適切な範囲に入るかを調べる。
次に、候補選別を通った問題に対して、追加で128本のrolloutを行う。各rolloutは採点され、全体のpass rateが計算される。pass rateが事前に決めた範囲に入っていれば、正規化advantageを計算し、GRPOで更新する。
長文能力については、直前のmid-trainingと同じデータmixを使い、それを目標長である256Kにre-packして作る。アブレーション結果から、短いコンテキストで効率よく学習し、最後に少量の長文extensionを追加すればよいと見ている。ここも詳細な記述が多く参考になる。
コメント
===
フロンティアモデルに匹敵するモデルの学習詳細が述べられているという点で有用である。特に、具体的な手法そのものよりも、学習方針、例えば、NLLで評価すること、Scaling Ladderを構築して評価すること、技術採用を検証可能にしていくことなどは、他で書かれていることが少なく参考になる部分が多い。
特に、事前学習は作ったモデルがどの程度良いか、採用を評価するには、後続タスクまで作らないと難しい場合があり、単純ではない。今回のテクニカルレポートには、その点で参考になる部分が多いのではと考える。
気になった点として、specialistを蒸留する際、最近はon-policy蒸留も増えているが、このレポートでは通常のSFTを採用している理由は特に書かれていなかった。複数のspecialistの能力を安定に統合するため、単純でスケールしやすい方針を優先したのかもしれない。
3
48
281
40,537
finite_block_design retweeted
継続学習における忘却現象の解明は、重要な未解決問題である。本研究では、生成モデルの中でも重要な拡散モデルの継続学習について、Modern Hopfield Network(MHN)のエネルギー地形との関連から忘却現象を解明しようとしている。
生成モデルにおける忘却を Hopfield energy の上昇として定式化すると、クラスタ内にある典型的なサンプル、すなわち広いエネルギー basin にあるサンプルよりも、孤立した外れ値的なサンプルの方が忘れられやすいことが理論的に示される。
そして、replay buffer において、このような高エネルギーサンプルを優先的にリプレイすることで、忘却を効率的に抑えられることが実験的にも示される。
コメント
===
本研究は、忘却を理論的に扱う枠組みとして興味深い。ここでは、拡散モデルを中心に議論しているが、Transformer なども、対称性を一部意図的に崩した Hopfield エネルギーモデルとしてみなせることが知られている。そのため、本研究の視点は、拡散モデルに限らず、より広いモデルや継続学習の問題にも適用できる可能性がある。
1
16
152
15,216