
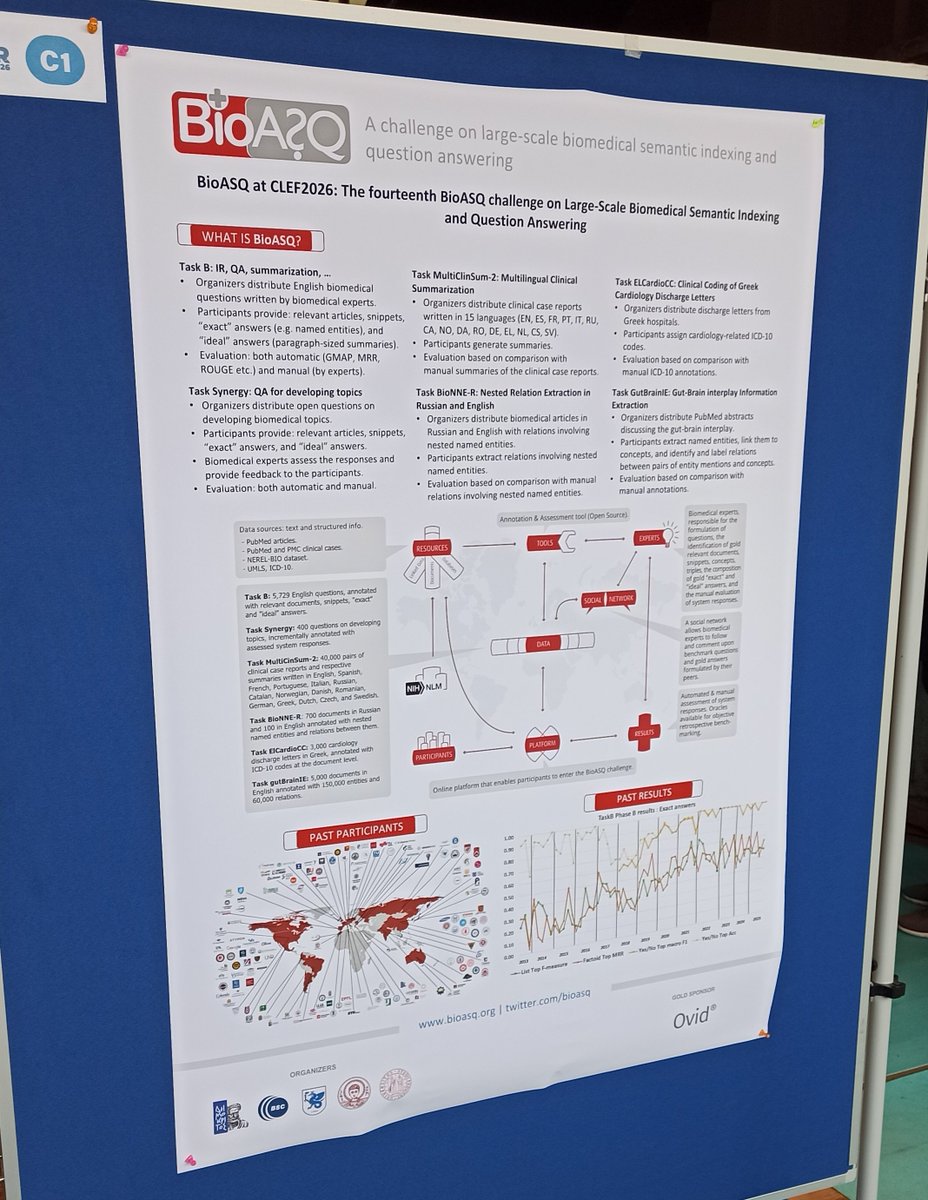
We were happy to present the 14th #BioASQ #CLEF2026 lab on large-scale #biomedical #semanticIndexing and #QuestionAnswering at the 48th European Conference on Information Retrieval #ECIR2026 today!
Paper here: doi.org/10.1007/978-3-032-21…
More info here: participants-area.bioasq.org



2
4
80

Mar 9
8/ OpenMed_MedO1
40K diverse verifiable problems: lab values, surgery, pediatrics, emergency medicine.
Trains exact-answer extraction across broad medical domains. Boosts BioASQ and HealthBench.
app.primeintellect.ai/dashbo…
1
5
174

Feb 5
This paper is awesome! I love the reframing of synthetic question generation for training or evaluating search models as a *Search Environment* -- a great framing for works like InPars, Promptagator, UDAPDR, ... with the new environment-first framing of AI systems.
"For the 3B LLMs, RL improves over RAG by 9.6 and 5.5 points for PaperSearchQA and BioASQ respectively. For 7B models, the difference is 14.5 and 9.3." 🚀
Congratulations @jmhb0 and team! 🎉
Feb 4

Check out PaperSearchQA, which I'll present at EACL in Morocco this March! We built an RL training environment for teaching LLMs to search and reason over scientific papers. 60k question-answer pairs 16M papers to search over benchmarks. RL training improves the model.

2
2
8
690
Overcoming Topology Bias and Cold-Start Limitations in Drug Repurposing: A Clinical-Outcome-Aligned LLM Framework
1. This new study introduces a novel framework that addresses key limitations in drug repurposing, specifically targeting the issues of topology bias and cold-start scenarios in computational models. The framework leverages a clinical-outcome-aligned approach using large language models (LLMs) to enhance drug repurposing accuracy and robustness.
2. Traditional graph neural networks (GNNs) often struggle with inductive generalization and popularity bias, failing in cold-start scenarios where new compounds lack prior graph connectivity. The study demonstrates that their proposed DR-SFT model achieves remarkable performance in these challenging settings, with a top-10 precision of 0.80, significantly outperforming GNN baselines.
3. The innovation lies in the integration of clinical trial outcomes as rewards for model optimization. Using Kahneman-Tversky Optimization (KTO), the framework aligns model predictions with real-world clinical utility, effectively filtering out popular but ineffective drug candidates. This clinical alignment results in a top-10 precision of 0.90 in hard-negative tests, showcasing superior discriminative power.
4. Beyond repurposing accuracy, the model also achieves state-of-the-art performance on BioASQ and Chemprot benchmarks, demonstrating enhanced biomedical reasoning and factuality. The study further validates the model's predictions through molecular docking simulations and experimental confirmation, identifying BAY 61-3606 as a novel high-affinity FLT3 binder for acute myeloid leukemia (AML).
5. The research highlights the potential of combining semantic reasoning with clinical outcome alignment to bridge the gap between computational predictions and physical reality. This paradigm shift from structural probability to clinical utility offers a scalable and evidence-grounded path for identifying viable therapeutic candidates.
📜Paper: biorxiv.org/content/10.64898…
💻Code: github.com/cat-tontree/drkto
#DrugRepurposing #LLM #ClinicalAlignment #ComputationalBiology #BiomedicalResearch

2
14
1,825
Jan 16
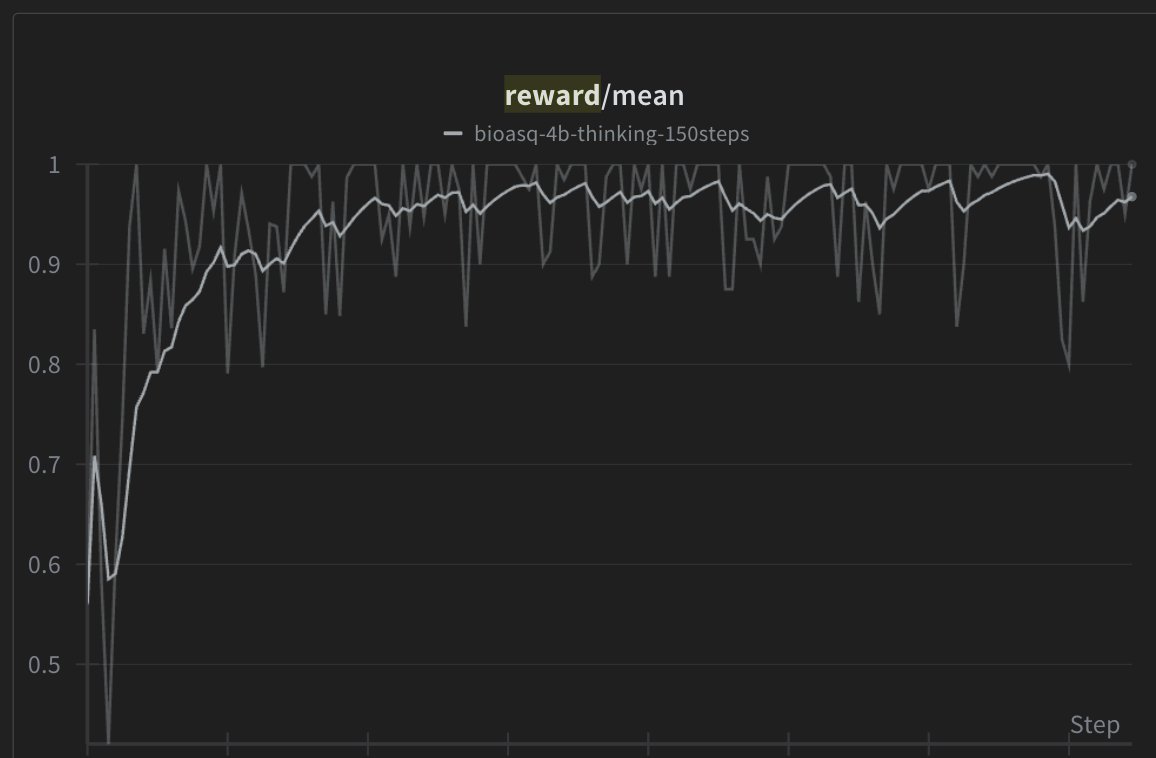
BioASQ: Evidence-based medicine through biomedical QA.
Built on PubMedQA, models learn to answer biomedical questions using peer-reviewed literature, bridging research and clinical practice.
Training AI to reason with scientific evidence, not hunches.
Jan 15

🚨 Another day, another drop!!!
I am releasing 8 new medical RL environments on Prime Hub!
From differential diagnosis to drug safety, these environments cover the full spectrum of clinical AI challenges.
Thread 🧵👇

1
3
9
800
Jan 15
4/ BioASQ - Biomedical Question Answering
Evidence-based medicine powered by PubMedQA.
Models learn to answer biomedical questions using peer-reviewed literature, bridging the gap between research and clinical practice.
The foundation for AI-assisted medical research.
1
1
5
423
The @BioASQ Task Synergy on #QuestionAnswering for developing topics is on!
Find the 1st round here participants-area.bioasq.org…
Submitting results will remain active for three days, until Thursday, January 15th, at 13:00 GMT.
#eHealth #LLMs #CLEF2026

2
4
91
Get ready for the new version of the #BioASQ Synergy task on #InformationRetrieval and #QuestionAnswering for developing #Biomedical topics, in the context of BioASQ14! Task guidelines: participants-area.bioasq.org… #eHealth #clef2026 #LLMs

1
3
96
The 14th #BioASQ workshop will be held at #CLEF2026, Sept. 21-24, 2026, in Jena, Germany.
This year, BioASQ offers six tasks in six languages! More details on bioasq.org
Register for the BioASQ tasks here: clef-labs-registration.dipin…
#eHealth #clef_initiative #LLMs

3
2
115

8 Oct 2025
Small open models can answer medical questions as well as closed models when paired with retrieval and ensembling.
In BioASQ 13B test batches, open ensembles tied or beat proprietary systems.
Each question comes with PubMed snippets, so the system first picks useful evidence then writes a clean answer.
It ranks all snippets by similarity to the question, keeps the top 10, and sends only those to the model.
For factoid and list questions, it adds 3 past examples to teach the format, while yes or no and summary use 0-shot prompts.
It forces a structured JSON style using a small rule set, which keeps answers tidy and easy to parse.
It combines multiple models, uses majority vote for yes or no, and merges repeated items for facts and lists.
Mixing families like Phi, Qwen, Gemma, and Mistral helps because their mistakes rarely overlap.
Across batches, small open models, including 4-bit versions, stayed competitive with closed models, and full open models did even better.
Teams handling sensitive medical data can self-host small models with retrieval and light ensembling and still get strong quality.
----
Paper – arxiv. org/abs/2509.18843
Paper Title: "Are Smaller Open-Weight LLMs Closing the Gap to Proprietary Models for Biomedical Question Answering?"

4
4
23
4,307

25 Sep 2025
Are Smaller Open-Weight LLMs Closing the Gap to Proprietary Models for Biomedical Question Answering?
1. This study explores whether smaller open-weight large language models (LLMs) can effectively replace larger closed-source models in biomedical question answering. The authors participated in Task 13B Phase B of the BioASQ challenge and compared several open-weight models against top-performing proprietary ones like GPT-4o and Claude 3.5Sonnet.
2. The researchers used various techniques to enhance question answering capabilities, including retrieving the most relevant snippets based on embedding distance, in-context learning, and structured outputs. For certain submissions, ensemble approaches were utilized to leverage the diverse outputs generated by different models for exact-answer questions.
3. The results demonstrate that open-weight LLMs are comparable to proprietary ones, and in some instances, open-weight LLMs even surpassed their closed counterparts, particularly when ensembling strategies were applied. This suggests that smaller open-weight models have the potential to be competitive in biomedical question answering tasks.
4. The study highlights the importance of utilizing in-context learning and selecting the best snippets for improving the performance of LLMs in biomedical question answering. The authors also experimented with different prompting strategies and found that hand-crafted prompts worked better than automated prompt generation for certain question types.
5. The authors tested multiple models, including Phi-4, Gemma-3-12B, Qwen2.5-14B, and Meditron Phi-4-14B, and found that ensembling methods, especially combining open and closed models, led to improved performance for factoid and list questions. This indicates that integrating diverse LLM families can enhance the overall performance.
6. For summary questions, the open-weight model Phi-4 exhibited promising performance in terms of ROUGE metrics. The authors used a cross-encoder reranking approach to select the best summary from candidate summaries generated by different models, showing the potential of open-weight models in generating high-quality summaries.
📜Paper: arxiv.org/abs/2509.18843
#BiomedicalQuestionAnswering #LargeLanguageModels #OpenWeightLLMs #Ensembling #InContextLearning #BioASQChallenge

2
672

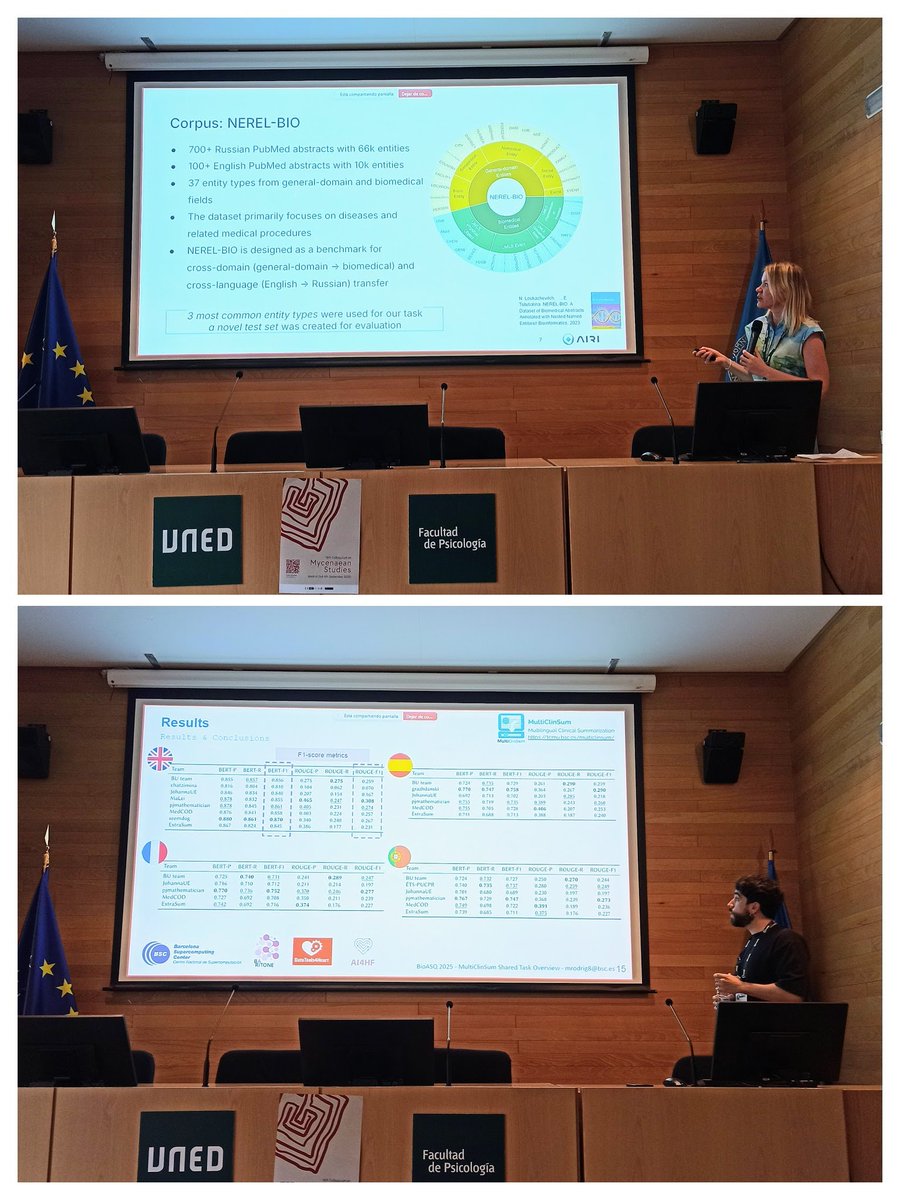
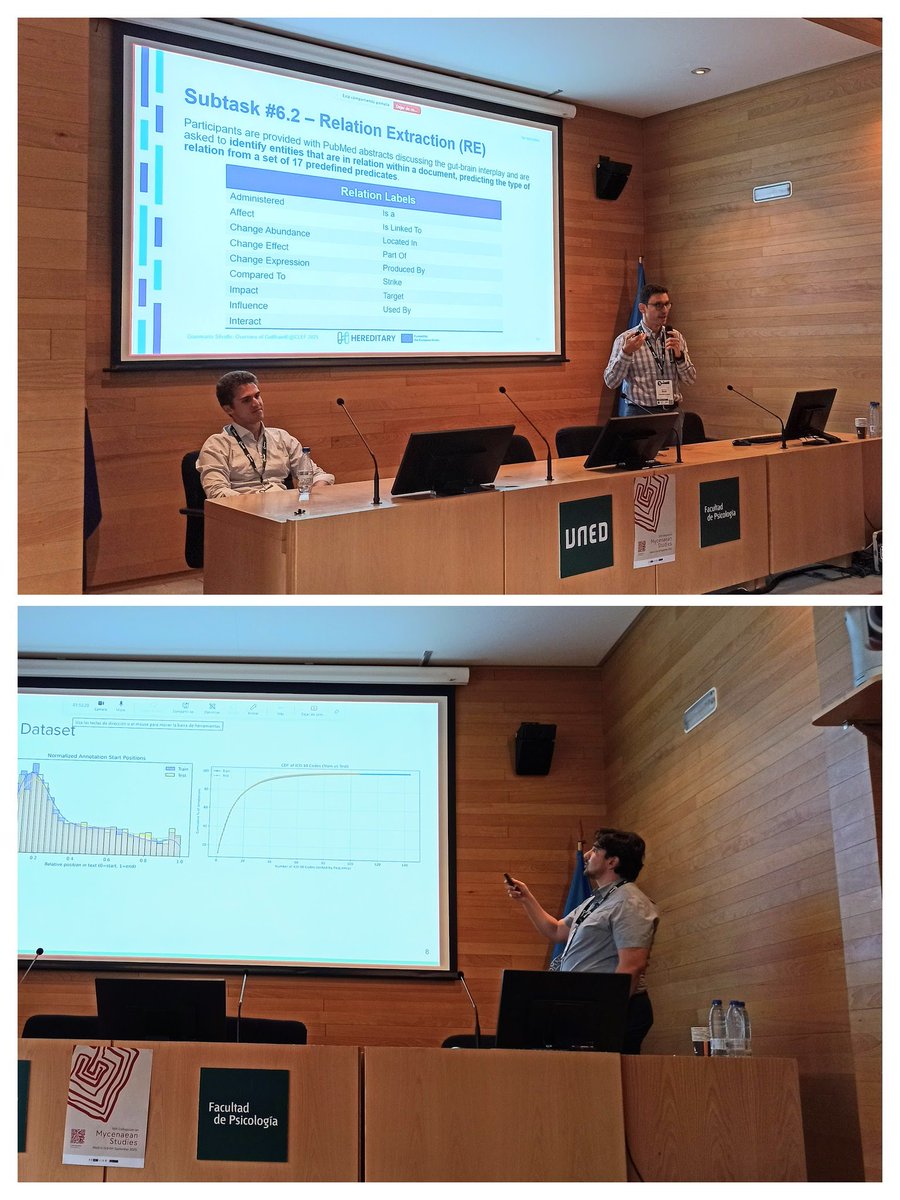
The 13th #BioASQ workshop is now completed after two exciting days at #CLEF2025!
Stay tuned for @BioASQ 14th edition at #CLEF2026 with six tasks in #biomedical #QA, #Summarisation, #NER, and #InformationExtraction that will cover ten languages and three document types!

1
3
6
508

10 Sep 2025
🏆 Celebrating success! @saradueromero received the BioASQ Lab Award for the SINAI team
outstanding work
🌟 A proud moment for the entire SINAI team 💪
#CLEF2025 #AI #NLP

3
7
134

10 Sep 2025
🚀 Today we share the concept of Student-Teacher framework adapted for clinical case report 🩺📑 summarization.
📑 We present a poster @ #CLEF2025 @bioasq MultiClinSum Workshop at @uned
👇 The quick breakdown of what we’re presenting is down below in this tread
🧵 1/n

9 Sep 2025

📢 Just registered the #clef2025 and ready to dive into talks about NLP and IR advances in various fields including healthcare 👨⚕️
📜We also presenting poster for @BioASQ:
nicolayr.com/#bioasq2025
If you're here, too, I'd love to connect! ✨
#CLEF2025 #bioasq

2
8
827
9 Sep 2025
🚀 The SINAI group is also at #CLEF2025!
This time, our colleague Sara Dueñas is presenting our work on the BioASQ task.
📄 SINAI at BioASQ@CLEF 2025: A Multi-Stage RAG Pipeline for Biomedical Semantic Question Answering
#NLP #AI #BiomedicalAI #QuestionAnswering #RAG


4
5
117

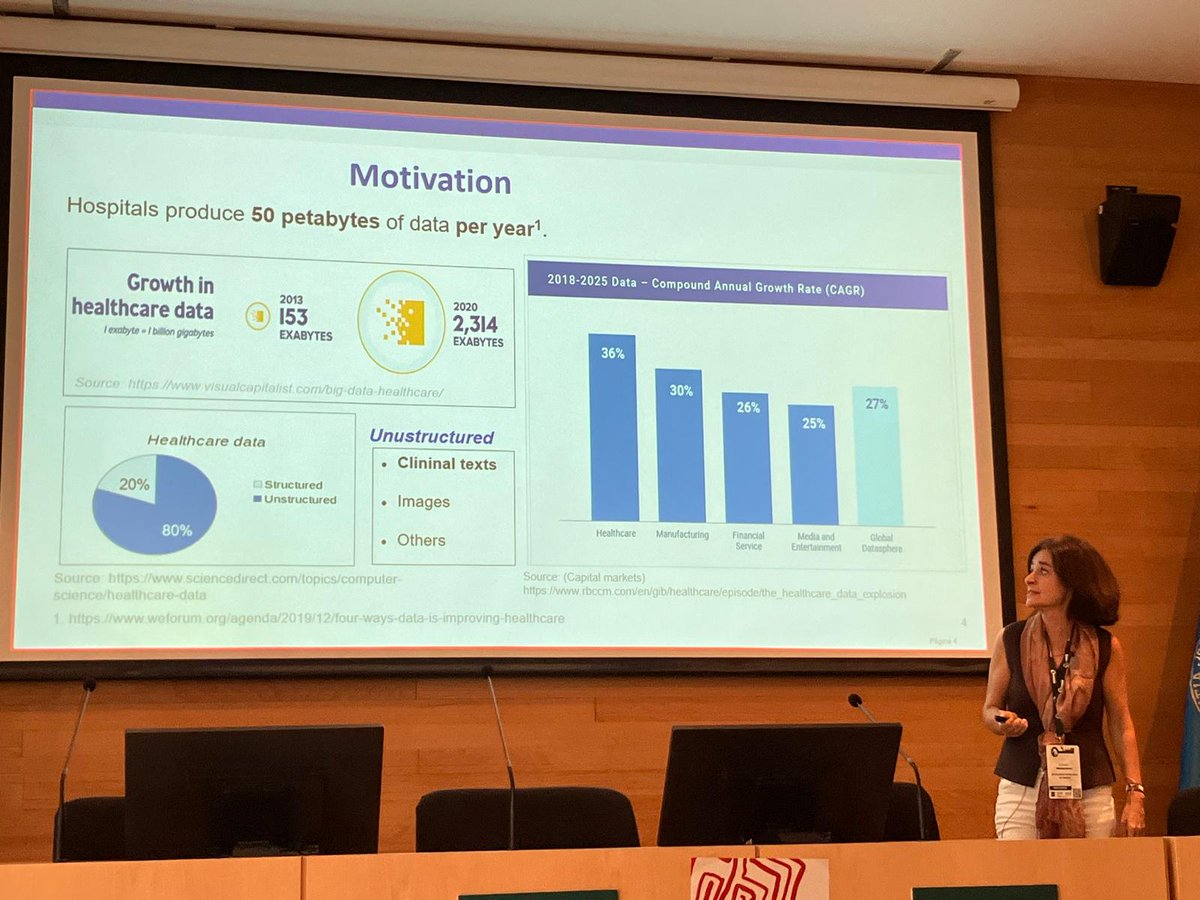
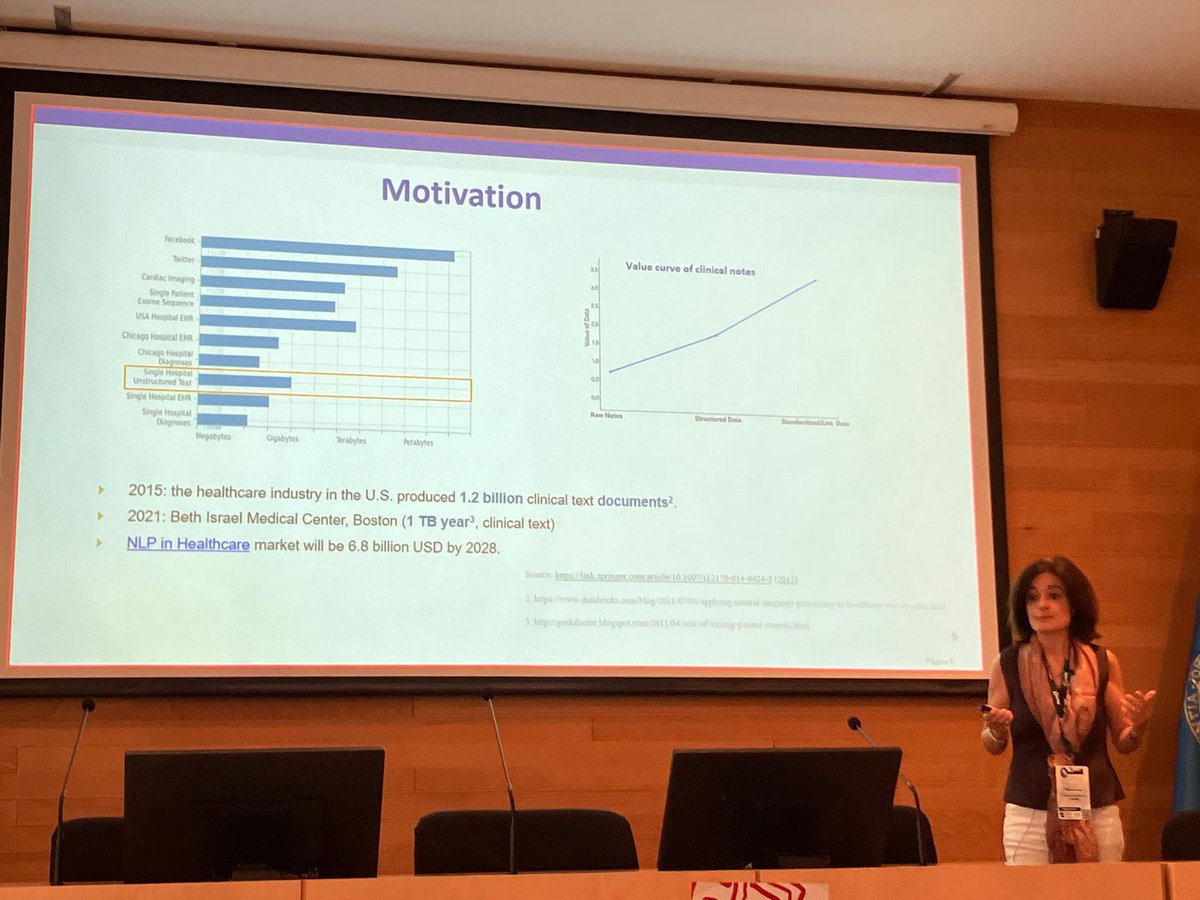
📝 Ernestina Menasalva (@ernesmena) gives a plenary talk at #CLEF2025: From Clinical Notes to Clinical Insights @BioASQ 💡


2
6
244
Anastasios Nentidis (@Tasos0000) starts the @BioASQ Lab session, summarizing the results of participants’ in the tasks related to large-scale biomedical semantic indexing and question answering 📕 #CLEF2025

3
5
313
29 Aug 2025
The paper builds a medical retrieval augmented generation system that reasons causally and answers more reliably.
Up to 10.3% accuracy gain vs vanilla RAG.
Standard medical RAG often grabs text that looks similar to the question yet misses causal links, so answers drift.
MedCoT-RAG scores each document by 2 signals, how close it is to the question and whether it contains clear cause effect wording, then prefers mechanistic pieces.
During generation it follows a 4 step clinical pattern, list key findings, explain the mechanism, weigh alternatives, then give a short evidence based conclusion.
Using the same causal framing in retrieval and reasoning keeps context and answers in sync and cuts hallucinations.
Tested on USMLE style MedQA, MMLU-Med, and BioASQ yes or no, it beats strong baselines that use only retrieval or only chain of thought.
Ablations show that domain embeddings alone or generic chain of thought help less than the full causal combo, the big win comes from pairing causal retrieval with structured reasoning.
----
Paper – arxiv. org/abs/2508.15849
Paper Title: "MedCoT-RAG: Causal Chain-of-Thought RAG for Medical Question Answering"

1
7
2,568
13 Aug 2025
The paper builds a 3-agent search system that beats flat agents on real enterprise tasks.
Enterprises need answers that combine private documents with the Web.
Training 1 big agent that drives every tool at once sounds simple, but it struggles because the action space explodes, it overuses easy tools, it underuses harder Web search, and training wastes data.
HierSearch splits the job.
A local agent searches text chunks and a knowledge graph.
A Web agent queries search engines and reads pages.
A planner decides which agent to call, merges the evidence, then writes the final answer.
They train the 2 lower agents first, then train the planner on top, this is hierarchical reinforcement learning.
They also add a small knowledge refiner that keeps only evidence that actually moves the next thinking step forward, then adds a few items that support the final answer across sources, this blocks copied hallucinations.
EM means exact match, F1 balances token precision and recall.
Across 6 benchmarks it wins clearly, with F1 at 62.83 on MuSiQue, 46.37 on OmniEval finance, 66.99 on BioASQ medical, 68.00 on NQ, 67.40 on HotpotQA, and 72.81 on PubMedQA.
Ablations show each piece matters.
Bottom line, a simple 3-agent stack plus a light refiner gives better answers, less noise, and lower Web spend.
----
Paper – arxiv. org/abs/2508.08088
Paper Title: "HierSearch: A Hierarchical Enterprise Deep Search Framework Integrating Local and Web Searches"

6
41
186
12,218