
The fastest AI dev news on X — model releases, tools, and what they actually mean
Joined April 2016
- Tweets 13,348
- Following 1,159
- Followers 11,247
- Likes 7,211
3,891 Photos and videos












Marktechpost AI retweeted

Jun 13
Moonshot AI Releases Kimi K2.7-Code: a Coding Model Reporting 21.8% on Kimi Code Bench v2 Over K2.6
Here's what's actually in it.
1. It's a coding-focused model built on Mixture-of-Experts, 1T total parameters, 32B active. 256K context window. Open weights under a Modified MIT license on Hugging Face.
2. The benchmark gains are over K2.6 (and company-reported)→ 21.8% on Kimi Code Bench v2 (50.9 → 62.0) → 11.0% on Program Bench → 31.5% on MLS Bench Lite
3. The efficiency number is the one I'd watch→ ~30% lower reasoning-token usage vs K2.6 Reasoning tokens bill as output. Across a long agent run, that compounds into real cost and latency.
4. Against the closed frontier, here's where it actually landsGPT-5.5 leads on all six rows. Claude Opus 4.8 leads on five. K2.7-Code beats Opus 4.8 on MCP Mark Verified (81.1 vs 76.4).
5. Pricing is low for high-volume runs→ $0.19 / 1M cached input → $0.95 / 1M cache-miss input → $4.00 / 1M output
Full analysis: marktechpost.com/2026/06/12/…
Kimi code: kimi.com/code?track_id=4fe13…
API: platform.kimi.ai/
Model weight: huggingface.co/moonshotai/Ki…
@Kimi_Moonshot
4
5
52
34,965
Databricks Open-Sources Omnigent: The "Meta-Harness" Layer for AI Agents
Juggling multiple AI agent frameworks like Claude Code, Codex, or Pi often means dealing with fragmented environments, manual context switching, and fragile prompt-based guardrails.
To solve this, Databricks team has built Omnigent (under the Apache 2.0 license)—a powerful meta-harness built that standardizes how we compose, govern, and share AI agents.
If you run more than one coding agent, it's worth a look.
Quick framing: a harness is the wrapper that turns a model into an agent — Claude Code, Codex, Pi. Omnigent sits one level above them.
Here are takeaways:
1. One layer over every harness → Claude Code, Codex, Pi, and custom YAML agents in the same session → Swap a harness or model with a one-line change → The same session is reachable from terminal, web, desktop, and phone
2. Control through policies, not prompts → A cost policy can pause an agent after every $100 it spends → A contextual policy can require approval to git push after an npm install → Its OS sandbox injects secrets like a GitHub token only at the egress proxy
3. Collaboration that isn't copy-paste → Share a live agent session by URL → Teammates watch it work, comment on files, co-drive, or fork the conversation
4. Two example agents ship with it → Polly: delegates to coding sub-agents in parallel git worktrees, then routes each diff to a reviewer from a different vendor than the writer → Debby: sends every question to both Claude and GPT and lets them debate
It's Apache 2.0
Full analysis: marktechpost.com/2026/06/13/…
Repo: github.com/omnigent-ai/omnig…
Technical details: databricks.com/blog/introduc…
We have created a small demo to show how the research works: ai-paper-demos.vercel.app/om…
@databricks @DbrxMosaicAI
15
61,107
The US government ordered Anthropic to disable its two most capable models. Three days after launch, Claude Fable 5 and Mythos 5 went dark for everyone.
Here's what actually happened:
1. The order→ Arrived June 12, 5:21pm ET, as an export control directive → Cited national security authorities → Banned access for any foreign national, inside or outside the US
2. Why both models went fully offline: Anthropic can't separate foreign nationals from US users in real time. So it disabled Fable 5 and Mythos 5 for all customers. Every other Claude model, including Opus 4.8, stays online.
3. The trigger→ Another company claimed it jailbroke Mythos (per Axios) → The administration had earlier tried to delay the launch → Anthropic declined, and the letter followed
4. Anthropic's response: The company is complying but disputing the rationale. It calls the cited jailbreak narrow and non-universal. It says the same capability is widely available elsewhere, including OpenAI's GPT-5.5.
5. Why builders should care→ Calls to claude-fable-5 now return errors → Route to Opus 4.8 as a fallback for now → A government can pull a live model by directive
This looks like the first government-forced takedown of a publicly deployed frontier model.
Full analysis: marktechpost.com/2026/06/13/…
Anthropic's blog: anthropic.com/news/fable-myt…
#AI #Anthropic #ClaudeAI #AIPolicy #MachineLearning
1
11
211
Marktechpost AI retweeted
Jun 12
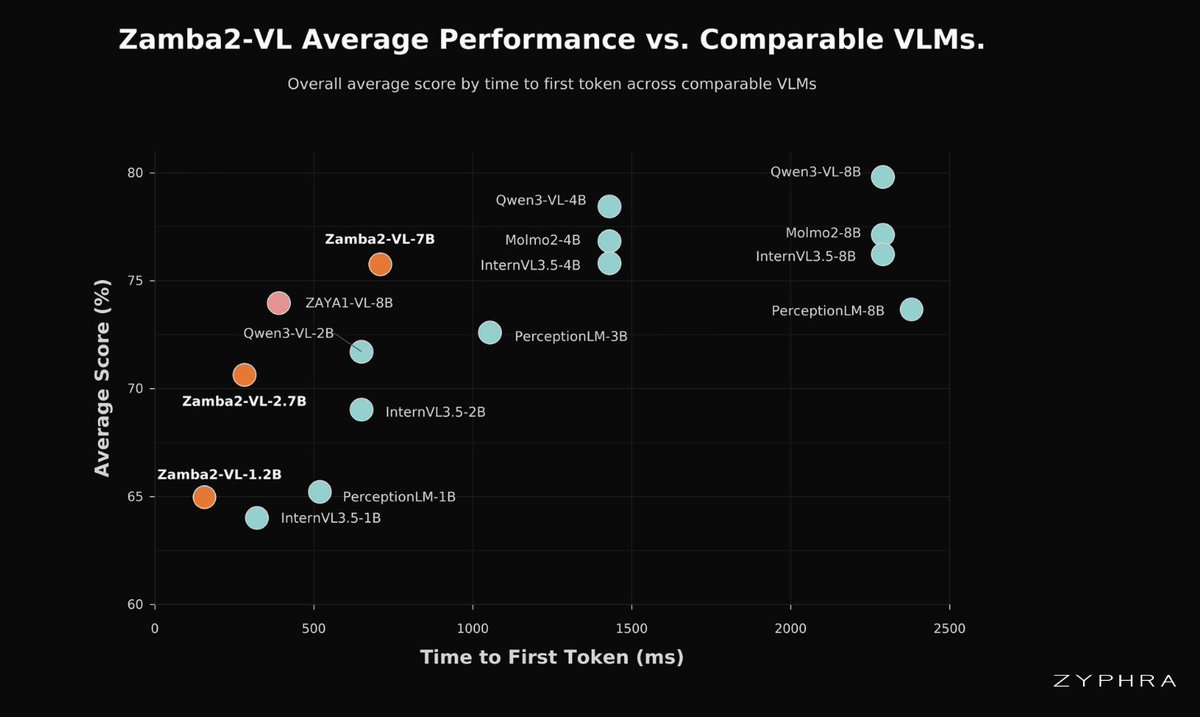
Zyphra Released Zamba2-VL: Hybrid Mamba2–Transformer Vision-Language Models That Cut Time-to-First-Token by About an Order of Magnitude
It's a family of open vision-language models that swaps the usual dense Transformer backbone for a hybrid one.
Here's what is super interesting
1. The architecture is the actual storyMost open VLMs put a dense Transformer under the vision encoder. Zamba2-VL uses Zamba2 — Mamba2 state-space layers carry most of the compute, with a few shared transformer blocks (each with a per-layer LoRA adapter) kept for in-context retrieval.
2. The payoff is latency, not leaderboards→ Near-linear-time prefill instead of quadratic attention → Fixed-size recurrent state instead of a growing KV cache → Roughly an order-of-magnitude lower time-to-first-token on a 32k-token prefill
The gap is widest at 1.2B and 2.7B — the sizes that matter for on-device and edge.
3. It's competitive, not dominant — and they show where it lags→ Strong on counting: Zamba2-VL-1.2B hits 62.5 on PixMoCount (InternVL3.5-1B: 32.8) → DocVQA holds up at 90.9 for the 2.7B model → But it trails larger models on MMMU (37.7) and MathVista (51.0)
4. Fully open→ 1.2B, 2.7B, 7B under Apache 2.0 → Weights and inference code on Hugging Face and GitHub
Full analysis: marktechpost.com/2026/06/12/…
Model card: huggingface.co/collections/Z…
Repo: github.com/Zyphra/transforme…
Technical details: zyphra.com/our-work/zamba2-v…
@ZyphraAI
2
16
740
Marktechpost AI retweeted
Jun 10
Anthropic just released Claude Fable 5 and Claude Mythos 5.
Both sit in a new tier called Mythos-class, above the Opus class.
Here is what is worth learning:
1. Same model, two products
→ Fable 5 and Mythos 5 share one underlying model
→ Fable 5 ships with safety classifiers for general use
→ Mythos 5 lifts cyber safeguards, limited to Project Glasswing
2. The capability claims
→ Anthropic reports state-of-the-art on nearly all tested benchmarks
→ Stripe ran a 50M-line Ruby migration in a day
→ Strongest gains show up on long, complex tasks
3. How the safeguards work
→ Flagged requests fall back to Claude Opus 4.8
→ Coverage: cybersecurity, biology and chemistry, distillation
→ Fallback triggers in under 5% of sessions
4. What matters for your integration
→ 1M token context window, up to 128k output tokens
→ Adaptive thinking is always on, raw reasoning never returned
→ Refusals return HTTP 200 with stop_reason: refusal
5. Pricing and access
→ $10 per million input, $50 per million output
→ Less than half the price of Mythos Preview
→ Included on paid plans through June 22, then usage credits
Full breakdown: marktechpost.com/2026/06/10/…
Launch sentiment: I tracked 40 most trending posts across X, Hacker News, and LinkedIn and here is an interactive dashboard worth checking: ai-paper-demos.vercel.app/my…
Technical details: anthropic.com/news/claude-fa…
Docs: platform.claude.com/docs/en/…
@claudeai @AnthropicAI
2
1
34
203,188
Marktechpost AI retweeted

Jun 11
Gemma 4 now runs 2x faster with MTP GGUFs! Run locally on just 6GB RAM. ⚡️
MTP enables Google Gemma 4 run ~1.4–2.2× faster with no accuracy loss.
Gemma 4 12B MTP can run at 162 t/s vs. 52 t/s without MTP. 31B reaches 101 t/s.
GGUFs Guide: unsloth.ai/docs/models/mtp

60
252
2,144
209,380
Marktechpost AI retweeted
Jun 11
Cohere just released its first coding model named ‘North Mini Code’
It has 30B parameters. Only 3B Active Parameters for Agentic Coding
The minimum to run it? A single H100.
Five things stand out:
𝟭. 𝗧𝗵𝗲 𝘀𝗽𝗮𝗿𝘀𝗶𝘁𝘆 𝘁𝗿𝗶𝗰𝗸 North Mini Code is a sparse mixture-of-experts model. → 30B total parameters, 3B active per token → 128 experts per block; the router picks 8 → So roughly 6% of experts run on any token → Small active compute, large total capacity
𝟮. 𝗕𝘂𝗶𝗹𝘁 𝗳𝗼𝗿 𝗿𝗲𝗮𝗹 𝗲𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴, 𝗻𝗼𝘁 𝗷𝘂𝘀𝘁 𝗰𝗵𝗮𝘁 → Sub-agent orchestration → Systems architecture mapping → Code reviews and terminal tasks → Native tool use and interleaved thinking → 256K context, 64K max output
𝟯. 𝗧𝗵𝗲 𝘀𝗽𝗲𝗲𝗱 𝗻𝘂𝗺𝗯𝗲𝗿𝘀 (𝗖𝗼𝗵𝗲𝗿𝗲'𝘀 𝗼𝘄𝗻) → Up to 2.8x output throughput vs Devstral Small 2 → 30% better inter-token latency → 33.4 on the Artificial Analysis Coding Index Always re-test on your own workload.
𝟰. 𝗛𝗼𝘄 𝘁𝗼 𝗿𝘂𝗻 𝗶𝘁 → Minimum: one H100 at FP8, BF16 weights → Serve with vLLM; trained for OpenCode → Quantized for Ollama, LM Studio, llama.cpp → Also on Cohere API, Model Vault, OpenRouter
𝟱. 𝗧𝗵𝗲 𝗰𝗮𝘁𝗰𝗵 The blog says Apache 2.0. The Hugging Face card adds a non-commercial, acceptable-use note. → Read both before you ship commercially.
The bigger signal: capable coding models are shrinking.
A single-GPU, open-weight agent changes who can self-host.
Full analysis: marktechpost.com/2026/06/11/…
Model weight: huggingface.co/CohereLabs/No…
Technical details: cohere.com/blog/north-mini-c…
@cohere
1
2
16
10,169
Marktechpost AI retweeted
Jun 10
𝗚𝗼𝗼𝗴𝗹𝗲 AI 𝗷𝘂𝘀𝘁 𝗿𝗲𝗹𝗲𝗮𝘀𝗲𝗱 𝗗𝗶𝗳𝗳𝘂𝘀𝗶𝗼𝗻𝗚𝗲𝗺𝗺𝗮 — 𝗮𝗻 𝗼𝗽𝗲𝗻 𝗺𝗼𝗱𝗲𝗹 𝘁𝗵𝗮𝘁 𝗴𝗲𝗻𝗲𝗿𝗮𝘁𝗲𝘀 𝘁𝗲𝘅𝘁 𝗶𝗻 𝗽𝗮𝗿𝗮𝗹𝗹𝗲𝗹, 𝗻𝗼𝘁 𝘁𝗼𝗸𝗲𝗻-𝗯𝘆-𝘁𝗼𝗸𝗲𝗻.
Most LLMs today are autoregressive — one token at a time, left to right. DiffusionGemma takes a different path, it replaces token-by-token autoregression with discrete diffusion. Here is how it works:
𝟭. 𝗠𝗼𝗱𝗲𝗹 → 26B Mixture-of-Experts on the Gemma 4 backbone (25.2B total, 3.8B active). → 8 active experts of 128, plus 1 shared. 30 layers, 256K context.
𝟮. 𝗗𝗲𝗰𝗼𝗱𝗶𝗻𝗴 → It denoises a 256-token canvas in parallel, not one token at a time. → Roughly 15–20 tokens are finalized per forward pass. → Google calls the mechanism Uniform State Diffusion.
𝟯. 𝗔𝘁𝘁𝗲𝗻𝘁𝗶𝗼𝗻 → Prefill uses causal attention to ingest the prompt and write the KV cache. → Denoising uses bidirectional attention, so every canvas token attends to all others.
𝟰. 𝗟𝗼𝗻𝗴 𝘀𝗲𝗾𝘂𝗲𝗻𝗰𝗲𝘀 → Block Autoregressive Diffusion commits a finished 256-token block to the KV cache. → A fresh canvas then initializes, conditioned on prior history.
𝟱. 𝗦𝗮𝗺𝗽𝗹𝗶𝗻𝗴 → Entropy-Bounded Denoising with adaptive stopping, max 48 denoising steps. → Low-confidence tokens are re-noised and refined — a self-correction path autoregressive models lack.
𝟲. 𝗣𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝗻𝗰𝗲 𝗮𝗻𝗱 𝗳𝗼𝗼𝘁𝗽𝗿𝗶𝗻𝘁 → Up to 4x faster on dedicated GPUs: 1000 tokens/sec on H100, 700 on RTX 5090. → Fits in 18GB VRAM when quantized. Native NVFP4 support.
𝟳. 𝗟𝗶𝗺𝗶𝘁𝗮𝘁𝗶𝗼𝗻𝘀 → Output quality is below standard Gemma 4; Google recommends Gemma 4 for production. → The speedup applies to local, low-concurrency inference, not high-QPS cloud serving.
Full breakdown with the comparison table: marktechpost.com/2026/06/10/…
Model weight on HF: huggingface.co/google/diffus…
Technical details: blog.google/innovation-and-a…
@GoogleDeepMind @googleaidevs
3
20
2,007
Marktechpost AI retweeted
Jun 9
🚨 Google just dropped Gemini 3.5 Live Translate — a streaming speech-to-speech audio model for real-time interpretation. 🌍🎙️
What makes it wild:
- 70 languages, auto-detected
- Continuous streaming (no turn-taking) — stays just seconds behind you
- Preserves your tone, pitch & pacing in the output
- Audio-only pipeline for strict low latency: 16kHz in → 24kHz out, 100ms chunks
- Configure via Live API: targetLanguageCode echoTargetLanguage
- Every output carries an invisible SynthID watermark
Shipping across the Live API, Google Meet (5 → 70 languages, 2000 combos), and the Translate app. The babelfish is basically here.
Full analysis: marktechpost.com/2026/06/09/…
Model card: deepmind.google/models/model…
@GoogleDeepMind @GoogleAI
#AI #GenAI #Gemini #GoogleAI #SpeechAI #MachineLearning #LLM #VoiceAI #DevTools
1
1
10
338
Marktechpost AI retweeted
Jun 9
A New Study from Harvard and Perplexity Finds AI Agents Perform 26 Minutes of Autonomous Work per Session vs 33 Seconds for Search
The research study compares Perplexity Search and Computer on near-identical queries from the same users (cosine similarity > 0.99). and Yes, the agent is faster...
Three things stood out.
1. Autonomy is now measured in machine time
→ 26 min of autonomous work per session vs 33 sec (48×)
→ Meaningful dissatisfaction: 1.3% vs 2.9% (55% lower)
More autonomy, without losing output quality.
2. The time and cost savings are large but expected
→ 269 → 36 min per matched task
→ 87% less time, 94% less cost (vs a Search Human baseline)
→ $0.16 vs $2.05 per step
3. The part most people will miss: scope, not speed
→ Cross-occupation work: 59% vs 50%
→ Create-level tasks: 50% vs 26%
→ 23% of agent queries hit work the same users never sent to Search
Full analysis: marktechpost.com/2026/06/08/…
Paper: arxiv.org/pdf/2606.07489
Technical details: research.perplexity.ai/artic…
We have created small demo to show how the research works: ai-paper-demos.vercel.app/ag…
@perplexity_ai
5
2
17
62,991
Marktechpost AI retweeted
Jun 8
Xiaomi's MiMo team just pushed a 1-trillion-parameter model past 1000 tokens per second. On commodity GPUs, not custom silicon.
We covered the MiMo-V2.5-Pro-UltraSpeed release, built with the TileRT systems team.
Here's what's actually interesting:
1. The headline number→ 1000 tokens/s decode on a 1T-parameter MoE model → Demos peak near 1200 tokens/s → Runs on a single standard 8-GPU node
2. FP4 quantization, applied selectively→ MXFP4 format, on the MoE Experts only → Other modules keep higher precision (FP8, per TileRT) → QAT keeps capability essentially on par with the original
3. DFlash speculative decoding→ A research-community method using block-level masked parallel prediction → The draft model fills a whole block in one forward pass → Average acceptance length: 6.30 in coding, 5.56 in math/reasoning, 4.29 in agent tasks
4. TileRT handles the systems side→ At 1000 TPS, each operator runs for only microseconds → A Persistent Engine Kernel stays resident on the GPU → Small ops like RMSNorm and RoPE turn into bottlenecks at this scale
5. How it compares→ Cerebras served Kimi K2.6 (1T) at 981 tok/s on custom wafer-scale hardware → Groq runs Kimi K2 (1T) near 200 tok/s on its LPU → MiMo reaches comparable speeds without custom silicon, which is the real story
Full analysis: marktechpost.com/2026/06/08/…
Model weight: huggingface.co/XiaomiMiMo/Mi…
Technical details: mimo.xiaomi.com/blog/mimo-ti…
@XiaomiMiMo
3
19
118
42,908