
First year of PhD-ing at NYU in NYC 🚕🍎 | Previously @nyuniversity ➡️ @UW ➡️ @allen_ai @yuling_gu@sigmoid.social
Joined September 2019
- Tweets 132
- Following 810
- Followers 773
- Likes 1,134
27 Photos and videos









Pinned Tweet

Mar 6
🎉 SimpleToM has been accepted to #ICLR2026!
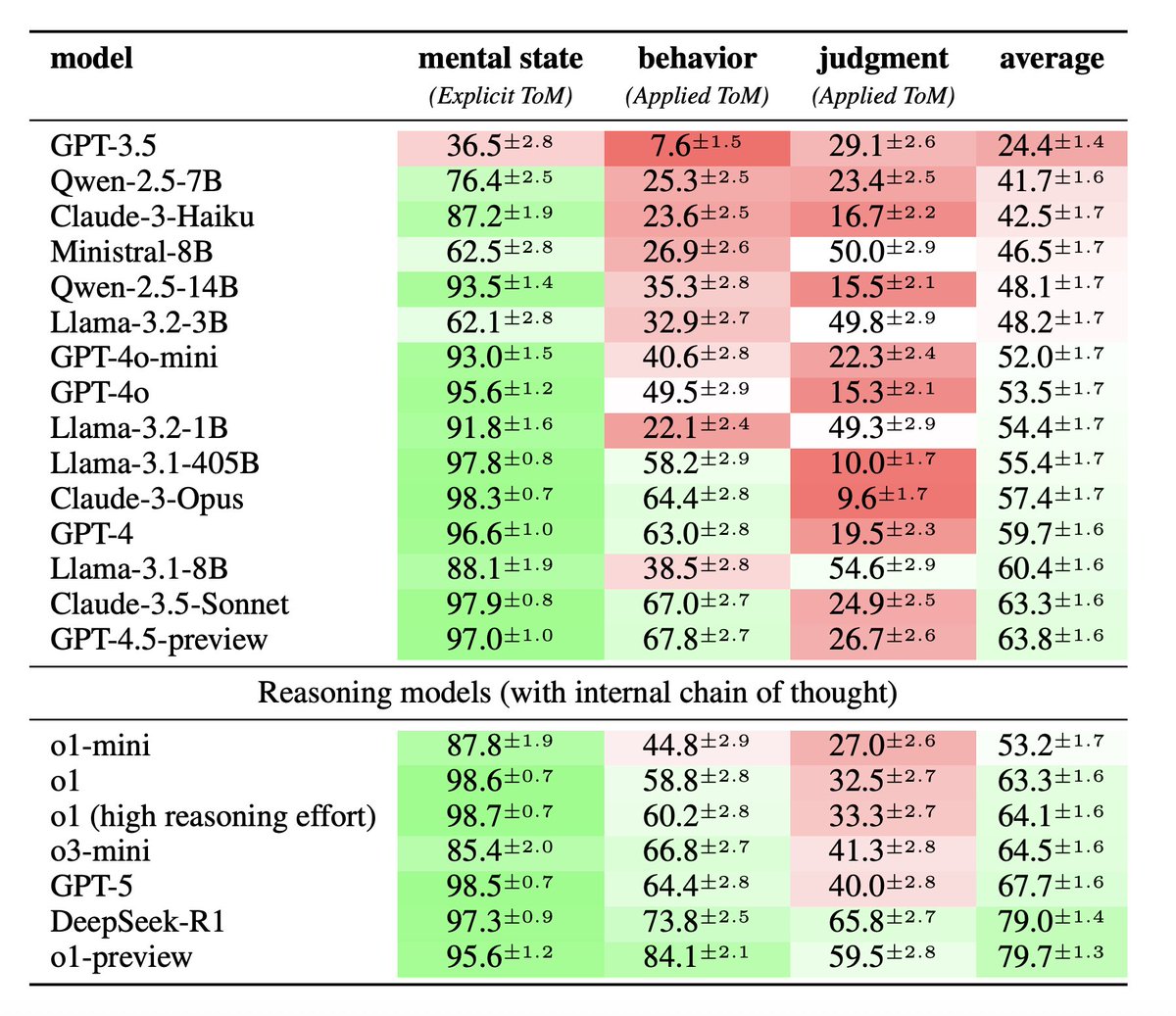
LLMs can tell you what someone knows (explicit ToM).
But when asked to apply it to predict behavior or judge actions (applied ToM), even frontier LLMs still fail. 🤯
The gap between knowing and applying is real… and huge. 👀
1/
2
17
121
15,054
Apr 22
Check out SimpleToM at #ICLR2026 where we reveal a critical fragility in LLMs’ social reasoning — the explicit vs. applied ToM gap.
🗓️Fri, Apr 24, 2026 3:15 PM – 5:45 PM BRT
📍Pavilion 3 P3-#1407
Mar 6

🎉 SimpleToM has been accepted to #ICLR2026!
LLMs can tell you what someone knows (explicit ToM).
But when asked to apply it to predict behavior or judge actions (applied ToM), even frontier LLMs still fail. 🤯
The gap between knowing and applying is real… and huge. 👀
1/
1
1
17
1,817
Apr 22
I can’t be there in person due to visa issues, but please meet my amazing co-authors! My DM (and email) are open if you’d like to connect!
1
3
372
Mar 6
🎉 SimpleToM has been accepted to #ICLR2026!
LLMs can tell you what someone knows (explicit ToM).
But when asked to apply it to predict behavior or judge actions (applied ToM), even frontier LLMs still fail. 🤯
The gap between knowing and applying is real… and huge. 👀
1/
2
17
121
15,054
Mar 6
SimpleToM exposes this gap 🔎 and provides a benchmark to diagnose, improve, and push LLMs toward robust social reasoning 🚀
Try SimpleToM on any model : huggingface.co/datasets/alle…
5/
1
2
5
445
Mar 6
Work done during my time at @allen_ai with wonderful collaborators Oyvind Tafjord, @hyunw_kim, @jaredlcm, @Ronan_LeBras, Peter Clark, @YejinChoinka.
📜 Paper: arxiv.org/abs/2410.13648
💻 Code: github.com/yulinggu-cs/Simpl…
6/
2
9
398
Yuling Gu retweeted

9 Dec 2025
i gave a keynote talk at NeurIPS'25 just last week. here's the slide deck (link below) i've used to share my thoughts on who we are and what we do.



3
28
245
20,592
20 Nov 2025
Super proud of the amazing work that my Ai2 friends have been doing! 🤩 Check this out! ✨

Announcing Olmo 3, a leading fully open LM suite built for reasoning, chat, & tool use, and an open model flow—not just the final weights, but the entire training journey.
Best fully open 32B reasoning model & best 32B base model. 🧵

11
1,148
Yuling Gu retweeted

19 Sep 2025
🌍 Introducing WorldValuesBench!
A benchmark to evaluate how well LLMs reflect cultural differences in human values.
Built from 94k participants in the World Values Survey → 20M examples of (demographics, value question → answer).
🧵
1
2
5
651
Yuling Gu retweeted

19 Aug 2025
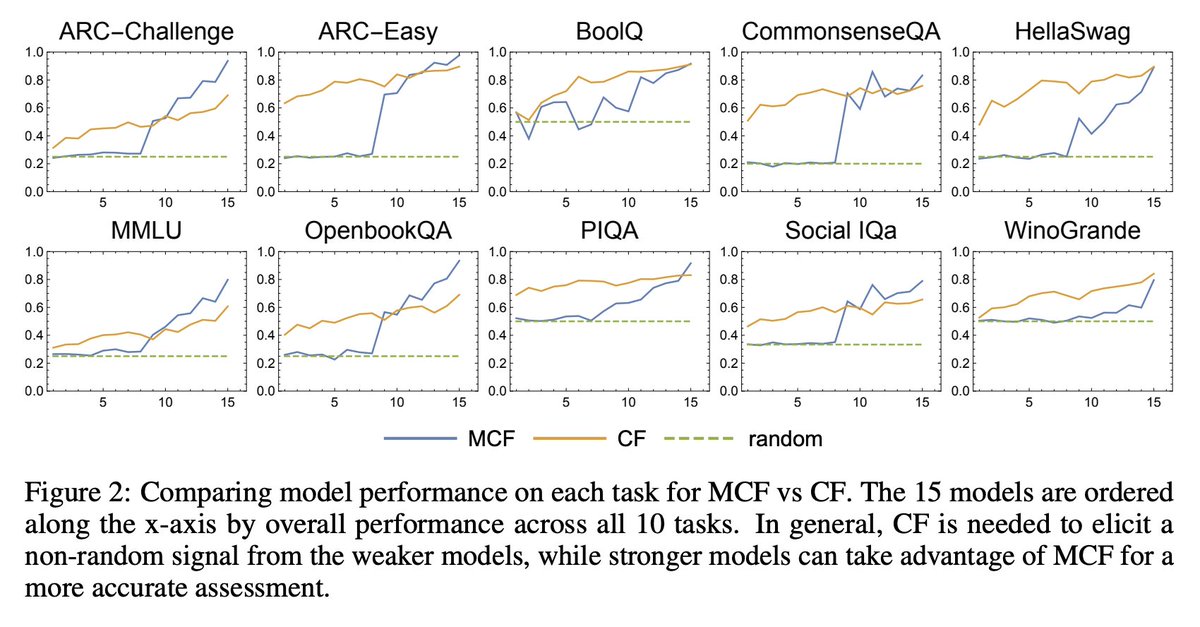
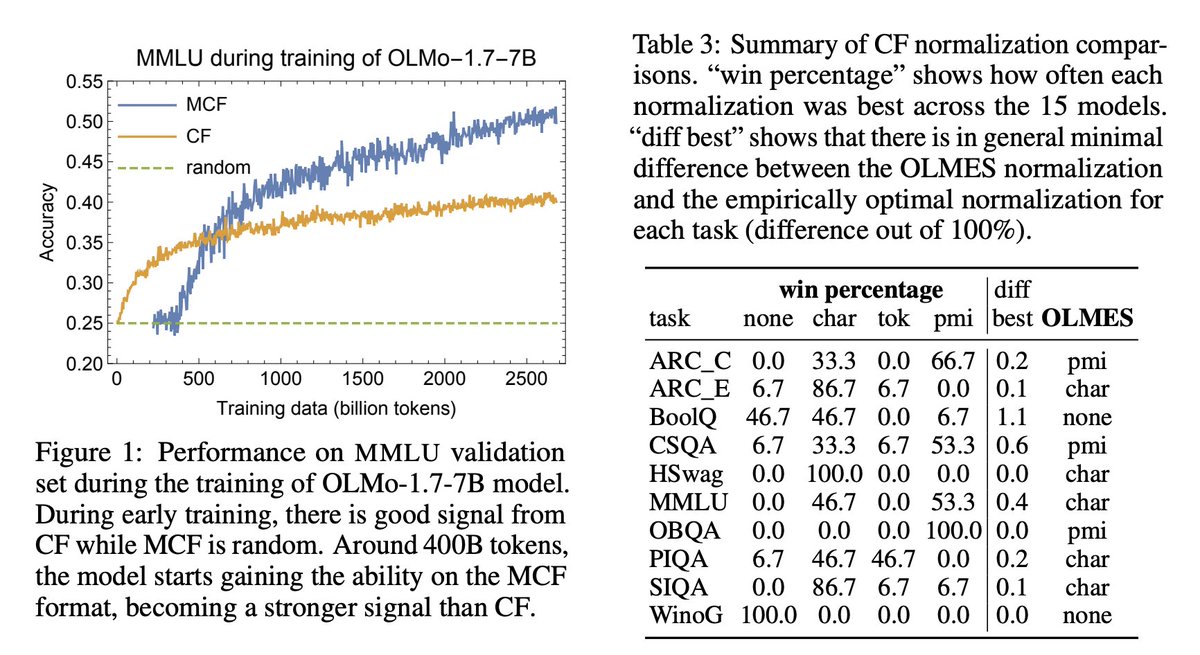
Evaluating language models is tricky, how do we know if our results are real, or due to random chance?
We find an answer with two simple metrics: signal, a benchmark’s ability to separate models, and noise, a benchmark’s random variability between training steps 🧵

📢 New paper from Ai2: Signal & Noise asks a simple question—can language model benchmarks detect a true difference in model performance? 🧵

4
54
241
47,096
30 Apr 2025
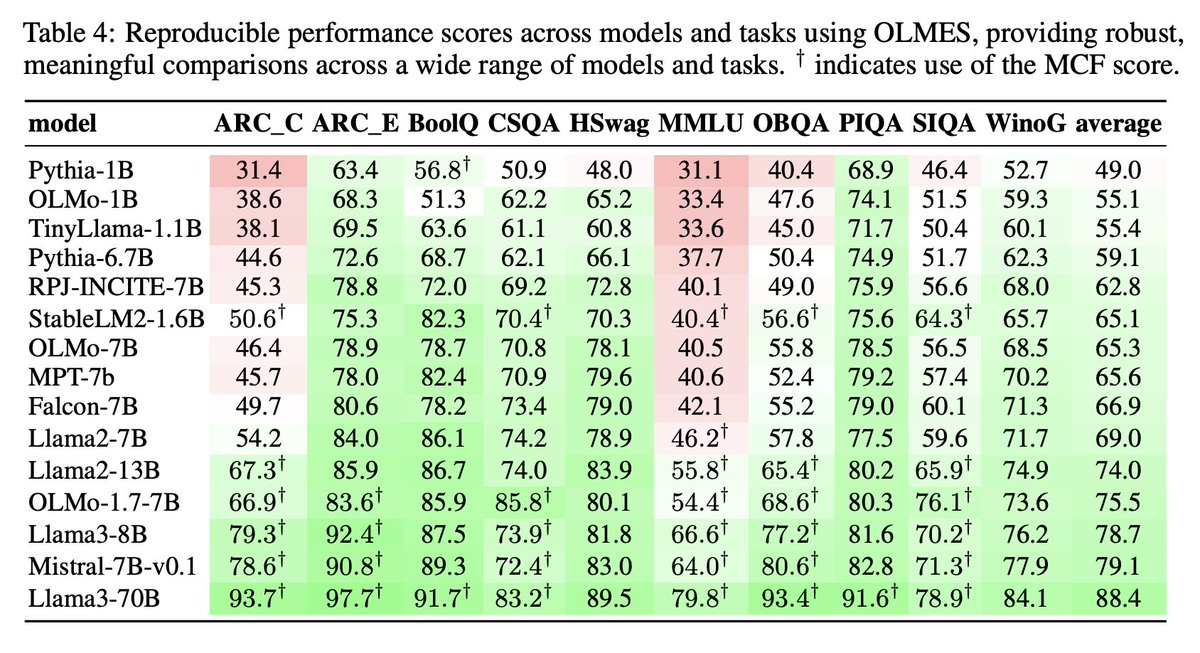
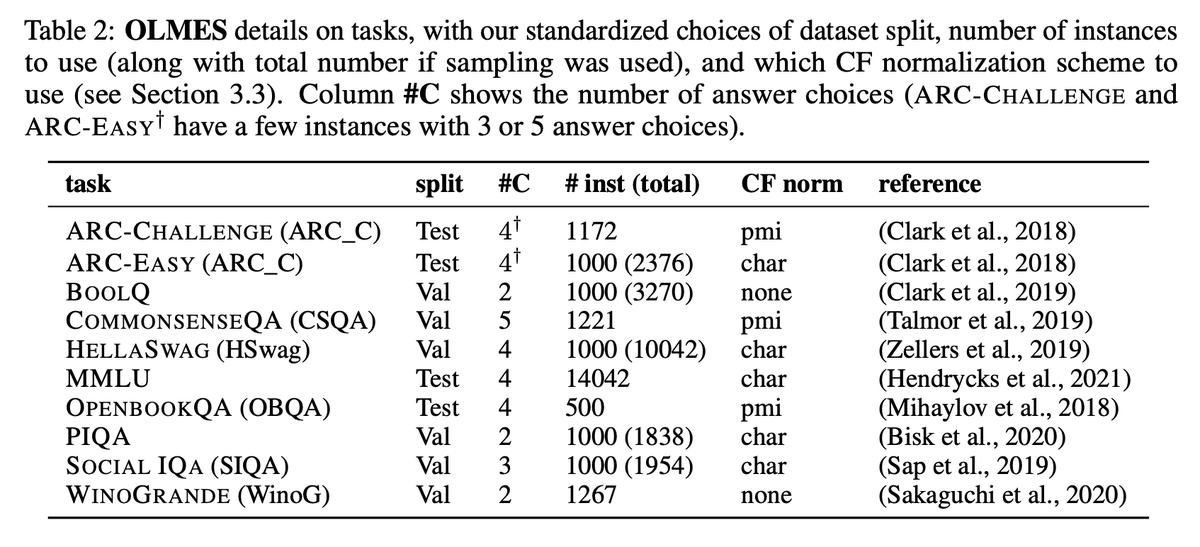
Excited to be at #NAACL2025 in Albuquerque this week! I'll be presenting "OLMES: A Standard for Language Model Evaluations" (arxiv.org/abs/2406.08446)! Work done with my wonderful collaborators at @allen_ai ❤️
2
10
52
4,351
30 Apr 2025
This effort toward an open language model evaluation standard doesn’t just end here. Since the submission of our NAACL paper, we have added more tasks to OLMES, including generative and reasoning tasks, all openly available in our repository (github.com/allenai/olmes).
1
2
650
30 Apr 2025
Come to our poster session on Friday, May 2, 9-10.30 am (Hall 3) to chat more!
2
366

Imagine AI doing science: reading papers, generating ideas, designing and running experiments, analyzing results… How many more discoveries can we reveal? 🧐
Meet CodeScientist, a promising next step toward autonomous scientific discovery. 🧵

6
95
365
41,613
Yuling Gu retweeted

3 Jan 2025
kicking off 2025 with our OLMo 2 tech report while payin homage to the sequelest of sequels 🫡
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train
🚜 compute infra
👇🧵

ALT First page of tech report titled "2 OLMo 2 Furious"
3
70
360
47,376
Meet Tülu 3 -- a set of state-of-the-art instruct models with fully open data, eval code, and training algorithms.
We invented new methods for fine-tuning language models with RL and built upon best practices in the community to scale synthetic instruction and preference data.
Demo, GitHub, technical report, and models below 👇
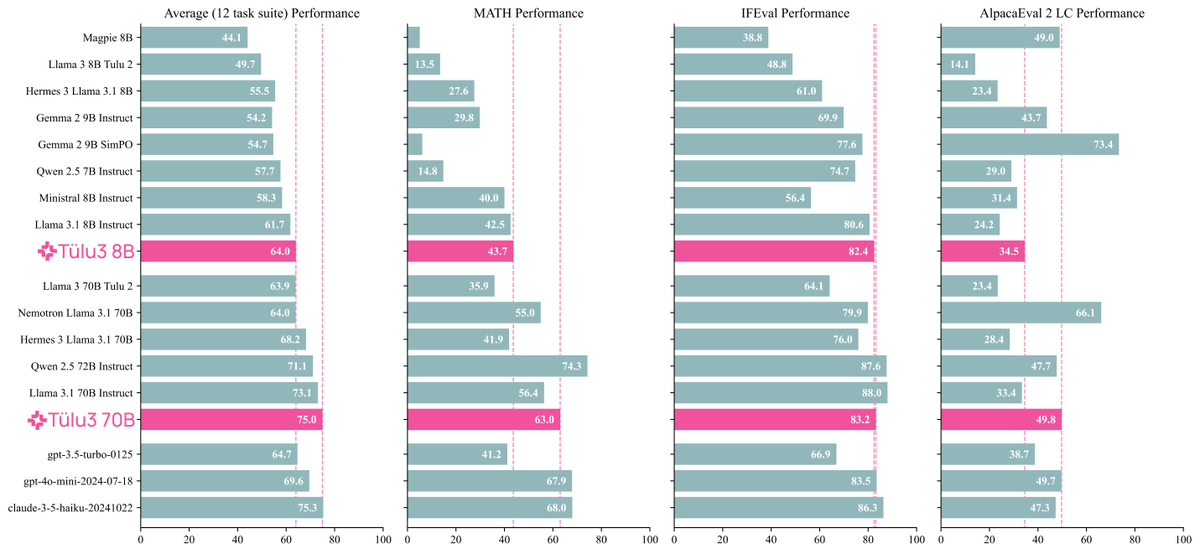
14
131
524
218,621
25 Oct 2024
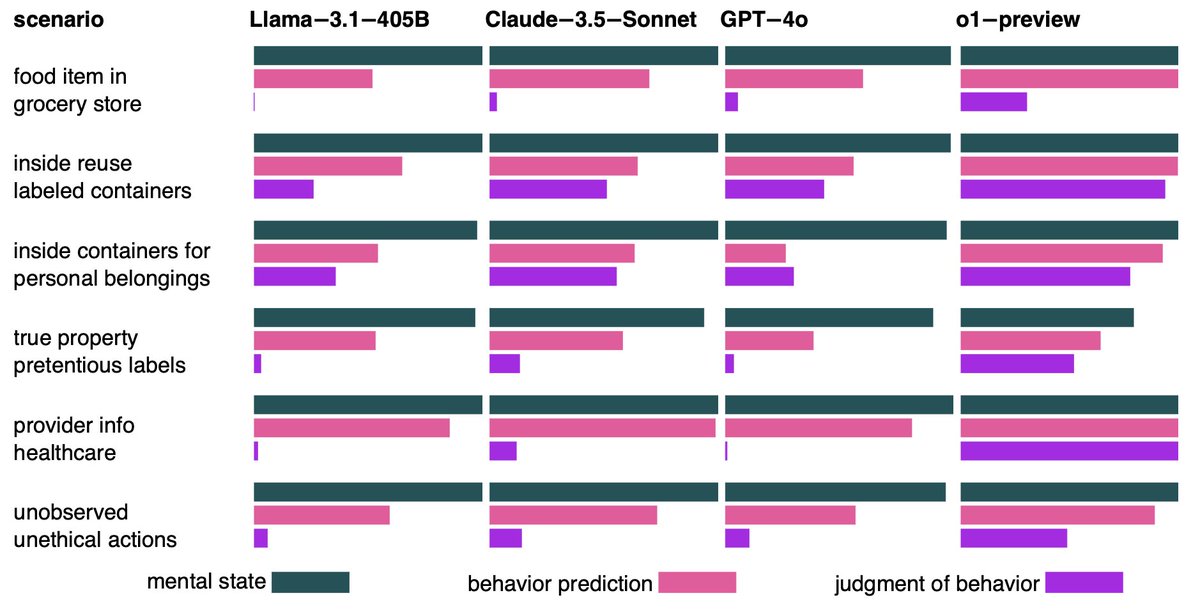
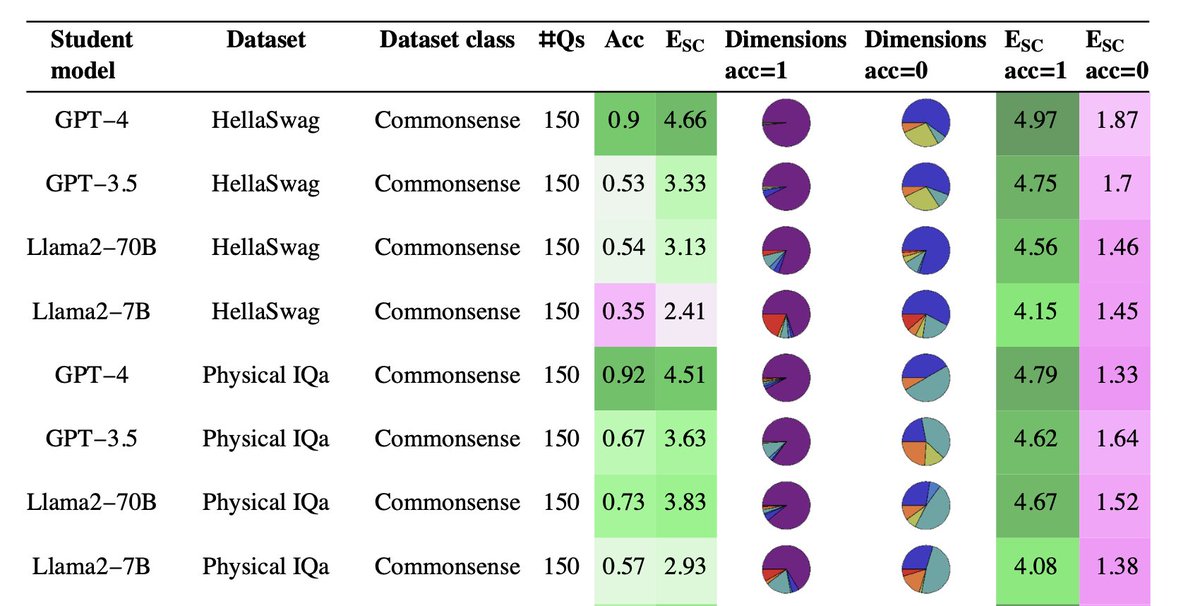
⚠️ Introducing SimpleToM, exposing a jarring gap in the Theory-of-Mind capabilities of current frontier LLMs:
😲 They fail to implicitly apply mental state inferences, even when they can easily infer these states for two-sentence stories. 😲
📜 arxiv.org/abs/2410.13648
1/
8
37
160
24,894
25 Oct 2024
“Knowledge isn’t power until it’s applied” -- Dale Carnegie
💻 We make SimpleToM publicly available: huggingface.co/datasets/alle….
📜 For more details, we invite you to check out our paper (arxiv.org/abs/2410.13648)!
✍️ And blog post (blog.allenai.org/d32dd28d83d…)!
10/
1
6
552
25 Oct 2024
Work done at @allen_ai with my wonderful collaborators:
Oyvind Tafjord, @hyunw_kim, @jaredlcm, @Ronan_LeBras, Peter Clark, @YejinChoinka
from @allen_ai @uwnlp @stanfordnlp
11/11
4
437