
Joined March 2024
- Tweets 54,604
- Following 3,233
- Followers 27,160
- Likes 43,371
875 Photos and videos















9h
⚽️世界杯惊喜!收到了 @XBITDEX_ZH 送的世界杯限定礼盒!
足球 LABUBU,我想要的都有!
大家想要的可以去官推参与下抽奖活动,正在抽 10 份世界杯礼盒。
而且 @XBITDEX 世界杯活动也在进行中,狂撒110万USDC,大家别错过!
目前XBIT中文群正在送大量预测券,每天500张!免费参与!
t.me/xbit_chinese

Jun 9

⚡️ XBIT 世界杯福利来了!
🎁 抽 10 人送足球 LABUBU 限定礼盒!
参与方式:
1️⃣ 关注 @XBITDEX @XBITDEX_ZH 点赞
2️⃣ 引用本推文(聊聊你的世界杯预测)
3️⃣ 评论区 @ 一位球友 写下你预测的冠军 🏆
📅 开奖时间:6/18 18:00 (UTC 8)
⚽️ 来 XBIT 用交易证明你的预测!


6
9
714
Jun 13
这次世界杯规模盛大,有什么一定要去撸的吗?
还真有,建议参与下 @Predictstreet 的世界杯活动,门槛低,福利多。
重点是这平台是 FIFA 世界杯的官方合作伙伴!背景没得说。
玩法也简单,加入平台领取自己的 Predictstreet Card ,每天做任务玩预测就能获得积分进行升级。
这些积分预期将具有实际价值,积分越多排名越多,进入排行榜前列应该会有不小的惊喜。
👇参与教程:
第一步:访问活动页面
sprint.adipredictstreet.com?…
第二步:连接自己的 X 账号 。
第三步:选择你支持的世界杯球队,领取你的 Card 。
第四步:进入仪表盘 ,连续打卡、开启卡包、获得积分、竞争排行榜。
注意:一定要每天开启礼物包,因为能够获得积分和倍率加成,同时完成预测任务,可获取奖励包和额外积分。
边预测赛事边赚取积分的玩法简单有趣,我计划在世界杯期间用 ADI Predictstreet 进行预测交易,看看有没有大福报 。
21
29
5,025
Jun 11
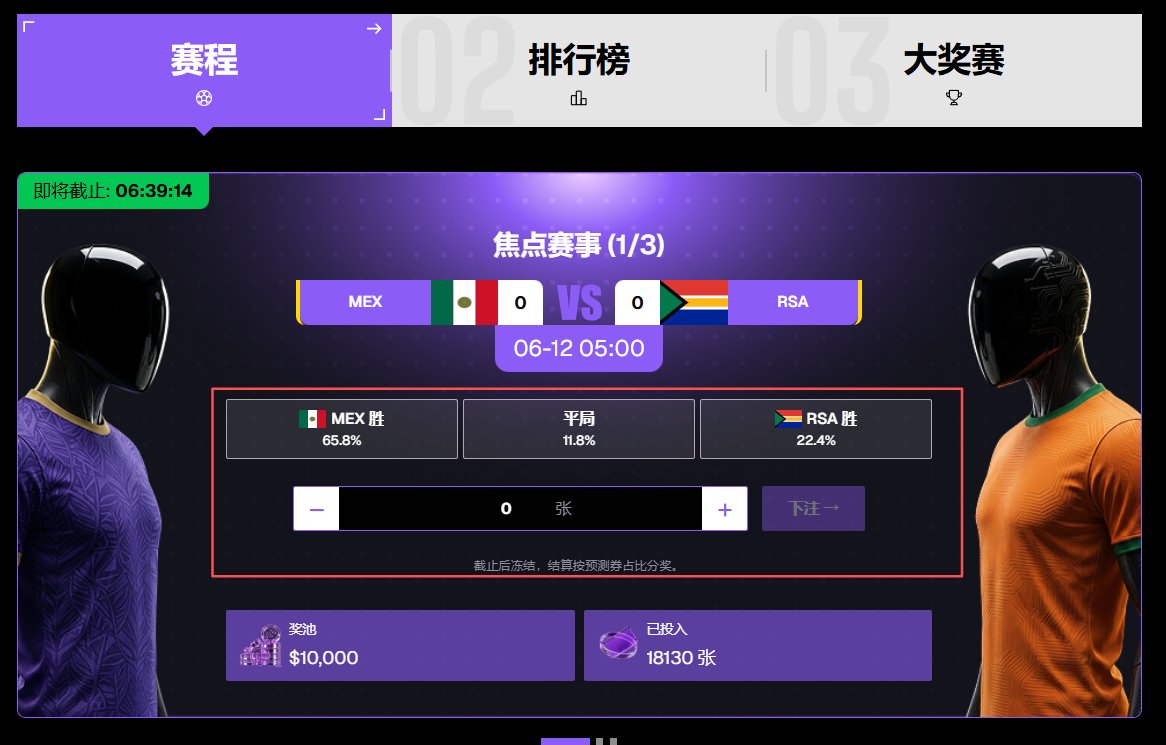
世界杯开赛,XBIT 送出 110万USDC奖池!教你如何边看球边赚真U。
2026 FIFA世界杯已经打响,各大预测平台都在做活动,我建议首选XBIT。
因为奖励明确:奖池高达110万USDC!
玩法简单:交易得预测券,用券参与投注每天瓜分USDC奖池!
活动时间:6月11日 – 7月19日(全程40天)
核心道具:预测券
预测券是参与活动的唯一凭证,在 XBIT 进行预测市场交易或合约交易,就能获得预测券,交易越多,券越多。
每日焦点赛:猜对就分钱
每天一场焦点比赛(小组赛猜胜/平/负,淘汰赛猜晋级队伍)。
你拿预测券押注你认为的结果,比赛结束后,所有猜对的用户,按券数量比例瓜分当日奖池。
举个例子:
奖池 10,000 USDC,你押了A队赢,共有 2,000 张券也押A队,你手里有 100 张 → 你能分到 100÷2000×10000 = 500 USDC。
最关键的是:猜对的人越少,单张券价值越高,押中冷门的收益可能远超预期。
📊 双排行榜:额外 100,000 USDC奖池
除了每日焦点赛,活动期间还有合约交易排行榜和预测市场排行榜,各 50,000 USDC 奖池,前100名用户都能分到奖励。
这意味着:你交易的每一笔,既在帮你赚预测券,也在为你冲击排行榜。
活动期间一共举行4期,每期都有4个榜单,每个榜单第1名直接拿1000U奖励。
✅ 三步参与
注册 XBIT app.xbit.com/ref=GRAY6
进行预测市场或合约交易 → 领取预测券
每日登录焦点赛页面,投入预测券押注你判断的结果
预测市场与合约交易存在风险,杠杆会放大亏损,请理性参与,控制仓位,DYOR。
@XBITDEX_ZH @XBITDEX
9
19
1,934
Jun 9
AI 交易分析记得装这个!Github 已获 84.6 k stars !
让硅谷基金经理工作不保的强大 AI 黑科技,金融 AI 领域的热门项目。
名字叫做 tradingagent ,这是一款多智能体量化交易系统。
它不是一个简单的交易机器人,而是把一家真实交易公司的工作流,拆成了一组 AI Agent。
它里面有基本面分析师、情绪分析师、新闻分析师、技术分析师;还有看多研究员、看空研究员、交易员、风控团队和投资组合经理。
也就是说,它不是直接拍脑袋给你一个「买入/卖出」,而是模拟了一场完整的投研会议。
它的几个亮点很明显:
1. 多智能体协作,不是单点判断
传统 AI 分析很容易「一句话定生死」。TradingAgents 把任务拆给不同角色:有人看财报,有人看新闻,有人看市场情绪,有人看技术指标,最后再汇总成交易观点。
2. 有「多空辩论」机制
它不是只找利好,也会安排看多和看空研究员互相质疑。这个设计很关键,因为金融市场最怕单边叙事,真正有价值的分析往往来自反方观点。
3. 自带风控和组合经理角色
交易不只是判断方向,还要考虑波动、流动性、风险敞口。TradingAgents 里有风险管理团队和 Portfolio Manager,负责评估交易建议是否应该被批准。
4. 支持多种数据维度
它可以结合基本面、新闻、社交情绪、技术指标等信息,不只是看 K 线,也不是只读新闻,而是更接近完整投研流程。
5. 支持多个大模型和本地模型
官方支持 OpenAI、Google、Anthropic、DeepSeek、Qwen、GLM、MiniMax、OpenRouter、Ollama 等模型,既能接云端大模型,也能用本地模型做实验。
6. 适合研究和复盘,而不是无脑跟单
它还支持决策日志和历史反思:每次分析完成后,会把决策记录下来,后续可以结合实际收益做复盘。这一点对策略研究很有价值。
TradingAgents 最强的地方,不是告诉你哪只股票一定涨,而是把「投研决策过程」AI 化了。
它让普通人也能看到,一家交易团队是如何从信息收集、观点碰撞、风险评估,到最终形成交易建议的。
感兴趣的可以体验下:
github.com/tauricresearch/tr…
7
7
1,204
小灰韭 retweeted

Jun 8
🎙️ #BTC 生态交流 AMA🎙️
📢本周主题:《从世界杯到SpaceX:全球注意力正在流向哪里?BTC又站在什么位置?》
⏰时间:2026年6月9日 20:00
🏆联合主办方 : @D7_LuckySeven @Kings_Gorge
💎主持人 : @CryptoGouba
🔥特邀嘉宾 :
@cryptocici1
@DJxiaoxiong8
@web3gray6
@shiyuan606
@Oxskybb
🔶 讨论话题
🧩 话题一|世界杯、SpaceX频繁刷屏:为什么全球热点越来越集中?
🧩 话题二|BTC正在争夺什么:资金,还是全球共识?
🧩 话题三|OMEGA视角:为什么真正的共识,往往形成于最安静的时候?
🧩 话题四|当所有人都在追热点,社区应该追什么?
👉 Space传送门:x.com/i/spaces/1AKEmmqNRAkKL…
16
6
16
8,852
Jun 8
BTC生态很多人可能觉得不好玩,但比特币上第一个真正原生全链上社交协议 @clawchatglobal 一定不能错过!
刚看到他们已经开始Beta 阶段正式开放,拿到访问码的可以去体验了
为什们会推荐大家关注ClawChat?
因为对我们 普通用户来说极其实用:
1.真正的隐私保护:端到端加密 比特币密钥体系,每一条私信、每一次互动,只有用户和对方能看到;
2.完全去中心化:任何人无法删除账号、屏蔽内容,所有数据永久记录在比特币链上;
3.Agent-Ready 设计:未来可以让可信 AI 代理帮管理通知、筛选内容、甚至代表用户进行安全互动,这在传统社交平台上几乎无法想象;
4.早期社区红利:现在Beta 阶段有200 名首批邀请用户,项目方已透漏 EXP 计划即将启动,早期参与者将有机会获得链上激励和社区治理权益。
很明显ClawChat 是比特币在社交领域的自然延伸。对于 Web2 平台种种限制的比特币持有者来说,ClawChat 真正做到了去中心化
作为 @op_catlayer @OPCATLayerCNa 首个社交生态项目,必定获得很多支持;而且是最早做比特币社交协议的方向的,有很大的竞争优势,我很看好,尤其目前还在早期,拿到结果也会大很多。

🐾 Alpha is behind us—ClawChat Beta is LIVE!
The world’s first BTC-native, fully on-chain, E2E encrypted, agent-ready social protocol is making waves:
🔥 8,000 early access requests
💌 200 early adopters already invited
Get ready for the EXP program—autonomous social on Bitcoin is just getting started.
The future of social is on-chain. 🟧🤖
Start your journey 👉 clawchats.app

61
41
7,949
Jun 7
Codex 新手小白必装的 6 个 Skills 技能合集!好用到不舍得分享!
每一个都能解决具体的问题,覆盖工作常见的各类场景。
Skill 不是越多越好,好用才是最重要的!
分享下我珍藏的 6 个 Skills :
1. Using-Superpowers
解决新手「不知道该什么时候用哪个 Skill」的问题。它相当于 Skill 调度器,能提醒 Codex 根据任务选择合适技能,避免一上来就盲目执行。
2. Brainstorming
解决「想法模糊、需求没理清」的问题。适合在写代码、做产品、规划项目之前,先帮你梳理思路、补全需求、形成清晰方案。
3. obsidian-skills
解决「笔记和知识库不会整理」的问题。它让 Codex 更适合处理 Obsidian 里的 Markdown 笔记、知识库内容、项目资料和学习记录。
4. skill-creator
解决「不会创建自己的专属 Skill」的问题。适合把常用提示词、固定流程、重复工作沉淀成可复用技能,让 Codex 更贴合自己的工作方式。
5. Playwright
解决「网页项目改完不会真实测试」的问题。它可以让 Codex 打开浏览器、点击页面、填写表单、截图检查,适合前端开发和网页测试。
6. Markitdown
解决「各种文件不好给 AI 读取」的问题。它能把 PDF、Word、PPT、Excel、网页等内容转成 Markdown,方便 Codex 总结、分析和提取重点。
这 6 个 Skill 分别覆盖了:技能调度、需求梳理、知识管理、自定义技能、网页测试、文档转换。对新手来说,能明显降低上手门槛,让你使用 Codex 的效率加倍!
25
17
81
4,885
小灰韭 retweeted

Calling all AI & Web3 builders in the Greater Bay Area! 📢🚀
Join our exclusive meetup diving into the intersection of AI-native social infra and decentralized communication.
What we’re exploring:
🤖 One Person Company (OPC) & Autonomous Agents
⚡️ Agent-to-Agent Onchain Comms
🟠 BTC-Native Innovation (OP_CAT)
🌐 Web3 Social Infrastructure
Come for the alpha, stay for the high-signal networking with top founders and researchers. 🍻
📅 Fri, June 19th | 5:00 - 8:00 PM
📍 Nanshan, Shenzhen
🎟️ Secure your spot: luma.com/cc262

57
18
66
6,483
Jun 4
#AI 如何让 Codex 像人一样操作电脑?三步教你搞定!
自动化替你干活,比如让它帮你分析数据,帮你做 PPT 等等。
第一步:更新 Codex 到最新版本
第二步:安装电脑操控插件
打开 Settings,找到 Computer Use–点击安装插件
装上后 Codex 就具备操作电脑的能力
第三步:输 @ computer 命令 ,告诉它要做什么任务,比如打开电商后台分析数据。
之后 Codex 就会自动操作浏览器处理工作,你只需要关注最终的执行结果就可以了。
尤其是日常一些琐碎事项,实现自动化后,只需要说清楚具体要做什么,Codex 就会帮你自动执行。
注意:如果无法安装插件,不能使用,可以直接问你的 Codex,让他帮你找出问题主动解决。
自从实现自动化以后,现在很多事情都解放双手了,每天节省了大量的时间与精力。 #Codex
9
7
1,298

XBIT Prediction Lever Whitelist Prediction Ticket Referral Giveaway!
Want to start stacking Prediction Tickets early and compete for a share of the World Cup $1,000,000 USDC Prize Pool?
Join the official XBIT Telegram community today, claim your whitelist spot, and win rewards!
🎁 Community Referral Rewards
🥇 1st Place: 35 USDC
🥈 2nd Place: 20 USDC
🥉 3rd Place: 12 USDC
🏅 4th–10th Place: 5 USDC each (35 USDC total)
🎟 11th–20th Place: Prediction Lever Whitelist
📌 How to Participate
1️⃣ Join the Telegram community
2️⃣ Get your exclusive referral link
3️⃣ Invite friends to join (valid users only)
4️⃣ The more valid referrals you bring, the higher you rank!
🔥 X Giveaway (Extra Bonus)
✅ Follow @XBITDEX and @XBITDEX_ZH
✅ Like & repost this post
✅ Comment which 🏆 country you think will win the World Cup
Complete all requirements to enter the lucky draw!
🎁 10 Lucky Winners
💰 10 USDC each
📅 Campaign Ends: June 5, 20:00 (UTC 8)
Winners will be announced based on:
• Referral leaderboard rankings
• X giveaway draw results
⚽ Join now, collect Prediction Tickets, and take your shot at the World Cup $1,000,000 USDC Prize Pool!
👉 Telegram: t.me/xbitpolymarket

101
90
155
4,669
Jun 3
XBIT 一鱼三吃活动别错过,预测市场福利拉满了。
白名单 活动激励 潜在空投,每个都很香。
第一鱼:进官方群拿预测杠杆功能白名单
官方群:t.me/Polymarket1
第二鱼:完成预测市场交易,拿预测券
在2026世界杯期间,平台会开很多比赛预测奖池(总奖池超100万 USDC)。
你可以拿着预测券去参与比赛预测,猜对了就能直接分钱!
预测券通过交易获得,交易量越大,预测券越多,比如交易量达到5000U就能获得100张预测券。
第三鱼:潜在空投
XBIT 是有发币计划的,通过在平台交易活跃能够获得积分,积分关联潜在的空投。
一句话总结:
上白名单 → 做交易 → 赚预测券 → 后面拿来换钱
还没参与的尽快了,世界杯是全球盛事,百万U奖池挺难得,会有不小的惊喜。 @XBITDEX_ZH
37
29
4,394

Jun 2
ClawChat 又更新了,迫不及待的去体验了新功能!
自定义个人资料横幅:我已经改成和我 X 一样的横幅了,喵主页跟 X 主页很像,一眼就能快速了解你是谁,很喜欢这个设计。
管理员超级 @:群组所有者和创建者现在可以一键 @ 所有人。这个对于群管理真实用,不怕群成员错过重要信息了!
快速头像操作:轻点头像查看详情,长按即可在聊天中即时 @ 他们,在群聊中艾特指定人员真方便。
「喵」预览与调度:完善你的完全链上内容,预览并调度你的喵语,以便每次都完美无瑕。
消息置顶 (PIN):管理员现在可以在群组/频道中置顶关键消息,让公告始终置顶醒目,这也是群管理必备的实用功能!
这几个功能我都体验了,不得不夸一下 ClawChat 团队,对于测试用户的每个反馈都积极响应,新功能上线的也很快,用户体验越来越好了。
接下来期待新功能,同时也提醒大家,Alpha 测试结束之后就是 Beta 测试,目前官方正在举行六一儿童节白名单抽奖活动,大家记得去参与下哦,拿到白名单就是惊喜。
只有拿到白名单才能提前体验 ClawChat ,提前拿到内测的积分,好处多多,千问别错过。
同时我也建议大家多关注 @bruceonbitcoin @opdafu @D7_LuckySeven 能第一时间掌握 Op_CAT Layer 和 ClawChat 的最新动态。
#opcatlayer #opcat #ClawChat
30
1
45
2,613
Jun 1
你的 Codex 是不是额度消耗很快?安装这个技能,直接节省 80%的 Token 消耗!
这个精品 Skill 一定要安装,既省钱又好用!
技能名称:AnySearch skill
这是一种「先搜索、再精读」的 Codex 技能,它的核心作用不是让模型更聪明,而是减少模型需要读进上下文的内容量。
它能解决的问题场景:
- 在大项目里快速定位相关文件、函数、配置、报错来源
- 避免把大量无关文件塞进 Codex 上下文
- 先用本地搜索工具筛出候选,再只读取最相关的几段代码
- 对文档、日志、代码仓库做关键词/语义检索
- 帮 Codex 更快找到「该改哪里」
为什么说它能节省大量 Token?
因为 Codex 的消耗主要来自两部分:
输入 Token:你发给模型的上下文,包括代码、文件内容、历史对话、工具结果。
输出 Token:模型的回答、分析、补丁等。
如果没有搜索技能,Codex 可能会:
- 读取整个大文件
- 打开很多不相关文件
- 在上下文里保留大量无用代码
- 多轮试错定位问题
这会快速增加输入 Token,会导致额度极具消耗。
A
nySearch 的技能会先做「索引/搜索/过滤」,举个例子:
用户:修复登录失败的问题
普通方式:读 routes、controllers、services、middleware、配置、测试等很多文件
搜索方式:先搜 login / auth / session / error message,只读命中的相关代码
结果就是:
少读文件 = 少输入 Token
少走弯路 = 少输出 Token
定位更快 = 更少轮对话
所以 AnySearch 能减少 Codex 额度消耗,简单来说:AnySearch 的价值在于让 Codex 先找重点,再读取重点,而不是把项目内容大面积喂给模型,这就是它节省 Token 和 Codex 额度的主要原因。
最后 AnySearch skill 的安装链接:github.com/anysearch-ai/anys…
#Codex #AI #skill
6
9
38
3,977
May 31
OP_CAT Layer 为什么值得关注?
创始人刘博士 @bruceonbitcoin 用 1 分钟就把重点告诉我们了:
因为比特币的可编程性和扩展性仍然存在很大的限制:如果你想做更复杂的智能合约,比如 DeFi、pumpfun 发行代币,或者其他复杂的智能合约,就得跑到别的链上去。
而 OP_CAT Layer 就是专门为比特币打造的!它以比特币作为原生资产,解锁比特币高级智能合约的功能,同时 保留比特币 UTXO 模型 解锁高级智能合约功能 保证安全性不变。
@OPCATLayerCN 把比特币从「被动的价值存储工具」, 升级为「可编程的下一代金融系统」。 这才是中本聪当年想要的 BTC !
这也是我想要的 BTC! 重点保持关注,等风来!
May 31

OP_CAT Layer 创始人刘博士1分钟讲清楚我们做了什么
✅ 保留比特币 UTXO 模型
✅ 解锁高级智能合约功能
✅ 同时保证安全性不变
我们把比特币从"被动的价值存储工具", 升级为"可编程的下一代金融系统"。 这才是中本聪当年想要的 BTC。 #OPCATLayer #BTCFi
9
11
2,400
May 31
小灰韭我要黑化了,我要拿回属于我的东西了。
最近明显感觉X流量下降了,原来是偷摸调整算法了。
大家可以看下这篇最新算法解析,在Grok自动翻译全量后,X算法彻底变了!
以前发中文,只跟同语言5000人竞争。
现在语言墙没了,你得跟5万不同语言账号抢同一块的注意力。
结果就是:
爆款不看账号大小,几百粉丝也能起量
每条推文都从零开始
内容质量 参与度 > 粉丝基数
当前最优打法:
短推 泛流量 持续高频发布。
正常内容和“发疯”内容比例平衡,别全卷也不要太保守。
AI创作者注意了:账号权重下调,内容为王的时代彻底来了。
所以得活跃起来了,不然流量会越来越差的,形成两极分化。
May 24

So I spent some time studying the new Twitter/X algorithm today since the latest version was published about a week ago on Github (github.com/xai-org/x-algorit…).
My goal was to answer why so many people have seemingly seen such a dramatic drop in their posts' reach.
The first answer, which is actually somewhat unrelated to the ranking algorithm on Github, is the auto-translate feature, rolled out worldwide on April 7, 2026 (x.com/nikitabier/status/2041…).
Before that date, if you wrote in English about, say, the Trump-Xi Beijing summit, you were competing for attention with maybe 5,000 other English-language accounts writing on geopolitics.
After that date, your post is competing for attention with other posts on the same topic IN EVERY LANGUAGE ON EARTH. For some topics that do command global attention like geopolitics, that's a very brutal multiplier: you used to be one of 5,000, you're suddenly one of 50,000 (something of that order): MUCH more difficult to stand out.
Secondly, the number of followers you have matters far less than it used to: each post now has to earn its audience reader by reader, on the predicted engagement of the post, and how its topic matches what each reader has recently been engaging with.
Here is how the algorithm works, in simple terms: when you, as a reader, open your feed, the algorithm doesn't load "posts from accounts you follow." Instead it runs a 2-stage prediction of what posts you're likely to engage with in that very moment.
The first stage is the retrieval stage. The system narrows billions of posts on X/Twitter that day down to roughly 1,500 candidates by matching the semantic content of each post - what it's about - against what you as a reader have recently engaged with. Some candidate posts come from accounts you follow; others are pulled from across the platform by pure topic similarity to your recent interests.
You can test this retrieval stage easily: start disproportionally engaging with - say - Brad Pitt videos and you'll bit by bit see your timeline flooded with Brad Pitt content, most of it from accounts you've never followed and never heard of.
Then there's the ranking stage. Each of these candidate posts for your feed is fed through a Grok-based model that tries to understand if you'll engage with the post.
It looks at 15 engagement metrics:
1) P(favorite) — the reader likes the post
2) P(reply) — the reader replies to it
3) P(repost) — the reader reposts it
4) P(quote) — the reader quote-tweets it
5) P(click) — the reader clicks a link in it
6) P(profile_click) — the reader taps through to your profile
7) P(video_view) — the reader watches the video
8) P(photo_expand) — the reader expands an image
9) P(share) — the reader shares it (DM, off-platform, etc.)
10) P(dwell) — the reader stops scrolling and lingers on the post
11) P(follow_author) — the reader follows you after seeing it
12) P(not_interested) — the reader marks "not interested"
13) P(block_author) — the reader blocks you
14) P(mute_author) — the reader mutes you
15) P(report) — the reader reports the post
Fifteen predicted actions, each multiplied by a weight, summed: that sum is the score that determines in which priority a post will be seen among other candidates.
Please note that posting something with a video or an image can give your post an advantage as 2 actions are specifically for these: video_view and photo_expand. No video or photo and you don't get a score for these. Also, naturally, having a video maximizes the chance that a user will "dwell" on your post to watch it.
Also note that 4 of these actions carry negative weights (not_interested, block_author, mute_author and report): meaning that if the model expects a post to generate a lot of negativity, it'll get de-boosted quite dramatically.
But note, first and foremost, what's NOT in there: none of the things that, naively, one might think a serious information platform would weigh. There is no P(this post is true and well-sourced). No P(the author actually knows what they're talking about). No P(this person has spent a decade building a body of work that has held up). No P(this account has earned the right to be taken seriously on this topic). No P(the author has a large following from credible people). The model does not seem to care - at all - about any of that.
Every post starts from zero. You could have ten years of rigorous, well-sourced analysis behind you - or you could be just an uneducated rando who registered yesterday. To this algorithm, you're both just a bag of engagement probabilities.
Now, sure, to be fair, there is a "brand" effect that's not covered by the algorithm: someone who has in fact built a brand will naturally have better engagement metrics because people recognize their account. But that's an indirect, second-order effect. And crucially, it's legacy: those "brands" were built under earlier versions of the algorithm that gave followers and reputation more weight.
Lastly, several other features of the new algorithm compound the dilution, none of them visible from outside but all consequential.
The May 15 update added an "impression bloom filter," tightening the rule that once a reader has been served a post, the system won't serve it to them again. Before, a strong post could marinate in someone's feed across multiple refreshes and accumulate engagement on the second or third pass. Now it basically gets one shot.
Also, your own posts compete with each other. An "Author Diversity Scorer" inside the ranking stage attenuates the score of every subsequent post of yours that ends up in a reader's candidate pool. In plain terms: if multiple of your posts land in a reader's candidate pool, the system shows one at full strength and dampens the others. So don't post several times consecutively on the same topic.
And, last but not least, another huge impact on reach is that, in the old algorithm, when someone reposted or quote-tweeted you, your post was broadcast to their followers' timelines - a repost from an account with 100,000 followers was a huge boost.
In the new algorithm, that mechanism is vastly demoted: reposts - like every post - need to go through the retrieval and ranking stage mentioned above, so a repost from a big account is a long way from the boost it used to be.
This is especially brutal for low-effort quote tweets, which used to function as cheap amplification: now they often can't even clear the retrieval stage - they simply don't contain enough novel semantic content for the system to match them to anyone's interests.
So, putting it all together, the reach collapse comes from many forces stacking at once:
- Auto-translate makes your posts compete for attention against an order of magnitude more content
- The retrieval stage matches posts by topic, not by who follows you
- The ranking stage scores purely on predicted engagement with no weight for credibility, expertise, or track record
- The bloom filter narrows every post's window to one strong shot
- The diversity scorer penalizes prolific posting
- Reposts no longer carry much distribution power
Each of these alone would dent your reach. Combined, they amount to a complete reset: your audience that you built painstakingly over years basically doesn't matter much anymore, and it's much - much - harder to stand out even if you're a big account.
People structurally rewarded by this algorithm are folks who:
- Post visually (videos/images)
- Post on globally popular topics because they clear the retrieval stage easily
- Provoke strong emotional reactions - likes, replies, reposts
- Don't care about accuracy or seriousness because the algorithm doesn't measure it
- Don't care about their existing audience because every post is judged in isolation anyway
In short this new algorithm, like so many on social media, is all about maximizing whether people will engage with something - not about whether they should.
9
6
1,905