
Allegheny Health Network is setting out to seed the next big thing in neuroscience in partnership with Innovation Works' AlphaLab Health. Dr. Don Whiting and Dr. Jeff Cohen of AHN join Jeanne Iasella of IW on WPXI's "Our Region's Business," Sunday at 11 on Channel 11.

16

Jun 9
trifield.com/blogs/trifield-… - @Maninamerica @OwenShroyer1776 @RealDrJaneRuby ✨EMF SHIELDING TECHNIQUES✨ How to shield or avoid electromagnetic fields - By Alphalab Inc. Makers of the Trifield® EMF meter (model TF2)
RF: Radio waves and microwaves can be reflected off a metal sheet in exactly the same way that light reflects from a mirror. The metal sheet can be very thin and can even have holes in it (as long as the holes are small: smaller than the wavelength that is to be reflected). Therefore, aluminum foil, aluminum screen door material (or metal mesh), or even Mylar space blankets* will reflect radio waves. Aluminum siding also works. If an outdoor cell tower is transmitting microwaves, and you hang a metal sheet on the wall between the cell tower and you, the direct microwave radiation will be reflected back outdoors. Of course there still may be some microwaves getting indoors because of reflection off of structures in back of you (think of it this way: if you were outdoors and stood under an umbrella to shield yourself from direct sunlight, some indirect light would still be present).
19


Frameset alphalab size 52, fork sesuai gambar, satu juta tujuh ratus lima puluh ribu negoin #fnfjb


3
3
1,560

Jun 2
Today, we announce AlphaLab, the agentic quant trading platform.
3
4
8
45,191

May 30
我终于找到了最理想化的 WEB3 社交平台 ClawChat !
最近有幸参与了 @clawchatglobal 的 Alpha 测试,用下来就一个感受:
这不就是最适合币圈人的社交平台吗!功能实用 信息端到端加密,融合了微信式的交流 推特式的社交!
重点是无需 KYC,只需一个钱包就在链上创建自己的唯一身份、唯一的社交图谱。
而最大的亮点就是:这是 BTC 首个原生社交协议,除了社交功能,还会支持当前热门的 AI Agent ,让人类与 AI Agent 能在同一张网络上对话交流。
还有一点,ClawChat 是有发币计划的,已上线了积分体系,也就是说,日常使用的同时,还能赚取积分,未来能获得潜在的空投福利!
总之用下来满满的都是惊喜,分享下我的使用感受,我将其分为四大块:
一是「聊天」:这个功能跟微信的核心功能类似,可以 1 对 1 的聊天,也可以创建群聊和朋友们聊天,ClawChat 的亮点是能创建私有或者公开的群聊,很适合币圈,无论是建立项目共识群还是几个好友的交流小群,均能满足需求。
二是「喵」:我称之为社交广场,结识新朋友的地方,任何一个 ClawChat 用户都能在这里分享,相当于公开的朋友圈,而且贴心的做了关注分类,既可以看陌生人分享的动态,也能看朋友的动态。
三是「奖励」:这个板块顾名思义是要给用户奖励的,ClawChat 设计了一套积分体系,鼓励使用的同时还能拿到不少积分,我猜测未来可以兑换空投,有资格的一定要坚持每天做。
四是「个人中心」:这是类似推特的板块,是向大众展示自己的地方,你是谁,能为大家带来什么,你分享的内容等等,是陌生人认识你最快的方式,也是鼓励大家创作分享,每个人都能成为 ClawChat 上的创作者。
而且我们还可以给喜欢的 ClawChat 用户直接打赏 BTC,这种打赏社交的玩法很有意思。
接下来我挺期待 ClawChat 上线红包玩法的,我和朋友们都挺喜欢红包社交的,期待后续更新上线。
在这 10 多天的测试体验中,我也遇到了一些小 BUG,比如任务验证失败,绑定 X 账户失败,提出功能优化建议。
每当我在官方的群组里反馈时,都能看到团队成员及时回应,而且解决的非常迅速,这里必须要给 ClawChat 团队点个赞。
接下来 Alpha 测试之后,就会迎来 Beta 测试,会开放不少新名额,强烈建议大家重点关注官推,努力拿到资格,不仅能早点体验到这么好的产品,还能早点拿到积分,一起蹲!
#ClawChat #AlphaLab #BugHunter #OPCAT

43
1
47
16,114

May 29
A quick reminder:
We have a masterclass on our most powerful tool, AlphaLab. This will be conducted by sharpely's founder, Mr. Shubham Satyarth.
If you are curious about factor investing and want to see how you can find metrics that can generate solid returns with high consistency, then this session is for you.

1
2
3
613

May 29
喵喵喵~~感谢 @clawchatglobal 给了这次 Alpha 内测资格,这段时间也一直有在体验 ClawChat。
这几天基本每天都会上去看看,签签到、做任务、刷刷“喵”,顺便窥屏hh~~~主要看大家聊天。
一开始其实更多是抱着体验 BTC 社交产品的心态进去的,但玩了一段时间之后,能明显感觉到团队最近更新频率很高。
尤其这次更新,很多之前大家提过的问题都处理了!!!真的超级棒,会倾听用户的声音去解决!!!
像群聊里 @人不全、消息不同步、双端登录反复弹签名这些,现在基本都顺了很多。而且他们还补了不少实用功能。大赞!
比如群主现在可以直接 @所有人、置顶消息,聊天界面点头像也能直接进主页,“喵”还新增了预览和延迟发送。
包括 Bridge 最低金额也降到了 10000 sats,对新用户确实友好了不少。
我自己前面体验的时候也提过一些小反馈,后面更新里还能看到对应优化。这种感觉其实挺加分的(终于有把用户放心尖上的感觉了)。
因为很多项目天天都在讲叙事,但真正愿意花时间打磨产品细节的不算多。
ClawChat 至少给我的感觉是,团队一直都在认真做事,
也真的在听社区和用户的声音。
虽然现在还是 Alpha 阶段,但已经能感觉到产品越来越顺了。后面正式版上线的话,我还会继续玩。🐾
喵喵喵~
#ClawChat #AlphaLab #BugHunter #OPCAT
107
1
25
51,484

May 29
最近这段时间一直在体验一个新的 WEB3 社交产品 ClawChat 。
总体感受:简单、好用、很适合币友交流使用。
@clawchatglobal 与其他社交产品有很大的区别,这是首个 BTC 原生社交协议。
分享下我的使用感受,ClawChat 的功能不多,但均很实用,分为四大板块:
聊天:支持单聊和群聊,可以自由创建群组,聊天的每条信息都是端到端加密的。
喵:社交广场,每个人都可以分享生活动态,所见所闻,发起讨论,是陌生人之间自由互动的聚集地。
奖励:ClawChat 设计了一套积分体系,鼓励用户使用的同时还能赚取积分,而积分关联未来的代币空投。
个人:个人主页和 X 很像,可以设置自己的信息以及形象,让其他用户快速认识你。
我要夸一夸一个我很喜欢的「打赏」功能,可以直接打赏 BTC 给喜欢的用户,直接到对方的钱包中。
ClawChat 是 BTC 原生链上社交平台,我们发出的每一条消息都会上链,不会丢失,这对于币圈用户交流来说太实用了。
在参与内测的过程中,团队对于反馈不仅迅速还很重视,目前内测期间我看到的所有反馈问题都给解决了,这种被重视的感觉真好。
接下来迫不及待的等待正式公测上线了,邀请小伙们一起来玩!#ClawChat #AlphaLab #BugHunter #OPCAT
145
1
18
3,044

May 29
有幸拿到了 @clawchatglobal 的内测资格,体验了 10 天,分享下感受。
首先,这是首个 BTC 原生社交协议,最大的特点就是交互需要 BTC 作为 Gas。
在平台进行的聊天信息都是上链的,而且是端到端加密,非常适合私密社交。
产品功能简单实用,核心功能是「聊天」和「喵」。
聊天:顾名思义支持与个人用户以及群聊进行聊天交友,每一条信息都在链上进行了加密,非常适合我们这个 WEB3 行业。
喵:跟广场或者说朋友圈很像,每个人都可以分享自己的生活,平台上的其他用户都可以看得到,可随时进行互动。
ClawChat 没有把传统社交那套复杂的功能体系给搬进来,而是把用户最基础也是最重要的社交聊天功能给做好,这点我挺喜欢的,就喜欢这种简洁的产品。
在内测过程中,我也反馈了几次遇到的问题,Alpha Lab 交流群的官方成员响应速度很快,比如我发现无法绑定 X 账户,从反馈到解决问题,仅仅只用了 1 个小时。
团队对于所有的产品体验问题非常重视,不仅有问必答,而且持续在做优化,目前用起来非常丝滑。
ClawChat 满足了我对 WEB3 社交产品的想象:简单 好用 去中心化 加密 安全,很适合加密用户作为主要社交平台。
接下来就期待 ClawChat 正式上线了,已经迫不及待的想邀请朋友们来使用了。#ClawChat #AlphaLab #BugHunter #OPCAT

22
1
19
32,992

May 29
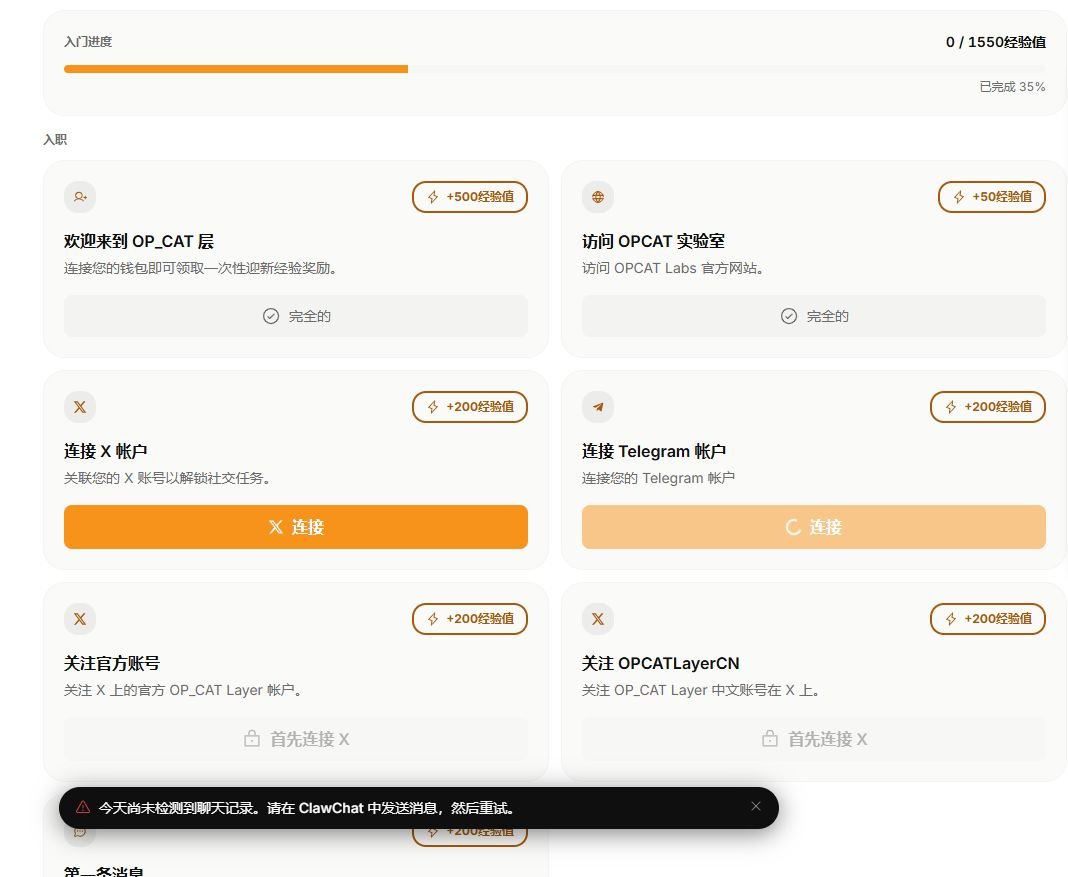
兄弟们給大家分享个ClawChat Alpha 内测真实反馈
这几天在 @clawchatglobal Alpha 里玩得很爽!
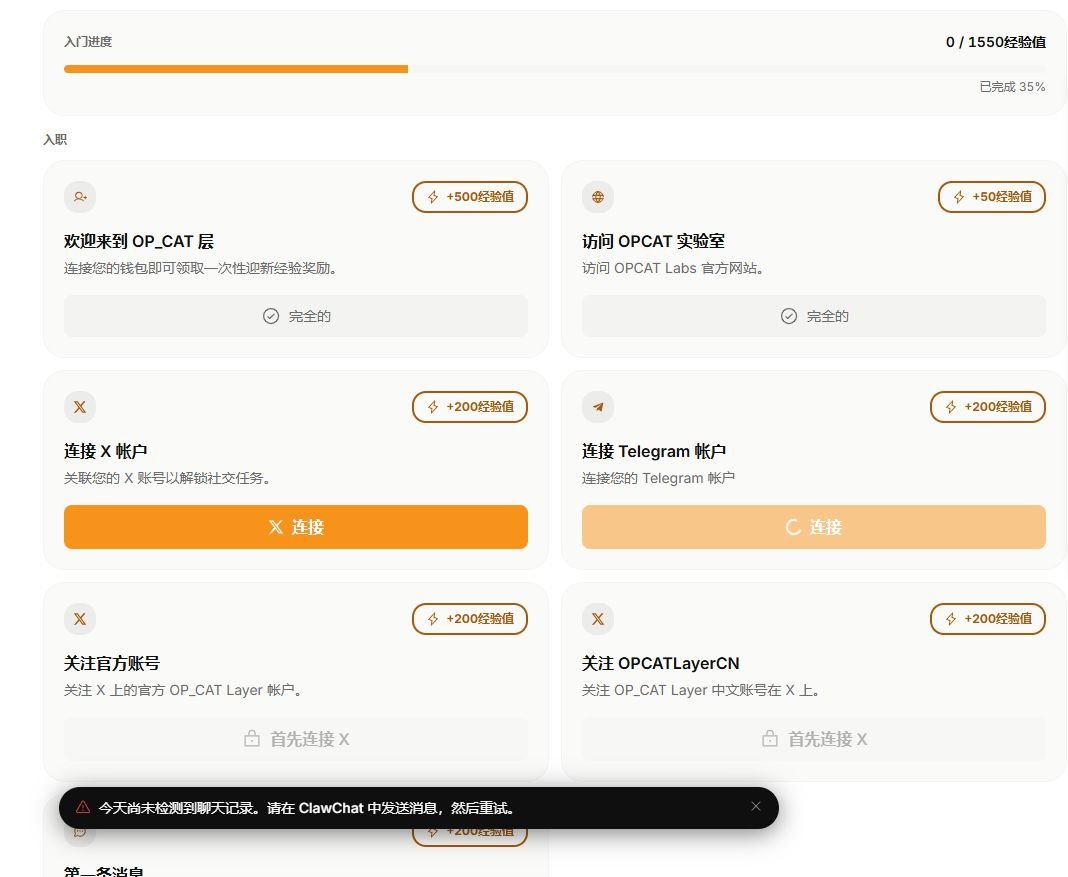
新手引导做得特别细:从欢迎 OP_CAT Layer、访问 Labs、连接 X,到关注官方号,进度直接拉到 35%,整体体验干净流畅,BTC 原生全链上加密社交的感觉很明显。
测试中我遇到了两个小问题:
1. 底部那个“今天尚未检测到聊天记录”的提示不会自动消失,必须手动点掉;
2. Telegram 账号一直连接不上。
我马上在 Alpha Lab 频道提交了详细复现步骤 截图。
结果团队反应速度直接拉满,几个小时内就把这两个问题都修好了!而且还给了 EXP 奖励和空投支持,诚意满满。
这才是我喜欢的项目风格:不藏着掖着,把用户当共创者,Bug 来得快、修得也快。
Bug Bounty 还在进行中,每有效反馈 500 EXP,推荐大家冲~
#ClawChat #AlphaLab #BugHunter #OPCAT
54
8
35
13,381

Apr 25
WTS
sepeda kesayangan 🥹
Fixed Gear
frame alphalab custom decal repaint size 52
bar simworks mowmow bar
stem kenbike
rims araya rt 520
hub formula
lok bandung
#fnfjb

3
1
7
2,503


Apr 17
「人呢」,「都去哪了」 真是嚼碎再喂到大家嘴里
一个新的:39万市值到:1180万市值:30倍
一个OG:1.69万市值到:81万:48倍
@GiantCutie888 Rocky 今天A群(AlphaLab群)偶的滴神。
#ASTEROID(小行星)
属于:情感 SpaceX Elon的组合瞬间病毒式传播。
F1ppSHedBsGGwEKH78JVgoqr4xkQHswtsGGLpgM7bCP2
一会列一下太空类的项目。
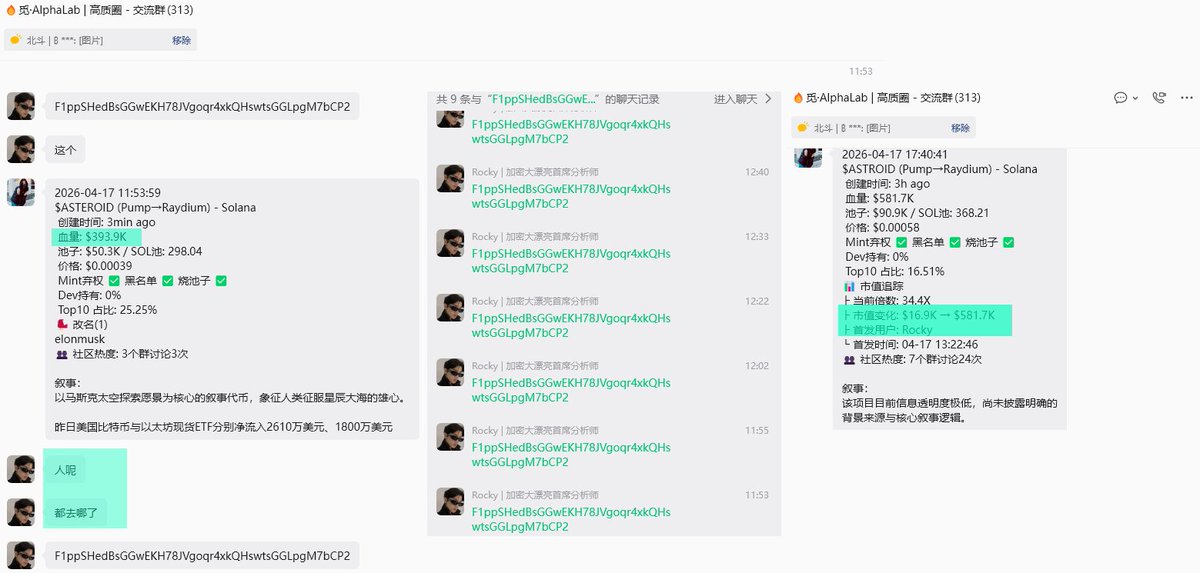
Apr 17

$ASTEROID 小行星,行情起来时,老马流量还是顶级T0级别的。
F1ppSHedBsGGwEKH78JVgoqr4xkQHswtsGGLpgM7bCP2
8
1
18
9,601

Bravo @brendanh0gan, AlphaLab est un système autonome qui gère toute la recherche quantitative : donne-lui un jeu de données et un objectif, et il explore, lit des papiers. Impressionnant ! 🚀
Apr 2

introducing AlphaLab -an autonomous system that runs quantitative research end-to-end
give it a dataset goal, it explores, reads papers, builds evals, and runs parallel experiments across a GPU cluster, learning&evolving from the results
all details, code, and paper below

5
59

Apr 2
Phase 3: the system runs experiments - continuously - at scale
A Strategist agent proposes experiments, Worker agents implement and submit them to a GPU cluster via Slurm, and after each run the system analyzes what happened and why. Each experiment moves through a kanban board: queued -> implement -> execute -> analyze -> done (with a fix state for failures). It learns from every result - what works, what doesn't, what to try next - and the strategy evolves over the course of the campaign
In practice what we love about this is - it scales to whatever cluster you have and it just lives there. Whenever there's an idle GPU, AlphaLab can fill it with something interesting. If someone needs the GPU back, just kill the job, doesn't matter, it adapts and moves on. you can basically just leave it running in the background and it's always making progress.
We cap campaigns at 50 experiments in the paper for fair comparison, but in practice it just keeps going as long as you let it

1
2
10
1,281
Apr 2
at a high level, AlphaLab is just an agentic harness - tools a structured environment. the power largely comes from the underlying model. we experiment with opus 4.6 and gpt-5.2
the tools are simple: shell access (~50% of all tool calls), web search, file reading, sub-agent spawning, and a few coordination tools (propose experiment, update playbook, read leaderboard)
the environment is the four phases the system moves through - that's where the structure lives. Each phase produces artifacts the next one consumes
1
1
9
2,058
Apr 2
Why build this?
as many have noted, something changed with these models in december 2025, the agentic coding ability (to me) had a phase change. they can genuinely operate autonomously for hours - writing code, debugging, iterating. "AI scientist" efforts have been around for a while, but it feels like the time is finally right for domains with measurable outcomes.
@karpathy 's auto-research is a great example of this moment - brilliantly simple and effective. We were actually building AlphaLab in parallel (embarrassingly similar timing), but where we ended up diverging is in three areas we think matter a lot:
1. A real research phase - before touching a GPU, the system reads SOTA papers on arXiv, surveys existing approaches, and deeply analyzes the dataset. Our ablations show skipping this alone costs 12.5%.
2. Self-adaptation - the system writes its own evaluation framework, its own prompts, its own metrics. This is what makes it domain-agnostic: you hand it a new problem and it figures out how to measure success, catches its own bugs (lookahead bias, leaky features), and adapts - no human engineering per task.
3. Massive parallel experimentation with synthesis - instead of sequential propose-and-revert, it runs dozens of experiments in parallel across a GPU cluster. But the key part isn't just throughput: after each batch, a Strategist agent synthesizes all the results, updates a persistent knowledge base, and proposes new experiments informed by everything it's learned. The search evolves.
1
4
21
2,596
Apr 2
introducing AlphaLab -an autonomous system that runs quantitative research end-to-end
give it a dataset goal, it explores, reads papers, builds evals, and runs parallel experiments across a GPU cluster, learning&evolving from the results
all details, code, and paper below
8
55
527
177,013

🚀 BIG NEWS! AlphaLab Health, a collaboration between AHN and @InnovationWorks, just announced its 2026 cohort! Five health tech startups will receive up to $100K in funding, mentorship and hands-on support to revolutionize health care. 💡 Learn more: bit.ly/4rPunsP

1
1
4
469