
Cloud architect 🏆#AWS Certified Solutions Architect,database & security specialist Be more ☁️native than naïve! fail early, fail often, but always fail forward
Joined April 2009
- Tweets 24,575
- Following 1,745
- Followers 618
- Likes 18,491
606 Photos and videos








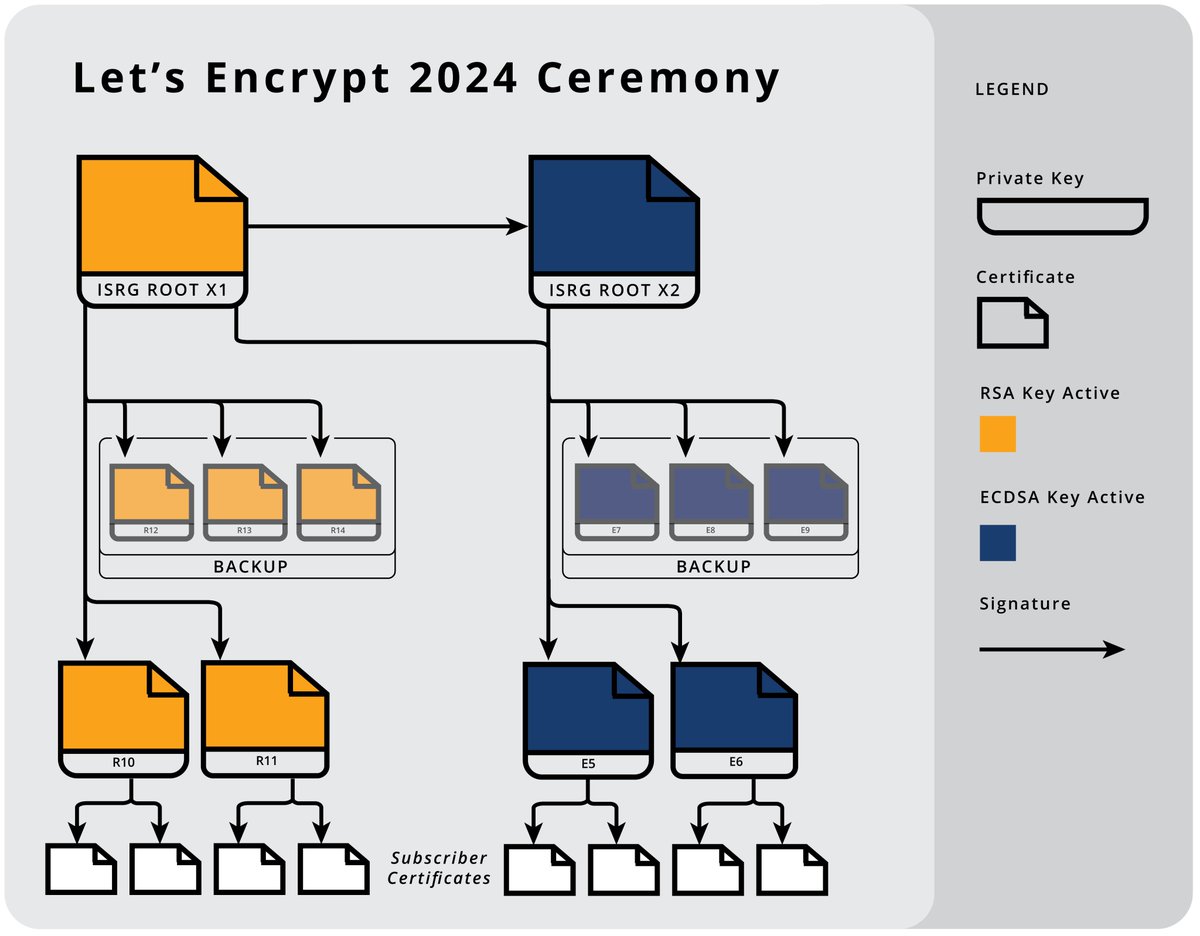

Pinned Tweet

1 Jul 2023
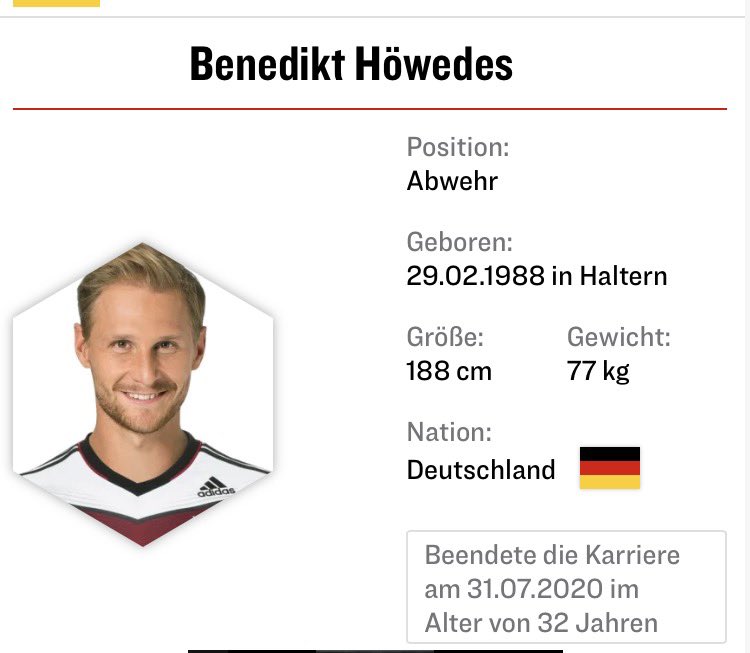
I’m happy to share my new and highest AWS Certified Solutions Architect – Professional from Amazon Web Services (AWS) Web Services! it’s the 1002nd Amazon Web Services (AWS) certificate from T-Systems International international #peoplemakeithappen credly.com/badges/f679dd41-d…

3
1
9
655
Frank Pientka☁️ retweeted

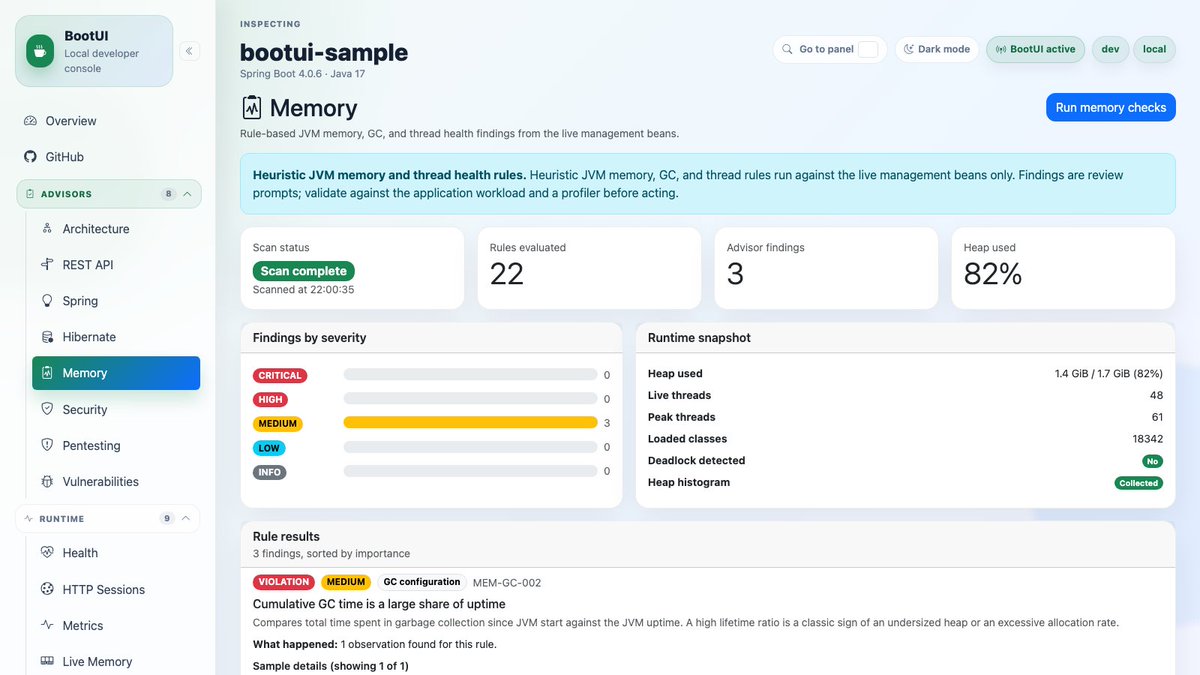
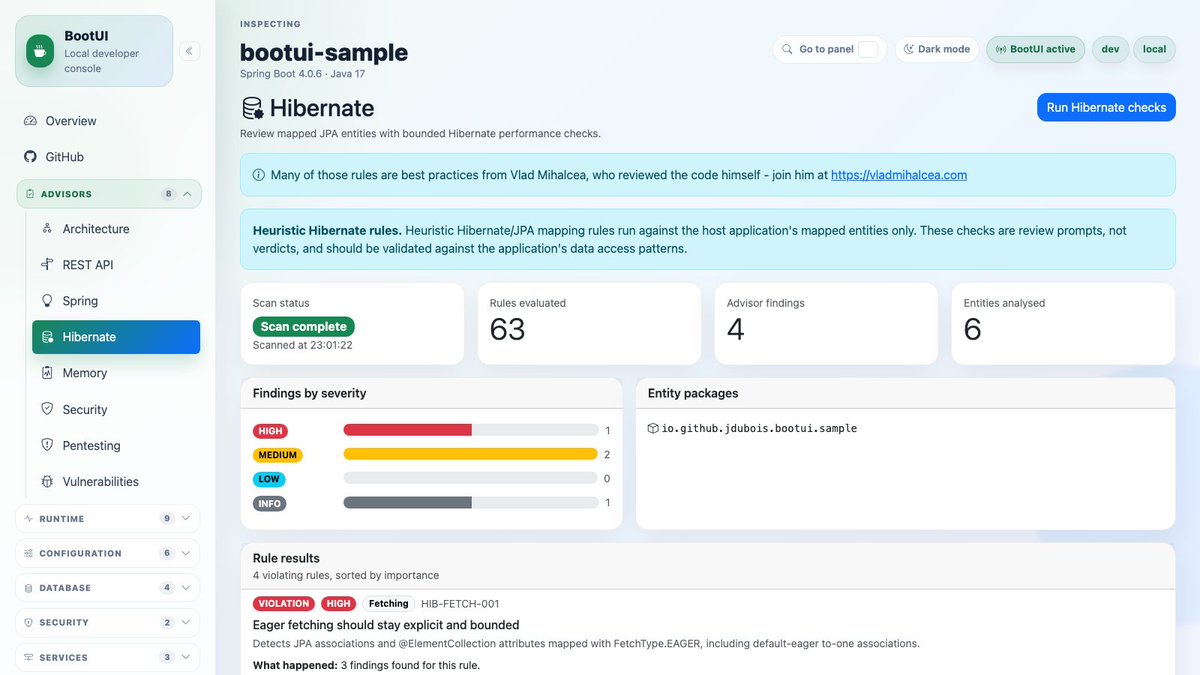
BootUI 1.1.0 is released! My agents have been hard at work during the week-end, and we added nearly 20,000 lines of code 😱
➡️ You'll have an easy to use dashboard telling you what needs to be improved in your project!
➡️ Full changelog: github.com/jdubois/boot-ui/b…
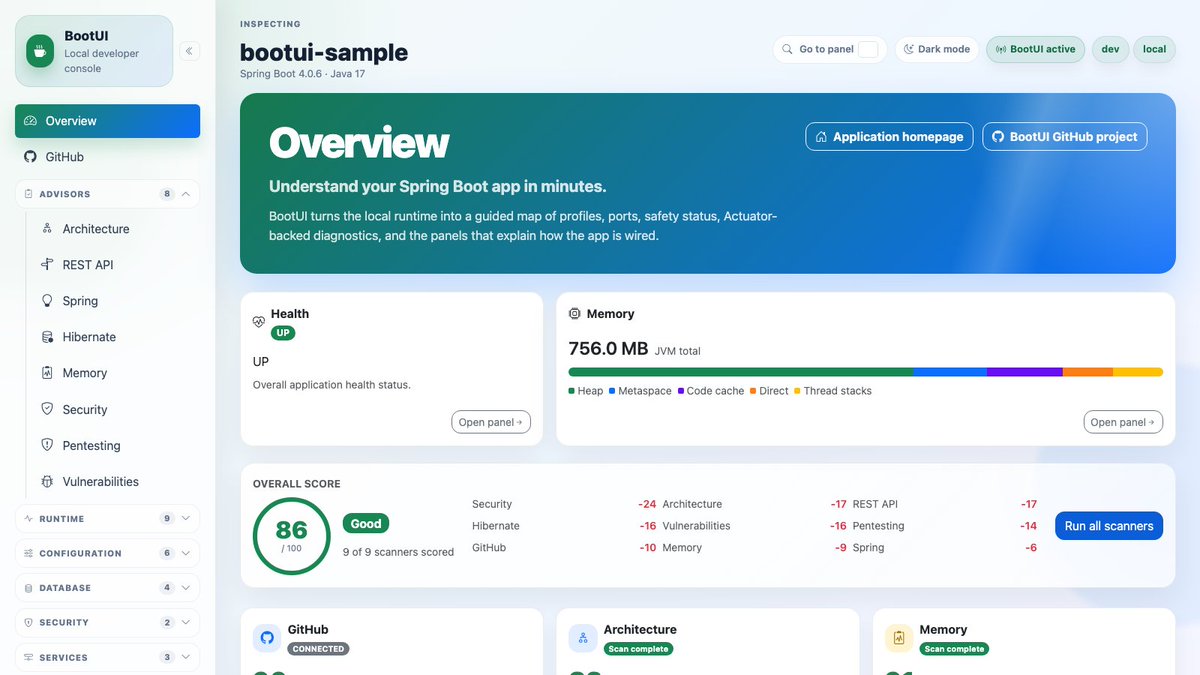
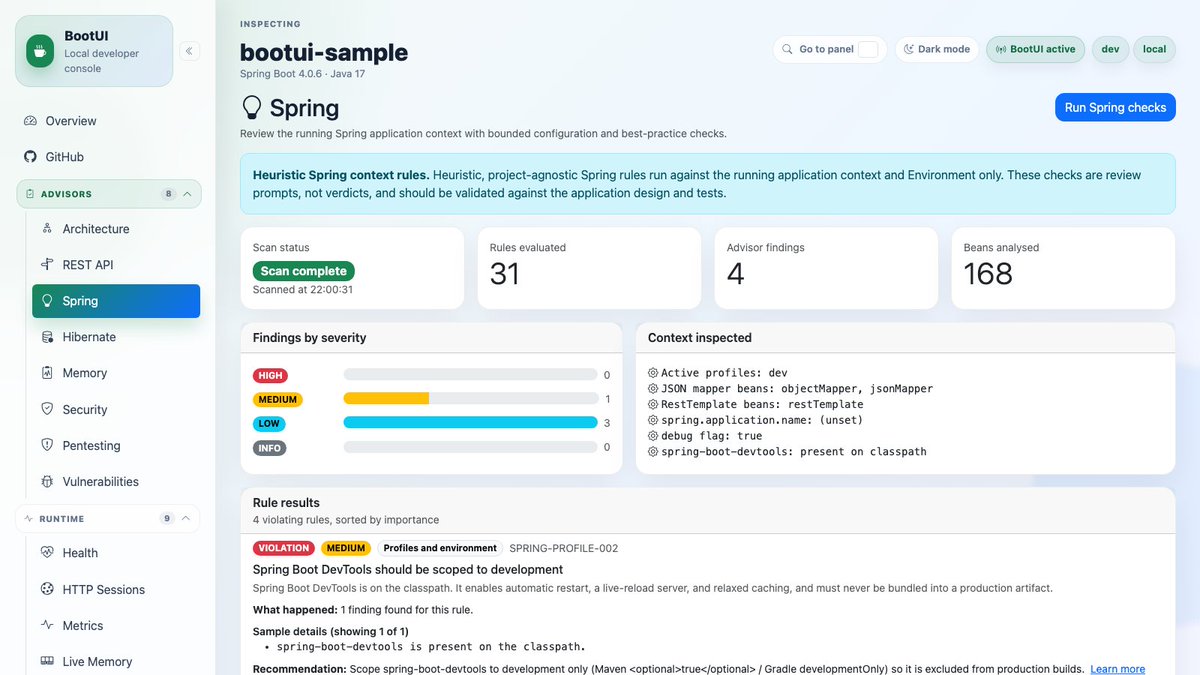
3
5
28
2,206
Jun 13
Jünglinge werden müde und matt, und Männer straucheln und fallen; aber die auf den HERRN harren, kriegen neue Kraft, dass sie auffahren mit Flügeln wie Adler, dass sie laufen und nicht matt werden.
Jesaja 40,30-31/LU17
4
May 21
Mehr Investitionen als bei Northvolt stehen in Aussicht. Das Projekt braucht keine Zuschüsse, aber extrem viel Energie. ndr.de/nachrichten/schleswig…
8
May 10
KI frisst Software: Top-Investor stößt Microsoft-Aktien ab | heise online
heise.de/-11288640
1
17

Ubuntu 26.04 LTS #ResoluteRaccoon has landed.
Discover the biggest updates in our announcement: canonical.com/blog/canonical…

51
199
1,183
58,040
Apr 22
Mein Artikel als Coverstory in der nächsten ix 05.20025 #EUDI -Wallet: Das ist der aktuelle Stand der digitalen europäischen Brieftasche heise.de/-11252204
26
Frank Pientka☁️ retweeted

Apr 19
RAG vs. CAG, clearly explained!
RAG is great, but it has a major problem:
Every query hits the vector DB. Even for static information that hasn't changed in months.
This is expensive, slow, and unnecessary.
Cache-Augmented Generation (CAG) addresses this issue by enabling the model to "remember" static information directly in its key-value (KV) memory.
In fact, you can combine RAG and CAG for the best of both worlds.
Here's how it works:
RAG CAG splits your knowledge into two layers:
↳ Static data (policies, documentation) gets cached once in the model's KV memory
↳ Dynamic data (recent updates, live documents) gets fetched via retrieval
This gives faster inference, lower costs, and less redundancy.
The trick is being selective about what you cache.
Only cache static, high-value knowledge that rarely changes. If you cache everything, you'll hit context limits. Separating "cold" (cacheable) and "hot" (retrievable) data keeps this system reliable.
You can start today. OpenAI and Anthropic already support prompt caching in their APIs.
I have shared my recent article on prompt caching below if you want to dive deeper.
👉 Over to you: Have you tried CAG in production yet?

81
446
2,844
525,738
Frank Pientka☁️ retweeted

Apr 18
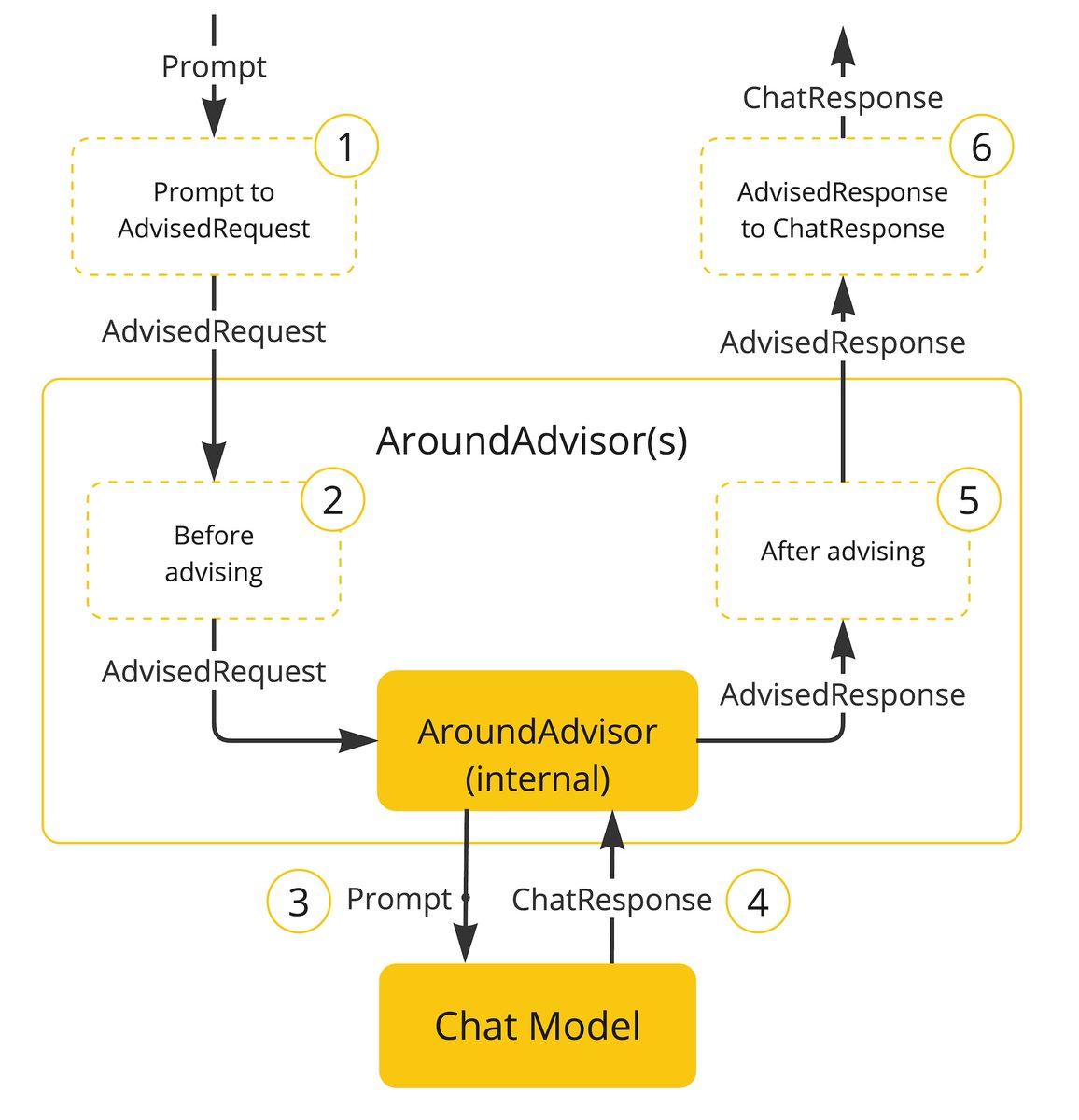
A harnessed LLM agent.
Most people picture this as a model with tools bolted on. The real architecture inverts that relationship.
The model itself is deliberately thin. Intelligence gets pushed outward, and the harness composes it at runtime.
Three dimensions orbit the harness core:
𝗠𝗲𝗺𝗼𝗿𝘆 holds state the model shouldn't carry in weights or context. Working context, semantic knowledge, episodic experience, and personalized memory each have their own lifecycle.
𝗦𝗸𝗶𝗹𝗹𝘀 hold procedural knowledge. Operational procedures, decision heuristics, and normative constraints specialize the general model per task.
𝗣𝗿𝗼𝘁𝗼𝗰𝗼𝗹𝘀 hold the interaction contracts. Agent-to-user, agent-to-agent, and agent-to-tools are three distinct surfaces with their own failure modes.
Between the core and these modules sit the mediators: sandboxing, observability, compression, evaluation, approval loops, and sub-agent orchestration. They govern how the harness reaches out and how state flows back in.
The useful question this framing unlocks: for any new capability, where should it live? Stable knowledge goes to memory, learned playbooks go to skills, communication contracts go to protocols, loop governance goes to the mediators.
Harness design becomes a question of what to externalize, and how to mediate it.
I'm building a minimal agent harness from scratch. Didactic, easy to read, no magic. Open-sourcing it soon. Stay tuned.

83
286
1,562
238,557


Mar 3
Stromausfall in Aachen legt Verwaltungen in NRW lahm | nichts gelernt und keine Redundanz vorhanden heise.de/-11196992
32
Frank Pientka☁️ retweeted

Feb 26
28
187
918
116,944

Jan 22
„AI eats Software“Warum SaaS-Aktien an der Wall Street crashen | Der Software-Sektor steht am Beginn seiner vielleicht größten Umbruchphase seit der Cloud-Revolution. KI wird Software dabei nicht sofort einfach ersetzen, sie dürfte sie aber neu definieren heise.de/-11150650
8
Frank Pientka☁️ retweeted

31 Dec 2025
That’s how you can represent 2026 with five 2’s. Happy New Year 🎉
Please share your own fun facts about the number 2026 🥳

14
105
472
22,996
27 Dec 2025
PostgreSQL RPM repository now supports multiple RHEL minor versions YUM Repository Red Hat’s decision to ship a major OpenSSL update (3.2 → 3.5) together with the RHEL 10.1 and 9.7 releases caused unexpected breakage for users of Rocky Linux, AlmaLinux yum.postgresql.org/news/post…
39
27 Dec 2025
Indian IT Was Supposed To Die From AI. Instead It's Billing for the Cleanup it.slashdot.org/story/25/12/…
10
25 Dec 2025
18
24 Dec 2025
Check out my 2025 LinkedIn Rewind! 🎬
Made with @coauthorstudio rewind.coauthor.studio/r/F5h…
1
11
12 Dec 2025
RSL 1.0 statt robots.txt: Neuer Standard für Internet-Inhalte | heise online heise.de/news/RSL-1-0-Standa…
47