
May 23
Stage4 P4 is complete.
Today:
- preview lineage implementation finalized
- freeze snapshot verified
- lineage note recorded
- pushed to GitHub
Built one layer deeper around observation without over-assertion.
A boundary that can inspect, trace, and preserve—without collapsing into verdict.
Next: back to Stage4 runtime governance.
Stage4 P4 完了。
今日は
・preview lineage 実装完了
・freeze snapshot確認
・lineage note保存
・GitHub push完了
「観測すること」と
「断定しすぎないこと」
その境界を守るための確認レイヤーを、
ひとつ深く積み上げました。
次は Stage4 runtime governance 本流へ戻ります。
#VECTOR #AI_Lab
#CAW . 🌘🤲✨
3
45

Including current fancy job at $AI_lab
1
8
314

Mar 30
1
9
759

ULB CODE – 800734
नगर निगम के स्कूल, अब डिजिटल युग के साथ।
गाजियाबाद नगर आयुक्त विक्रमादित्य सिंह मलिक द्वारा भोपुरा स्थित नगर निगम स्कूल में छात्राओं के लिए AI और डिजिटल लैब की शुरुआत की गई।
यह पहल छात्राओं को आधुनिक तकनीक से जोड़ते हुए उनके उज्ज्वल भविष्य की दिशा में एक मजबूत कदम है।
@SBMUrbanUP @mlkhattar @tokhansahu_bjp
@aksharmaBharat @ChiefSecyUP @Secretary_MoHUA @RoopaMishra77 @CommissionerMe3 @dm_ghaziabad @sunitadayalbjp @VikramadityaSM @NSA_GNN
#नगरनिगम_स्कूल #डिजिटल_शिक्षा #AI_Lab #DigitalLab #SmartEducation #FutureReadyStudents #GirlsInTech #EducationForAll #DigitalIndia #GhaziabadNagarNigam #VikramadityaSinghMalik #SchoolTransformation #TechForEducation #BrightFuture

4
92

24 Jun 2025
気づけば今週…!金曜日にestieオフィスでライブコーディング含むAI駆動開発の知見共有イベントやります! #不動産AI_Lab
24 Jun 2025

【6/27 AI駆動開発MeetUp at estie🎉 】
「AI駆動開発MeetUp」の開催まであと3日となりました!
estie六本木オフィスでの現地開催です。
ぜひご参加ください!
estie.connpass.com/event/357…
1
4
914

1 May 2025
🔸Reliable Interactive FCIT Chatbot using RAG
🔸Pass Classification in Football using Computer Vision
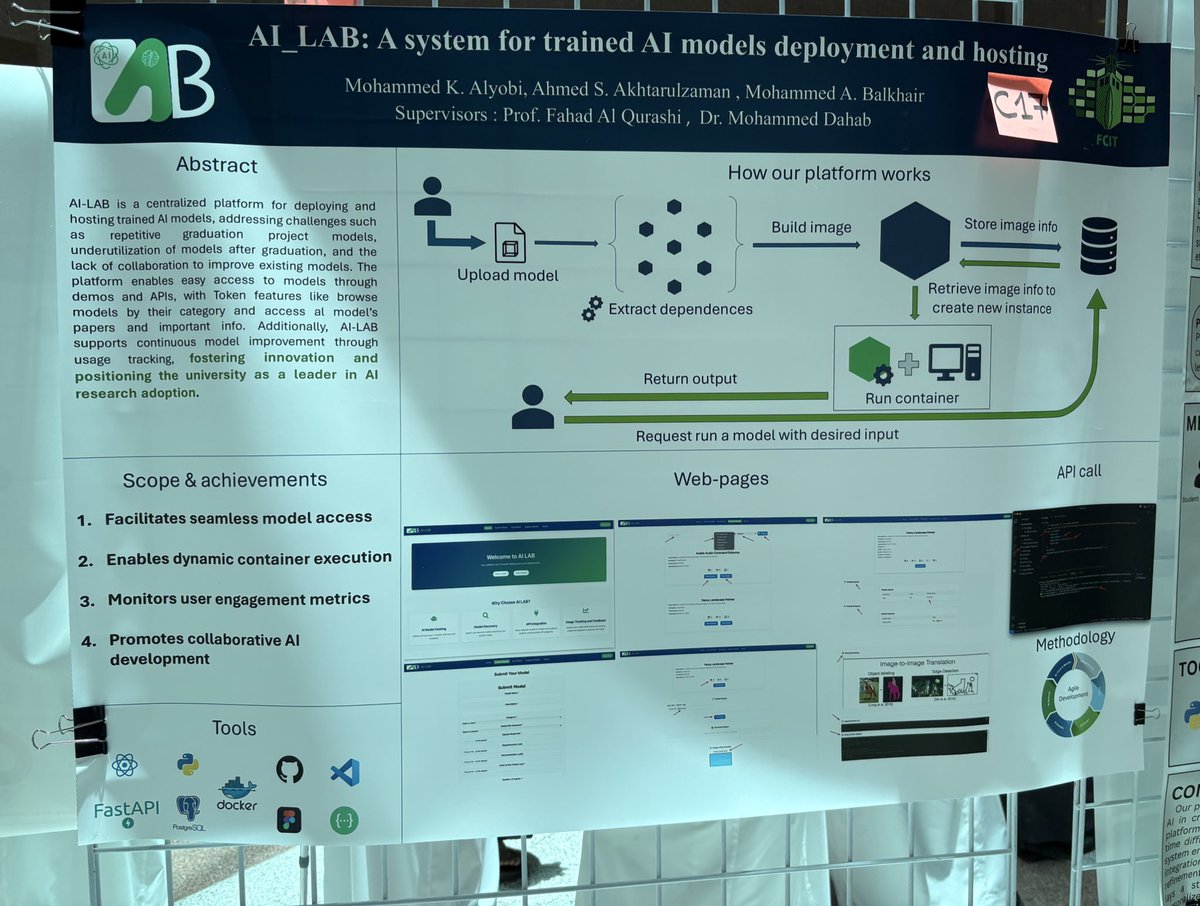
🔸AI_LAB: System for Trained AI Models Deployment and Hosting
🔸AI-Powered Graduation Project Management System



1
2
1,360

8 Mar 2025
#እኛ_የሚያጨበጭብልን_ካድሬ_አንፈልግም!
የ1ኛው ክፍለ ዘመን ብልፅግና ሰሙኑን በፕሮፓጋንዳ የተጠመደበት እኛ ሌላ ዓለም ውስጥ መግባታችንን አለማወቁ እጅግ ኋላቀር ስብስብ መሆኑንም መረዳት ይቻላል!😁 ጭራሽ የተማሪዎች #AI_Lab. ገብቶ መደስኮር🤣




4
23
1,374

31 Jan 2025
#DeepSeek models are live on @Krutrim Cloud with #cheapest price in the world.
We will also share details on our #AI_lab, state-of-the-art #Indic models and research progress including #OpenSource drops on 4th Feb!
#AI4India
31 Jan 2025

India can’t be left behind in AI. @Krutrim has accelerated efforts to develop world class AI. As first step, our cloud now has DeepSeek models live, hosted on Indian servers. Pricing lowest in the world bit.ly/4hxS7wM
Details on our AI lab, SOTA model and research progress, open source drops on 4th Feb!
1
7
1,157

14 Nov 2024
Y EL PERFIL DICE AI_LAB, MAS INNTELCIA ARTIFICIAL NO PUEDE SER
3
402

6 Sep 2024
Google scholar citations of papers from #NAVER #AI_Lab were over 40,000 since 2017! H-index and i10-index are 75 and 205 including #BioBERT, #Cutmix, #StarGAN!
Sangdoo Yun (current head of AI lab) 's citation has been already overtaken mine!
really proud!
scholar.google.com/citations…

5
13
189
24,089

31 Aug 2024

4
11
1,139

🤝 Representantes del @gob_na, el @culturagob y el sector audiovisual se han reunido en ‘Professor Octopus AI_LAB’ (@PlatypusWombat), la primera Unidad de I D i empresarial del sector audiovisual en Navarra que desarrolla tecnología de IA para las Industrias Creativas.


2
6
543

Profesor Octopus AI_LAB se convierte en la primera Unidad de I D i Empresarial del sector audiovisual del #SINAI 🥳
8 Feb 2024

💡 #INNOVACIÓN | La empresa que ha invertido 2 millones en un laboratorio de IA para las industrias creativas y digitales. #NavCapital @ADItech @gob_na #SINAI #InnovaciónNavarra
navarracapital.es/la-empresa…
2
93

19 Nov 2023
💥💥 NÀO TA CÙNG...NHẢY SỐ !
Tư duy xíu nha bà con
1️⃣CEO #Digiu Alexey Ognev đã từng là Top Manager 5 năm liền tại 2 công ty phần mềm tại Thành phố Novosibirsk
2️⃣Anh ấy cũng từng là quản lý tại Ngân hàng Sberbank 2 năm liền ( Liên Bang Nga )
3️⃣Hiện nay anh ấy đang cố vấn cho Ngân hàng Trung Ương tại 1 Quốc Gia châu Phi để giúp họ phát hành #CBDC ( tiền Điện tử Quốc Gia Nam Phi )
4️⃣ Tháng 08/2024 Chính Phủ Nga trao quyền cho Ngân hàng TW Sberbank triển khai thí điểm CBDC đầu tiên với dùng tại Nga
5️⃣Cùng chờ đợi điều gì nữa đây .... ACE viết tiếp giúp mình nha
#DigiU #RWA
#blockchain
#AI_Lab
#CBDC
1
3
115
8 Nov 2023
💥💥 NÀO TA CÙNG...NHẢY SỐ !
Tư duy xíu nha bà con
1️⃣CEO #Digiu Alexey Ognev đã từng là Top Manager 5 năm liền tại 2 công ty phần mềm tại Thành phố Novosibirsk
2️⃣Anh ấy cũng từng là quản lý tại Ngân hàng Sberbank 2 năm liền ( Liên Bang Nga )
3️⃣Hiện nay anh ấy đang cố vấn cho Ngân hàng Trung Ương tại 1 Quốc Gia châu Phi để giúp họ phát hành #CBDC ( tiền Điện tử Quốc Gia Nam Phi )
4️⃣ Tháng 08/2024 Chính Phủ Nga trao quyền cho Ngân hàng TW Sberbank triển khai thí điểm CBDC đầu tiên với dùng tại Nga
5️⃣Cùng chờ đợi điều gì nữa đây .... ACE viết tiếp giúp mình nha
#DigiU #RWA
#blockchain
#AI_Lab
#CBDC



8
10
258

7 Jun 2023


2
222
2 Jun 2023


2
196
31 May 2023
2
134
24 May 2023

Aligning Large Language Models through Synthetic Feedback
propose a novel framework for alignment learning with almost no human labor and no dependency on pre-aligned LLMs. First, we perform reward modeling (RM) with synthetic feedback by contrasting responses from vanilla LLMs with various sizes and prompts. Then, we use the RM for simulating high-quality demonstrations to train a supervised policy and for further optimizing the model with reinforcement learning. Our resulting model, Aligned Language Model with Synthetic Training dataset (ALMoST), outperforms open-sourced models, including Alpaca, Dolly, and OpenAssistant, which are trained on the outputs of InstructGPT or human-annotated instructions. Our 7B-sized model outperforms the 12-13B models in the A/B tests using GPT-4 as the judge with about 75% winning rate on average
paper page: huggingface.co/papers/2305.1…

1
10
61
23,131
31 Jan 2023
31 Jan 2023

[1/9] How to be a scalable video-language model in terms of video length?🤔 🎞️
We propose a 🌟Semi-Parametric Video-Grounded Text Generation🌟 as the answer, treating a video as an external data store and employing cross-modal retrieval.
📜 arxiv.org/abs/2301.11507

20
2,085