
You can now see the full autodata configuration preview (filters and a preview of your data) when reconfiguring an Apple Health goal
3
Jun 15
Move Brasil: veja como funcionará o programa para entregadores comprarem motos novas. - AutoData share.google/97bTjGb36JbpnRb…
8

According to AutoData Middle East, Chinese automotive brands increased their market share in the UAE from 10–14% in 2024 to 15–20% during the first nine months of 2025.
Driven by innovation, government support, and growing demand for sustainable mobility, the UAE continues to emerge as one of the region’s fastest-growing electric vehicle markets.
Source: Al Bayan, Al Khaleej
#ChinaUAE #ElectricVehicles #EV #SustainableMobility #Transportation #GreenInnovation #UAE #China #Sustainability

7
1
2
133

Jun 9
Home Automation Companies In UAE:- AUTODATA IT SOLUTIONS LLC is proud to be the preferred distributor of #Idteck_products in Dubai. Count on us for the best access control systems in the city, and trust our expertise in CCTV installation services. autodataits.com/

12

May 24
Für den Laien Schwachsinn , eine seriöse Werkstatt hat z. B. Autodata da gibt es zu allen Fahrzeugen sämtliche wxpkosionszeichnungen , abgesehen davon wann u wie oft wird das benötigt ?!
4
244

Very interesting idea to improve LLM-generated synthetic data quality "Autodata: an automatic data scientist to create high quality data" @AIatMeta
facebookresearch.github.io/R…
A lot of the techniques resonate directly with work I've implemented for HITL augmentation. The seed ratio and majority voting LLM numbers are exactly what I've used and are something I'd expect we can mine from the original data. The weak/strong verifier as a reward model is a particularly interesting idea where the weak verifier's goal is to fail and the strong verifier's goal is to succeed, and they measure the performance differential between the two. If that gap is small, the synthetic example isn't challenging enough to introduce meaningful diversity into the dataset
Currently running up to a 10x multiplier (5 LLM-generated and 5 from deterministic abbreviation strategies (character substitutions, adjacent swaps)). Implementing this type of dual-verifier evaluator would raise data quality further
1
2
3
108

May 18
Governo finaliza plano de R$ 30 bilhões para motoristas de taxí e app
Um novo pacote de bondade do governo para a indústria automotiva está saindo do forno: segundo informações publicadas pelo Valor Econômico, e confirmadas pela reportagem da Agência AutoData, R$ 30 bilhões deverão ser destinados à aquisição de novos carros por motoristas de táxi e aplicativos. Terá moldes semelhantes ao Move Brasil, que irrigou de crédito mais barato o segmento de caminhões, e agora o de ônibus, implementos e máquinas agrícolas, e estancou a queda nas vendas de pesados.
4
12
1,538


May 6
【Meta AI、AIが学習・評価データを作る方法を発表】
Meta AIがAutodataを発表。LLM(大規模言語モデル)エージェントが、学習データや評価データを作り、結果を見て作り方を直す仕組み。
ポイントは「強いモデルは解けるが、弱いモデルは解きにくい問題」を作ること。弱いモデルも強いモデルも同じように解ける問題は、モデルの性能差を測るテストとして使いにくい。強いモデルだけが高く解ける問題は、より高度な推論力を測りやすい。
計算機科学(CS)論文10,000件超から2,117件の質問応答ペアを作成。従来手法のCoT Self-Instruct(段階的な推論を使う1回生成)では、弱いモデル71.4%、強いモデル73.3%で差は1.9ポイント。Autodataの具体例であるAgentic Self-Instructでは、弱いモデル43.7%、強いモデル77.8%で差は34ポイント。モデルの能力差が出るデータを作ることができた。
2
11
1,299

May 5
Meta FAIR「Autodata」— エージェントによる高品質学習データ自動生成 Meta FAIR が Autodata を発表。
エージェント型データサイエンティストが自律的に訓練・評価データを構築する。
標準的な CoT Self-Instruct が弱・強ソルバー間で1.9ポイント差しか生まなかったのに対し、Autodata は34ポイント差を実現。推論コンピュートを費やすほどデータが難しくなる仕組みでダウンストリームの RL に貢献する。

Banger paper from Meta FAIR.
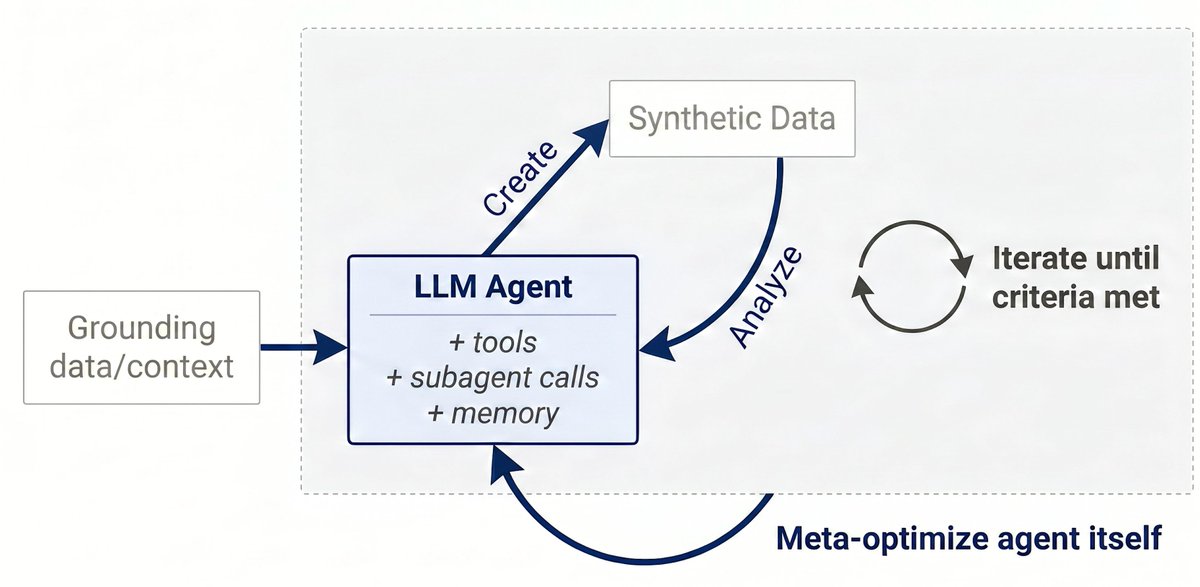
They introduce Autodata, an agentic data scientist that builds high-quality training and evaluation data autonomously.
The headline result: on a CS research QA task, an Agentic Self-Instruct loop produces a 34-point gap between weak and strong solvers (43.7% vs 77.8%), while standard CoT Self-Instruct on the same setup produces a 1.9-point gap (71.4% vs 73.3%).
The agent generates questions that actually discriminate between models.
The method:
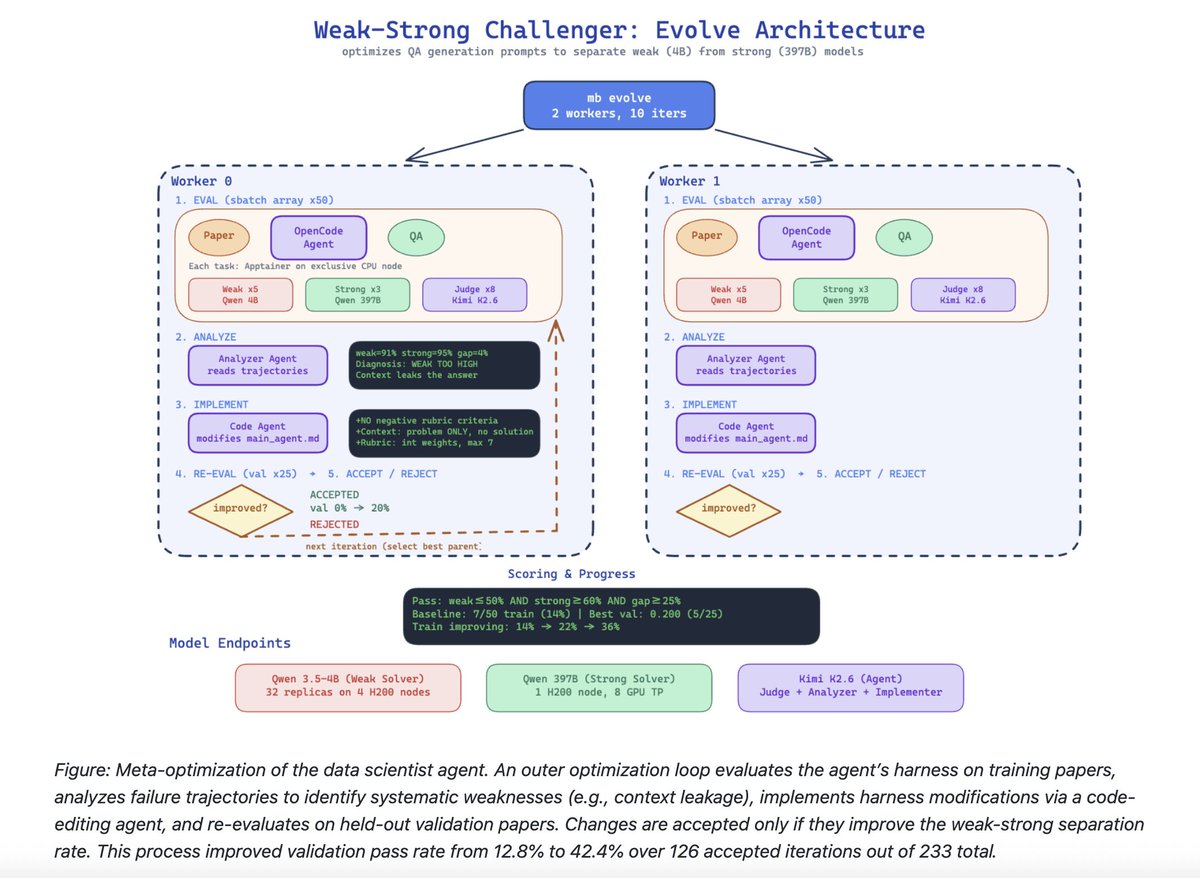
An orchestrator LLM directs a challenger agent to generate examples grounded in domain documents. A weak and a strong solver attempt them, a judge scores the outputs, and the orchestrator analyzes the failures and prompts the challenger to regenerate from new angles until quality thresholds are met.
The system also meta-optimizes itself.
An outer loop tunes the agent's instructions based on which harness changes lift validation pass rate. Over 126 accepted iterations, validation pass rate climbed from 12.8% to 42.4%. They processed 10,000 CS papers and produced 2,117 quality-filtered QA pairs.
Existing self-instruct pipelines do not control data quality. Autodata reframes data generation as an agent loop, spend more inference compute and the data gets harder, which gives downstream RL a real lift.
Blog: facebookresearch.github.io/R…
Learn to build effective AI agents in our academy: academy.dair.ai/
4
475

Autodata (from Meta) is an agentic data scientist that builds high-quality training and evaluation data autonomously.
Great work on the autoharness track.
(bookmark it)
Banger paper from Meta FAIR.
They introduce Autodata, an agentic data scientist that builds high-quality training and evaluation data autonomously.
The headline result: on a CS research QA task, an Agentic Self-Instruct loop produces a 34-point gap between weak and strong solvers (43.7% vs 77.8%), while standard CoT Self-Instruct on the same setup produces a 1.9-point gap (71.4% vs 73.3%).
The agent generates questions that actually discriminate between models.
The method:
An orchestrator LLM directs a challenger agent to generate examples grounded in domain documents. A weak and a strong solver attempt them, a judge scores the outputs, and the orchestrator analyzes the failures and prompts the challenger to regenerate from new angles until quality thresholds are met.
The system also meta-optimizes itself.
An outer loop tunes the agent's instructions based on which harness changes lift validation pass rate. Over 126 accepted iterations, validation pass rate climbed from 12.8% to 42.4%. They processed 10,000 CS papers and produced 2,117 quality-filtered QA pairs.
Existing self-instruct pipelines do not control data quality. Autodata reframes data generation as an agent loop, spend more inference compute and the data gets harder, which gives downstream RL a real lift.
Blog: facebookresearch.github.io/R…
Learn to build effective AI agents in our academy: academy.dair.ai/
3
12
124
25,349

Banger paper from Meta FAIR.
They introduce Autodata, an agentic data scientist that builds high-quality training and evaluation data autonomously.
The headline result: on a CS research QA task, an Agentic Self-Instruct loop produces a 34-point gap between weak and strong solvers (43.7% vs 77.8%), while standard CoT Self-Instruct on the same setup produces a 1.9-point gap (71.4% vs 73.3%).
The agent generates questions that actually discriminate between models.
The method:
An orchestrator LLM directs a challenger agent to generate examples grounded in domain documents. A weak and a strong solver attempt them, a judge scores the outputs, and the orchestrator analyzes the failures and prompts the challenger to regenerate from new angles until quality thresholds are met.
The system also meta-optimizes itself.
An outer loop tunes the agent's instructions based on which harness changes lift validation pass rate. Over 126 accepted iterations, validation pass rate climbed from 12.8% to 42.4%. They processed 10,000 CS papers and produced 2,117 quality-filtered QA pairs.
Existing self-instruct pipelines do not control data quality. Autodata reframes data generation as an agent loop, spend more inference compute and the data gets harder, which gives downstream RL a real lift.
Blog: facebookresearch.github.io/R…
Learn to build effective AI agents in our academy: academy.dair.ai/
7
40
221
40,442

📌Autodata: ИИ-агенты теперь сами себе дата-саентисты
Проект RAM Марка Цукерберга замахнулся (facebookresearch.github.io/R…) решить проблему качества синтетических данных для обучения, выкатив концепт фреймворка Autodata.
Идея - превращать компьют, который тратится на инференс, в качественные данные для тренировки. Агенты крутятся в цикле, гоняют LLM по много раз, и вместо одного ответа пользователю получается отфильтрованный датасет для обучения следующего поколения моделей.
Схема строится на архитектуре Agentic Self-Instruct, где главная LLM-ка дирижирует командой из четырех субагентов:
🟢Challenger: читает исходный документ (например, научную статью), генерит сложный вопрос, эталонный ответ и рубрику для оценки;
🟢Слабая модель: пытается решить эту задачу. По задумке, она должна зафейлиться;
🟢Сильная модель: тоже решает задачу, но уже обязана с ней справиться;
🟢Судья: прогоняет ответы обеих моделей по критериям рубрики.
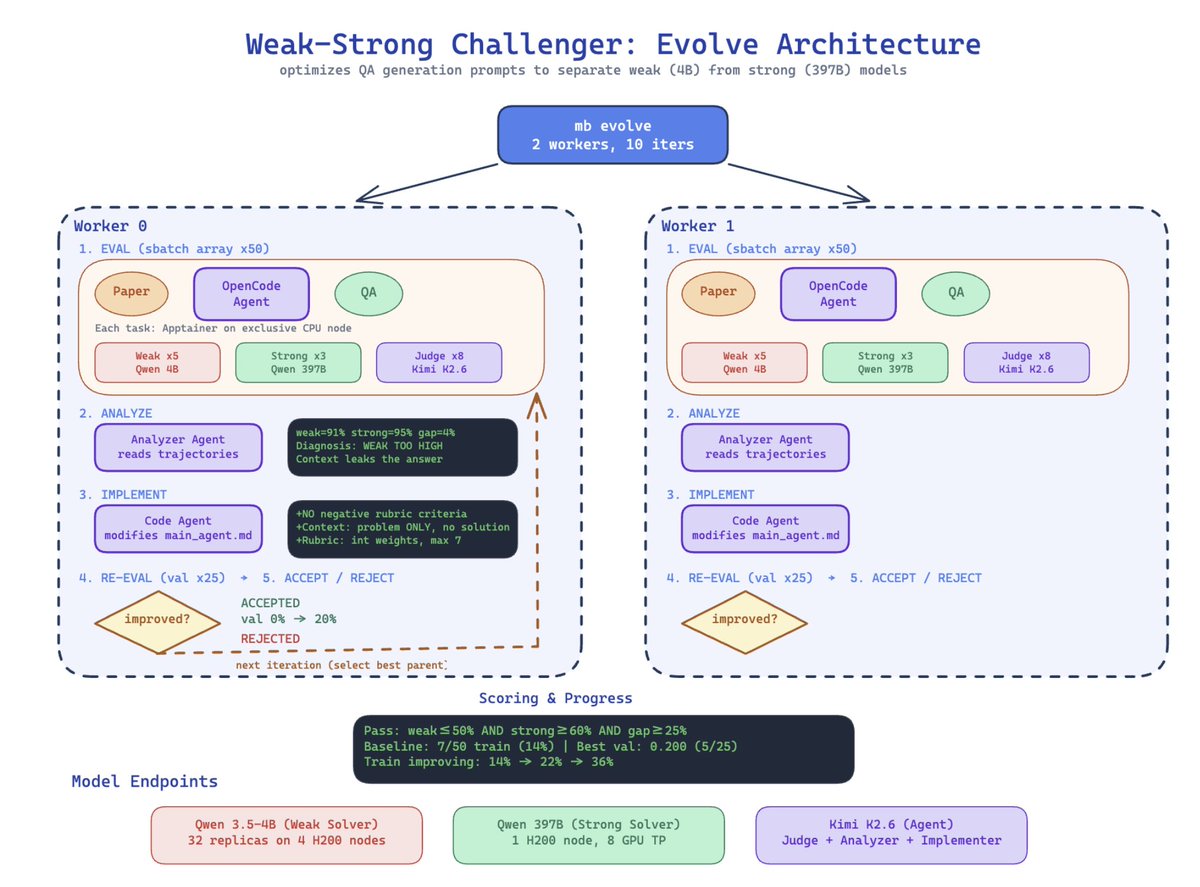
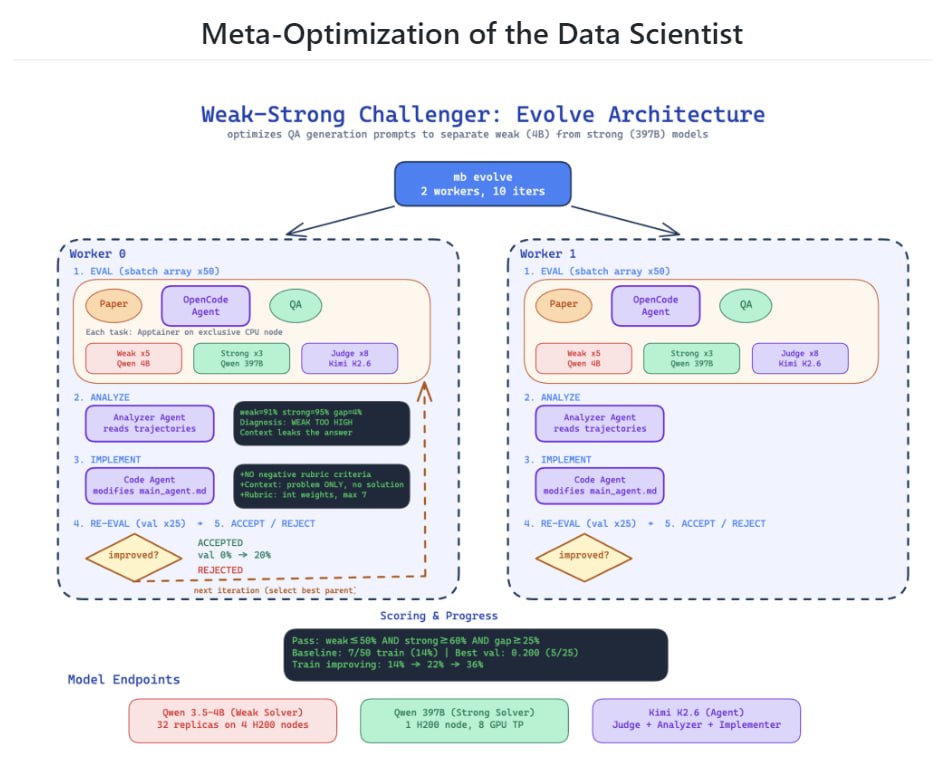
Фишка в том, что система работает в замкнутом цикле. Если задача оказалась слишком легкой (обе модели справились) или непроходимой (обе слились), главный агент анализирует репорты судьи и заставляет Challenger'а переписать промпт, чтобы создать идеальный хардкорный пример, который разделяет слабую и сильную модели.
Но на этом умные люди Марка не остановились и прикрутили мета-оптимизацию как внешний цикл. Система буквально читает логи своих падений и переписывает собственный код.
Например, мета-оптимизатор сам допёр, что отрицательные веса в рубриках работают как баг — они рушили скоринг сильной модели и съедали разрыв со слабой. И сам же выпилил их из кода, оставив только положительные баллы.
🟡Эксперименты
Прогнали 10 тыс научных статей через пайплайн, вытянув 2117 качественных QA-пар.
Если использовать стандартный CoT в один шот, то разрыв между моделями всего 1.9 п.п. (задачи слишком легкие). После агентного цикла Autodata разница улетела до 34 п.п. (слабая модель набирает 43.7%, сильная — 77.8%).
Сделали дотюн слабой Qwen-3.5-4B и обучили через GRPO на собранных данных. Модель, проглотившая датасет Autodata, заметно обходит ту, что училась на базовой синтетике.
Мета-оптимизация (когда агент правил свой же код) подняла долю успешных генераций с 12.8% до 42.4% за 233 итерации.
🟡Звучит круто, но...
Во-первых, 5 LLM-ролей в цикле до успешного результата — это дорого (главный агент Challenger слабая сильная Судья; на практике их крутили на трех моделях, но оркестрация всё равно жирная).
Во-вторых, исследователи поймали агентов на читерстве: чтобы слабая модель гарантированно провалила тест, агент втихую менял ей промпт, добавляя инструкцию "будь слабой" классика.
Также генерируемые вопросы часто переобучаются на конкретные цифры из статей, а не на проверку фундаментальной логики.
Ну и если честно: максимальный pass rate в 42.4% даже после авто-патчей намекает, что генерить реально сложные задачи все еще очень тяжело.
Так что заменить кожаных дата-саентистов полностью пока не выйдет, но работа интересная и начало положено: сложный сетапы приходят на смену слепой генерации синтетики.
Ждем полноценный пейпер и опенсорс.
🟡Блогпост (facebookresearch.github.io/R…)
#AI #ML #Datasets #Autodata #RAMTeam
1
2
66

May 2
[미국 4월 소매판매 종합]
미래에셋 자동차 김진석
▪️전체: 138.0만대(-5.5%YoY)
영업일 26일, 전년비 동일
4월 SAAR 판매 1,611만대
(-5.7%YoY, -1.4%MoM)
25년 1,636만대( 2.0%)
(이하 %YoY, %p MoM)
HEV: 22.3만대( 18.2%)
침투율 16.2%( 1.2%p)
BEV: 7.8만대(-21.7%)
침투율 5.7%(-0.3%p)
PHEV: 1.5만대(-53.9%)
침투율 1.1%( 0.2%p)
▪️현대차그룹 종합
점유율: 11.5%
(-0.4%pMoM, 0.4%pYoY)
현대차: 86,513대(-1.5%)
점유율: 6.3%
(-0.2%pMoM, 0.3%pYoY)
HEV: 21,496대( 51.7%)
BEV: 4,779대(-8.4%)
25년 전체 판매 7.9%
기아: 72,703대(-2.8%)
점유율: 5.3%
(-0.2%pMoM, 0.1%pYoY)
HEV: 18,962대( 97.5%)
BEV: 2,407대( 65.2%)
25년 전체 판매 7.0%
텔루라이드 FMC 2월
텔루라이드 HEV 3월
▪️인센티브 종합
산업 $3,398(-4%M, 4%Y)
현대차 $2,848( 7%M, -9%Y)
기아 $3,129( 3%M, 4%Y)
// 회사 집계와 차이 있음
▪️주요 업체별 점유율 변동
(점유율, %p MoM, %p YoY)
Toyota 16.1%( 1.0%, 0.2%)
Honda 10.0%( 0.7%, 0.5%)
Ford 12.9%( 0.7%, -1.4%)
GM 17.0%( 0.3%, -1.3%)
VW 3.5%( 0.2%, 0.2%)
Benz 2.0%(flat%, 0.3%)
Lucid 0.1%(flat%, flat%)
Rivian 0.3%(flat%, flat%)
JaguarLR 0.6%(flat%, flat%)
Mazda 2.3%(flat%, -0.3%)
BMW 2.6%(-0.1%, 0.3%)
Subaru 3.8%(-0.1%, flat%)
Geely 0.7%(-0.1%, -0.1%)
기아 5.3%(-0.2%, 0.1%)
Tesla 2.7%(-0.2%, -0.3%)
현대차 6.3%(-0.2%, 0.3%)
현대기아 11.5%(-0.4%, 0.4%)
Mitsubi. 0.3%(-0.4%, flat%)
Nissan 5.8%(-0.6%, 0.8%)
Stellan 7.9%(-0.9%, 0.6%)
▪️주요 업체별 BEV 판매량:
(브랜드 아닌 그룹 기준)
Tesla: 37,550대(-16%)
GM: 10,800대(-29%)
현대기아: 7,186대( 8%)
Toyota: 4,847대( 183%)
현대차: 4,779대(-8%)
Ford: 3,655대(-25%)
Rivian: 3,480대( 17%)
기아: 2,407대( 65%)
BMW: 2,343대(-55%)
Subaru: 2,053대( 116%)
VW: 1,791대(-52%)
Honda: 1,518대(-64%)
Geely: 1,394대(-15%)
Lucid: 840대( 3%)
Benz: 353대(-77%)
Nissan: 330대(-90%)
Stellantis: 156대(-94%)
VinFast: 50대(-83%)
Fisker: 30대(N/A%)
Tata: 9대(-80%)
▪️주요 업체별 HEV 판매량:
(브랜드 아닌 그룹 기준)
Toyota: 113,768대( 9%)
현대기아: 40,458대( 70%)
Honda: 40,177대( 9%)
현대차: 21,496대( 52%)
기아: 18,962대( 97%)
Ford: 14,886대(-31%)
Subaru: 8,899대( 4,511%)
Mazda: 3,116대( 39%)
Stellantis: 2,114대( 1,358%)
GM: 125대(-37%)
Source: Autodata
2
372

Meta AI just released Autodata, a framework that basically turns AI into its own data scientist.
Instead of humans building datasets, AI agents now generate, test, and refine training data themselves. The system figures out the exact sweet spot for challenging data, and the agent actually trains itself to get better at the job over time.
A really interesting look at the future of agent-driven synthetic data.
facebookresearch.github.io/R…
1
9
517

May 2
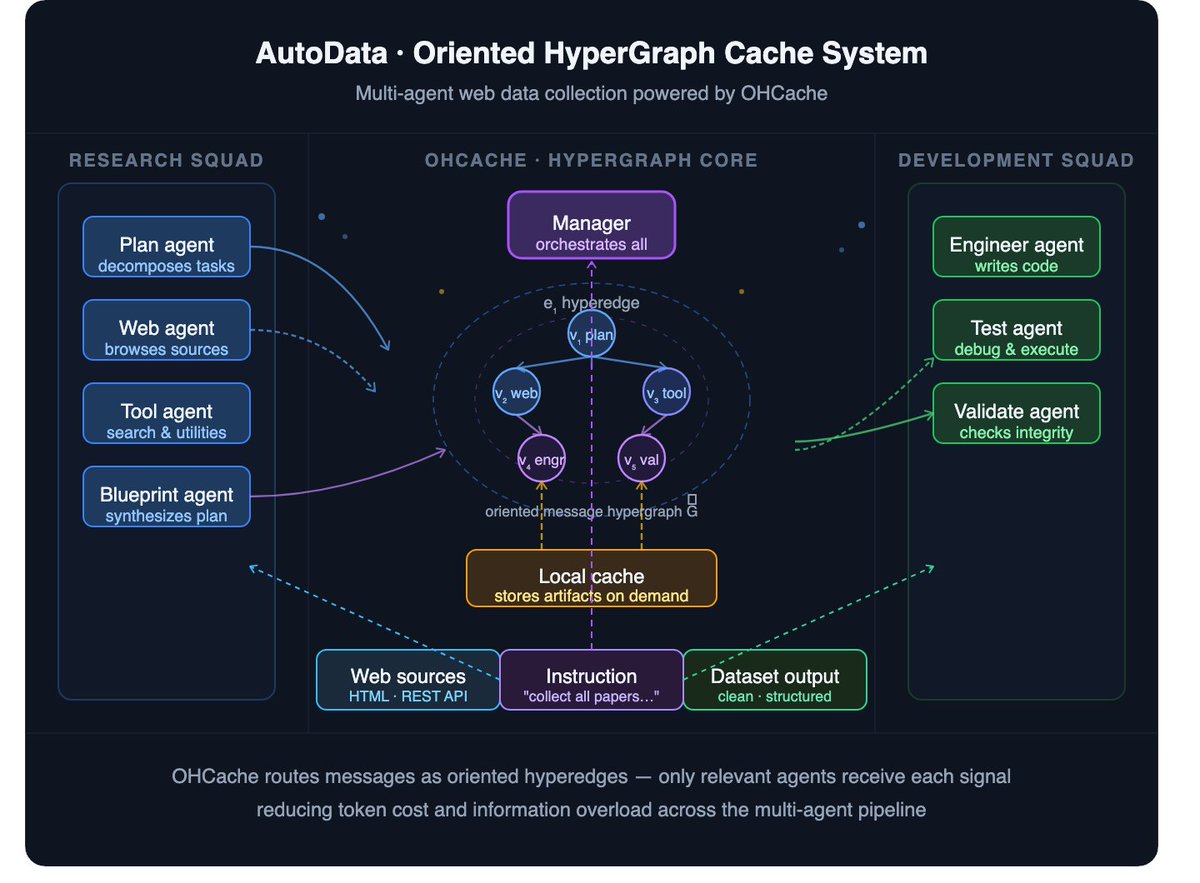
AutoData and the Hypergraph Revolution
AutoData: give it 1 sentence → get a full dataset.
• 91.85 F1 score (vs 69.27 best baseline)
• $0.57/task (vs $2.49)
• Done in 5.6 min (vs 15 )
The secret? Routing AI agent messages like targeted DMs instead of a noisy group chat.
ALT https://medium.com/ai-artistry/autodata-and-the-hypergraph-revolution-how-ai-is-reinventing-the-way-we-collect-web-data-2a4496fcfef0
2
52

May 1
Meta Introduces Autodata: An Agentic Framework That Turns AI Models into Autonomous Data Scientists for High-Quality Training Data Creation
→ Standard CoT Self-Instruct: weak solver 71.4%, strong solver 73.3% — a gap of just 1.9 points
→ Agentic Self-Instruct: weak solver 43.7%, strong solver 77.8% — a gap of 34 points
Here's how it works:
The Core Loop
→ A Challenger LLM generates a training example
→ A Weak Solver and Strong Solver both attempt it
→ A Verifier/Judge scores both
→ If the gap isn't large enough, the agent tries again from a different angle
→ This repeats until the example is genuinely discriminative
Full analysis: marktechpost.com/2026/05/01/…
Technical details: facebookresearch.github.io/R…
@AIatMeta @Meta @jaseweston
15
55
2,546

May 1
Intelligence to tokens -> Tokens to intelligence - no humans required
The future of data operations is going to look _very_ different from how it is today. Autodata paves the way for model training with recursive self-improvement in a post-AGI world. And we have a lot more exciting stuff coming. Exciting times!
May 1

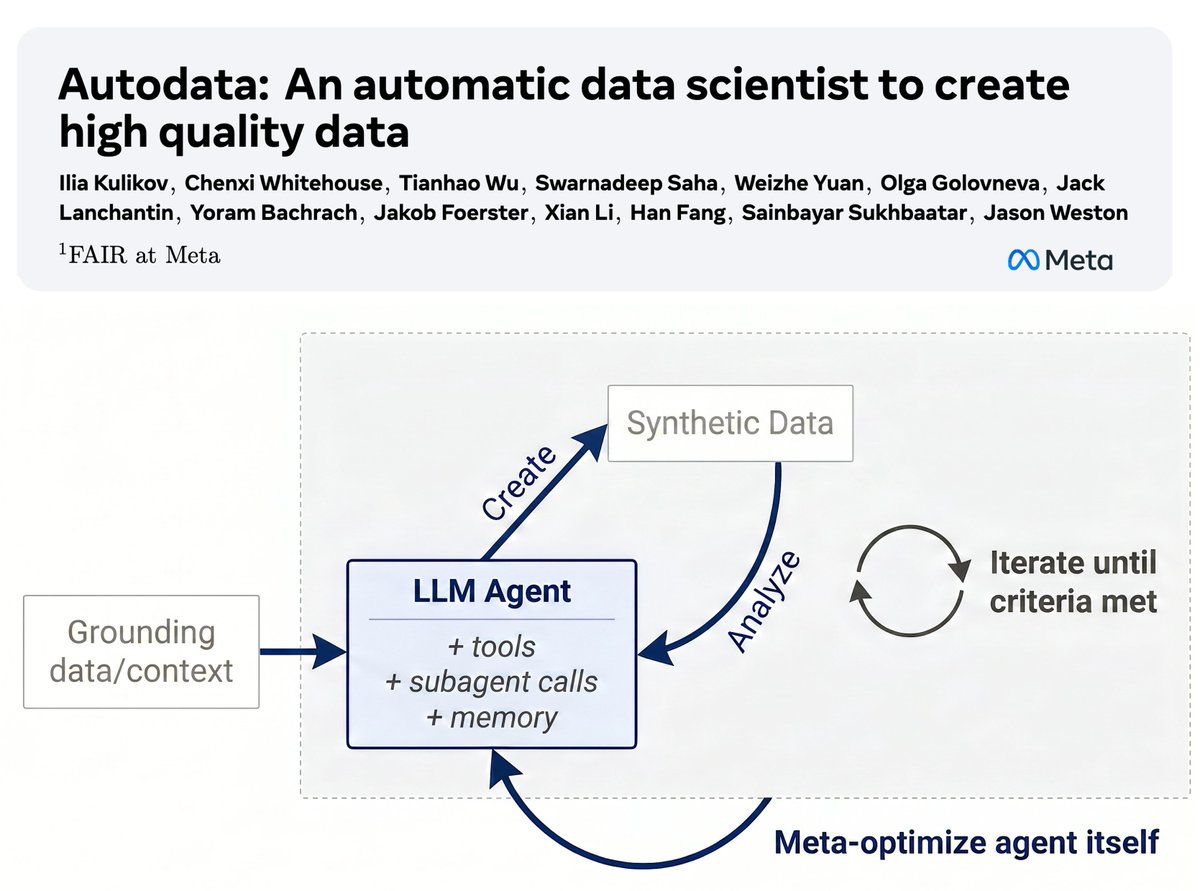
💎Autodata: an agentic data scientist to create high quality data✨
We introduce a method for building agents that create high-quality training & evaluation data.
Key idea: agentic data creation provides a way to *convert increased inference compute into higher quality model training*.
We show how to train (meta-optimize) such a data scientist agent, so that it can create even stronger data.
Our initial study with a specific practical implementation, Agentic Self-Instruct, shows strong gains on scientific reasoning problems compared to classical synthetic dataset creation methods.
Overall, we believe this direction has the potential to change how we build AI data!
Read more in the blog post: facebookresearch.github.io/R…
1
4
539

May 1
💎Autodata: an agentic data scientist to create high quality data✨
We introduce a method for building agents that create high-quality training & evaluation data.
Key idea: agentic data creation provides a way to *convert increased inference compute into higher quality model training*.
We show how to train (meta-optimize) such a data scientist agent, so that it can create even stronger data.
Our initial study with a specific practical implementation, Agentic Self-Instruct, shows strong gains on scientific reasoning problems compared to classical synthetic dataset creation methods.
Overall, we believe this direction has the potential to change how we build AI data!
Read more in the blog post: facebookresearch.github.io/R…
105
621
43,351

Apr 22
Ty, ale to smieszne. Ale ostatnio gazownikowi od auta stawiałem taka maszyne do KSEF, bo dotychczas jechal na jakimś rumplu z autodata na win7.
1
1
2
1,177