
Fair point. However, the IT services and consulting folks do need to answer why has there been not even a SINGLE product/company/startup investments coming out in other areas of AI. Its not just about foundation models or implementation services.
What about:
1. Designing custom harnesses for industry specific usecases. Build / buy / invest in startups / incubate, etc. There should be a communication around it at the rate of once per week.
2. Thought leadership around key enterprise issues like data privacy, local vs cloud AI models? Not claude generated, gatekept 'white papers' but genuine demos publicly available and pushed around. Is there a genuine case example available?
3. Domain specific evals??? This is the biggest one. You're telling me that your Insurance practice is a billion $ big, you serve top 10 insurers but cannot build a productized service for Insurers to test 50 new AI tools and products with reliable evals and benchmarks? Its the same old tired 2018 case studies framework (gained 40% underwriting efficiency by using AI models). There is enough domain expertise in each of these large companies to help national insurers around evals and benchmarking all major workflows in each of 50 states, each of 10-15 product lines in the US. You have tonnes of teams doing very similar work across the industry and you're best placed to abstract out signals by spending some meaningful time with the humans working on those tasks.
Perhaps, what's missing is the organizational intent and will. Ultimately, I think its a cultural & incentives issue.
Cultural - My guess is that most CXOs still secretly hope and think that this is a massive fad/wave like the y2k/cloud, etc. and in the end they'll be vindicated via new implementation contracts by 'partners' like Anthropic/OpenAI/Google. I've read/listened to some of the Q'ly calls and nothing tells me otherwise.
Incentives - most execs have a revenue / eps target given by board, and they cannot get capex or startup investment proposals approved by the same board. They're superstars who've won at this game for years and now the game has changed.

Bashing Indian IT service companies for not building frontier AI is fair.
But they were built for services.
The real question is much sharper:
Where is Tata’s Qwen?
Qwen came from Alibaba — a company smaller than the listed Tata empire.
Where is Ambani’s ERNIE? ( Baidu )
Where is Mahindra’s Hunyuan?
Where is Adani’s Pangu?
Where is L&T’s defence AI foundation model?
Where is Birla’s industrial AI model?
China’s established corporate giants are building frontier models.
Alibaba built Qwen.
Baidu built ERNIE.
Tencent built Hunyuan.
Huawei built Pangu.
ByteDance built Doubao.
iFLYTEK built Spark.
So stop gaslighting people with “India lacks capital.”
India does not lack capital.
India does not lack engineers.
India lacks a billionaire class willing to risk serious money on frontier AI.
There is money for weddings, cricket, retail, ports, media, and political access.
But when it comes to building India’s Qwen, suddenly everyone becomes a cautious accountant.
That is the scandal.
14

Alex Murphy retweeted

OpenEvidence is understandably not happy with the recent LLM benchmarking study!
I agree with the larger point of better benchmarks needed. Perhaps OpenEvidence could be evaluated on our open and completely transparent Medmarks benchmark suite 🙂

Rigorous evaluation of medical AI is good for everyone, and we welcome it. Counter to a half-dozen independent studies from institutions such as the Mayo Clinic that were highly positive on OpenEvidence—a lone paper now purports to show that generalized AI beats specialized clinical AI (@UpToDate, @EvidenceOpen). The paper has a massive undisclosed conflict of interest and irredeemable methodological flaws.
Behind the scenes: The study authors run a competing in-house medical AI at their hospital, and asked OpenEvidence for an API to power it — including rights to build a "competing product" with OpenEvidence's own API. OpenEvidence declined. Then, this paper coincidentally appeared.
Point-by-point, looking closely at the datasets used in the study, the disingenuous and fatal flaws become immediately apparent 🧵.

1
4
26
3,394

They will walk on these streets in the name of benchmarking then come back home and install cabros on a single street and pose for dozens of photos
Jun 12

Our president and governors will visit such clean cities then come back to our filthy dirty towns and still feel proud.
2

40m
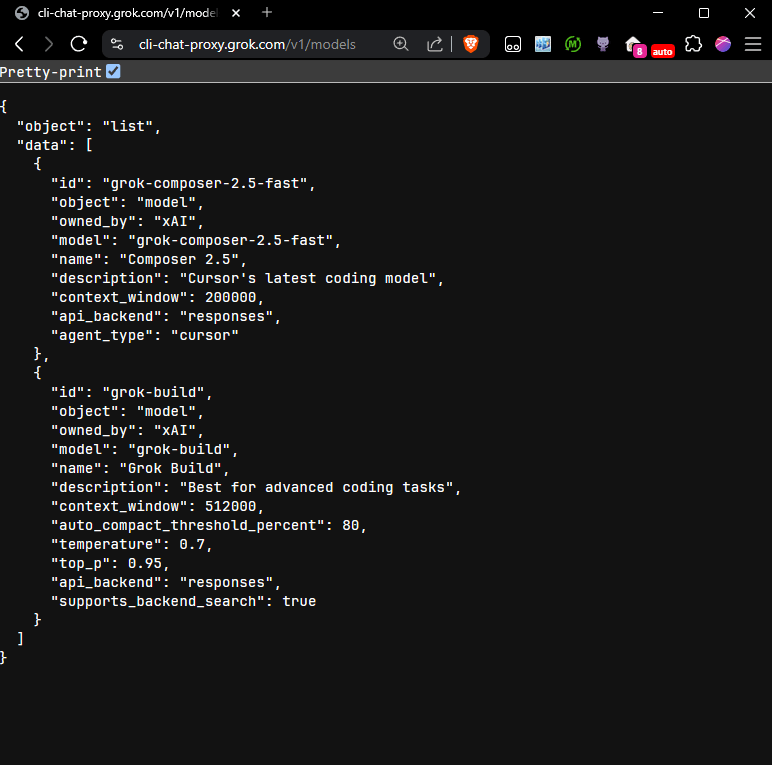
Native Composer is difficult to run in a client-agnostic/harness-agnostic way, but in case this helps:
xAI serves it too. Headless benchmarking is easy and legal. Free tokens included in your already owned SuperGrok subscription.

22

Same with whiteland and Privana north and eventually both Aspen and Aravallis will get benifit of shift in benchmarking because of the name NORTH close to them.
6

Bitcoin was the first cryptocurrency. Many had their doubts. Yes,it later turned out good.
But the continuous benchmarking GTECH on the performance of Bitcoin only point to one direction...@gtechnetwork will never list the coin.
1
19

The aging biomarker field has a measurement problem that nobody talks about. Over the past decade, we've accumulated dozens of epigenetic clocks, each trained on different cohorts, different preprocessing pipelines, different endpoints. Horvath, GrimAge, PhenoAge, DunedinPACE. All claim to measure biological age. But because none were ever tested head to head on the same dataset, the honest answer to "which one works best" has been: we don't actually know.
The Biomarkers of Aging Challenge, now published in Nature Aging, took the same approach that transformed protein structure prediction. CASP gave us AlphaFold. This challenge gives aging measurement its first real benchmarking arena. Five hundred individuals, ages 18 to 99, DNA methylation profiles paired with real health outcomes, all run through a single standardized platform. Open to anyone. The winning models identified novel methylation signatures and outperformed existing biomarkers by combining advanced machine learning with biological domain knowledge that no single lab would have deployed alone.
The question that matters most in longevity science right now isn't whether we can measure aging. It's whether we can agree on how to measure it. This is the infrastructure that makes agreement possible. 🧬
pubmed.ncbi.nlm.nih.gov/4227…
13

"A strong example of transparent AI benchmarking. The open-source approach and publicly tracked predictions add real credibility to the results. Great work!" 🚀
190

@GovernmentZA needs to go around for immigration benchmarking cause clearly they are clueless about what needs to be done and how to implement our laws. South Africa is our only home and it must be protected. Having the same skin colour doesn't mean we must allow lawlessness.

This video serves as a reminder that in South Africa, we are governed by morons who can't reason at all. People who cannot protect the future of their country, all they know is looting the state.
We are in SERIOUS TROUBLE with the current leaders.
13
Aarav Fractal retweeted

You shouldn't have to reveal your salary to prove you're underpaid.
So I built PayParity — confidential salary benchmarking on Zama's FHE stack. It computes on encrypted data. Your numbers stay private, the comparison still works.
Prove fair pay. Expose nothing.

1
1
1
14

Mtukufu lies @WilliamsRuto and fashionista @kipmurkomen seems you went to Haiti for benchmarking how a country can be run by goons you are the idiots who our forefathers warned us about
241

Post 1️⃣
India Healthcare Achievements – in last 12 years!!
You can use this data in Mains
✅ Medical Education Expansion
"India Doubled Its Medical Colleges in 12 Years"
Medical colleges: 842 (2014) → 2,100 (2026) — 2.5x increase
MBBS seats: 51,348 (2014) → 1.28 lakh (2026) — 2.5x increase
PG seats: 31,185 (2014) → 85,822 (2026) — 2.75x increase
✅Indigenous Medical Innovation
"India Started Building Its Own Cures"
NexCAR19 – India's first CAR-T (Chimeric Antigen Receptor T-cell) therapy for cancer; indigenously developed and world's most affordable CAR-T
Developed first indigenous MRI machine to reduce diagnosis costs
Nafithromycin – India's first indigenous Macrolide antibiotic against pneumonia (2024)
10,000 genomes sequenced under GIP (Genome India Project)
Penicillin G production resumed after a 30-year gap
✅HPV Vaccination
"India's Big HPV Push"
Free HPV vaccine for 1.15 crore girls aged 14 — protection against cervical cancer
90-day nationwide drive for maximum coverage
India joins 160 countries with HPV vaccination programmes
✅Healthcare Budget
"The Healthcare Budget Went Beast Mode"
Budget: ₹35,163 Crore (2014–15) → ₹1,06,530 Crore (2026–27)
203% increase
✅Tuberculosis Control
"TB Is Losing Ground in India"
93.33% drop in missing TB cases
TB incidence fell by 21% (double the global pace)
TB treatment coverage: 53% (2015) → 92% (2024)
Over 20 crore vulnerable population screened
28 lakh patients diagnosed under TB Mukt Bharat Abhiyan (Pradhan Mantri Tuberculosis Mukt Bharat Abhiyan)
✅AI in Healthcare
"India Unlocked AI in Healthcare"
Launched SAHI (Strategy for Artificial Intelligence in Healthcare for India)
National Federated Learning Platform — validating AI health models using data under ABDM (Ayushman Bharat Digital Mission)
Among the first countries to adopt a national AI strategy for health in South-East Asia
BODH (Benchmarking Open Data Platform for Health AI) — developed by IIT Kanpur and NHA for testing and benchmarking AI solutions
✅Disease Elimination
"Diseases That Haunted India? Almost Gone"
India declared Trachoma-free by WHO in 2024
Became the 3rd country in South-East Asia to achieve this
Malaria cases down by 80% , deaths down by 78%
Now targeting elimination of: TB, Leprosy, LF (Lymphatic Filariasis), Measles, Rubella, and Kala-azar
✅ BioPharma Growth
"BioPharma Is India's Next Flex"
₹10,000 crore allocated for Biopharma SHAKTI (Strengthening Healthcare and Knowledge-based Technology Innovation)
Bioeconomy: $10B (2014) → $195B (2025) → target $300B by 2030
11,800 biotech startups
India supplies 70% of global anti-retrovirals and 55–60% of UNICEF vaccines
Pharma exports: $31B in FY26
✅COVID-19 Vaccination
"India Ran the World's Fastest Vaccine Drive"
220 crore COVID-19 vaccination doses administered
Developed 2 indigenous vaccines in under 1 year
Single-day record: over 2.5 crore vaccine doses
1
2
11
509

2h
InfoFi programs on Kaito ran real protocol spend last quarter. It's a paying network.
$KAITO ~13% today, $113M mcap, $24M volume. The part that needs benchmarking: governance token only, or is there a fee distribution mechanism?
Move looks positioned, not speculative. Someone has a view.
8

Public funds have evidently been allocated and misused, yet the ground reality raises serious questions about how effectively those resources are translating into safer and more humane civic operations.
The manner in which this work is being carried out appears deeply concerning, particularly for the workers being deployed under such conditions.
Perhaps it is time for our Hon. @PMOIndia to examine how critical infrastructure and drainage maintenance are undertaken in advanced nations, and consider bringing safer, more efficient, and more dignified technologies to India.
@CMOMaharashtra, is this truly the standard of drainage cleaning we aspire to — or the kind practiced in places like Davos and other global cities recently visited for benchmarking governance models?
@mybmc, despite being regarded as India’s richest municipal corporation and among the wealthiest civic bodies in Asia, with a reported annual budget of ₹74,427 crore, citizens are entitled to ask whether such resources are adequately reflecting in modern civic practices and worker safety.
@mayor_mumbai @TawdeRitu @AshwiniBhide — does this align with the values of humane governance?
@ShelarAshish @AmeetSatam — would appreciate your views on whether this is the best we can offer as a city.

Forget child labour..no human being should be allowed to enter these drains!
BMC pays huge amounts to contractors for this work. Why can’t they use machinery, which would make the job faster, safer and more efficient?
Just to save money, they are putting human lives at risk!
@Dev_Fadnavis @TawdeRitu, please take strict action against these contractors. 🙏🏻
19

2023: Prompts.
2024: Models.
2025: Agents.
2026: Loops.
2027: Systems.
Everyone is benchmarking IQ.
Winners are benchmarking context, memory, tools, permissions, orchestration, and MCP.
The model is becoming a commodity.
The runtime is the moat.
1
7


Hi. Do you do benchmarking for the Kimi K2.7 model? I couldn't see it in your leadboard.
27

Totally understand and it’s not meant to be a critique, just a reflection how incentives drive behavior.
For better or worse, contamination of public benchmarks and the lack of understanding of what harness/tools each model uses is completely common in benchmarking LLMs. I’ve become more cynical about these types of papers - it oftentimes just reaffirms prior biases.
I for one, think the harness/tooling/distribution is critical and at least half the value, which is kudos to the tremendous progress OE has made in pushing medicine into the future.
1
14

The risk/reward is logically valid but thats not even what I was referring to. It’s more a factor of small team grinding like crazy just to keep the core product improving for real world users, which is both a resource constraint/opportunity cost in itself, and also makes it really hard to do an full academic eval that’s better than nothing, bc all the targets are moving and the stuff we care about most is often near impossible to measure anyway. So it’s just in practice hard to do something truly academically useful to the world, esp at the direct practical cost to ongoing product improvement. And we all know that the common benchmarks are horrible as soon as you dig into them, so just blindly maxing around those is also bad. Again, I’m sure that will ring hollow, and also hope we can get more into the academic world as if nothing else it’s good citizenship.
For the second part: Do you really think it’s standard for LLM benchmarking papers to have open web search for old web searchable datasets, and have the headline finding be comparing to closed to web search models? If so, then that’s pretty freaking depressing.
1
1
3
29