
GitHub Classroom was a lifesaver for educators, especially in places like India.
Shutting new sign-ups feels like a step back for coding education.
Likely reasons?
❗️ It’s been in maintenance mode for a while with persistent bugs, scaling challenges, and limited updates, making it tough to sustain long-term.
⚡️Good news: there are solid close alternatives already:
Codio → GitHub’s official partner with seamless GitHub repo integration, autograding, browser-based IDEs, and migration tools. Free for instructors to start.
Classroom 50 (by Fifty Foundation) → Free & open-source, built on Harvard CS50’s proven workflow. CLI web interface for assignments, GitHub Actions autograding, and submissions. Launching soon, perfect Git-native replacement.
Quick DIY options: GitHub template repos manual invites, or simple scripts for repo provisioning.
Hoping these partners deliver the reliability Classroom deserved.
What’s everyone switching to?
Any strong recommendations for assignment management student repos?
#GitHubClassroom #CodingEducation #CS #teaching
1
4
1,678


Apr 17
Discover how to create “Galactic Academy: The Ultimate Exam” with SurveyMars. Build quizzes fast, enable auto-grading, track results, and engage learners instantly.#SurveyMars #TinyExam #OnlineQuiz #AutoGrading #EdTech
3
4
41

Apr 9
i had over 300 submissions for this show so there is a chance the autograding could have glitched. pls pls reach out to me if one of your answers is wrong or vice versa and I can fix it for you!
Apr 9

results for paris are FINALLY in! ⭐️ sorry for the long delay! these were graded to the best of my ability with what I was given - in the event that any of the answers are wrong, I will recalculate all scores!! working on some more edits now🫶🏼 amsterdam submissions will open tmr!
1
4
480

Mar 31
No. Traditional autograding.
Horrific that that's a legitimate term now.
What it is, is it says it gives points based on such and such criteria, I test it for myself, seems to work, I send it in and get 0 points with having no idea why.
Well 52% points now overall, but meh.
1
3
23

Feb 8
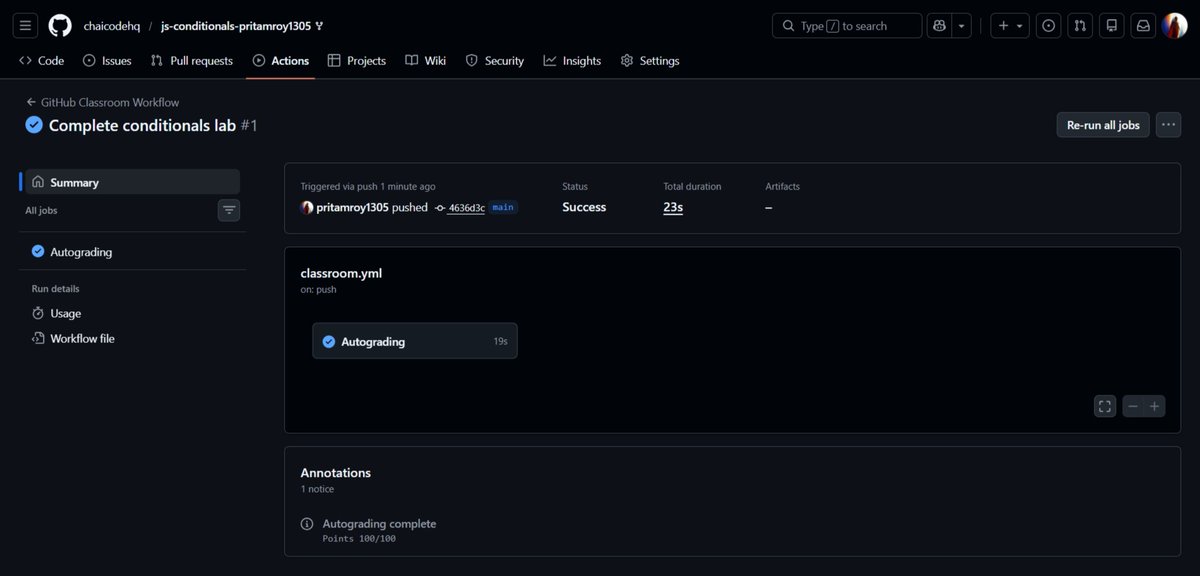
Autograding: Success ✅
All conditions met, all tests passed, 100/100.
Pushed the code, trusted the logic, and let GitHub do the talking.
2
35

git workflowのエクササイズをGitHub Classroomのアサインメントとして課して、その結果をautogradingしてpull requestに自動でフィードバックする仕組みを構築してみている。こういうめんどくさいのもAIで簡単にできるようになった。
3
1,390
Jan 29
How to Auto-Grade Quizzes in SurveyMars and Save 3 Hours on Manual Scoring
#AutoGrading #OnlineQuizzes #EdTechTools #TeacherProductivity #SurveyMars
3
5
38

15 Dec 2025
Upload. Grade. Generate — Done!
SKUUNI makes exam assessment and report cards fast, accurate, and stress-free for schools.
Sign up and simplify exam reporting.
#SKUUNI #EdTech #ExamSeason #AutoGrading #SchoolAdmin #Teachers

4
4
85

24 Nov 2025
What are your thoughts on teachers using LLM-based systems for autograding? I see these getting advertised and deployed around our parts more and more. Personally not a fan for human and technical reasons.
3
8
3,399

10 Nov 2025
I'm teaching a new "Intro to Modern AI" course at CMU this Spring: modernaicourse.org. It's an early-undergrad course on how to build a chatbot from scratch (well, from PyTorch). The course name has bothered some people – "AI" usually means something much broader in academic contexts – but I think the time has come where the first thing that many students interested in AI should see is how the AI they are familiar with actually works (because it's really simple!) The more people who understand it the better.
I'll be trying to put as much material as I can that we develop online (assignments autograding, hopefully lecture videos), though as a first-time course there are also likely to be some bumps along the way. Hopefully it becomes a good resource over time, though.
Feedback welcome.
51
244
2,158
614,480

4 Nov 2025
Unbelievably detailed new paper from DeepMind on benchmarks and autograders they used on IMO Gold journey.
For me main takeouts are:
- autograding can achieve ~90% accuracy even on long and difficult reasoning
- DeepThink is quite behind IMO Gold model on very difficult problems

11
64
598
45,734

19 Sep 2025
ty! the funny thing is that it worked so terribly slowly because i obv didn't have enough time to implement tensors with autograding, just scalars, which were being placed alone in those massive tiles used in operations, basically wasting 99.9% of the compute
26
1,042

5/ The npm package has been significantly improved! So you can run Pyret on your command line if you really want to (or need to, e.g., for autograding). ↵
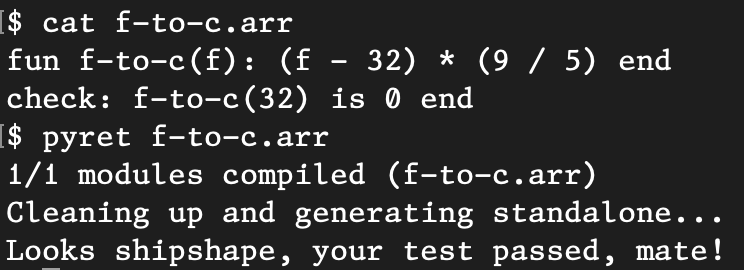
ALT Screenshot showing a program and its execution completely on the command line.
1
3
187

i was running an autograding script, checking out all my students repos, running a grading script & then pushing up results
this semester we are going to github actions and my commits are gonna drop like a stone
1
11
1,149

14 Aug 2025
🚨 Excited to share our new preprint benchmarking OpenAI’s GPT-5 series for ophthalmology question answering.
Using the AAO BCSC dataset, we tested GPT-5 (including mini & nano) across four reasoning levels vs three older LLMs. GPT-5 with high reasoning scored an impressive 96.5%, ranking first in our LLM arena for both accuracy and justification quality. The most cost-efficient configuration was GPT-5-mini with low reasoning. We also introduce a scalable new method for evaluating long-form answers using LLM-as-a-judge autograding.
🔗 arxiv.org/abs/2508.09956
@DanielMiladMD @SumitSharmaMD @pearsekeane @YihTham

4
9
1,153

27 Jul 2025
🤖🛡️ 𝙀𝙭𝘾𝙮𝙏𝙄𝙣-𝘽𝙚𝙣𝙘𝙝: 𝙀𝙫𝙖𝙡𝙪𝙖𝙩𝙞𝙣𝙜 𝙇𝙇𝙈 𝙖𝙜𝙚𝙣𝙩𝙨 𝙤𝙣 𝘾𝙮𝙗𝙚𝙧 𝙏𝙝𝙧𝙚𝙖𝙩 𝙄𝙣𝙫𝙚𝙨𝙩𝙞𝙜𝙖𝙩𝙞𝙤𝙣 🛡️🤖
#for_ai_scientists
#for_ai_researchers
#for_ai_architects
#did_you_know_that researchers from Penn State University, Microsoft Security AI Research, Tsinghua University & AG2 AI spun up a fully-interactive MySQL playground stocked with 57 Azure-Sentinel log tables and 589 LLM-generated questions-all rooted in 8 simulated multi-stage attacks-to benchmark how well agents can hunt threats end-to-end?
🧠✨ 𝙒𝙝𝙖𝙩'𝙨 𝙉𝙚𝙬?
➊ Bipartite Incident Graph → QA Pipeline. Alerts & entities form a graph; LLMs walk edges to craft grounded Q & As-with deterministic answers and step-wise solution paths.
➋ SQL-as-Action RL Environment. Agents issue SQL, get rows/errors back, and earn discounted partial rewards for every hop they correctly uncover.
➌ Fine-grained Autograding. GPT-4o judge string checks award credit even when an agent finds only part of the kill-chain-perfect for RL training.
📊🚀 𝙆𝙚𝙮 𝙁𝙞𝙣𝙙𝙞𝙣𝙜𝙨
- Task difficulty: mean reward over 12 top models = 0.249; best (o4-mini) hits 0.368.
- Open-source surge: Llama-4 Mav-17B pulls 0.29, rivalling proprietary chat models.
- Alert logs matter: dropping them cuts GPT-4o reward 0.26 → 0.21; alert-only DB soars to 0.46.
- Turns vs payoff: rewards jump steeply up to 15 SQL calls, plateau after 25.
- Prompting tricks: ReAct Reflection lifts GPT-4o from 0.26 → 0.56 (k = 3 trials) at modest extra cost.
🔧📈 𝙒𝙝𝙮 𝙋𝙧𝙖𝙘𝙩𝙞𝙘𝙖𝙡 𝙁𝙤𝙡𝙠𝙨 𝘾𝙖𝙧𝙚
1️⃣ Closer to the SOC floor. Agents must pivot through noisy real-world logs-not canned CTI trivia.
2️⃣ Process-level rewards. Perfect playground for RLHF/RLAIF: every intermediate IoC is labeled.
3️⃣ Extensible by design. Drop in new log tables & regenerate Qs automatically-benchmark grows with your SIEM.
🔭🌐 𝙉𝙚𝙭𝙩 𝙎𝙩𝙚𝙥𝙨
- RL training loops leveraging path-based partial credit.
- Alert-free scenarios to test zero-day hunting.
- Graph-aware agents that query via paths, not brute-force SQL.
Thanks to Yiran Wu, Mauricio Velazco, Andrew Zhao, Manuel R. Meléndez Luján, Srisuma Movva, Yogesh R., Quang Nguyen, Roberto Rodriguez, Qingyun Wu, Michael Albada, Julia Kiseleva and Anand Mudgerikar for their research paper:
ExCyTIn-Bench: Evaluating LLM agents on Cyber Threat Investigation
lnkd.in/dpwsn9-i
⭐ Star my repo:
lnkd.in/dxbWyDyW
📬 Stay tuned and subscribe:
lnkd.in/dxt7fYJk
#ai #genai #generativeai #favikon #cloud #agenticai #ExCyTInBench #cybersecurity #threathunting #sql #multiagent #benchmark #llm #cloudcomputing #innovation

2
35

17 Jul 2025
Join the Future of Tech-Enabled Education & #Innovation!
@cdacindia Mumbai invites you to an exciting Online Workshop showcasing two powerful tools designed for educators, developers, and researchers on 24th & 25th July at 3:00pm.
🎓 Parikshak – An advanced online programme grading tool that:
✅ Automates coding exams
✅ Provides smart, intuitive feedback
✅ Detects plagiarism in real-time
A game-changer for institutions conducting large-scale programming assessments!
🔗 NBF Lite – A lightweight Blockchain framework for:
✅ Rapid prototyping
✅ Blockchain-based research
✅ Building #eGovernance and GovTech applications with ease
Based on the National Blockchain Framework – Vishvasya, #NBFLite is the perfect starting point for innovators exploring #Blockchain for public good.
🗓️ Don’t miss this opportunity to experience cutting-edge tools built in India for India's digital future.
📌 Register now: forms.gle/7N7ca3M7Ud6n2wUf6
Let’s code smart. Let’s build secure. Let’s innovate together. 💡
@GoI_MeitY #Parikshak #EdTech #BlockchainIndia #ProgrammingTools #AutoGrading #PlagiarismDetection #Hyperledger #TechForGood #CodeSmart #PrototypeWithBlockchain

4
245

25 May 2025
This is just the first step!
Think: autograding hooks, CI integration, local problem packs, and benchmarking on your own GPUs.
We're constantly building more, follow along and contribute here:
github.com/tensara/tensara-c…
6
213
23 May 2025
Join the Future of Tech-Enabled Education & Innovation!
@cdacindia Mumbai invites you to an exciting #OnlineWorkshop showcasing two powerful tools designed for educators, developers, and researchers:
🎓 Parikshak – An advanced online program grading tool that:
✅ Automates coding exams
✅ Provides smart, intuitive feedback
✅ Detects plagiarism in real-time
A game-changer for institutions conducting large-scale programming assessments!
🔗 NBF Lite – A lightweight Blockchain framework for:
✅ Rapid prototyping
✅ Blockchain-based research
✅ Building e-Governance and GovTech applications with ease
Based on the National Blockchain Framework – Vishvasya, NBF Lite is the perfect starting point for innovators exploring Blockchain for public good.
🗓️ Don’t miss this opportunity to experience cutting-edge tools built in India for India's digital future.
📌 Register now: forms.gle/QRJYsCVnESUEP7Bf9
Let’s code smart. Let’s build secure. Let’s innovate together. 💡
Connect on Facebook: facebook.com/share/p/18fUUzC…
@_DigitalIndia @GoI_MeitY #Parikshak #NBFLite #C_DACMumbai #EdTech #BlockchainIndia #ProgrammingTools #AutoGrading #PlagiarismDetection #Hyperledger #eGovernance #TechForGood #CodeSmart #PrototypeWithBlockchain #InnovationIndia

2
5
434