What if you could scale phone-use agent training without hand-building every environment?
Tencent Hunyuan and collaborators present PhoneWorld: a pipeline that automatically turns real screenshots and user interactions into controllable mock apps, executable tasks, and verifiers.
Under the same training budget, replacing just 10K steps from an AndroidWorld baseline with PhoneWorld supervision improves all four benchmarks at once—HYMobileBench by 17.7 pts, AndroidControl by 6.0, AndroidWorld by 14.7, and PhoneWorld by 52.5. More apps = even bigger gains.
PhoneWorld: Scaling Phone-Use Agent Environments
Paper: arxiv.org/abs/2605.29486
Our report: mp.weixin.qq.com/s/uzasS6q6L…
📬 #PapersAccepted by Jiqizhixin

3
403

Jun 16
Anthropic Computer Use: closed API.
OpenAI Operator: closed API.
Google Project Mariner: closed API.
@BytedanceTalk built the same thing — made it fully open source
under Apache 2.0 — and it became the largest open source
GUI agent project on GitHub.
bytedance/UI-TARS-desktop — 33,500 GitHub stars.
Launched January 2025. The entire stack shipped publicly.
Here's what makes it different from every other AI agent:
→ GUI-native — takes screenshots, understands what's on screen,
executes real mouse clicks and keyboard actions
→ No DOM inspection. No API keys for the target software.
If a human can see it and click it — UI-TARS can too
→ UI-TARS Desktop — Electron app for local and remote
computer control, plus browser automation built in
→ Agent TARS — CLI and Web UI for terminal and product
pipeline integration, multimodal tools included
→ UI-TARS-2 benchmarks: 47.5% OSWorld, 73.3% AndroidWorld,
88.2% Online-Mind2Web — roughly double the v1 scores
→ MCP integration — connect to any MCP tool from the agent
→ Event Stream Viewer — watch data flow and debug in real time
→ Streaming tool support with timing statistics per call
→ Five-layer open release: model, framework, runtime,
MCP kernel, and behavior logs — all public
→ Automates: travel booking, VS Code config, GitHub navigation,
form filling — anything a human does on a screen
→ Apache 2.0 licensed — 2,900 forks, shipping actively
The closed players have the model. ByteDance shipped the stack.
Discovered on OSSphere : ossphere.dev/bytedance/UI-TA…
What's the most repetitive screen task you'd automate first
with a GUI agent? Drop it below 👇
#UITARS #OpenSource #AIAgents #GUI #BuildInPublic #ByteDance #ComputerUse
2
118

Jun 16
Apple's Ferret-UI Lite is a 3B-parameter on-device GUI agent built for mobile, web, and desktop. Key ingredients: curated real synthetic GUI data, chain-of-thought reasoning, visual tool-use, and RL with designed rewards. On GUI navigation, it hits 28.0% on AndroidWorld and 19.8% on OSWorld. Competitive for its size, though those nav scores show how hard real-world GUI automation remains. #aiagents #ondeviceml #guiautomation
machinelearning.apple.com/re…
20
Jun 15
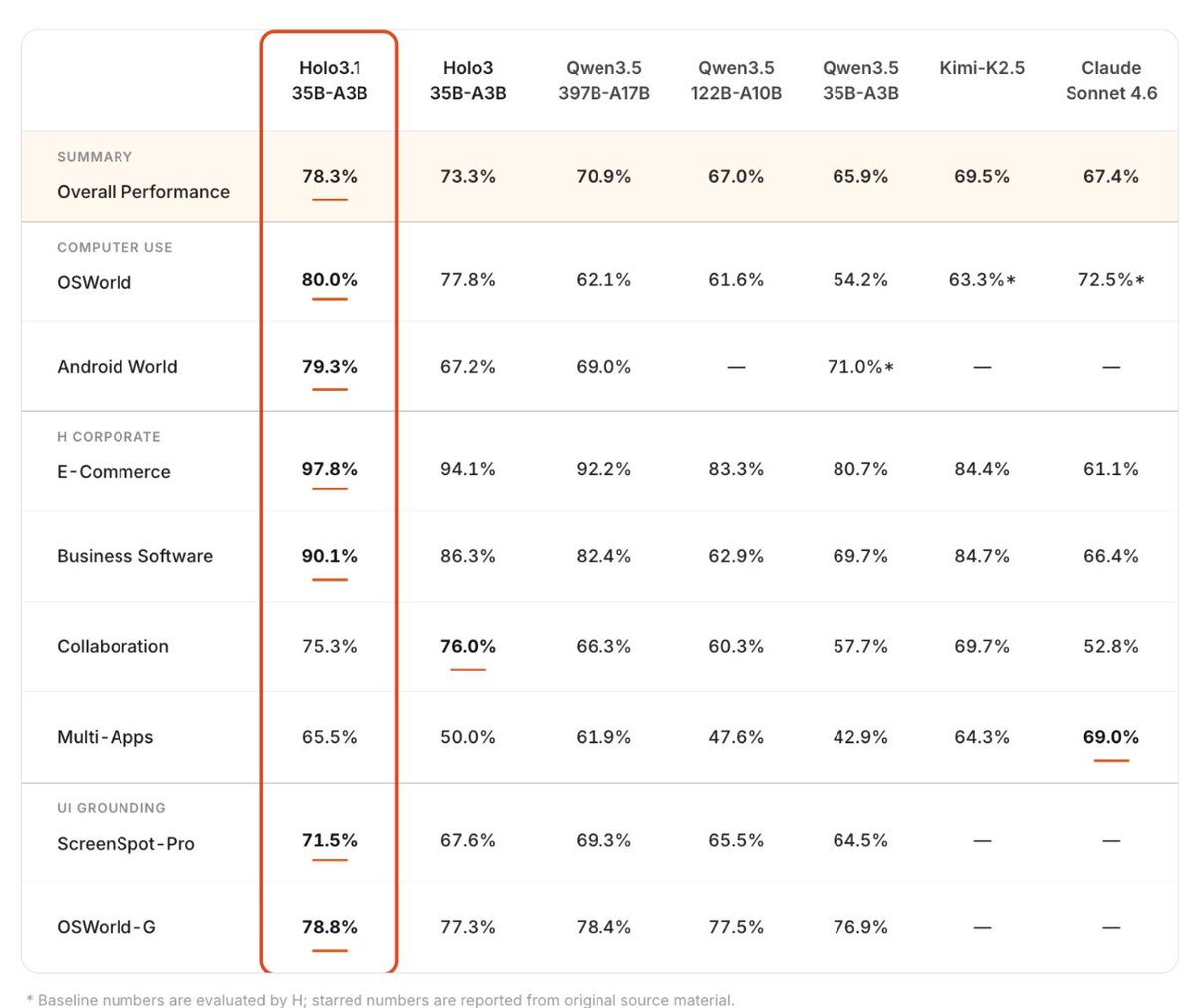
Holo3.1 from Hcompany is a computer-use agent family (based on Qwen) targeting cross-environment robustness: web, desktop, and mobile. Notable result: their 35B-A3B model jumps from 67% → 79.3% on AndroidWorld. First release to ship quantized weights (FP8, Q4 GGUF, NVFP4) for local inference. Caveat: several benchmarks cited are internal, so treat cross-family comparisons cautiously until third-party evals land.
huggingface.co/blog/Hcompany…
37

Jun 14
Can't remember what you last did in a multi-step app task? What if your AI agent could?
Researchers present SE-GA — a GUI agent with a memory system that learns as it goes. It uses a hierarchical memory to recall past steps, actions, and context, then self-improves on the fly.
Result: SOTA on offline & online benchmarks — 89% on ScreenSpot, 75.8% on AndroidControl-High, and strong gains on dynamic AndroidWorld.
SE-GA: Memory-Augmented Self-Evolution for GUI Agents
Paper: arxiv.org/abs/2605.16883
Code: github.com/jinshilong-dev/SE…
Our report: mp.weixin.qq.com/s/7lIMXc0JW…
📬 #PapersAccepted by Jiqizhixin

8
25
2,003

Jun 13
The 'screenshot-to-cloud' agent era is officially over ☁️❌ Holo3.1 launched with quantized checkpoints (Q4 GGUF, NVFP4, FP8) meaning you can run serious computer-use agents on your actual laptop. No subscription. No data harvesting. Just pure local automation. Mobile support included (79% on AndroidWorld!). From 0.8B edge models to 35B beasts. Finally—AI that actually lives on your device. Time to build 🛠️✨ url: huggingface.co/blog/hcompany…
1
4
127

Jun 5
【PCやモバイルの操作に対応するAIモデル「Holo3.1」】
HcompanyがHolo3.1を発表。WebやPC、モバイルの操作に対応するComputer Use Agents(画面や端末を操作するAIエージェント)向けのモデル群で、ローカル推論向けの量子化チェックポイント(軽量化済みモデル)も公開した。
35B-A3Bモデルでは、AndroidWorld(Android端末操作の評価ベンチマーク)でスコアが67%から79.3%に向上。4Bモデルと9Bモデルも同ベンチマークで58%から72%に向上した。外部のエージェント基盤向けに、function calling(関数呼び出し)の標準方式にも対応する。
量子化チェックポイントは、現時点では35B-A3B向けにFP8、Q4 GGUF、NVFP4形式を用意。WindowsやMacでエージェントをローカル実行でき、同一ネットワーク内のDGX Spark(小型AI計算機)と組み合わせた運用にも対応する。DGX Sparkでは、NVIDIAとの最適化とNVFP4量子化により、平均ステップ時間を6.8秒から3.3秒に短縮した。

1
3
899

Jun 2
Holo 3.1 reaches a new SOTA on AndroidWorld, a popular computer use agents benchmark
Can be explored here paperswithcode.co/paper/8569…
Jun 2

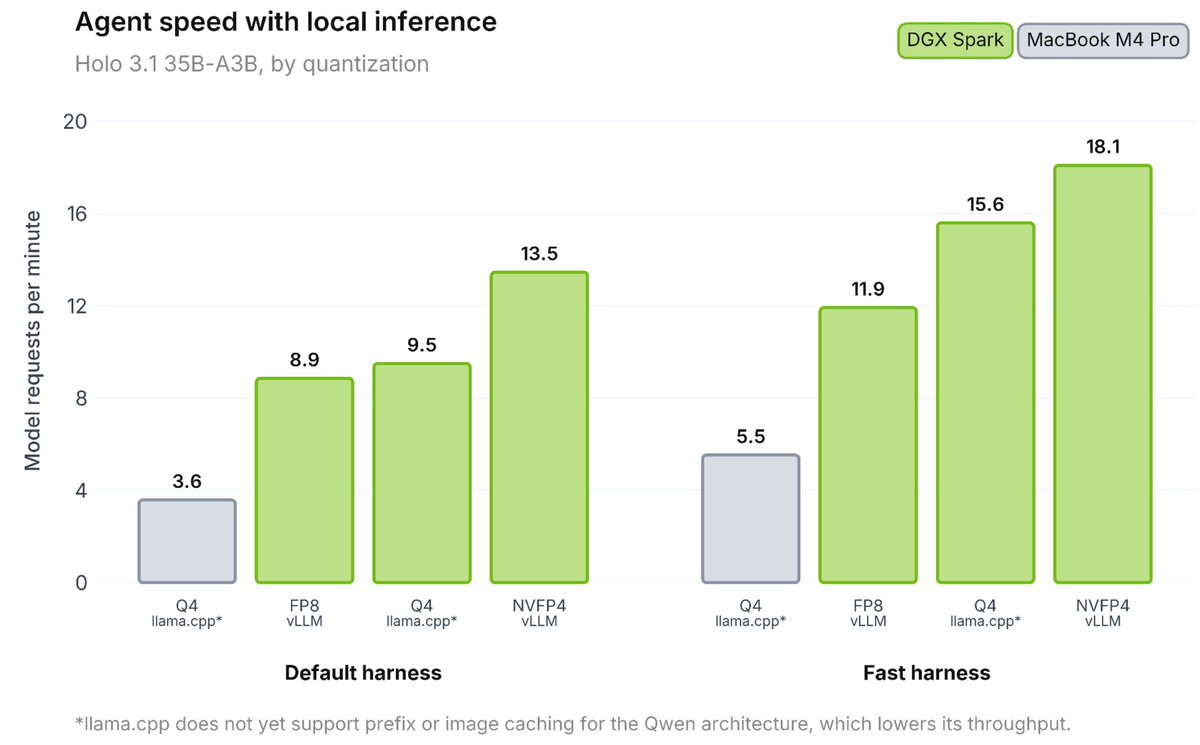
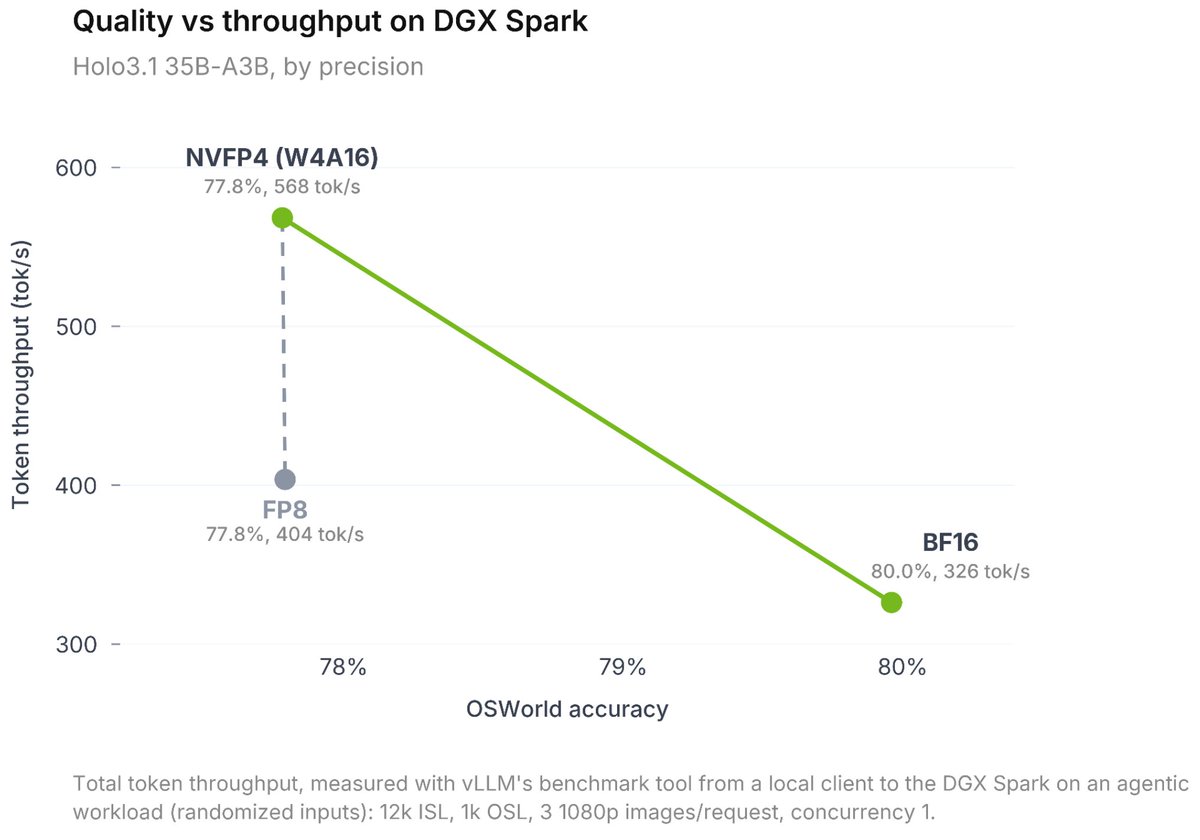
Computer-use agents are moving from the cloud to your local machine. Fast.
When we launched Holo3 two months ago, the production feedback was clear: digital agents need to be blazing fast, cost-effective, and versatile.
Today, we're dropping Holo 3.1, engineered to run anywhere, instantly.
Massive token throughput. Low latency. Ready for your local workflow!

3
7
37
11,189

Jun 2
📱 Breakthrough Mobile Performance
Desktop was just the start. We’ve driven a massive leap in mobile environment control. On the AndroidWorld benchmark, our 35B model skyrocketed from 67% to 79.3%, while our compact 4B and 9B models leaped from 58% to 71%.
2
1
27
4,206

May 24
Life update: Left Agi inc
Leaving notes.
Worked with multiple companies before, but this time it hits different.
Been working at AGI Inc for the past year. Joined as a contractor, later ended up leading RealEvals., worked with teams across Fortune 500. Hit SOTA on AndroidWorld , OsWorld too.
Crazy journey. Learned a lot overall evolved
Moving to the next chapter
1
1
8
197

May 24
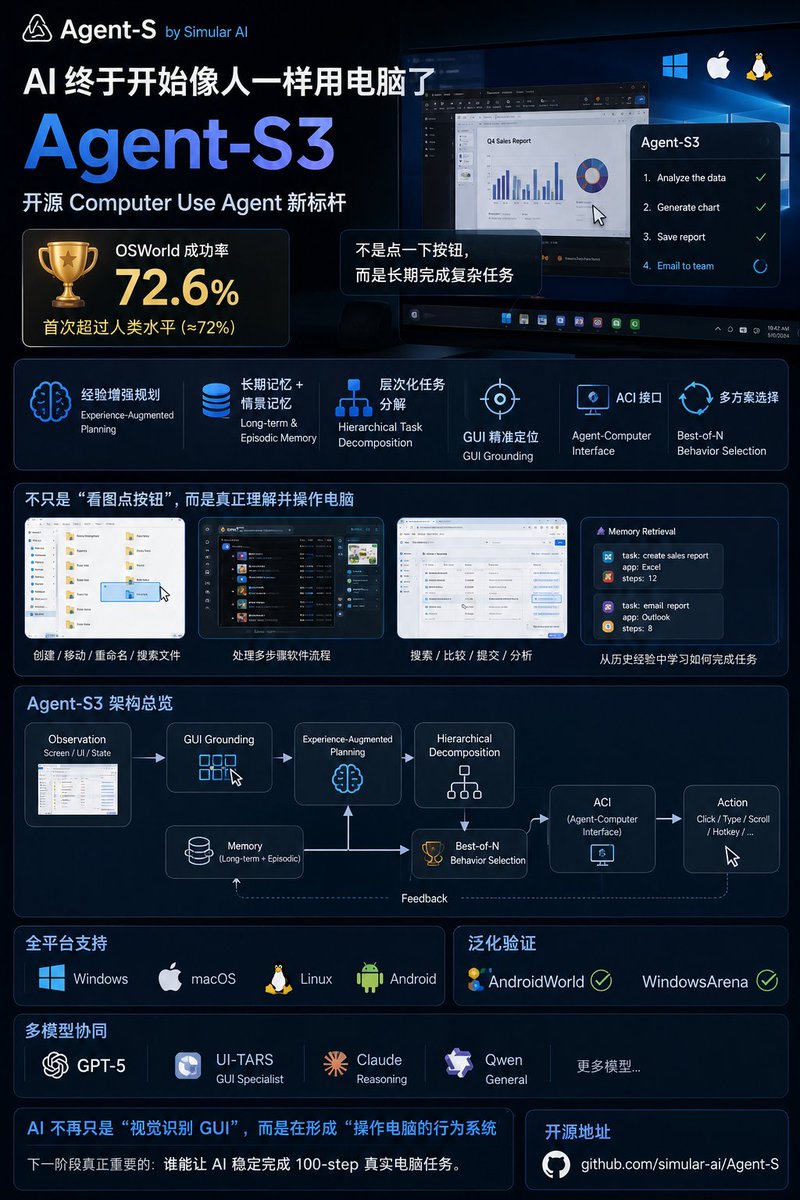
AI Agent终于开始"像人一样用电脑"了
不是API automation。不是workflow script。不是RPA
而是:真正看屏幕、理解界面、自己操作电脑。
Simular AI开源的Agent-S最近越来越猛
最新的Agent S3,已经在OSWorld上做到:
🏆 72.6%成功率
👉第一次超过人类水平(≈72%)
重点是它不是单纯"截图 点按钮",而是一整套Computer Use Agent架构:
🧠 Experience-Augmented Planning(经验增强规划)
📦 长期记忆 episodic memory
🎯 Hierarchical task decomposition
👀 GUI grounding(精准定位界面元素)
⚙️ Agent-Computer Interface(ACI)
🔁 Best-of-N behavior selection
🌐 Windows / macOS / Linux 全支持
📱 AndroidWorld / WindowsArena 泛化验证
🧩 GPT-5 UI-TARS 等多模型协同
最关键的一点:
👉它不是"让AI会用电脑",而是"让AI学会如何长期完成复杂任务"。
以前Computer Use:点一下按钮就迷路。
现在Agent-S已经开始:
📂操作文件系统
📊处理复杂软件流程
🌐长链路网页任务
🧠从历史经验中检索"以前怎么做过"
这一步真正变化的是:
👉AI不再只是"视觉识别GUI",而是在形成"操作电脑的行为系统"
很多人还在卷聊天机器人,但下一阶段真正重要的,可能是:谁能让AI稳定完成100-step真实电脑任务
github.com/simular-ai/Agent-…
#AI #Agents #ComputerUse #OpenSource
109

May 21
Cannot scale up for training and evaluation for CUA agents?
So when I am doing computer-use agents, the evaluation is done on specific benchmarks like OSWorld and AndroidWorld, and training is like selecting environments from these benchmarks to do RL, which only has very limited environments and cannot scale up.
We present OpenComputer, a pipeline that can turn software into computer-use agent training and evaluation environments. It already contains 1,000 tasks and environments, and we are continuing to scale up! We welcome contributors to synthesize more tasks and environments as well.
1
1
6
1,611

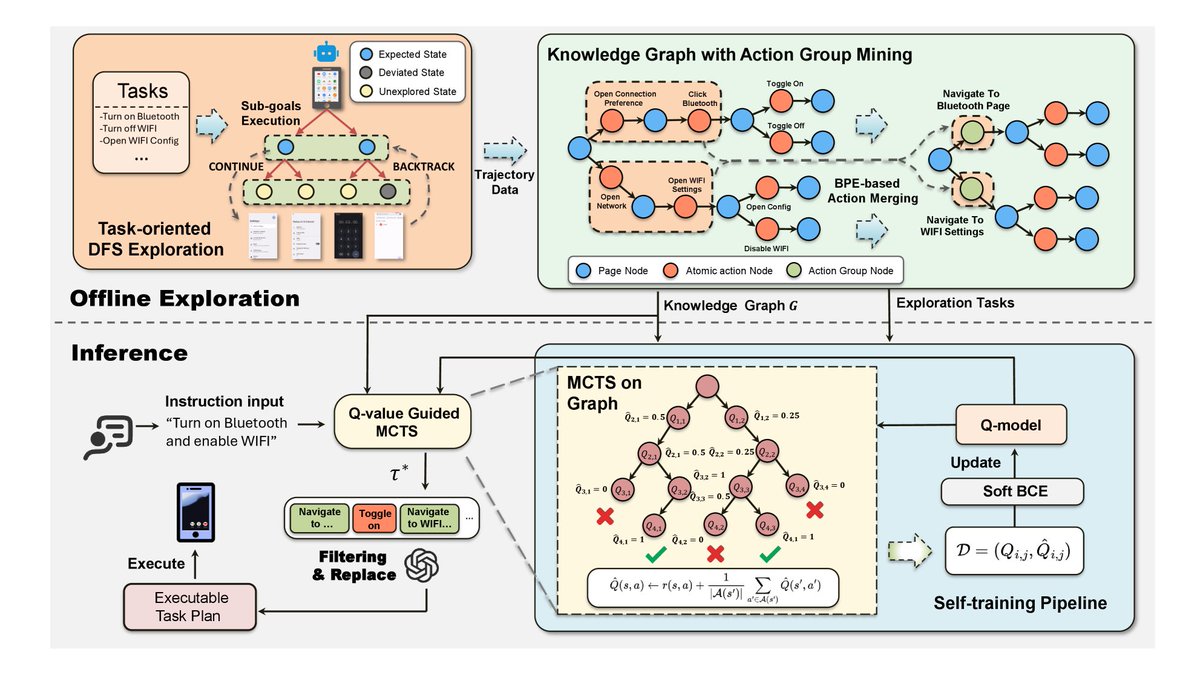
Will need to try this with JARVIS... new paper drop:
Executable Agentic Memory (EAM) gives GUI agents a map. Instead of re-reading every screen from scratch, the agent builds a knowledge graph of what it's seen and what works, then navigates it.
- 19.6% accuracy on AndroidWorld vs UI-TARS-7B ( SOTA on-device baseline)
- Matches closed cloud at 6x fewer tokens
-2.8s average per step
arxiv.org/abs/2605.12294
1
9
560

May 13
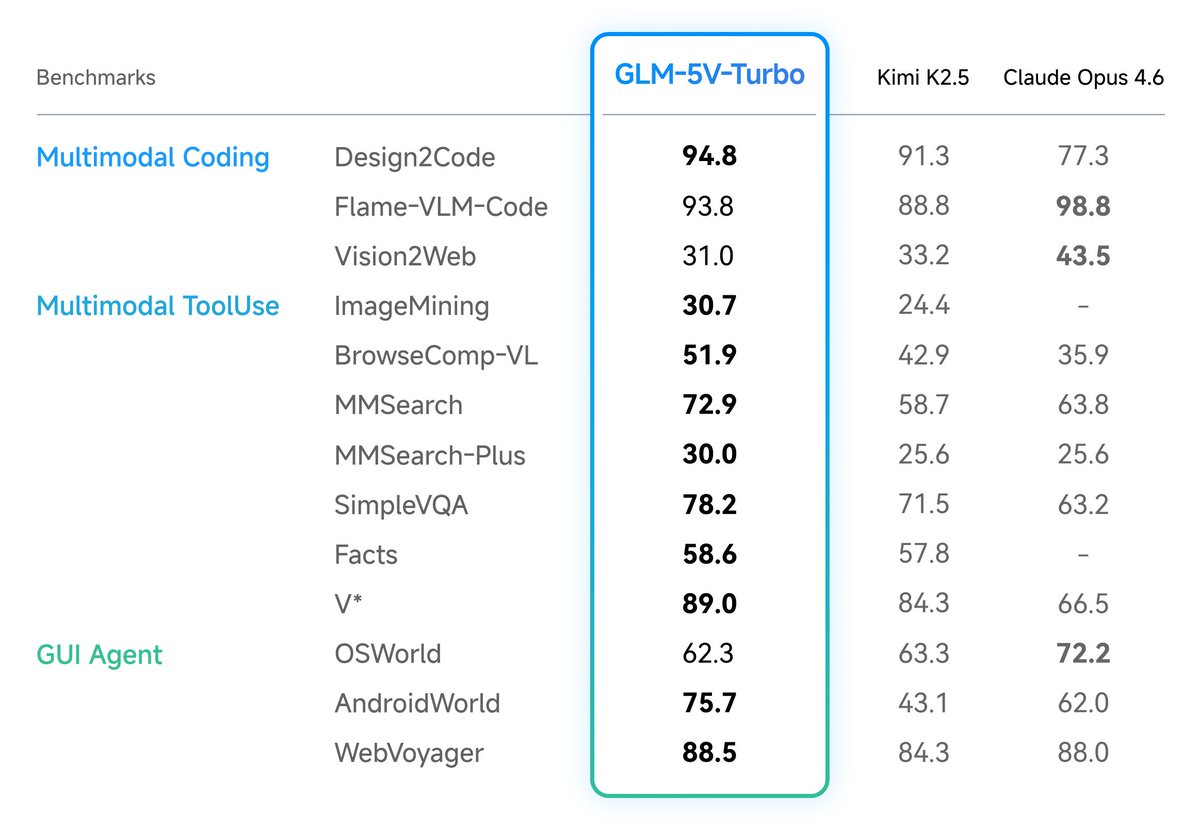
GLM-5V-Turboが発表された(https://arxiv[.]org/html/2604.26752v1)。
Zhipu AIが開発したマルチモーダルエージェント基盤モデル。多くの従来VLM(視覚言語モデル)が「テキストモデルに視覚を後付け」する設計なのに対し、視覚理解を推論・計画・実行の中枢として一体化しているのが核心。
実装が面白い。視覚エンコーダー「CogViT」は2段階の事前学習で構築。第1段階では「意味表現担当のSigLIP2」と「テクスチャ担当のDINOv3」の2つのTeacherモデルから知識を蒸留しながら、マスク率35%でMasked Image Modeling(画像の隠れた部分を復元するタスク)を実施。QK-Norm(クエリ・キーベクトルの正規化)でアテンションスコアの爆発を防ぐ工夫も入っている。第2段階では可変解像度入力に対応しながら、80億件の中英バイリンガルデータでコントラスト学習。
MMTP(マルチモーダル・マルチトークン予測)では「画像トークンをどうMTPヘッドに渡すか」という実装問題があった。3案を比較した結果、視覚埋め込みをそのまま渡す案は「MTPヘッドが軽量すぎて分布の異なる視覚表現を吸収しきれない」と判明。最終的に全画像トークンを特殊トークン「<|image|>」に置き換える案が0.5Bモデルの実験で最も安定した収束を示したため採用された。
RL訓練インフラも凝っている。参照モデルのパラメータはCPUに常駐させ、必要な直前にGPUへ非同期プリフェッチして即解放することでメモリ圧力を抑制。GPU通信経路から大型Pythonオブジェクトを外すことで通信バッファを約7GB削減している。
30以上のタスクカテゴリにまたがる多タスクRLの結果、SFT(教師ありファインチューニング)比でOSWorld 4.9%、CharXiv(グラフ理解) 7.7%、OCRBench 4.2%、MVBench(動画理解) 5.6%と横断改善。最終ベンチマークはDesign2Code 94.8(Claude Opus 4.6超え)、AndroidWorld 75.7、OSWorld 62.3。
論文が繰り返す洞察は「知覚(Perception)の精度が上位能力の上限を決める」こと。推論や計画のエラーに見えるものの多くが視覚環境の誤読から始まっている。見ることが正確でなければ考えることも正確にならない、という当たり前が最先端でもまだ難しい。
2
316

May 13
Google just previewed Gemini Intelligence for Android.
Funny timing: last week I built a rough version of the same idea.
My project is called On Screen. It is an autonomous agent for your phone. It can look at what is happening on the screen, move across apps, and do native tasks like messaging someone, finding a link, booking an Uber, or setting an alarm.
The original inspiration was @FarzaTV @heyclicky for desktop. Farza is also working on Clicky for mobile, which is awesome.
@vineetwts has also made something similar in this space.
x.com/vineetwts/status/20425…
To be clear, this is not perfect. It hallucinates. It gets stuck. Sometimes it finishes half a task and then randomly moves to another one. I built this as an initial prototype over 5 weekdays. (over weekends)
The cloud version works better right now, but I am more bullish on the on-device branch.
If an agent can see your screen 24/7, privacy cannot be an afterthought. I do not think people will be comfortable sending their full phone context to a company all the time.
That is the part I find most interesting: tiny on-device models, mobile GUI grounding, AndroidWorld-style tasks, and whether phone agents can become useful without leaking everything.
I talk about that in the second half of the video.
You can download the APK here: onscreen.mayankpratapsingh.i…
Try it, break it, and tell me where it fails. That feedback will decide whether I build version two.

Today, we introduced Gemini Intelligence, which brings the best of Gemini to our most advanced devices.
Gemini Intelligence integrates premium hardware and innovative software to help you stay a step ahead and work proactively to get things done throughout your day. #TheAndroidShow
1
5
547

Let @sai_borg babysit Claude Code. Not you.
90.1% WebVoyager
72.6% OSWorld - first to surpass human performance
71.6% AndroidWorld
Your work isn’t one surface. Agent S isn’t either. @SimularAI
Open source: github.com/simular-ai/Agent-…
1
8
465

May 3
aiming for 5 research topics for the upcoming few months, if yall want to join in pls do so,
GPU shortage wont be there (hopefully)
(worked on these problem statements a bit previously, and have ran a few experiments on each)
find them below:
ps 1 : Process Reward Models Beyond Outcome Supervision
Without the need for human-labeled trajectories, we provide a completely automated approach for training Process Reward Models (PRMs) that either meet or surpass the quality of gold step-level annotations. We create dense Monte-Carlo Tree Search (MCTS) rollouts with depth d ≥ 32 and branching factor b = 8, starting from a base policy π_θ trained via SFT on chain-of-thought data. Each intermediate step is scored using an ensemble of outcome verifiers (ORMs) bootstrapped from self-consistency and LLM-as-judge signals under temperature T = 0.7. A process-DPO variation with step-wise Bradley-Terry losses weighted by MCTS visit counts and calibrated via Platt scaling on a short held-out verification set is introduced to reduce verifier noise.
By simultaneously optimising the PRM and policy under a single RLVR goal that alternates between process-level preference optimisation and outcome-level PPO updates, with adaptive mixing ratio λ_t planned via cosine annealing, our method closes the annotation gap. Our auto-annotated PRM delivers 14.7% pass@1 over outcome-only RM baselines at 7B scale and transfers to code and scientific reasoning domains with 3% deterioration following LoRA adaptation on 2k domain-specific trajectories, according to extensive ablation on GSM8K, MATH, and HumanEval. We present the multi-domain PRM benchmark, the distilled verifier weights, and the whole MCTS annotation program, offering the first production-ready recipe for frontier-scale process supervision.
ps 2 : Computer-Use Agents and GUI Grounding
In addition to introducing a large-scale synthetic data engine that uses Playwright Android Emulator instrumentation to generate 500k grounded interaction traces across web, mobile, and desktop environments, we formalise GUI grounding failures through a tripartite decomposition: perception (pixel-to-semantic mapping), planning (high-level action sequence), and execution (low-level mouse/keyboard trajectories). Pixel-level segmentation masks, accessibility tree annotations, and oracle action sequences obtained via deterministic UI state diffing are linked with each trace. Using a hybrid loss that combines contrastive screen embedding alignment (using InfoNCE on cropped UI elements), autoregressive action token prediction, and auxiliary bounding-box regression heads that function at 4× downsampled resolution to maintain fine-grained OCR and icon semantics, we train a multimodal VLA policy on top of a Qwen2-VL-7B backbone.
A domain-adversarial training objective that aligns screen embeddings across platforms while maintaining task-specific action distributions is combined with test-time adaptation using a lightweight 256M adapter that conditions on platform-specific accessibility trees to achieve cross-platform zero-shot transfer. Our model decreases end-to-end grounding error from 48% (Claude-3.5 baseline) to 19% on the recently released GUI-Grounding-Bench (which includes 12k actual jobs from WebArena, AndroidWorld, and OSWorld), with the biggest improvements in perception-heavy mobile UIs. We provide the cross-platform VLA checkpoint, the failure atlas taxonomy, and the complete synthetic trace generator, creating the first reproducible benchmark and recipe for reliable computer-use agents.
ps 3 : Agent Memory Architectures Beyond RAG
We present TypedAgentMemory, a modular memory substrate controlled by a differentiable memory controller trained end-to-end with the agent policy that explicitly distinguishes episodic semantic (dense vector summaries with SAE-derived concept tags), procedural, and working (short-term KV cache compression) memories. A 128-dim uncertainty head that thresholds epistemic uncertainty from an ensemble of forward passes gates memory writes. The controller uses a hierarchical policy over four memory operations: write, consolidate (graph-based merging with GNN message passing), forget (learned eviction via eligibility traces and recency relevance scores), and retrieve (hybrid dense symbolic query routing). Explicit memory consolidation every 50 steps is used to evaluate long-horizon tasks on τ-bench, WebArena, and GAIA. This results in a 2.3× decrease in context length and a 31% improvement in success rate over flat vector-store RAG baselines.
Per-memory-type differential privacy approaches, such as homomorphic encryption for procedural skill graphs, concept-level k-anonymity on semantic features, and ε = 0.5 noise injection on episodic writing, are used to ensure privacy. Ablations show that typed memory facilitates effective cross-task transfer through procedural memory reuse and prevents catastrophic forgetting on 200-step agent trajectories. We provide the first rational substitute for monolithic RAG for production-grade autonomous agents by making the whole TypedAgentMemory library (based on LangGraph FAISS Neo4j), the long-horizon evaluation harness, and pretrained memory controllers for Llama-3.1-8B and Qwen2.5-72B open-source.
ps 4: SAE Universality Across Model Families
By training 128k-feature JumpReLU SAEs (expansion factor 64, k = 32) on residual streams of Llama-3.1-8B, Qwen2.5-72B, Gemma-2-27B, Mistral-Large-2, and DeepSeek-V3 with the same hyperparameters and reconstruction aims, we perform the first extensive cross-family SAE universality investigation. A bipartite matching that quantifies pairwise overlap at both neuron-level (cosine similarity > 0.85) and concept-level (via automated interpretation pipelines using 512 probe prompts per feature) is obtained by performing feature matching via optimal transport with Sinkhorn algorithm on normalised decoder weight matrices. By grouping similar features from different families into 4.2k platonic ideas and annotating each concept with activation data, downstream steering efficacy, and causal mediation scores calculated via route patching, we further build a universal feature library.
Steering vectors created from the universal library outperform within-family SAEs on out-of-distribution tasks and enhance zero-shot generalisation on MMLU-Pro, GPQA, and LiveCodeBench by an average of 9.4% when transferred between families, according to downstream transfer studies. We make available the whole SAE training software, the universal concept library with 4.2k interpreted features, the cross-family matching dataset (which includes optimum transport plans), and a plug-and-play steering toolkit that works with Hugging Face Transformers and vLLM. In order to facilitate transfer learning, model merging, and safety interventions within the existing frontier model ecosystem, this study offers the first rigorous atlas and infrastructure for mechanistic universality.
ps 5 : Synthetic Data Generation Without Mode Collapse
We provide an iterated synthetic data pipeline that explicitly characterises the collapse threshold ρ*(q) as a function of generator quality q (as determined by the activation entropy of the SAE feature and the entropy of the output distribution H_π). Using temperature-annealed sampling (T=1.0 → 0.7) supplemented with SAE-guided rejection sampling, we create synthetic corpora at different mixing ratios ρ ∈ {0, 0.1,…, 1.0} starting from a 7B base policy π_θ trained on 200B tokens of FineWeb-Edu. At each generation, we train a 128k-feature JumpReLU SAE (expansion factor 64, k=32) on the residual stream of the current model and filter synthetic samples whose top-activating features show activation entropy below a calibrated threshold τ derived from the real-data reference distribution.
Our experiments provide the first empirical collapse-threshold map ρ*(q) at 1.3B–7B scale, demonstrating that SAE-guided diversity sampling extends the safe mixing ratio by 2.3× compared to persona-conditioned or temperature-only baselines, while generator entropy H_π ≥ 4.2 nats delays the onset of measurable perplexity degradation on a held-out real validation set until generation 7 under accumulation (versus generation 3 under pure replacement). A closed-form constraint on variance contraction rate under synthetic mixing is derived theoretically, connecting the number of safe iterations before tail probability mass falls below 10^{-3} to the spectral gap of the generator's transition kernel.

16
14
164
15,862

May 1
🔥 GLM-5V-Turbo: A native foundation model for multimodal agents — not a language model with a camera bolted on. Most AI agents still treat vision as an afterthought; this paper makes perception a core part of reasoning, planning, and execution.
Key innovations: CogViT (a vision encoder built for fine-grained understanding), Multimodal Multi-Token Prediction (efficiently handles images during training without exploding compute), and joint reinforcement learning over 30 task categories covering perception, reasoning, and agentic skills.
Results speak loud: 94.8 on Design2Code (beats Claude Opus 4.6), 75.7 on AndroidWorld, 62.3 on OSWorld, 51.9 on BrowseComp-VL. It also retains strong text-only coding — 22.8 on CC-Backend, 68.4 on CC-Frontend. The team released ImageMining, a new benchmark for vision-centric deep search.
Why it matters: Real-world agents need to see layouts, buttons, videos, and documents, not just read text. GLM-5V-Turbo shows that integrating vision natively unlocks a new tier of autonomous capability — from GUI automation to multimodal deep research. Perception isn't a low-level module; it's the ceiling for everything above it. The era of agents that truly see has arrived.
🔗 arxiv.org/abs/2604.26752

2
55


Apr 23
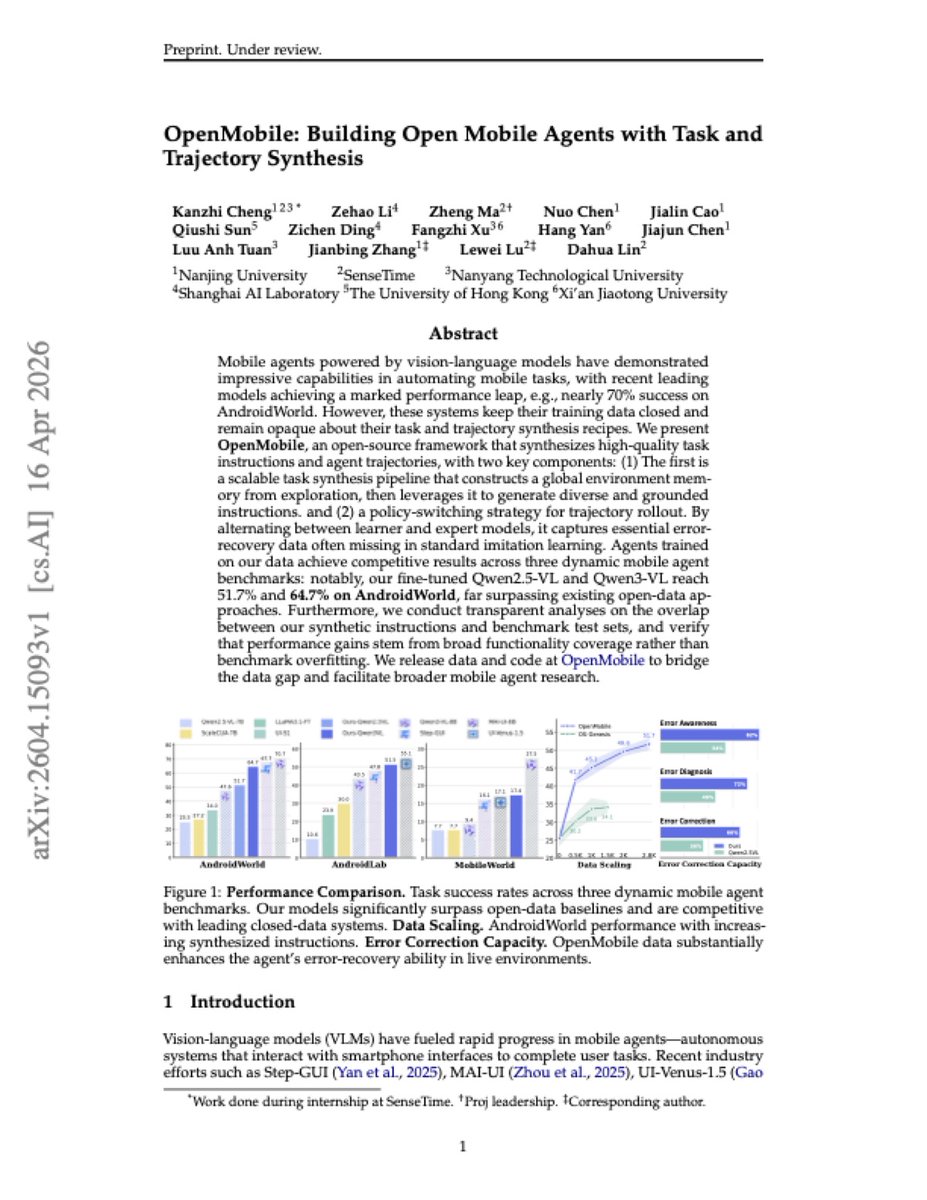
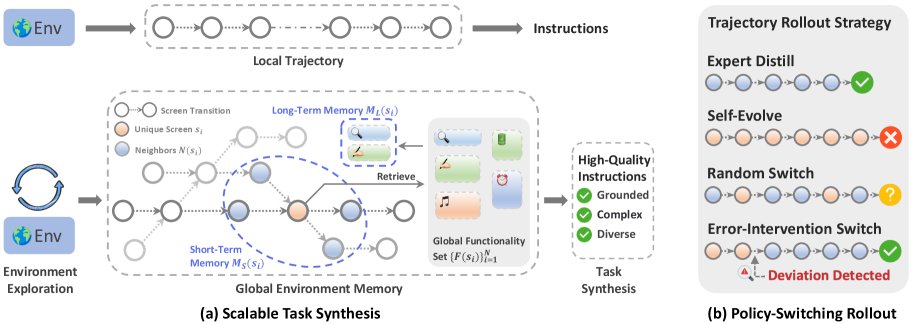
OpenMobile
Open-source framework for mobile agents that synthesizes high-quality task instructions and trajectories, achieving 64.7% on AndroidWorld with Qwen3-VL and bridging the gap between closed and open mobile agent systems.
1
6
24
1,531