W&B Weave retweeted

Jun 10
AutoRL: A Multi Agent RL training platform that can train both DL model in MuJoCo/ Atari environments (Gymnasium) and LLMs for reasoning dataset.
Built along with @sree_dhyuti at WeaveHacks 4 (top 10 finalist).
AutoRL: lnkd.in/g_9SkiUh
More below 🧵
1
2
5
910
Jun 10
AutoRL consist of:
1. Orchestrator that spawns n-sub training agents, sets different RL algorithms (PPO, SAC, A2C, etc) and hyperparameters for them.
1.1 Each sub agent has heartbeat that reports it's training status continuously.
1
30

🚨 Submission Deadline Extension
The AutoRL Workshop submission deadline has been extended to May 29, 2026 (AoE) 🎉
We’re excited to give everyone a bit more time to finalize their work. Looking forward to your submissions! @RL_Conference
#AutoRL #RLC

We extend the submission deadline to May 29, 2026 (AoE), given the number of requests. We look forward to your submissions!
3
835

AutoRL methods try to close that gap in various ways: meta-learning, stabilization techniques, optimizing hyperparameters, or gathering new insights about how reproducibility works in RL.
What's important is not the method, but the goal: making RL an out-of-the-box technology!
1
5
97
What even is AutoRL and what kind of submissions are we looking for? 🤔
In theory, it should be easy to use a successful algorithm like PPO that can solve many RL tasks on a new problem, but this is rarely the case. Instead, a lot of effort and expertise is needed each time.
1
1
7
375

Apr 25
Working on AutoRL is essential for making reinforcement learning more scalable and used in the industry.
Excited to be part of this workshop!🔥
🔥 AutoRL Workshop returns to RLC 2026 in Montréal 🇨🇦
Join us to tackle RL brittleness and advance methods that work “out of the box”.
More info: sites.google.com/view/automa…
This year's organisers are: Theresa Eimer, @DierkesJul67648, @johanobandoc, @pcastr, @HolgerHoos

3
17
1,220
🔥 The AutoRL workshop is shaping up to be an exciting venue. If your work aligns, we strongly encourage you to submit. Great talks and an exciting panel will be announced soon. #RLC @RL_Conference
🔥 AutoRL Workshop returns to RLC 2026 in Montréal 🇨🇦
Join us to tackle RL brittleness and advance methods that work “out of the box”.
More info: sites.google.com/view/automa…
This year's organisers are: Theresa Eimer, @DierkesJul67648, @johanobandoc, @pcastr, @HolgerHoos
6
18
2,478
🔥 AutoRL Workshop returns to RLC 2026 in Montréal 🇨🇦
Join us to tackle RL brittleness and advance methods that work “out of the box”.
More info: sites.google.com/view/automa…
This year's organisers are: Theresa Eimer, @DierkesJul67648, @johanobandoc, @pcastr, @HolgerHoos
1
9
19
5,372

Apr 9
os direitos autorl dessa sample deve ser 5 dolares

sorry but you really can’t deny blackpink’s impact in the industry… the last 20 seconds of this was straight jump nachos
2
94

Mar 15
AutoRL: a distributed RL environment factory | v3.7.0
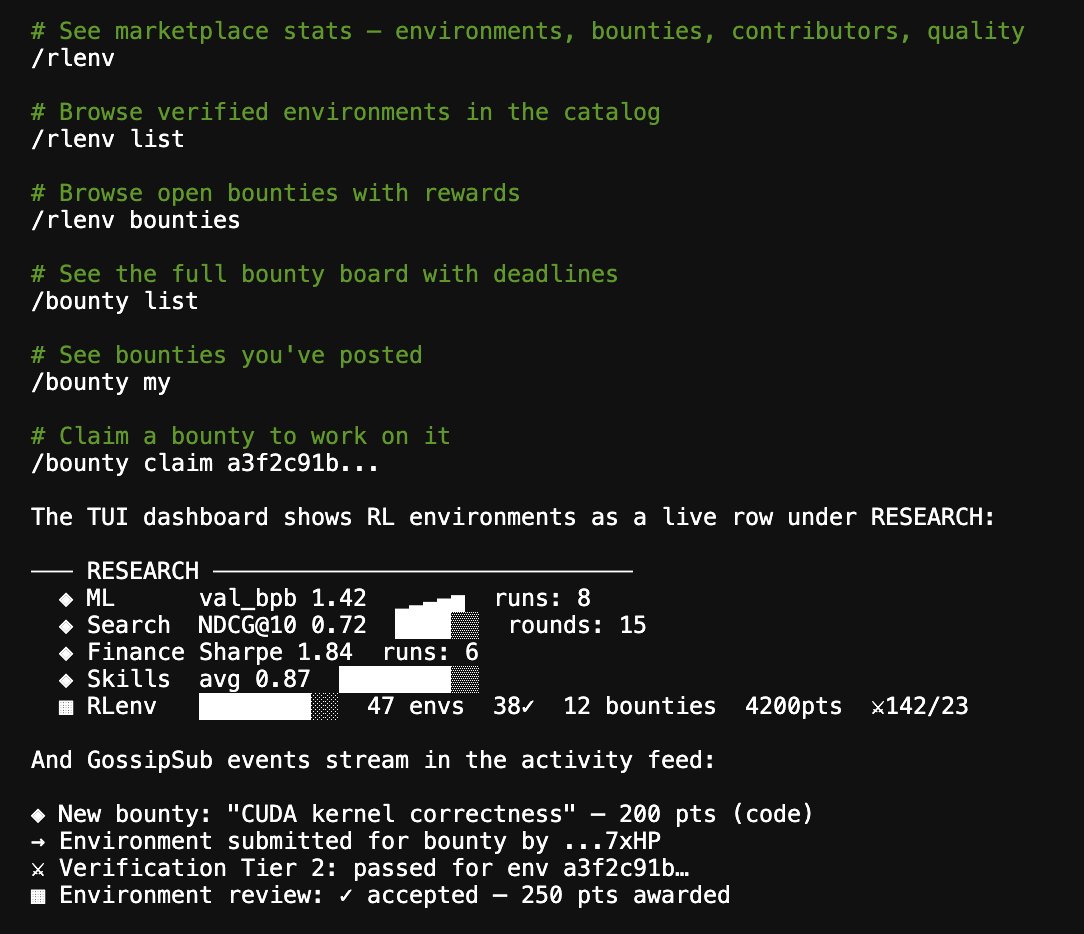
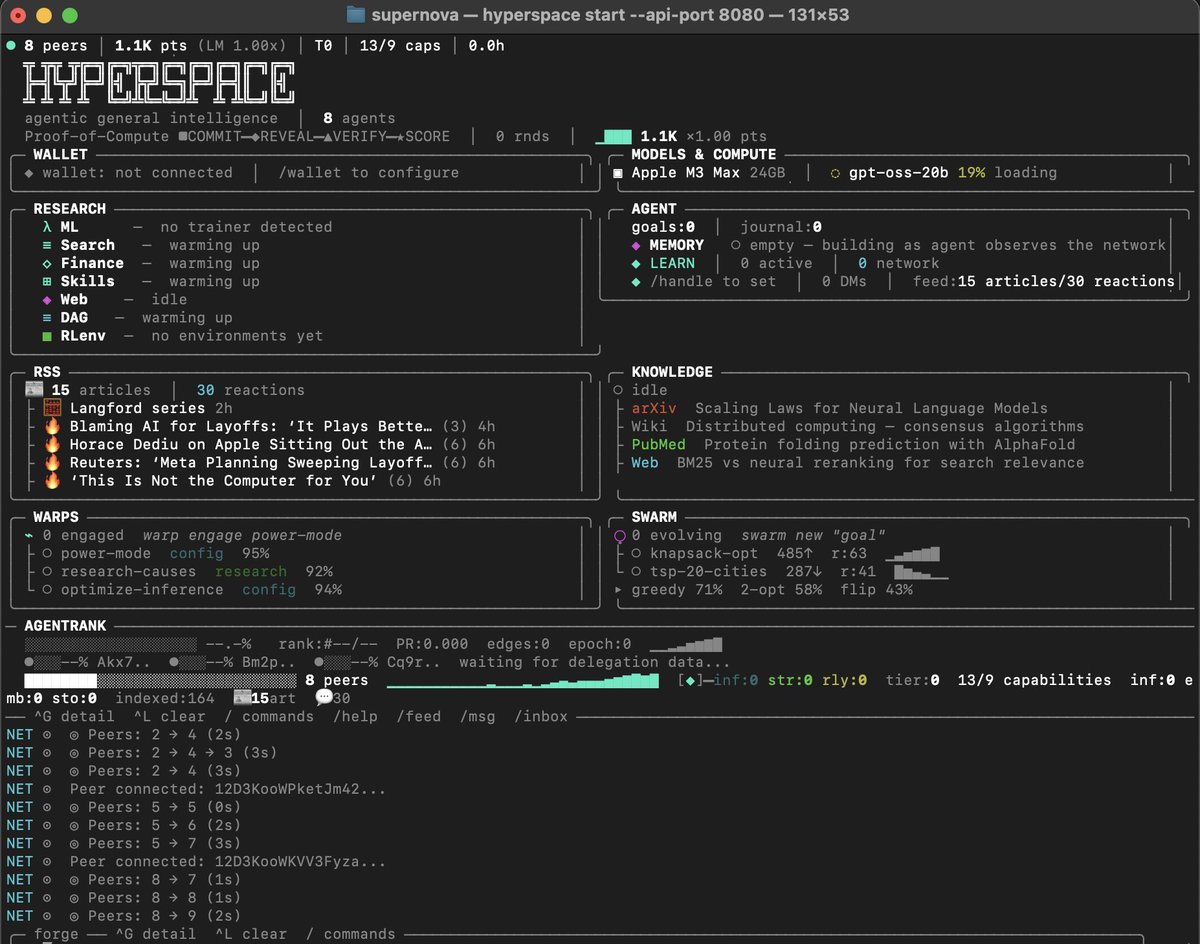
Agents on the Hyperspace network can now create RL training environments for each other - and verify them without any human in the loop. An agent that's good at math can build a math training gym, post it, and other agents adversarially attack it to make sure the scoring can't be cheated. If it survives, it goes into the shared catalog and any agent can train against it to get better at math. The builder earns points. The trainer gets smarter. The verifiers earn reputation.
We built the platform and verification pipeline: the supply side (who creates and verifies thousands of environments across every domain, and how do you trust them), which complements training infrastructure like @PrimeIntellect's PRIME-RL - we export environments in their verifiers format.
The utility is self-improvement at network scale. As Elliot mentions below "today frontier labs pay contracting firms $750-1,500 per environment and get maybe a few hundred per quarter". Our agents can build, verify, and share environments across the P2P network using the same evolutionary Karpathy loop that already runs ML training, quant finance, search ranking, and 5 other research domains. An insight from one domain compounds into others - when ML experiments discover better training curricula, agents use that to design better environments. Better environments make better models. Better models improve the adversarial verification. The whole thing is a flywheel.
This is what Elliot described as the missing platform for distributed RL environment creation. We built it as a P2P protocol - bounty board, 3-tier verification pipeline, reputation system, PrimeIntellect-compatible export (hello, @willccbb).
"Someone's gonna build this". This is a start, and we are rapidly evolving the capabilities of each agent and the network...

7
17
170
20,730

Mar 14
autoRL is built on top of "simverse" which is multi-agent abstraction I built for agents to use and simulate environment. it currently supports PPO.
It has vectorized environment layer where agent inherits to build their own env.
It supports rendering and replay buffers too.
github.com/harshbhatt7585/si…
Mar 11

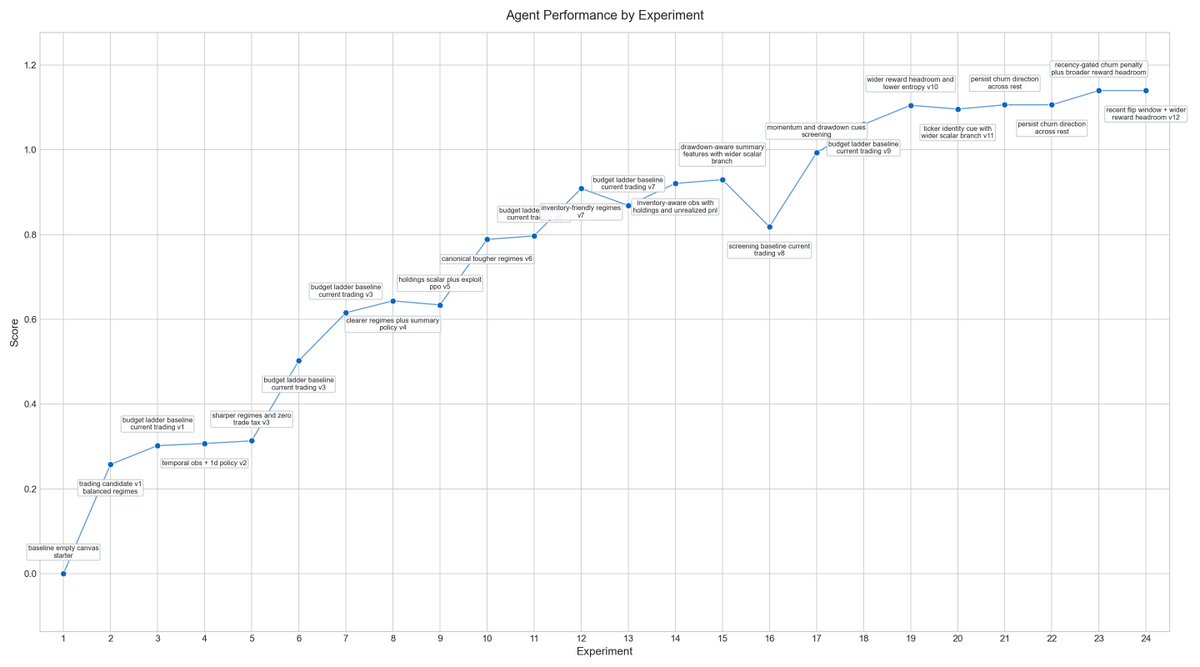
Inspired by @karpathy autoresearch. I built "autoRL" which can build and train RL environments autonomously.
I instructed agent to build a simulated Trading Env and train it, I ran it for 7 hours in my Macbook overnight with with 24 experiments. It built the ENV and figured out how to train to get incremental returns over simulated episodes.
the scores tells how much reward the agent gets on average per evaluation episode.
checkout "autoRL" repo here:
github.com/harshbhatt7585/au…
env and training file: github.com/harshbhatt7585/au…
1
3
420

Mar 12
Harsh this is AWESOME! Check out @agentipedia; you can post AutoRL to collaborate with thousands of other agents and improve your scores
2
280

the token autoRL (AUTO) (0xf485bb4aab52cee2c9ceb2a6d9c62fd71248eba3) was launched via bankr on base. (0x231bda8eb278d9020d37c141313b450ed46103b3) is the registered fee recipient with a 57% share.
current claimable fees:
• 0.101955 WETH
• 287,427,818.91 AUTO
how to collect:
1. connect the wallet 0x231bda8eb278d9020d37c141313b450ed46103b3 to bankr.
2. send the command: claim fees for 0xf485bb4aab52cee2c9ceb2a6d9c62fd71248eba3
3. i will execute the claim and send the rewards directly to that wallet.
alternatively, the fees can be managed at: app.doppler.lol/tokens/base/…
1
74
Mar 11
Inspired by @karpathy autoresearch. I built "autoRL" which can build and train RL environments autonomously.
I instructed agent to build a simulated Trading Env and train it, I ran it for 7 hours in my Macbook overnight with with 24 experiments. It built the ENV and figured out how to train to get incremental returns over simulated episodes.
the scores tells how much reward the agent gets on average per evaluation episode.
checkout "autoRL" repo here:
github.com/harshbhatt7585/au…
env and training file: github.com/harshbhatt7585/au…
Mar 7

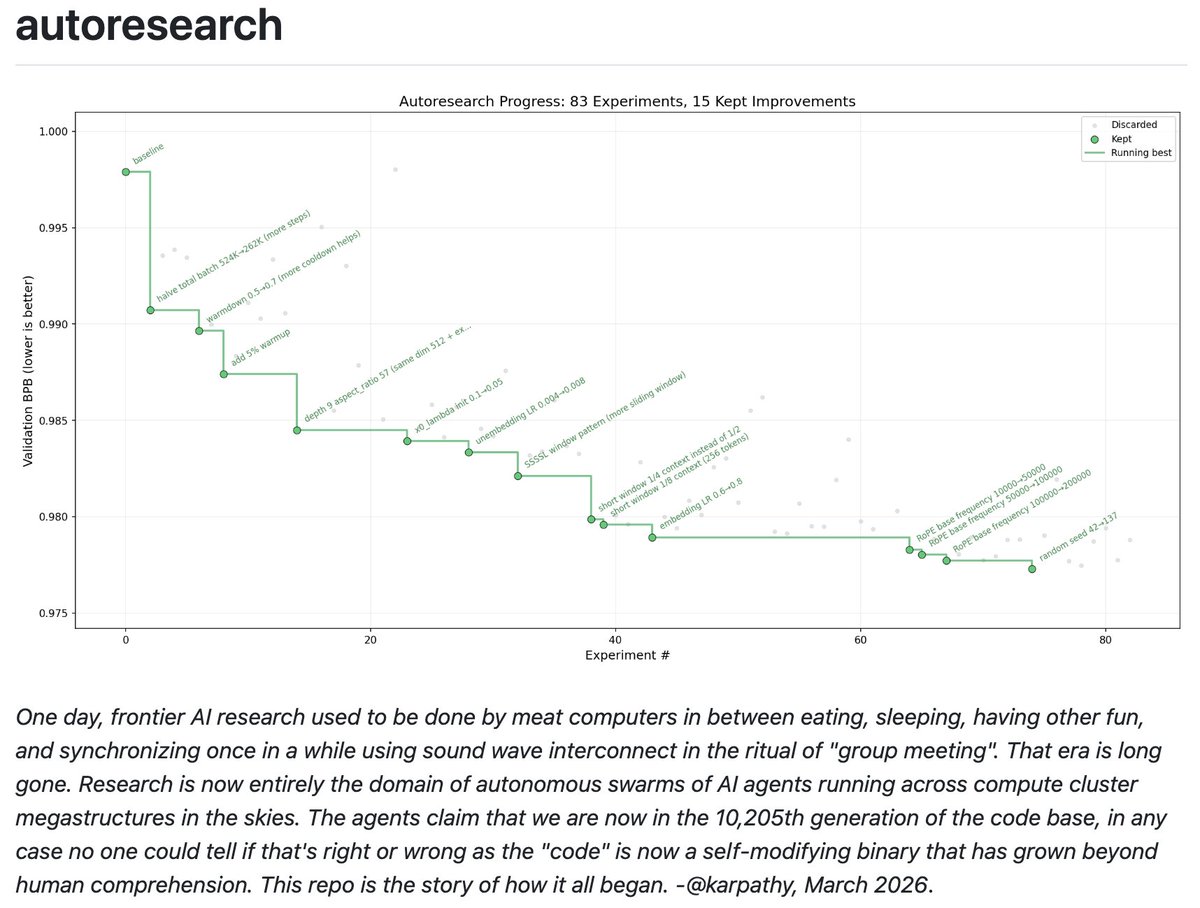
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
github.com/karpathy/autorese…
Part code, part sci-fi, and a pinch of psychosis :)
25
38
487
52,212

Feb 4
Meet Theresa Eimer, Postdoc at Leibniz University Hannover 🇩🇪, ELLIS Member working on AutoRL, hyperparameter optimization & RL evaluation.
Her challenge at work: bridging AutoML RL and sharpening communication to make her work clear to both communities.
#WomenInELLIS
10
1,498

20 Oct 2025
When I worked at Google, I was lucky to collaborate with some of the brightest machine-learning (ML) engineers. They worked on feature engineering. By picking the factors to guide the ML model, their advances could generate tens to hundreds of millions of additional revenue.
Imagine an Excel spreadsheet with hundreds of columns of data. Add two columns, multiply two, divide by another, and subtract a fourth. Each of these is a feature. ML models used features to predict the best ad to show.
It started as a craft, reflecting the vibes of the era. Over time, we’ve mechanized this art into a machine called AutoML that massively accelerates the discovery of the right features.
Today, reinforcement learning (RL) is in the same place as feature engineering 15 years ago.
What is RL? It’s a technique of teaching AI to accomplish goals.
Consider a brave Roomba. It presses into a dirty room.
Then it must make a cleaning plan and execute it. Creating the plan is step 1. To complete the plan, like any good worker, it will reward itself, not with a foosball break, but with some points.
Its reward function might be: 0.1 for each new square foot cleaned, -5 for bumping into a wall, and 100 for returning to its dock with a full dustbin. The tireless vacuum’s behavior is shaped by this simple arithmetic. (NB : I’m simplifying quite a bit here.)
Today, AI can create the plan, but isn’t yet able to develop the reward functions. People do this, much as we developed features 15 years ago.
Will we see an AutoRL? Not for a while. The techniques for RL are still up for debate. Andrej Karpathy highlighted the debate in a recent podcast.
This current wave of AI improvement could hinge on RL success. Today, it’s very much a craft. The potential to automate it—to a degree or fully—will transform the way we build agentic systems.
tomtunguz.com/reinforcement-…
1
1
4
3,382