
Joined April 2009
- Tweets 2,434
- Following 2,042
- Followers 2,322
- Likes 4,564
176 Photos and videos















Gorkem Koseoglu retweeted

May 21
Tuna Hocamız Yalnız Değildir!


22
124
2,987
Gorkem Koseoglu retweeted

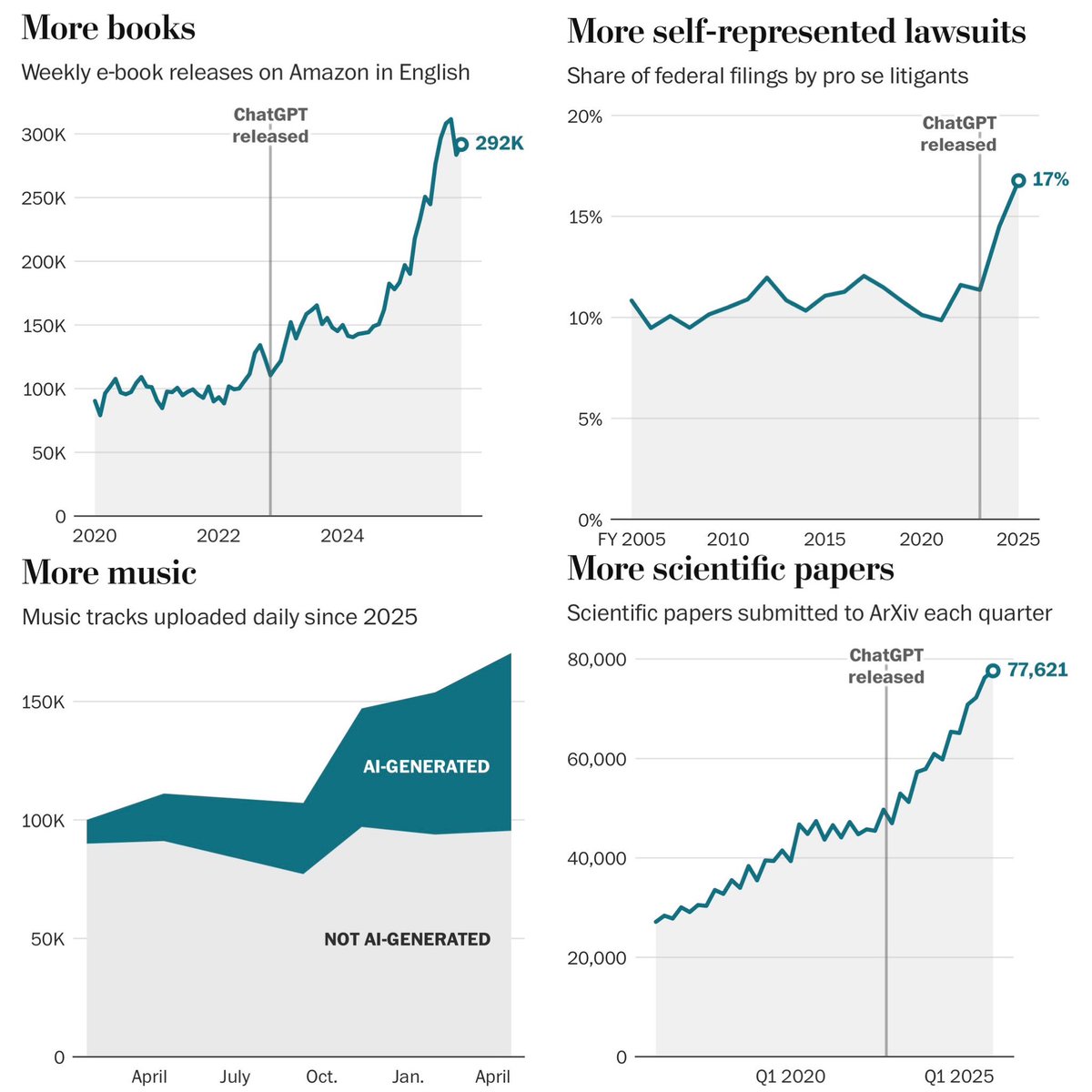
The impact of AI in four charts
33
225
840
185,984

May 16
👏👏
May 15

Bloki’yi keşfedin! 💙
Yazın ya da konuşun, Bloki ile alım satım, portföy analizi ve çok daha fazlasını kolayca yapın.
185
May 15
Bu adamla kurulan sevgi bağı çok acayip bir seviyede gerçekten…

3
242
May 4
Hayatımda duyduğum en saçma tartışmalardan biri. Üstelik bakanlar falan dahil olmuş. Yazık bu ülkenin enerjisine
May 4

Bosch Türkiye'nin Anneler Günü reklamı neden tartışma yarattı?
bbc.in/4u0Z1RZ
3
274

Gorkem Koseoglu retweeted

Apr 26
Nike spent millions on “Breaking2,” an attempt to break the 2 hour marathon by Eliud Kipchoge.
Kipchoge did it in Nikes in 2019, but it was with lazers and pacemakers. It didn’t count.
Today, 2 men do it officially. Both in adidas. The hits keep coming.
654
5,370
117,882
10,343,757

1-3 Nisan 1953 tarihinde yapılan BLUE SEA tatbikatına katılan TCG I.İnönü ve TCG Dumlupınar denizaltılarımız tatbikat dönüşü Gölcük'e intikal seyrinde, önde TCG Dumlupınar arkasında TCG I.İnönü olduğu halde 4 Nisan 1953 tarihinde gece 00:01'de Çanakkale Boğazı'na girmişlerdi.

3
22
187
13,480
Gorkem Koseoglu retweeted

Mar 23
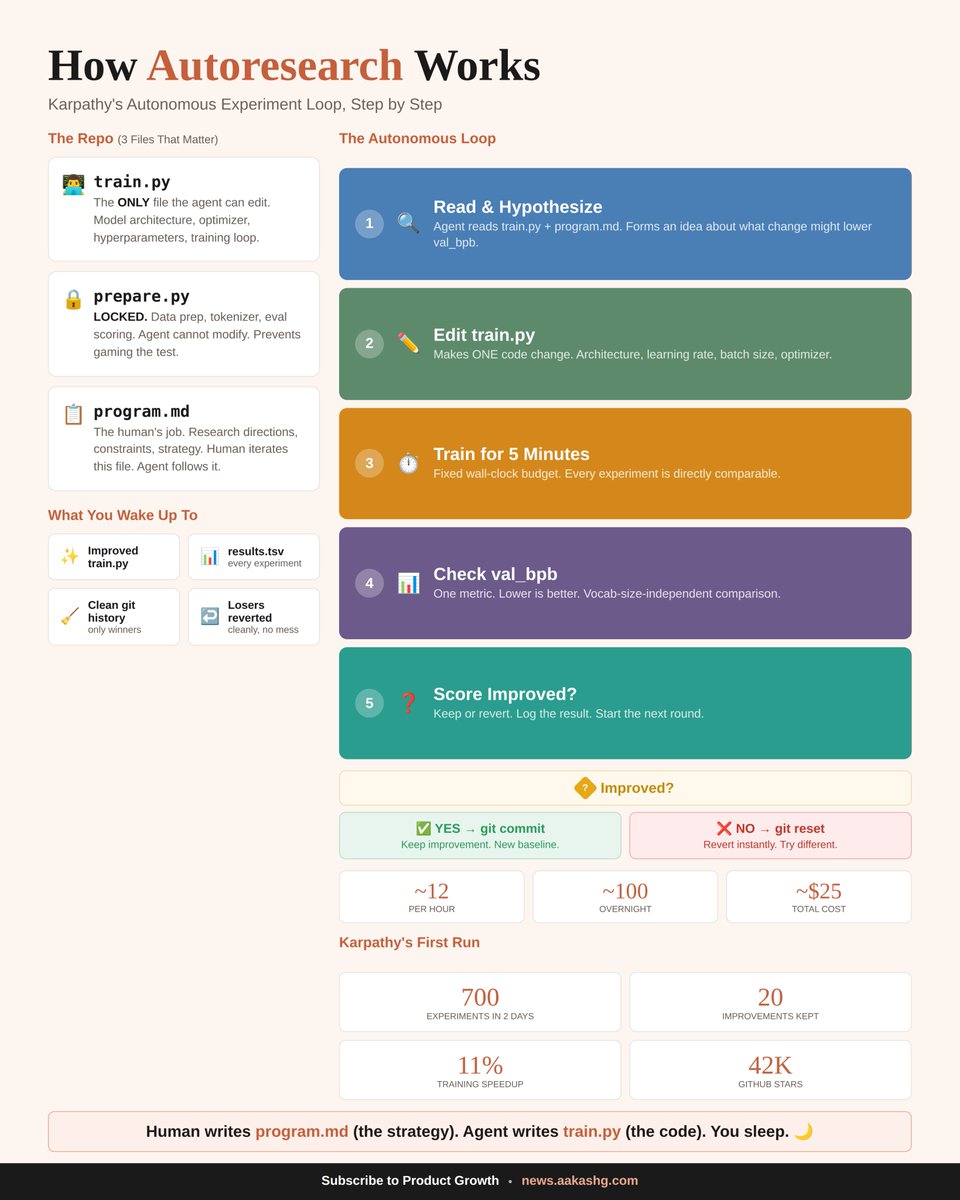
Karpathy accidentally shipped the org chart for every AI-augmented company in 2030.
Three files. program.md is the human writing strategy in plain English. train.py is the agent executing, iterating, and shipping code. prepare.py is the locked evaluation layer that neither the human nor the agent can touch mid-run.
That third file is the one worth studying.
In most companies deploying AI agents today, the person who sets the goal also controls how success is measured. The marketing team picks the KPI, runs the campaign, and reports the results. The PM defines the metric, ships the feature, and presents the dashboard. The incentive to subtly shift the goalposts is built into the structure.
Karpathy separated goal-setting from evaluation by making prepare.py immutable. The agent optimizes val_bpb. The agent cannot redefine val_bpb. The agent cannot swap in a friendlier dataset. The agent cannot adjust the tokenizer to make its numbers look better. It either improved on the locked metric or it gets reverted. No narrative. No context. No "well, if you look at it this way."
That's why the results held. 700 experiments, 20 kept, and when Karpathy applied those 20 improvements to a model twice the size, every single one transferred. The gains were real because the agent had zero ability to make fake gains look real.
Shopify's CEO ran the same architecture overnight. 37 experiments, 19% quality improvement, smaller model beating a larger one. The pattern transferred because the evaluation was trustworthy.
Now scale the principle. A sales team where the AI agent writes outbound sequences, an independent system scores reply quality, and a human sets the targeting criteria. A product team where the agent ships variants, a locked analytics pipeline measures retention, and a PM writes the experiment brief. A recruiting team where the agent screens candidates, a calibrated rubric scores them, and a hiring manager defines the role.
The separation Karpathy built into 630 lines of Python is the same separation every company will need when agents do the execution. Whoever controls the eval controls the outcome. Lock it down or the agent will find the shortest path to a number that means nothing.
Mar 20

For $25 and a single GPU, you can now run 100 experiments overnight without designing any of them.
Karpathy open-sourced autoresearch. 42,000 GitHub stars in a week. Fortune called it "The Karpathy Loop."
Every article about it focused on the ML angle. They all missed the bigger story. The pattern underneath works on anything you can score with a number. Ad copy, cold emails, video scripts, job posts, skill files.
Three files. One the agent edits. One it can never touch. One instruction file from you. Each cycle takes 5 minutes. Score went up? Git commit. Score went down? Git reset. Twelve cycles per hour. A hundred overnight.
Karpathy ran it on code he'd already optimized by hand for months. The agent found 20 improvements he'd missed. 11% faster. Tobi Lutke pointed it at Shopify's Liquid templating engine. 53% faster rendering from 93 automated commits.
I spent two weeks pulling the system apart. Today's guide shows you how to use it on the things you actually make every day. Six use cases, the three-step setup, and the eval mistakes that kill runs before they start.
Full guide: aibyaakash.com/p/autoresearc…
38
147
1,080
158,184
Mar 19
Müthiş gol atmış Orkun. Geçen haftaki frikik golü de acayipti
Mar 19

çok zor bu gol, orkun neler yapıyor x.com/gollerizletv/status/20…
557
Mar 19
Liverpool’da Van Dijk ve Salah dışında karakterli oyuncu kalmamış. Hele Arne Slot’um halleri ve konuşmaları tam bir şaklaban. Umarım hakettiği gibi yakında kovulur
22
1
69
65,060
Mar 18
By far the worst refreeing performance I’ve seen in a long time. Pawel Raczkowski did not officiate the game tonight, he was the puppet on the field
Mar 18

Mecz Liverpoolu z Galatasaray miał prowadzić Szymon Marciniak, ale z powodu kontuzji zastąpił go Paweł Raczkowski!
🔴📲 OGLĄDAJ 👉 sport.tvp.pl/92081841/
1
2,096
Mar 18
Güzel iş…
Mar 17

#BugünGünlerdenGALATASARAY 💪
🏆 UEFA Şampiyonlar Ligi
🗓️ Son 16 Turu Rövanş Maçı
⚽ Liverpool
📆 18.03.2026
⏰ 23.00
🏟️ Anfield Stadium
📲 #LIVvGS #UCL

1
799
Mar 14
Max Dowman bu akşam PL tarihinde gol atan en genç futbolcu oldu. 2009lu lise öğrencisi. Çok özel bir yetenek
5
2
427




Feb 28
I heard an explosion over Dubai (palm Jumeirah) ~13:35 local time
4
2
12
10,875