00KA retweeted

Jun 12
Not a general chatbot repurposed for science.
A research co-pilot built from the ground up for it.
#ASCI #AI4Science #OPENSCI
Jun 12


3
7
3,607
Anindyadeep retweeted

It was super fun talking to @akshay_krips today! We talked about what LiteFold does, current state of AI4Science, Autonomous discoveries and also the future of work. Glad to be in such communities like Proxima.

Meet the members of Proxima:
Anindyadeep (@anindyadeeps) is building Litefold. LiteFold combines physics-based simulation and AI to accelerate the design and validation of drug candidates in silico.
Their leading product is Rosalind: An AI Co-Scientist for Life Sciences.


1
2
25
1,577

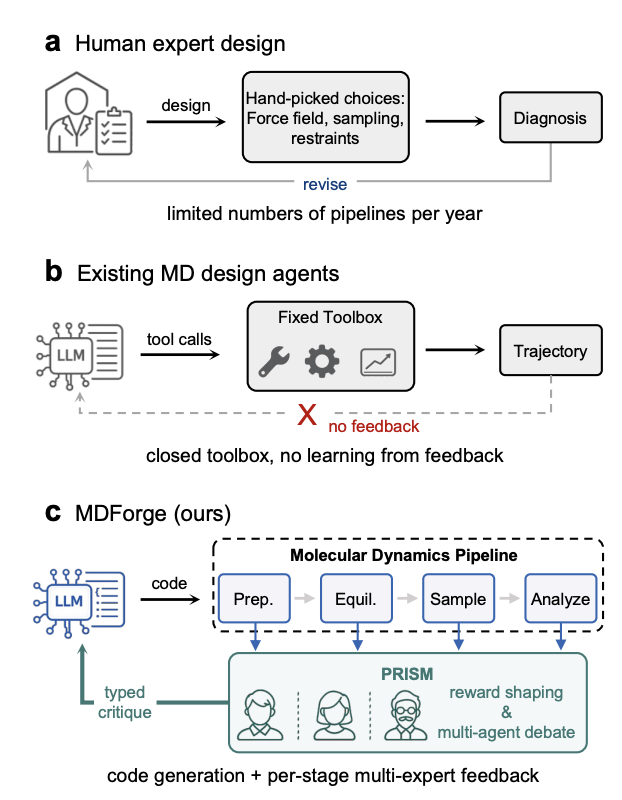
MDForge: Agentic Molecular Dynamics Pipeline Design under Sparse Simulator Feedback
1 MDForge is an LLM agent that autonomously designs full molecular dynamics (MD) pipelines as open-ended executable code, then improves them online from sparse, expensive simulator feedback (each trial can cost GPU-hours).
2 The key technical idea is PRISM (Process-Reward Interpretation via Subsystem Mediation): it turns a single terminal reward into dense, actionable signals by (a) extracting structured per-stage diagnostics across the MD pipeline (Prep, Equilibration, Production, Analysis) and (b) converting those diagnostics into typed critiques.
3 Instead of a fixed tool-calling “MD toolbox”, MDForge’s action space is program synthesis: the agent can compose whatever workflow the system demands (force-field setup, restraints, sampling protocol, estimators, guards, etc.), closer to what human experts actually do.
4 PRISM’s critique is produced by a multi-agent panel of physics specialists with non-overlapping jurisdictions: Force Field, Sampling, and Analysis. They debate in two rounds with cross-visibility, then an aggregator outputs a single typed critique that names the failing subsystem and the concrete edit to apply.
5 A reputation-weighting loop adjusts how much each specialist influences the final critique, based on whether their pre-execution predictions match post-execution evidence. This aims to downweight consistently miscalibrated “experts” within a task.
6 On SAMPL host–guest binding free-energy benchmarks (CB[7], OAH, CBClip), MDForge produced runnable pipelines reliably (5/5 successful trials per host) and improved held-out ranking performance versus verbal-RL baselines without PRISM. Example held-out Kendall tau: CB[7] 0.56 and CBClip 0.47, compared to 0.24 and 0.20 for a trial-level feedback baseline.
7 Ablations suggest both components matter: removing stage diagnostics caused unstable learning (the agent can’t localize what broke and may discard good pipelines), while removing multi-expert debate reduced transfer of ranking signal to held-out guests.
8 Mechanistically, PRISM encourages localized edits instead of “shotgun rewrites”: e.g., an Analysis-stage diagnostic flagging insufficient MBAR overlap triggers a typed critique to add an explicit overlap/convergence guard, implemented as a small targeted code change.
9 MDForge’s resulting CB[7] pipeline largely stayed in the methodological family of expert reference workflows (GAFF2 AM1-BCC charges, APR umbrella sampling, MBAR analysis), differing mainly in reliability-oriented engineering choices (guards, logging, automation).
10 In a prospective test, the best MDForge-designed CB[7] pipeline screened unseen candidate guests and selected Bromantane as top-1; competition 1H NMR against a picomolar reference (FMTA) measured Ka ≈ 8 × 10^12 M−1 (ΔGexp ≈ −17.6 kcal/mol), demonstrating end-to-end translation from autonomous pipeline design to wet-lab-confirmed high-affinity binding.
💻Code: github.com/Zehong-Wang/MDFor…
📜Paper: arxiv.org/abs/2606.12916
#MolecularDynamics #LLM #AgenticAI #ComputationalChemistry #FreeEnergyCalculations #SAMPL #ProgramSynthesis #VerbalRL #AI4Science
4
4
31
1,699

Jun 13
Very excited to visit Seoul and attend my first ICML conference and AI4Science workshop to discuss this work, AI, AI agents and agentic workflow in scientific research.
- Paper: arxiv.org/abs/2605.30353
- AI for Science Workshop at ICML2026: ai4sciencecommunity.github.i…
2
56
Hugging Science retweeted

Jun 10
Also big thanks goes to @huggingface for enabling open source AI and AI4science. we have been using HF for the longest time and our family of highly performant fMRI foundation models (CortexMAE) is available on HF along with the training dataset. @cgeorgiaw
1
2
22
10,507

Jun 12
most replies here are completely out of touch - you’d probably average out at 0.3%-1%. obviously a large difference between a $1bil seed funded ai4science org and a $5mil funded genomics startup
1
1,381

Impressive vision for ASCI.
Training a domain-specific model on full-text ingestion from nine rigorously curated academic corpora.
Eager to test the alpha. This could meaningfully raise the signal-to-noise ratio in scientific discovery. #AIResearch #AI4Science
Jun 12
1
23

Jun 12
4/ This is ASCI. #OPENSCI
We're building toward autonomous hypothesis generation and empirical validation.
The bottleneck for science has never been talent.
It's been time.
#AI4Science #AIScience
1
3
36

Jun 11
Are chemists done & is NMR solved? Not so fast! 🤔
Outperforming software is not the goal, to be truly useful, AI needs to operate like a human chemist under real lab conditions.
✨Check our #ICML2026 AI4Science Spotlight!
🔗OpenReview: openreview.net/forum?id=hsfH…
Thread 🧵
(1/7)
Jun 5

New Anthropic Science Blog: Making Claude a chemist.
To manipulate a molecule, chemists first need to understand its structure. Their main tool is NMR spectroscopy.
We found Opus 4.7 matches—and on some tasks beats—dedicated NMR software. Read more: anthropic.com/research/makin…
1
9
19
3,602

Next Monday (June 15), I’ll give a tutorial at AI4X 2026 Singapore, as part of the Agentic AI for Science tutorial.
My session: 10:30 AM–12:00 PM, Lecture Theater 29.
I’ll present the MOOSE research line, which asks:
How can LLMs help scientific discovery — with mathematical foundations, discovery harnesses, benchmarks, and scalable training recipes?
If you’re attending AI4X and interested in LLMs for scientific discovery / AI4Science, feel free to drop by!

3
14
890

Jun 10
In proud collaboration with Sam Leventhal & @HajijMustafa, led by @lennart_bastian!
📄 Paper: arxiv.org/abs/2606.09806
🌐 Project webpage: circle-group.github.io/resea… (in making)
💻 Code: [Coming soon]
Stay tuned for more from our CIRCLE group: circle-group.github.io/.
#ML #AI4Science
3
18
582

Jun 10
Excited to share that I’ll join MBZUAI as a tenure-track Assistant Professor in August 2026 and and lead the ATLAS Lab — AI for Trustworthy Learning and Science! 🚀
#MBZUAI #TrustworthyAI #AI4Science #GenAI #AcademicJobs #GenerativeAI #AgenticAI #LLM
5
1
14
2,033
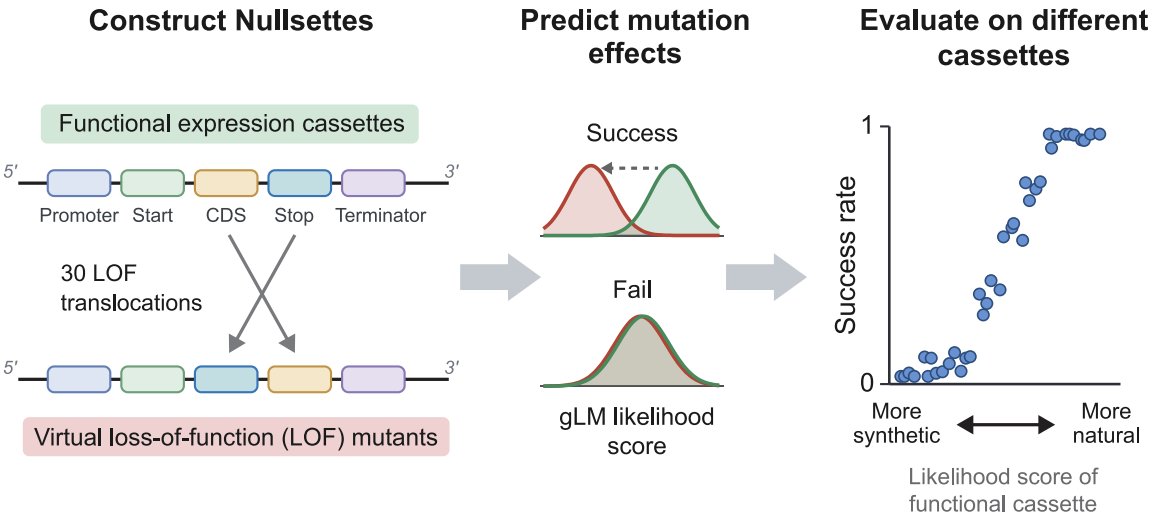
Evaluating DNA Function Understanding in Genomic Language Models Using Evolutionarily Implausible Sequences
1. The paper introduces Nullsettes, a benchmark designed to test whether genomic language models (gLMs) truly understand gene-expression function, rather than just matching evolutionary patterns seen in natural genomes.
2. Nullsettes creates in silico loss-of-function (LOF) mutations in synthetic expression cassettes by translocating key elements (e.g., promoter, start codon, CDS, stop codon, terminator; plus RBS in prokaryotes) so the canonical 5′→3′ regulatory architecture is broken while keeping all parts present.
3. The benchmark is intentionally “evolutionarily implausible”: nonmutant cassettes are functional yet low-likelihood under gLMs because they combine elements from distant species (e.g., GFP CDS with heterologous regulatory parts) and often use random but functional promoters from MPRA libraries.
4. Evaluation is zero-shot: for each cassette, a model scores the nonmutant and its Nullsettes mutants using sequence log-likelihood (or a model-specific pseudo-likelihood proxy), and a mutation type is considered detected if mutants show a statistically significant likelihood drop vs the nonmutant (paired permutation test with multiple-testing correction).
5. Across 14 state-of-the-art gLMs (35 variants), most models fail to reliably detect strong LOF mutations; 11/14 models drop below 50% success rate on at least one dataset, indicating poor generalization to engineered constructs that deviate from natural sequence statistics.
6. A key diagnostic finding is that prediction accuracy depends strongly on the model likelihood of the original (nonmutant) cassette: as nonmutant log-likelihood decreases, LOF detection collapses across nearly all models, consistent with reliance on evolutionary priors/pattern matching rather than mechanistic reasoning about transcription/translation.
7. Performance also worsens when promoters come from random-sequence libraries vs naturally derived promoters (significant paired drop across models), reinforcing that many gLMs behave sensibly mainly when evolutionary plausibility is a usable proxy for function.
8. Counterintuitively, more disruptive mutations (those breaking more steps of gene expression) are not easier for models; instead, success declines as disruption severity increases, suggesting models are not robustly tracking regulatory logic even when the functional failure should be obvious mechanistically.
9. Model comparisons suggest scaling is not the main lever: GENERanno-0.5B matches Evo2-7B despite far fewer parameters and less pretraining data, implying curated, function-relevant pretraining data can matter more than sheer size for functional generalization; AlphaGenome (supervised sequence-to-expression) is competitive on transcription-disrupting subsets but cannot be evaluated on translation-only disruptions.
💻Code: github.com/cellethology/GLM-…
📜Paper: doi.org/10.1021/acssynbio.6c…
#Genomics #SyntheticBiology #Bioinformatics #MachineLearning #FoundationModels #DNA #MPRA #RegulatoryGenomics #Benchmarking #AI4Science
1
9
26
3,424

Still looking for a nice place to present your latest research?
The abstract submission deadline for the Chemistry and Materials track at the AI4Science conference has just been extended till June-26.
Check out ai4sci.eu/ai4chemistrymateri…

1
1
67