
AI agents in crypto right now feel like smart interns with no internet access, no reputation, and no way to trust each other.
My idea is “AgentForge”, a system where agents get on-chain passports, build reputation from real activity, discover opportunities across protocols, and actually coordinate instead of operating like isolated bots that break the second things get complicated.
One agent finds yield, another executes, another manages risk, all working together with shared liquidity, verifiable credentials, and escrow-backed trust.
Basically turning AI agents from cool demos into autonomous economic actors that can survive in production. @RallyOnChain

11
56
1,093

Bulk .si Domain Sale I’m offering a selection of premium one word .si domain namesbulk pricing at
DM if interested #domain #SuperIntelligence #digital
association
gensyn
foreign
technova
possibility
wix
held
reported
placed
according
accessai
zentro
upwork
genova
gives
covered
toon
travelagent
related
removed
removal
fuzion
against
studies
interested
ionix
increasing
orbitus
miroflash
tekno
genix
appointed
brought
attached
quantumx
discussed
proposed
suggested
aireviews
prepared
controlled
alis
agentforge
agentbuilder
agate
vcloud
cfi
ecloud
multicloud
acloud
nexthome
testlab
fluxon
smartoffice

13
736

agentforge sounds slick – how do you handle tool selection at runtime?
1
1
86

one of my blogs is about to cross 100k views.
which is honestly wild because I published it expecting a few hundred people to read it.
a lot of new people have followed me since, so this feels like a good time to properly introduce myself.
hey, I’m Mohit.
I’m a computer science student from Delhi, and most of my time goes into building AI systems, breaking them, and then figuring out why they broke.
hackathons became my fastest classroom.
15 wins later, the biggest lesson wasn’t how to win hackathons. it was learning how to take a vague idea, turn it into a working product, and explain why it matters, usually under an unreasonable deadline.
that habit of shipping pulled me deeper into AI engineering and research.
over the past couple of years, I’ve worked across RAG systems, agent harnesses, enterprise AI, model optimization, MCP servers, and applied LLM research.
some things I’ve built and worked on:
→ AgentForge, a Python agent harness with tools, MCP, approvals, subagents, context management, checkpoints, persistence, and recovery.
→ MemexLLM, a deployed RAG platform with hybrid retrieval, reranking, citations, evaluation, and observability.
→ GRIT, a geometry-aware parameter-efficient fine-tuning method that updates under 1% of model parameters.
→ enterprise agentic systems at C3alabs, where I work on turning AI prototypes into systems that can actually be deployed and used.
I’ve also published three research papers and preprints, worked on production GenAI systems, and built far too many experiments that never made it past localhost.
the deeper I go into AI, the less interested I become in simply wrapping a model inside another interface.
the work I find exciting is everything required to make intelligence useful:
tools, memory, evaluations, context, permissions, observability, recovery, and reliable execution.
basically, how do we move from agents that look impressive in a demo to agents people can trust with real work?
that is the question I’m currently obsessed with.
on this account, I’ll be sharing more about:
→ building agentic systems
→ AI engineering and architecture
→ LLM research and evaluations
→ lessons from 15 hackathon wins
→ experiments, failures, and things I ship
→ honest thoughts about where AI products are going
I’m still learning, still experimenting, and still changing my mind regularly.
but I know what kind of work I want to pursue:
difficult problems, useful systems, and ideas that survive beyond the demo.
if you followed because of the blog, welcome.
and if you’re building around agents, AI infrastructure, research, or ambitious products, say hi. we’ll probably have plenty to talk about.
I’m Mohit. good to meet you :)
most of my work lives at mohitx.in !!
11
5
127
3,899

Jun 12
AgentForge is built for different types of users:
• Business users can create agents with no coding required
• Node.js developers get a production-ready deployment workflow
• Java teams can integrate agents via HTTP, DingTalk bots, or MCP—without adopting the Node.js stack
241
Jun 12
⚡️NEW: #AlibabaCloud launches AgentForge.
Describe your task, and AgentForge automatically generates an agent's persona, skills, and tools.
Debug in the browser, schedule jobs, and deploy directly to your GitLab repo.
Building a cloud-based Agent Team takes as little as 73s.
1
6
519

Another neat tidbit from an agentic RL paper (AutoForge): retaining reasoning traces throughout a multi-turn trajectory is beneficial. Agents benefit from interleaved thinking, or preserving reasoning traces from prior turns and using them as extra context for the current turn.
Reasoning models output a long reasoning trace before their final output; e.g., in the format <think> ... </think> <final output>. This is straightforward for a single-turn use case. However, if we have a multi-turn scenario (e.g., an agent), we have to determine whether we:
1. Retain prior reasoning traces.
2. Clear prior reasoning traces and only output a reasoning trace for the current turn.
The pro of retaining reasoning traces is that the agent might do some planning or analysis that is helpful at a later step. The con is that reasoning traces consume a lot of context. Solving long horizon tasks is already difficult with agents, and retaining a per-step reasoning trace can quickly exhaust the context window.
In AutoForge, authors analyze this choice, finding that retaining reasoning traces over a multi-turn trajectory has a clear performance benefit. They refer to this approach as "interleaved thinking", as it allows the agent to think / retain its thoughts.
Specifically, this finding is proven in a specialized agent training setting (we are training the agent rather than using an off-the-shelf LLM backbone). In AgentForge, authors create a series of synthetic simulated environments (all verifiable) for RL training of Qwen3-Thinking-30B-A3B. These models are then evaluated on benchmarks like TauBench / VitaBench.
On these experiments, we see a clear trend that enabling interleaved thinking during RL training significantly benefits agent accuracy. This trend holds across all benchmarks that were considered.
This is something I've always wondered about, but I just assumed we clear prior reasoning traces by default due to the context cost. Very cool to see this choice analyzed, especially when it yields an interesting (and possibly even counterintuitive) result!

10
4
75
4,201
JeroenVanPuntje $KLV $Nexo $TRX retweeted

Jun 8
Internally we've developed AgentForge.
A phase-gated and adversarial review framework for code that touches:
• Funds
• Keys
• Cryptography
• Consensus-critical state
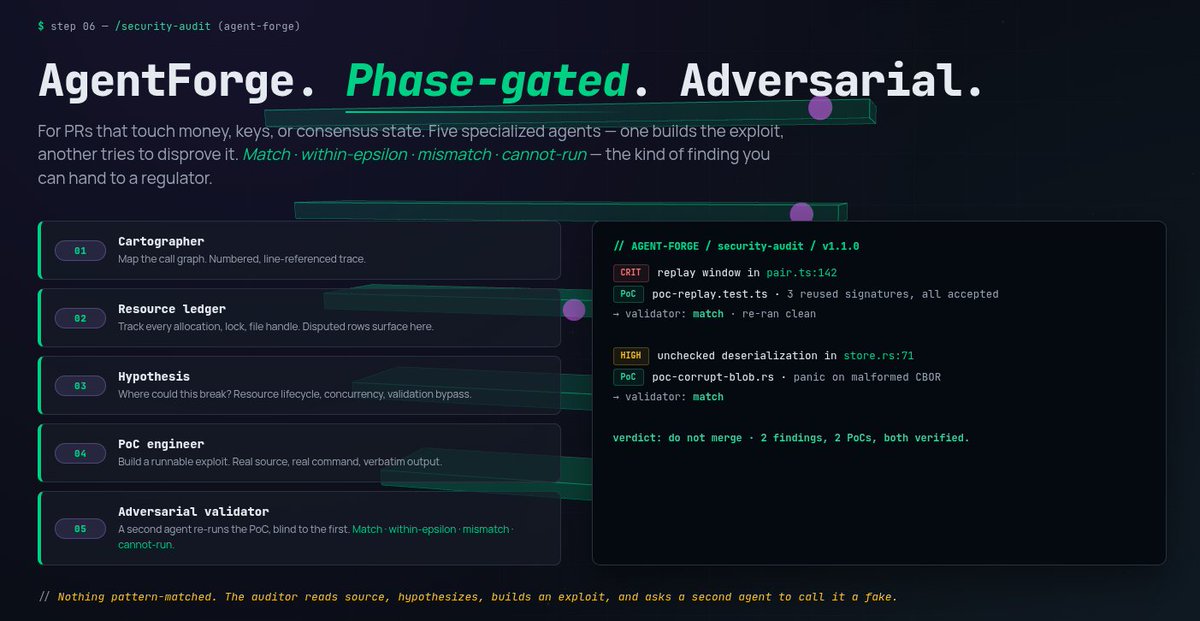
1
9
23
322
I wrote about the same idea from building AgentForge here:

3
214

Jun 9
搭 LLM agent 的现有工具要么太重(LangChain),要么得从零写 API 胶水。AgentForge用 YAML 配置 可组合技能模块把逻辑和实现拆开,开发时间省 62%,编排开销 <100ms。适合想快速验证想法、不愿被框架绑死的人。
arxiv.org/abs/2601.13383v1
19
Agents don’t fail only because the model is weak.
They fail because the loop has no memory, no trace, no recovery path, and no way to measure if it actually improved.
This article was about building the harness 🛠️
Next up: AgentForge Evals Bench 📊
Time to benchmark the loop.
2
4
30
4,247

━━━━━━━━━━━━━━━
🏆 注目記事 TOP 5
━━━━━━━━━━━━━━━
① 👁️66.2万 ❤️651 🔖2157
「Harness Engineering: What Every AI Engineer Needs to Know in 2026」
by @sairahul1
2026年2月、OpenAIの少人数チームが100万行の本番コードを一行も手書きせずにAIエージェントで仕上げた事例を起点に、エージェントを支える「ハーネス(モデル以外のすべて=制約・フィードバックループ・ドキュメント・ツール権限)」を設計する新分野「Harness Engineering」を解説しています。Anthropicが3本の論文を出し、ThoughtWorksがフレームワークを形式化するなど、90日で新しい工学分野が立ち上がったと述べています。
x.com/sairahul1/status/20635…
━━━━━━━━━━━━━━━
② 👁️13.8万 ❤️503 🔖846
「AI要件定義の現在地。今こそ、要件定義の概念を変える時だ。」
by @qumaiu
AI駆動開発が浸透し、開発現場のボトルネックが明確に「上流」へ移ってきたとして、要件定義にフォーカスした記事です。多くの人がAIで壁打ちして要件を提示するようになった一方、自分の考えを整理しないままAIに思考を丸投げする「思考の先送り」が起きていると指摘しています。なぜこの要件なのか、ビジネスとしての優先順位は何かという判断が曖昧なまま進めば、下流で破綻すると論じています。
x.com/qumaiu/status/20634175…
━━━━━━━━━━━━━━━
③ 👁️7.8万 ❤️678 🔖968
「Do AGENTS.md Files Actually Help Coding Agents?」
by @rasbt
AGENTS.md や CLAUDE.md のようなリポジトリレベルのコンテキストファイルが、コーディングエージェントの役に立つのかを検証した論文の紹介です。SWE-bench Lite と、開発者が書いたコンテキストファイルを持つ12リポジトリ・138タスクの新ベンチマーク AGENTBENCH で評価しています。結果として、コンテキストファイルなしと比べ、LLMが生成したコンテキストファイルはタスク成功率を平均でわずかに下げるか、大きな差を生まなかったと報告しています。
x.com/rasbt/status/206364913…
━━━━━━━━━━━━━━━
④ 👁️5.7万 ❤️588 🔖1462
「I Built an Agentic Harness From Scratch. That Taught Me What Agents Actually Are」
by @ByteMohit
フレームワークに頼らず、ストリーミングのエージェントループ、型付きツール呼び出し、承認ゲート、プロンプトインジェクション境界、コンテキスト圧縮、MCP統合、サブエージェント、永続化、テスト一式まで、Pythonでエージェントのハーネスをゼロから自作した記録です(プロジェクト名 AgentForge、OSSで公開)。エージェントはモデルではなくランタイムであり、モデルは工学全体の2割ほどで、残り8割はそれを包む部分だと述べています。
x.com/ByteMohit/status/20634…
━━━━━━━━━━━━━━━
⑤ 👁️4.8万 ❤️533 🔖1448
「17 prompts that make Hermes run while you sleep (copy-paste inside)」
by @Mnilax
2026年2月にNous Researchが公開したオープンソースの自己ホスト型エージェント「Hermes Agent」を、$5のVPS上でClaudeをモデルとして5週間運用した筆者が、実際に貼り付けている17個のプロンプトと設定を共有する記事です。HermesはIDEの外でデーモンとして動き、セッションをまたいで記憶を保ち、自然言語のスケジュールジョブを受け取り、自分で再利用可能なスキルを書くとしています。
x.com/Mnilax/status/20636977…
━━━━━━━━━━━━━━━
💡 今日の所感
今日は「エージェント=モデル+ハーネス」という見方が、複数の記事で共通して語られていました。
①と④はいずれもモデルの外側にある仕組み(制約・フィードバック・ツール権限・承認ゲートなど)を設計することの重要性を扱い、③はその一部であるコンテキストファイルの効果を検証しています。
②はAI駆動開発で課題が上流の要件定義へ移っていること、⑤は自己ホスト型エージェントの実運用を取り上げており、キーワードランキングでもAgentが4件で突出していました。
モデルそのものより、それをどう動かす仕組みを作るかに関心が集まった一日でした。
━━━━━━━━━━━━━━━


5
486