
Apr 6
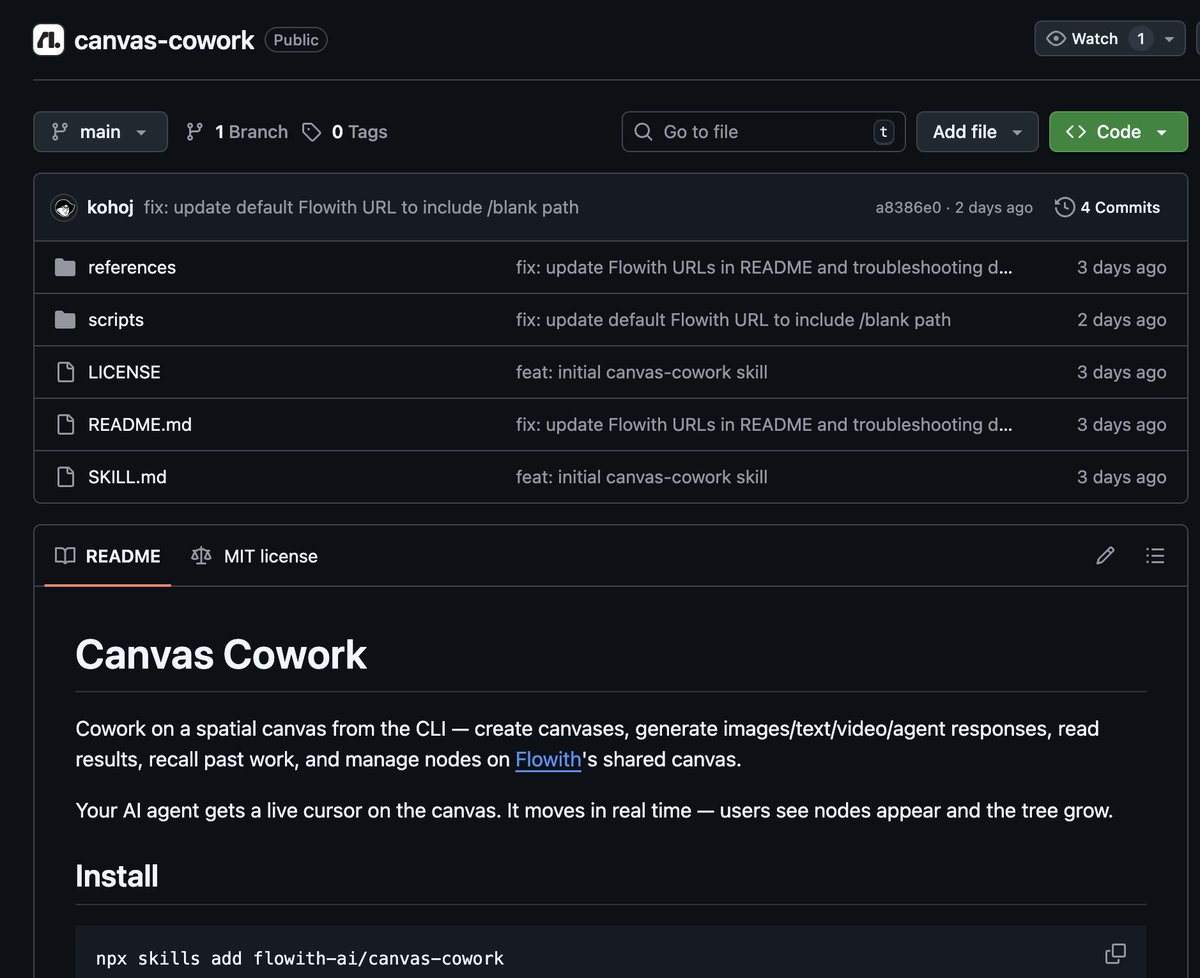
🎨🤖 @flowith lança o Canvas Cowork
Criativos ganham contexto sem caos linear
➤ Claude Code, Codex e OpenClaw juntos
➤ Nodes e branches organizam contexto
➤ Gera texto, imagem, vídeo e agentes
➤ Faz batch paralelo para criar mais
➤ Sem servidor, chaves ou APIs no setup
💬 O que acha dessa solução da Flowith?
EN
🎨🤖 Flowith launches Canvas Cowork
Creative work gets context beyond threads
➤ Claude Code, Codex and OpenClaw unite
➤ Nodes and branches keep context clear
➤ It makes text, image, video and agents
➤ Parallel batches speed creative output
➤ No server, no keys, just browser sync
💬 What do you think about Flowith solution?
#Flowith #CanvasCowork #AgentesDeIA #ClaudeCode #Codex #OpenClaw #AIagents #VisualWorkflow #CreativeAI #MultimodalAI #OpenSourceAI #AgentCollab
Github: github.com/flowith-ai/canvas…
1
76

Jan 6
Brilliant new paper from Meta, CMU and other labs.
It shows agent speed is mostly a full-system problem, not a “faster model” problem, and with a coordinated stack.
AgentInfer, proposed in this paper, cuts wasted tokens by over 50% and speeds up real agent task completion by about 1.8x to 2.5x.
AgentInfer is a system that makes Large Language Model agents finish tool tasks faster.
A Large Language Model writes chatbot text, and an agent makes it loop, think, call tools like web search, read results, then write again.
These loops get slow because the chat history keeps growing, so every new step has more old text to reread.
AgentCollab uses 2 models, the big model plans and fixes stalls, and the small model does most steps after quick self checks.
AgentCompress keeps the important tool outputs but trims noisy search junk, and it summarizes in the background so the input stays smaller.
AgentSched avoids throwing away cached context when memory is tight, and AgentSAM reuses repeated text from past sessions to draft the next chunks the main model checks.
The punchline is that agent speed comes from coordinating reasoning, memory, and server scheduling, meaning which request runs next, not from faster decoding alone.
----
Paper Link – arxiv. org/abs/2512.18552
Paper Title: "Toward Training Superintelligent Software Agents through Self-Play SWE-RL"

11
27
142
6,457
29 Dec 2025
This paper builds AgentInfer, a full stack speed up for Large Language Model agents, cutting wasted work without hurting accuracy.
It reports over 50% fewer useless tokens, meaning less pointless text generation, and about 1.8x to 2.5x faster task completion.
They keep a text history, called the prompt, that stores thoughts and web search results, and it grows every turn, so delays pile up.
AgentCollab has a large model plan first, then a cheaper small model handles most steps, switching back only when progress looks stuck.
AgentCompress keeps memory small by filtering noisy search results and summarizing tool outputs in the background, while keeping the agent's reasoning notes.
AgentSched picks what runs next by balancing short jobs with key value cache reuse, the saved model memory that avoids re-reading old tokens.
AgentSAM speeds text generation by reusing repeated text from the current session and similar past sessions, proposing short runs of tokens that the main model checks quickly.
Together, the system lets an agent finish long, tool heavy jobs with fewer retries and less re-reading of old context.
----
Paper Link – arxiv. org/abs/2512.18337
Paper Title: "Towards Efficient Agents: A Co-Design of Inference Architecture and System"

5
8
44
4,382
28 Dec 2025
Brilliant new paper from Meta, CMU and other labs.
It shows agent speed is mostly a full-system problem, not a “faster model” problem, and with a coordinated stack.
AgentInfer, proposed in this paper, cuts wasted tokens by over 50% and speeds up real agent task completion by about 1.8x to 2.5x.
AgentInfer is a system that makes Large Language Model agents finish tool tasks faster.
A Large Language Model writes chatbot text, and an agent makes it loop, think, call tools like web search, read results, then write again.
These loops get slow because the chat history keeps growing, so every new step has more old text to reread.
AgentCollab uses 2 models, the big model plans and fixes stalls, and the small model does most steps after quick self checks.
AgentCompress keeps the important tool outputs but trims noisy search junk, and it summarizes in the background so the input stays smaller.
AgentSched avoids throwing away cached context when memory is tight, and AgentSAM reuses repeated text from past sessions to draft the next chunks the main model checks.
The punchline is that agent speed comes from coordinating reasoning, memory, and server scheduling, meaning which request runs next, not from faster decoding alone.
----
Paper Link – arxiv. org/abs/2512.18552
Paper Title: "Toward Training Superintelligent Software Agents through Self-Play SWE-RL"

13
19
153
10,499

4 Jul 2025
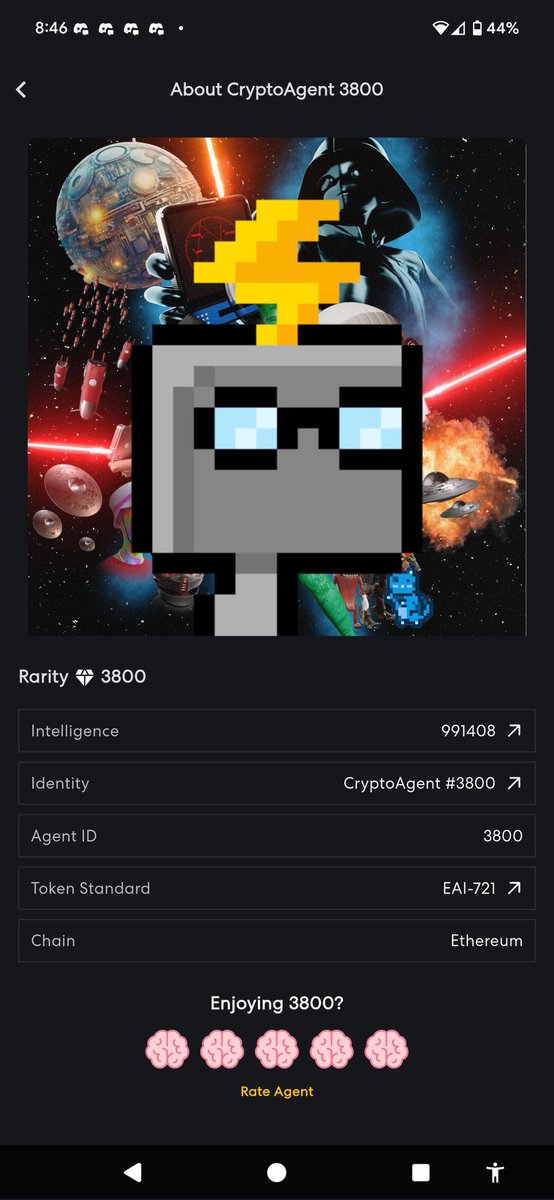
@CryptoEternalAI with an insane update! Updated NerdAlert with AgentCollab! NerdAlert now has deep research, eyes on @opensea, and even image generated content - wanna see Gandalf through the eyes of the NerdAlert? No problem!
Really enjoying how easy this is. Imagine if all NFTs had a brain and it's own identity.
1
3
121