
Machine Learning Software Engineer. Working on NLP problems and excited about all things AI and its applications.
Joined January 2008
- Tweets 1,899
- Following 1,251
- Followers 381
- Likes 1,141
127 Photos and videos
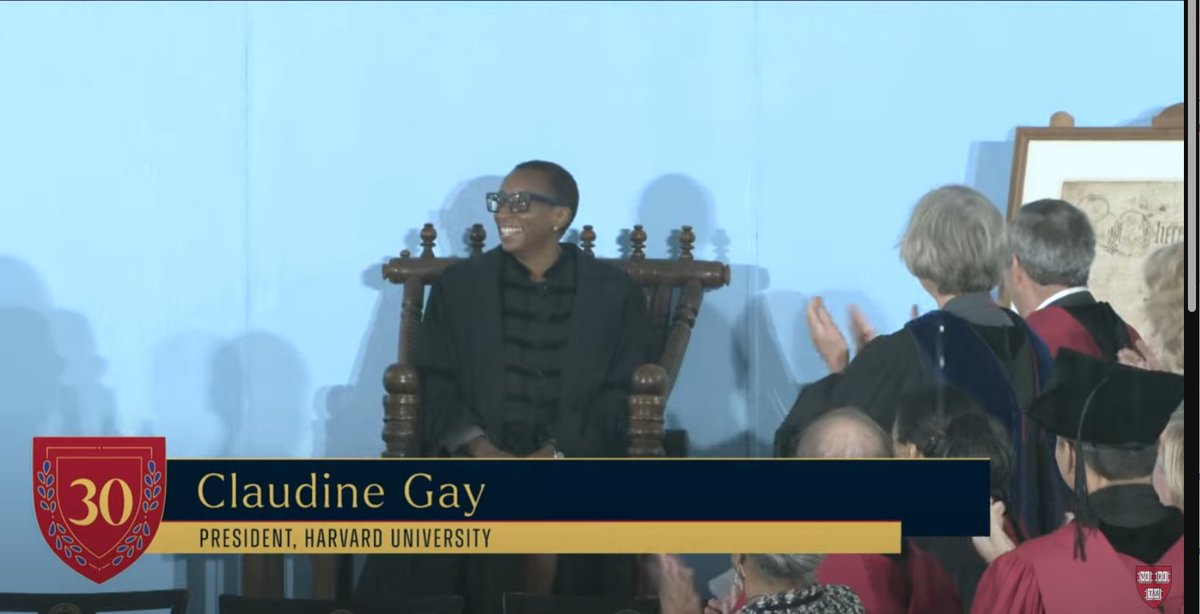










31 Oct 2024
¡Un honor y un orgullo ver nuestra cultura representada en Harvard Square! Gracias @AriadnaAyala por la invitación.
28 Oct 2024

agradecemos la presencia de Santiago Crehueras académico de Harvard University,
Conie Adkin miembro del consejo de ex-alumnos de Harvard University, Ariel Gamiño, presidente del consejo de ex- alumnos de extensión universitaria de Harvard. De Atlixco, Puebla, para el mundo.



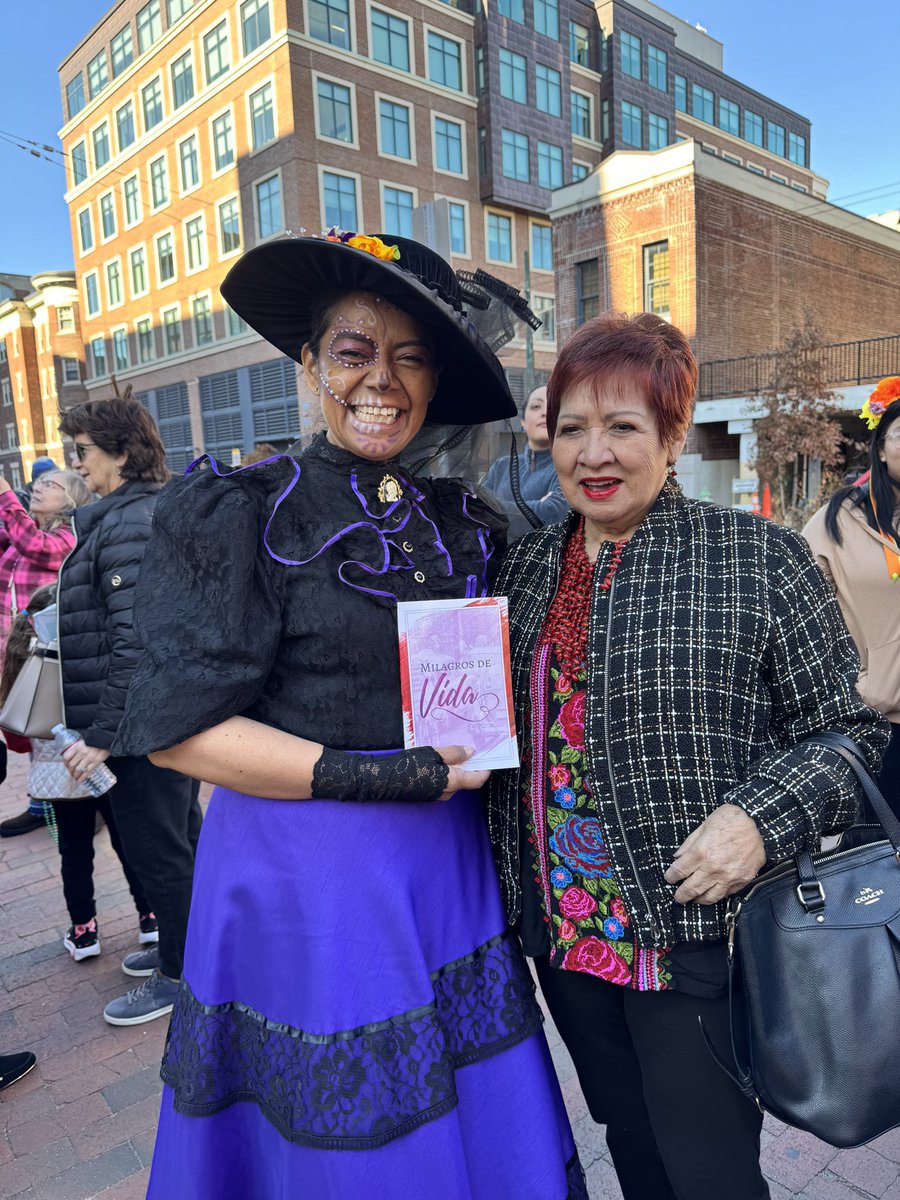
1
81
Ariel Gamiño retweeted

31 Jul 2024
My team is actively hiring software engineers:
Pay: 190,000 - 310,000 USD
Level: New grad/Mid-level
Location: Seattle/Bay Area
Tech stack: Go, Python, Typescript
-Direct referrals offered
-AI/ML roles open
-Free breakfast/lunch/dinner
-Summer 2025 internships
-RTs appreciated
427
1,013
7,790
6,194,036
Ariel Gamiño retweeted
25 Jun 2024
My team is actively hiring software engineers:
Pay: 190,000 - 280,000 USD
Level: New grad/Mid-level
Location: Seattle/Bay Area
Tech stack: Go, Python, TypeScript
-Direct referrals offered
-AI/ML roles available
-Free breakfast/lunch/dinner
-On-site gym
-RTs appreciated
351
963
6,704
1,829,232
Ariel Gamiño retweeted

25 Mar 2024
We're hiring! We're looking for people who're interested in (language/multimodal/action/foundation) model training , (learning) agents, and evaluation. Please let me know if you're interested.

Join us in shaping the future of AI!
AI Frontiers is a lab inside Microsoft Research with a mission to unlock new AI capabilities and solve real-world problems. We are hiring researchers and engineers in our teams based in Redmond and NYC.
Apply here: microsoft.com/en-us/research…
28
30
234
63,165
Ariel Gamiño retweeted

9 Mar 2024
* Language is low bandwidth: less than 12 bytes/second. A person can read 270 words/minutes, or 4.5 words/second, which is 12 bytes/s (assuming 2 bytes per token and 0.75 words per token). A modern LLM is typically trained with 1x10^13 two-byte tokens, which is 2x10^13 bytes. This would take about 100,000 years for a person to read (at 12 hours a day).
* Vision is much higher bandwidth: about 20MB/s. Each of the two optical nerves has 1 million nerve fibers, each carrying about 10 bytes per second. A 4 year-old child has been awake a total 16,000 hours, which translates into 1x10^15 bytes.
In other words:
- The data bandwidth of visual perception is roughly 16 million times higher than the data bandwidth of written (or spoken) language.
- In a mere 4 years, a child has seen 50 times more data than the biggest LLMs trained on all the text publicly available on the internet.
This tells us three things:
1. Yes, text is redundant, and visual signals in the optical nerves are even more redundant (despite being 100x compressed versions of the photoreceptor outputs in the retina). But redundancy in data is *precisely* what we need for Self-Supervised Learning to capture the structure of the data. The more redundancy, the better for SSL.
2. Most of human knowledge (and almost all of animal knowledge) comes from our sensory experience of the physical world. Language is the icing on the cake. We need the cake to support the icing.
3. There is *absolutely no way in hell* we will ever reach human-level AI without getting machines to learn from high-bandwidth sensory inputs, such as vision.
Yes, humans can get smart without vision, even pretty smart without vision and audition. But not without touch. Touch is pretty high bandwidth, too.

550
1,654
8,526
1,852,904
Ariel Gamiño retweeted

8 Mar 2024
AI will create 3.7 million jobs by 2025
Companies are paying $200k-$900k for AI roles.
Here are top 10 online courses with to master AI in next 28 days:👇
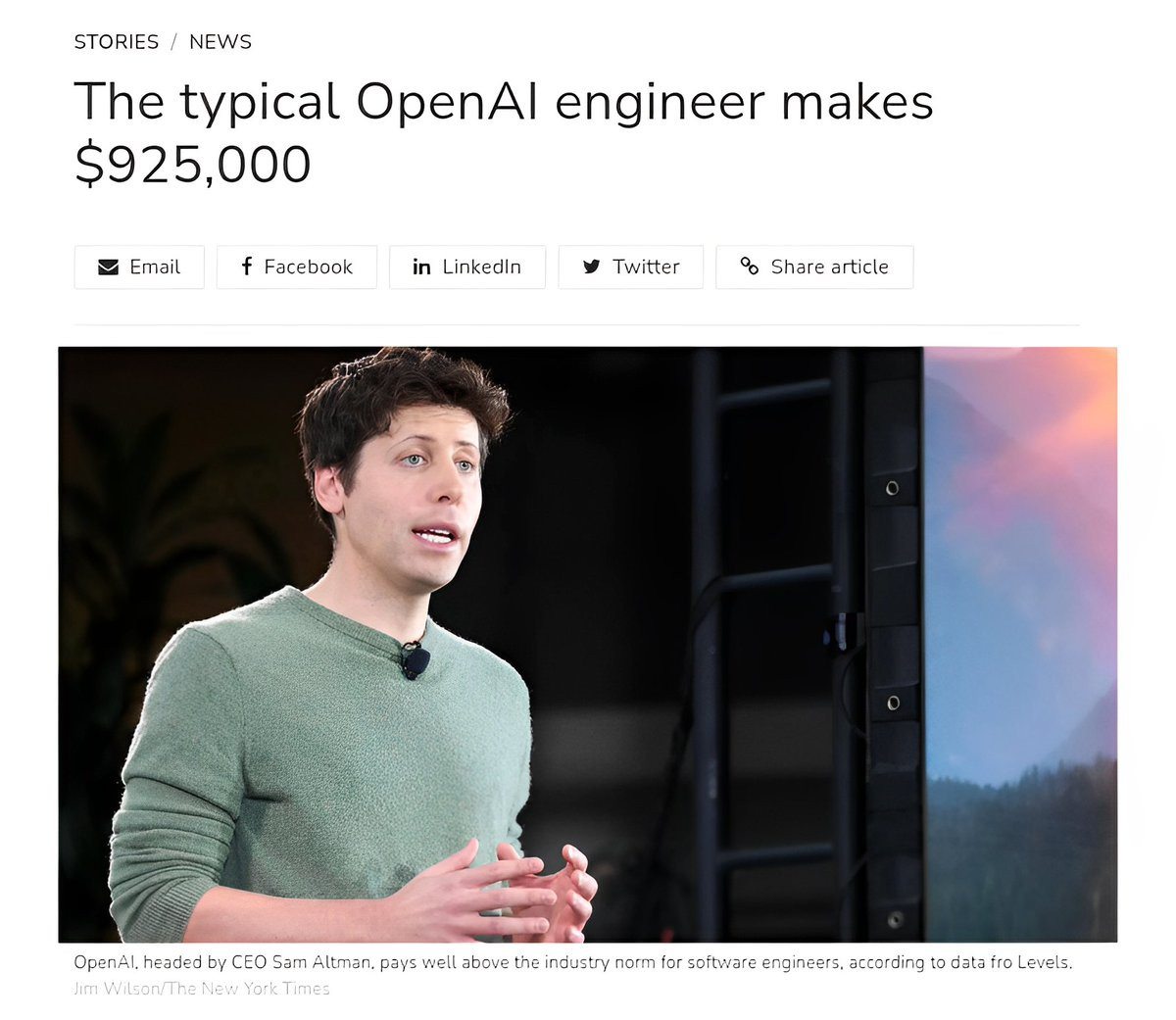
89
482
2,263
707,690
Ariel Gamiño retweeted

14 Feb 2024
Build Agentic Workflows from Scratch 🤖🔁
It’s tempting for an AI engineer to use an off-the-shelf agent, but building your own agents shouldn’t be scary (and limited to AI research papers)!
In our brand-new video tutorial we show you how to build an agent in two intuitive steps:
1️⃣ Define a single step of an agent execution: This is just a DAG that modifies state along the way. Chain together a prompt, LLM, tool calling, output parsing/processing. Conditionally decide whether to call a tool or return.
2️⃣ Plug this DAG into an agent worker: An agent worker will repeatedly call this DAG until completion!
All agentic flows can be decomposed this way, making it simple to reason about. In our tutorial we show you how to build a ReAct agent from scratch.
Check it out: youtube.com/watch?v=T0bgevj0…
Colab: colab.research.google.com/dr…
1
58
327
60,996
Ariel Gamiño retweeted

8 Dec 2023
I'm looking for:
- PhD students
- postdocs
- and potentially interns and research assistants (like a post-doc for those who haven't got a PhD)
Potential post-docs should reach out ASAP and strongly consider applying for funding from FLI; this would need to happen quite soon (probably within 1-2 weeks) for admin reasons.
grantinterface.com/Process/A…
38
222
865
284,696
Ariel Gamiño retweeted

1 Dec 2023
Microsoft launched a free course for beginners to learn AI.
The 12-week, 24 lesson curriculum is all publicly available on GitHub!
Here's what you'll learn & links to the lessons:
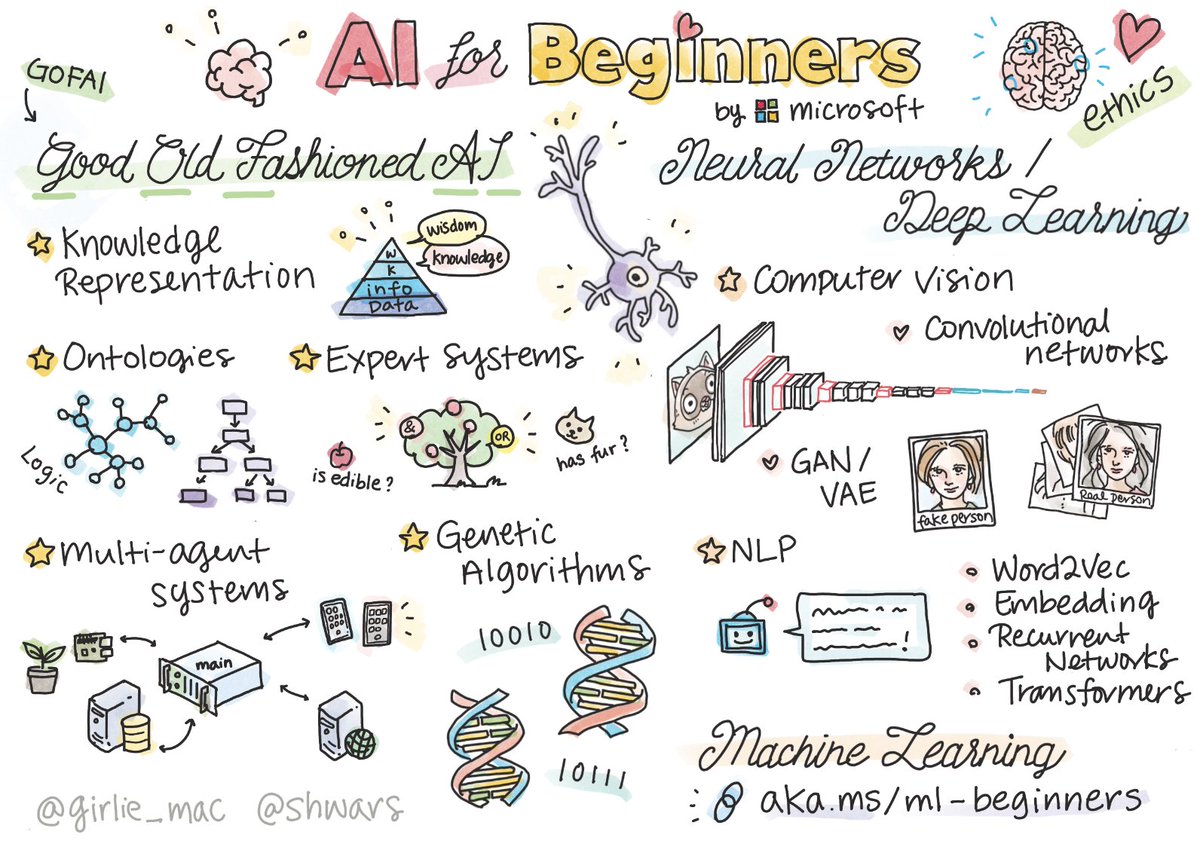
52
953
4,905
1,012,123
Ariel Gamiño retweeted
29 Nov 2023
The UAE Minister of AI @OmarSAlolama points to a historical precedent of premature technology regulation motivated by fear: the ban of the printing press in 1515 by Sultan Selim I led to the decline of the Ottoman Empire.
“We overregulated a technology, which was the printing press. It was adopted everywhere on Earth. The Middle East banned it for 200 years. The calligraphers came to the sultan and said: ‘We’re going to lose our jobs, do something to protect us’—so, job loss protection, very similar to AI. The religious scholars said people are going to print fake versions of the Quran and corrupt society—misinformation, second reason. It was fear of the unknown that led to this fateful decision."
google.com/amp/s/fortune.com…
196
845
3,906
754,629

My team at NVIDIA is hiring. We 🩷 you all from OpenAI. Engineers, researchers, product team, alike. Email me at linxif@nvidia.com. DM is open too. NVIDIA has warm GPUs for you on a cold winter night like this, fresh out of the oven.🩷
I do research on AI agents. Gaming AI, robotics, multimodal LLMs, open-ended simulations, etc. If you want an excuse to play games like Minecraft at work - I'm your guy.
I'm shocked by the ongoing development. I can only begin to grasp the depth of what you must be going through. Please, don't hesitate to ping me if there's anything I can do to help, or just say hi and share anything you'd like to talk about. I'm a good listener.

180
810
8,434
2,414,031
Ariel Gamiño retweeted

8 Nov 2023
Passionate about creating global impact? Seize the chance with DRCLAS Brazil Office Fellowship!
🌍 Immerse yourself in an enriching exchange experience!
⏳ Fellowship duration: 6 months to 1 year
📆 Application deadline: November 15th
Apply now loom.ly/2tx4ogE

3
9
1,039
Ariel Gamiño retweeted
21 Oct 2023
A reminder that people can disagree about important things but still be good friends.

171
553
8,439
911,122
29 Sep 2023
What and inspiring historical event to witness. Dr. Gay embodies the promise of America - that someone from a modest background can rise to lead one of the world's premier universities. She inspires hope for an even brighter future at Harvard and the world. @Harvard @HarvardExt
2
60
29 Sep 2023
Yeah that sounds great and all, but do you offer free coffee?
29 Sep 2023

paying $400k salary to the next person who joins us.
sr. software engineer.
just be good at coding.
1
1
260
29 Sep 2023
Fue un placer el compartir mi conocimiento con tan gran comunidad!
27 Sep 2023

Llega nuestra Keynote Speaker del día en voz de @gamino , Lead AI and Machine Learning Engineer quien nos llevará a aprender como la inteligencia artificial es una de las tecnologías que más rápidamente está transformando al mundo.

30
27 Sep 2023
Picking jaw from floor...
27 Sep 2023

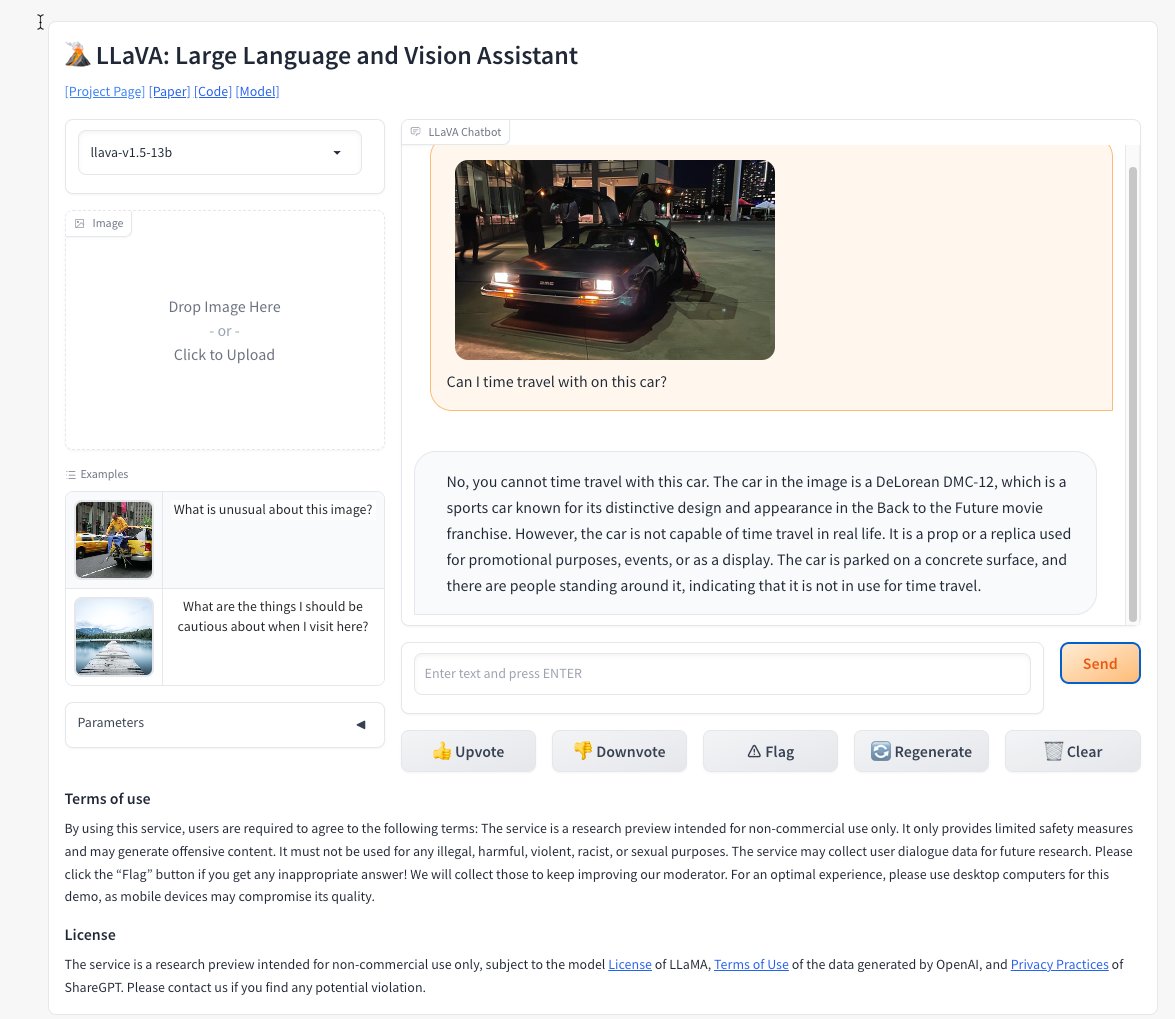
Multimodal ChatGPT just launched 24 hrs ago
It has already taken the internet by storm and blowing everyone's mind!
Here are 5 amazing things that it can do:

60
Ariel Gamiño retweeted

26 Sep 2023
My team is hiring!
jobs.netflix.com/jobs/296046…
62
465
1,728
399,181