
ReLU & GELU — How a Neuron Decides
A neuron has to make one decision, billions of times a second: fire, or don't fire.
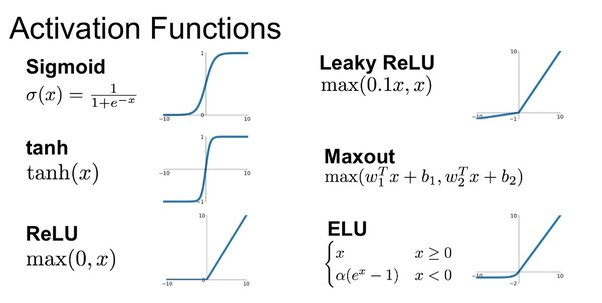
For most of AI's history, that decision was made by a smooth curve — sigmoid, or its cousin tanh. Sigmoid takes any number, squeezes it into a value between 0 and 1, and outputs that. Beautiful math. Catastrophic in practice. The problem: at the extremes, the curve flattens. The gradient — the signal that tells the neuron "you should adjust" — shrinks to almost nothing. Stack 50 of these layers, and the learning signal at the bottom is essentially zero. Networks refused to train. The field hit a wall around 2006 and stayed there for years.
In 2010, two researchers named Vinod Nair and Geoffrey Hinton proposed something brutally simple. Replace the curve with a hinge. If the input is positive, pass it through unchanged. If the input is negative, output zero. That's it. That was the entire contribution. They called it ReLU — Rectified Linear Unit.
The math is one line. The effect was enormous. The gradient on the positive side stays at exactly 1. No vanishing. Signals flow through 50 layers, 100 layers, 1,000 layers. The deeper you stack, the more ReLU outperforms the smooth curves that came before. By 2015 it was the default. By 2020 it was everywhere.
But ReLU had a quiet flaw. A neuron that only ever sees negative inputs will output zero forever. Its gradient is also zero. It never recovers. Engineers called this the "dying ReLU" problem. A bad initialization, a bad batch, and 30% of your network could just go silent and never come back.
In 2016, Dan Hendrycks and Kevin Gimpel asked: what if the decision to fire is probabilistic, not binary? They took the standard normal curve — the bell curve — and asked, for each input, "what's the probability that this value is positive?" Multiply the input by that probability. If the input is large and positive, fire fully. If it's slightly negative, fire a little. If it's deeply negative, don't fire. Smooth where ReLU is sharp. Gentle where ReLU kills. They called it GELU — Gaussian Error Linear Unit.
Every BERT, every GPT, every modern transformer uses GELU. The hinge was good. The probabilistic hinge was better.
The lesson: a neuron doesn't need a smooth decision. It needs the right decision. For a decade, the right answer was "yes or no." Now it's "yes, probably, by this much."
— 算子次元 · One-minute AI · #13 ReLU & GELU #AI #MachineLearning #DeepLearning #NeuralNetworks #ActivationFunction

73

17 Oct 2025
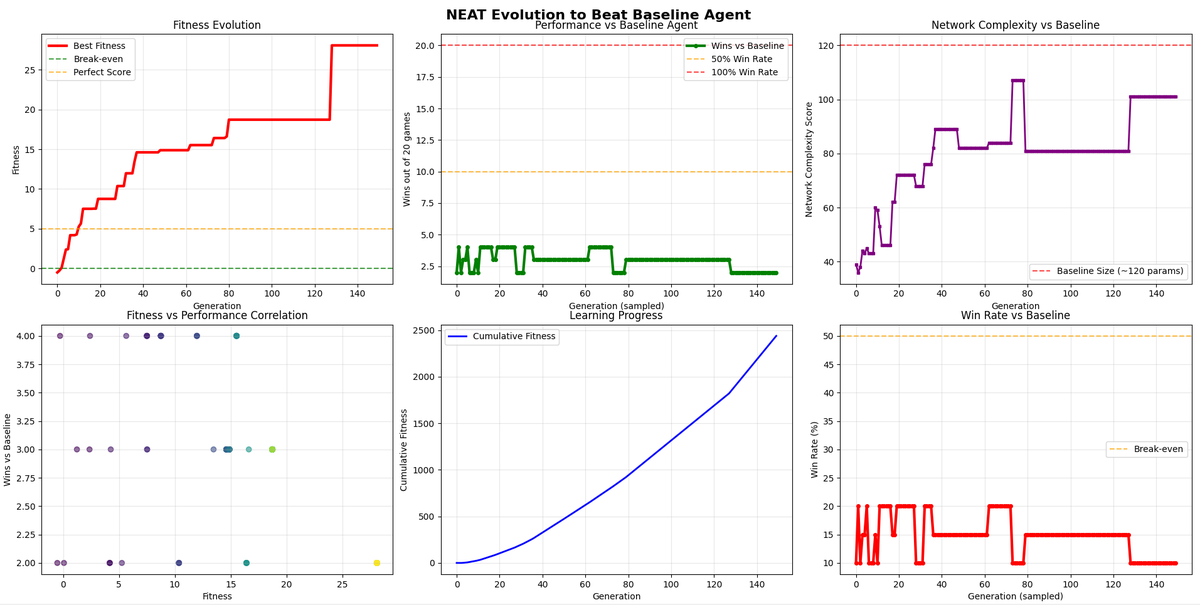
Somewhere in the start this was the result now it’s improving and improving (soon beating the baseline model) 🚀
@SakanaAILabs papers are helping a lot 💡
#NEAT #activationfunction
14 Oct 2025

Not so good it was a 14% win over the baseline model
I am happy but wanting to reach 25%
Better than earlier but I am devastatedly tired as it took 161172.8s == 44.77 hrs, will try one more time after changes with the activation functions and all
lets see after 50 hrs
6
284

17 Jun 2024
🚀 Day 8 of #100DaysOfDeepLearning:
🛡️ Learned Regularization: Keeping those models in preventing overfitting!
⚡ Mastered Activation Functions: Adding non-linearity and depth to neural networks!
#DeepLearning #Regularization #ActivationFunction #100DaysOfCode
6
71

14 May 2024
and the #activationfunction (#ReLU, #Softmax, etc) is the traffic warden allowing/restricting/converting the flow direction
Now let's make it complex!
Deep learning architectures come in various flavors, So:-
1
36

9 Apr 2024
Tanh as an activation function in machine learning offers high accuracy but is computationally expensive. #tanh #activationfunction #machinelearning
1
251

9 Mar 2024
📝Day 20 of #Deeplearning
▫️ Topic - Activation Function
🔰In Artificial Neural Networks or ANN, each neuron forms a weighted sum of its inputs & passes resulting scalar value through a function referred to as an #Activationfunction or step function
A Complete 🧵

5
10
33
6,923

15 Jan 2024
In this case the activationFunction implements the step function. The function returns 1.0 if the input is greater than 0 and 0.0 otherwise.
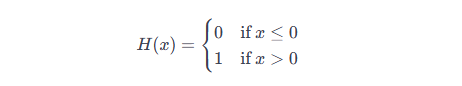
1
1
300

2 Jul 2023
you are looking for the "best" ACTIVATION function, be ready to spend some time looking for it because there are hundreds of them! #ArtificialIntelligence #AI #Robotics #DataScience #MachineLearning #DeepLearning #DataScientists #algorithms #activationfunction
3
50

6 Jun 2023
Uniqtech Guide to Activation Functions
medium.com/data-science-boot…
#DataScience #ActivationFunction #MachineLearning #AI #100DaysOfCode #100DaysOfPython
2
21

1 Jun 2023
رشته توئیت #شبکه_عصبی به جایی رسیده که داره مطالبش مشکل تر میشه.
برای توضیح مطالب جدید، بهتر دیدم رشته توئیت های جداگانه بزنم و از اونجا ارجاع بدم به این رشته توئیت ها.
اولین رشته توئیت در مورد #تابع_فعال_سازی یا #ActivationFunction هست که قراره اینجا در موردش بگم/1
1
8
766

🤯 Lowkey Goated When Deep Reinforcement Learning Continues To Amaze! 🤯 Check out the groundbreaking paper by @zaheer_abbas14 et al. on Loss of Plasticity in Continual #ReinforcementLearning #ActivationFunction 🤩 Link: deepai.org/publication/loss-…
2
1,307
🔥Lowkey Goated When ReLU Networks Are The Vibe🔥 Check out this paper on two-layer ReLU Networks by Yiwen Kou et al. #DeepLearning #ActivationFunction deepai.org/publication/benig…
2
933
🤯 Check out this groundbreaking paper by @juhan_bae, Nikita Dhawan et al. on Activation Functions and ReLus! 🔗 deepai.org/publication/effic… #NeuralNetworks #ActivationFunction #ReLu
3
12
2,043
Level up your data science vocabulary: Constant Error Carousel deepai.org/machine-learning-… #ActivationFunction #ConstantErrorCarousel
4
1,184
Level up your data science vocabulary: Activation Function deepai.org/machine-learning-… #VanishingGradientProblem #ActivationFunction
1
1
3

25 Nov 2022
Saved this Tweet to your Notion database.
Tags: [Activationfunction, Neuralnetwork, Tutorial, Datascience]
MixBin: Towards Budgeted Binarization
deepai.org/publication/mixbi…
by @UdbhavBamba et al.
#ActivationFunction #Binarization
3

18 Nov 2022
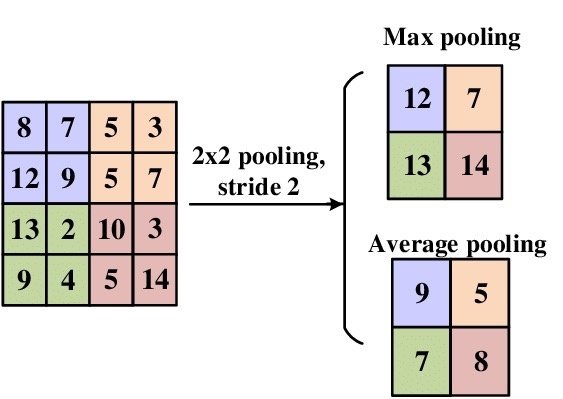
في التعلم العميق #DeepLearning #CNN يكون هنالك خطآ في فهم دور #ActivationFunction and #Pooling حيث AF تعمل على اضافه وظيفه غيرخطية الى النموذج لتمثيل وظائف معقدة بينما P تعمل علي تقليل الابعاد والسمات وكمية بيانات التعلم وبطريقة غير خطيه ويجب تطبيقها بعد AF في النموذج #Python #AI
10
38
From the Machine Learning & Data Science glossary: Multilayer Perceptron deepai.org/machine-learning-… #ActivationFunction #MultilayerPerceptron
2
7
DeepAI Term of the Day: Vanishing Gradient Problem deepai.org/machine-learning-… #ActivationFunction #VanishingGradientProblem
2
6