
🙏 Honored to receive the Akademiepreis of the Berlin-Brandenburg Academy of Sciences and Humanities today.
The Akademiepreis is awarded every two years for outstanding scientific achievements across all disciplines. This year’s citation recognized our work in computational biomedicine and biomedical data science.
While I am deeply grateful for this recognition, it really belongs to a much larger community. I have been extraordinarily fortunate to work with outstanding students, postdocs, group leaders, clinicians, collaborators, mentors, institutional partners, and friends over many years. Their ideas, creativity, dedication, and trust made this journey possible!
In my brief acceptance remarks, I spoke about a topic that has been on my mind recently.
Few things are as universal as health and disease. This is one reason why I believe AI in biomedicine can play a special role. Beyond advancing science, it provides an opportunity to explain AI through something that matters to everyone: helping people stay healthy, receive better care, and benefit from the best medical expertise available -> Perhaps healthcare is one of the most tangible ways to connect AI research with the broader public.
My sincere thanks to everyone who has been part of this journey!
🔗 bbaw.de/veranstaltungen/vera…
#BiomedicalAI #DigitalHealth #AIforGood

6
4
72
3,422

Jun 10
Claude Fable 5: Not So Fabulous (Yet)
Tried Fable 5 for biomedical knowledge graph tasks. Every biology-related request was blocked by safety controls.
Too restrictive for many life-science workflows.
Anyone else seeing this?
#Bioinformatics #BiomedicalAI #AI

1
92

Jun 10
📣 Happening today in Waltham, MA! We're excited to join industry leaders at DataDrivenPharma East to explore how AI, data science, and biopharma innovation are accelerating the future of drug development.
If you're attending, be sure to catch these sessions from the Mithrl team:
📍 AM | Inside the Business Track
AI Discovery at the Speed of the Program, Not the Pipeline
Vivek Adarsh, PhD, Co-Founder & CEO
📍 PM | Inside the Science Track
Multi-Agent AI for ICI Response Prediction Across Heterogeneous Datasets
Ada Shaw, PhD, Scientific Partnerships Lead & Biomedical AI Scientist
(based on collaborative study with Elephas, Erika van Euw, PhD, MBA, Christina Vivelo, PhD, Hinco Gierman, PhD, and team)
We hope to connect and discuss how agentic AI can help accelerate scientific discovery while maintaining transparency, traceability, and rigor.
View the agenda: bit.ly/4fKdwFn
@flyingthor @ecolienthusiast #DDPEast2026 #DataDrivenPharma #DrugDiscovery #BiomedicalAI #TranslationalResearch #Biotech

2
1
65

Jun 10
What if a synthetic child patient could help us explore leukemia treatment scenarios before reaching the clinic? 🧬🤖
This is the core idea behind STING DSS.
I am excited to announce that the STING Decision Support System is now live on the Web! 🚀🌐
Developed in my TÜBİTAK 1001 project, STING focuses on one of the most challenging and meaningful intersections of today’s research:
Childhood acute leukemia, drug repositioning, digital twins, synthetic patients, and explainable artificial intelligence.
STING DSS is designed as a browser-based AI decision-support research platform for pediatric acute lymphoblastic leukemia. It brings together multiple AI/ML modules into a sequential and interactive pipeline:
🧠 Bi-LSTM-based drug repositioning
💊 Candidate drug assessment, including Copanlisib and Novobiocin
🩸 Patient-specific pharmacokinetic/pharmacodynamic ODE simulations
⚙️ Genetic algorithm-based dose optimisation
🌐 GNN-driven digital twin prediction
🔍 Explainable AI with SHAP, permutation importance, counterfactual explanations, and GEMEX
🧬 CTGAN-based synthetic patient cohort generation
📊 5-class pediatric ALL risk stratification: LR / SR / IR / HR / VHR
But beyond the technical pipeline, the real purpose is bigger:
Can we make biomedical AI research more accessible, interactive, reproducible, and ethically scalable?
Can synthetic patients help researchers explore treatment dynamics before moving toward more sensitive real-world settings?
Can digital twins and AI-based simulations support the future of precision medicine in pediatric oncology?
STING DSS is one step toward answering these questions. ✨
🎥 In the video below, you can see the system in action.
🔗 Project Website: sting.sdu.edu.tr
🔗 GitHub Repository: github.com/tubitaksting/STIN…
We are also opening a participation channel for researchers and students who would like to receive an account and contribute to the STING ecosystem.
📝 Participation Form: forms.gle/1sWVzznJ5TNwWbDq9
If you are working on AI in healthcare, leukemia research, digital twins, synthetic patient modeling, explainable AI, drug repositioning, computational biology, or clinical decision support systems, I would be very happy to connect and hear your thoughts. 🌟
Your feedback, ideas, and collaborations can help shape the next steps of STING.
#STING #TUBITAK #ArtificialIntelligence #DigitalTwin #SyntheticPatients #PediatricALL #AcuteLymphoblasticLeukemia #LeukemiaResearch #ChildhoodLeukemia #DrugRepositioning #ClinicalDecisionSupport #DecisionSupportSystem #DeepLearning #MachineLearning #GraphNeuralNetworks #ExplainableAI #XAI #GEMEX #CTGAN #ODE #ComputationalBiology #BiomedicalAI #AIinHealthcare #PrecisionMedicine #PediatricOncology #HealthTech #OpenScience #Research #GitHub #SuleymanDemirelUniversitesi
1
1
3
593

Jun 9
Link: youtu.be/OxdFtmBL30E?si=vNLS…
Today, @AnthropicAI have released @claudeai Fable 5 & Mythos 5.
What does it mean for Biomedical and Clinical Research and Patient Care ?
I have prepared a very short overview...
Here is the Preview...
1. Autonomous single-cell genomics — the model assembled a cross-species atlas spanning 138 species and trained a method that beat a recently published one at ~1/100th the size.
2. Therapeutic design — running the protein-design loop end-to-end (binding sites, tool selection, failure recovery), with 9 of 14 targets yielding strong candidates. Immune-checkpoint and receptor-signaling biology sit right at the center of blood-cancer immunotherapy.
3. Novel hypotheses — the first model to consistently propose original, testable mechanisms; experts preferred them ~80% of the time in blinded comparison, and one was independently corroborated.
4. The honest part — these capabilities are dual-use, which is exactly why many biology/chemistry queries are deliberately gated. I think the safeguards, and the honest caveats around unpublished results, matter as much as the breakthroughs.
My take: the frontier isn't replacing the biologist or the biostatistician. It's raising the resolution at which we can design, hypothesize, and test — and our job is to verify fast enough to keep up.
#AIinMedicine #ComputationalBiology #SingleCell #Genomics #Hematology #Oncology #DrugDiscovery #PrecisionMedicine #MountSinai
#AIGenomics #TranslationalMedicine #PrecisionOncology #Hematology #MPN #ASCO26 #SingleCell #SpatialOmics #DrugDiscovery #Bioinformatics #GenomicsAI #ClinicalAI #PrecisionOncology #Hematology #MPN #MRD #FoundationModels #FDA #Elsa #HALO #ChatGPT #OpenEvidence #MountSinai #AACR2026 #EHA2026 #ASCO2026 #Tempus #Anthropic #ClaudeForLifeSciences #ClaudeForHealthcare #AgenticAI #Bomedemstat #Rusfertide #INCA033989 #DrugDiscovery #BioNeMo #BiomedicalAI
2
2
3,665

AutoScientists: Self-Organizing Agent Teams for Long-Running Scientific Experimentation
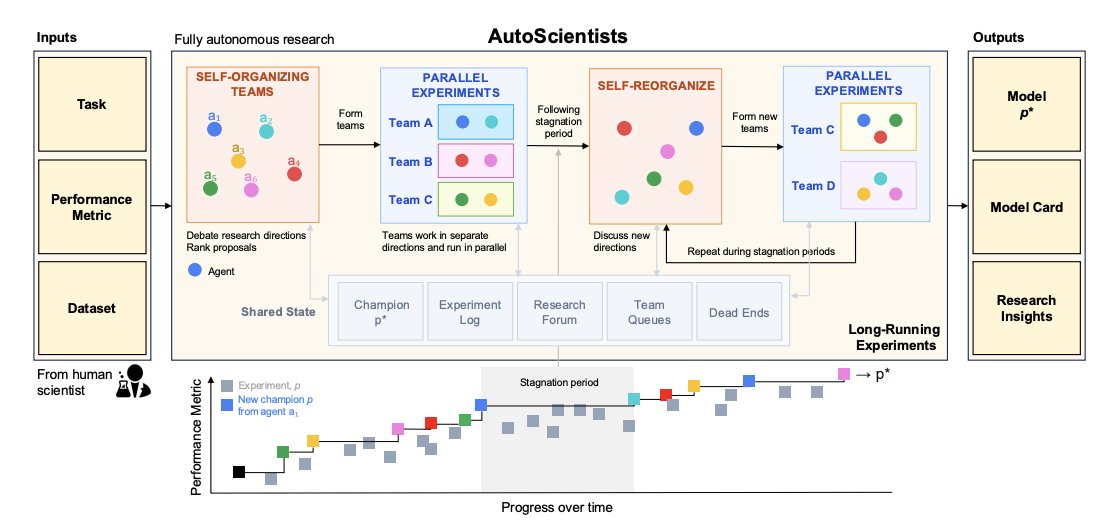
1. AUTOSCIENTISTS is a decentralized “AI lab team” designed for long-running computational experiments: agents maintain multiple competing hypotheses, run parallel experiments, and keep track of both successes and failures so the search can continue even after early ideas plateau.
2. Core design shift vs prior agentic systems: no central planner and no fixed search-space decomposition. Instead, agents coordinate through a shared experimental state (current champion, full experiment log, shared forum, team queues, and dead-end registries) and self-organize into teams that can be created/merged/split/retired as evidence changes.
3. The workflow alternates between discussion and execution phases. In discussion, agents propose research directions and critique each other’s proposals before spending compute. In execution, teams run experiments in parallel and write results back to shared state; when progress stagnates, agents trigger a new discussion and reorganize.
4. Two persistent roles per team: analyst agents and experiment agents. Analysts audit what has/hasn’t been tried, rank directions using empirical effect sizes from prior runs, enforce diversity/ambition constraints on new proposals, and maintain hypothesis documents. Experiment agents implement diffs, train/evaluate candidates, and log outcomes.
5. To prevent “champion pollution” from stochastic metrics, AUTOSCIENTISTS uses a noise-aware promotion gate: large improvements are accepted directly; small improvements within a measured noise band require confirmation on a second seed; failures and near-misses are still recorded to reduce repeated dead ends.
6. BioML-Bench (24 end-to-end biomedical ML tasks across imaging, drug discovery, protein engineering, single-cell omics): under matched experimental budgets and the same coding-agent backend, AUTOSCIENTISTS reaches 74.4% mean leaderboard percentile, outperforming Autoresearch by 8.33 points; the largest gains are in drug discovery (64.52% vs 46.16%).
7. GPT nanochat training optimization: from the same baseline, AUTOSCIENTISTS reaches a target validation bits-per-byte about 1.9× faster in terms of number of experiments (34 vs 65). Starting from an AUTOSCIENTISTS-discovered champion, it continues improving (7 accepted changes, reaching 0.9730 val_bpb) while the single-agent baseline accepts none over 100 experiments.
8. ProteinGym supervised fitness prediction: starting from the strong Kermut method, AUTOSCIENTISTS discovers an extension that improves ACE2–Spike binding Spearman correlation from 0.747 to 0.840. Freezing the discovered recipe and applying it across all 217 ProteinGym assays improves the official average Spearman correlation from 0.657 to 0.700 ( 6.5% relative).
9. Ablations indicate the gains come from multiple complementary mechanisms rather than one trick: removing analysts, cross-agent feedback, self-organization, or shared state each causes major degradation depending on the task (e.g., self-organization matters most when the productive direction shifts mid-run; shared records matter when avoiding duplicated failures is critical).
💻Code: github.com/mims-harvard/Auto…
📜Paper: arxiv.org/abs/2605.28655
#AIAgents #MultiAgentSystems #AutoML #ScientificDiscovery #BiomedicalAI #ProteinEngineering #LLM #MachineLearning #Reproducibility
5
21
1,544

Check out my latest article on Linkedin: Enabling Trust: Best Practices for AI & Machine Learning in Healthcare linkedin.com/pulse/enabling-…
#HealthcareAI #MachineLearning #DigitalHealth #BiomedicalAI #MedTech
1
2
3
55

🚀 Huge moment for biomedical discovery!
@EricTopol nails it sharing @Nature’s new editorial:
“AI scientists can and should empower human researchers. They cannot and should not replace them.”
Multi-agent AI from @GoogleDeepMind & @FutureHouseSF is already generating hypotheses, designing experiments, and surfacing fresh drug candidates for cancer, fibrosis, macular degeneration, antimicrobial resistance & more.
Human creativity AI speed = the ultimate scientific superpower.
As a senior scientist, I’m genuinely excited for what this collaboration unlocks next! 🔬🤖
What breakthrough are you most looking forward to?
#AIforScience #BiomedicalAI
May 20

Important editorial @Nature on the new "AI-scientist" papers
"AI scientists can and should empower human
researchers. They cannot and should not replace them."
nature.com/articles/d41586-0…

1
2
554

May 19
AI and machine learning are rapidly reshaping healthcare and biology—from improving diagnostics to accelerating drug discovery and decoding complex biological systems.
Explore the latest research in Research:
spj.science.org/journal/rese…
#AIinHealthcare #MachineLearning #BiomedicalAI

9
1
3
273

May 18
🧵 $SYNAPZ is building a governed Bio Research Engine — an AI swarm designed to run thousands of safe in-silico biomedical simulations before real lab time is wasted.
Not “AI cures disease.”
A research acceleration layer for hypothesis ranking, simulation, validation scoring and audit-backed discovery. 🧵
Every research question flows through a locked pipeline:
SUBMIT → POLICY CHECK → LITERATURE SCAN → DATA CURATION → KNOWLEDGE GRAPH → SIMULATION SWARM → RED-TEAM REVIEW → REPRODUCIBILITY CHECK → CONSENSUS SCORE → REPORT
No black-box claims.
No unsafe shortcuts.
🧬 In-Silico Simulation Layer
SYNAPZ can break a biomedical question into thousands of safe computational runs:
Target validation
Pathway perturbation
Biomarker ranking
Combination modelling
Resistance-risk simulation
Safety-signal review
Literature contradiction checks
All before wet-lab validation.
🧠 Swarm-Based Discovery
Specialised agents work in parallel:
Literature Scout
Data Curator
Knowledge Graph Builder
Simulation Agent
Hypothesis Generator
Red-Team Critic
Reproducibility Agent
Report Agent
Each one attacks the problem from a different angle.
📊 Ranked Validation Scoring
The system does not say “this works.”
It scores:
Evidence strength
Cross-dataset replication
Biological plausibility
Novelty
Contradictions
Safety concerns
Model agreement
Reproducibility
Then ranks what is worth expert review first.
🔐 Governed by Design
Hard boundaries are built in:
No wet-lab protocols
No pathogen engineering
No clinical advice
No dosage guidance
No unsafe dual-use outputs
No patient-identifiable data
Research support only.
Human approval where required.
⚖️ Red-Team Reproducibility Layer
Every promising result is challenged before it reaches a report.
Bias checks.
Confound checks.
Weak evidence detection.
Contradiction scoring.
Dataset hashing.
Model versioning.
Full audit trail.
If it cannot be traced, it does not pass.
This is how AI cuts down real lab time:
Not by replacing scientists.
By filtering thousands of weak ideas before they consume months of lab work, funding and human effort.
$SYNAPZ turns biomedical research into a governed, high-throughput, in-silico discovery pipeline.
#SYNAPZ #AI #BioAI #BiomedicalAI #DrugDiscovery #InSilico #ComputationalBiology #AIInfrastructure #AIGovernance #HumanInTheLoop #HealthTech #LifeSciences #BuildInPublic

2
9
14
402

May 18
🚨 Big news for Stanford AI!
We’re bringing the researchers behind @mbzuai frontier foundation models straight to Stanford.
AI Valley is co-hosting an exclusive evening with the Institute of Foundation Models (MBZUAI) Stanford Society of Engineers, Scientists, and Entrepreneurs.
From research lab → real-world systems. This is the room.
Featuring Stanford faculty:
Prof. Tengyu Ma (CS Statistics)
Prof. James Zou (Biomedical Data Science)
Prof. Shriti Raj (HAI Medicine)
Expect:
🔬 Deep technical dives
🔥 Fireside on model deployment
📷 Hands-on workshop with PAN (IFM’s world model platform)
🍽️Dinner recruiting giveaways
Built for Stanford undergrads, MS/PhD students, researchers & technical builders obsessed with foundation models, world models, and biomedical AI.
Details RSVP in comments 👇 #Stanford #MBZUAI #FoundationModels #WorldModels #BiomedicalAI #AIResearch

2
2
3
234

May 13
We applied 3 different evidence-analysis skills to the same pediatric vitamin D meta-analysis PDF.
The result was not just different summaries — but three completely different interpretations of what “strong evidence” actually means.
🏆 Final ranking:
1. Evidence Level Ranker (AIPOCH)
2. ai-research-22-agent-native-research-artifact-rigor-reviewer
3. scientific-civic-evidence
github.com/aipoch/medical-re…
#AIPOCH #EvidenceBasedMedicine #ResearchIntegrity #BiomedicalAI #SystematicReview #MetaAnalysis #ClinicalResearch #ScientificWriting #TranslationalMedicine #Bioinformatics
1
2
2,115
May 13
Three research-analysis skills. Same biomedical protocol PDF.
Completely different interpretations of “evidence quality.”
🏆 Ranking:
1. Result Reliability Checker (AIPOCH)
2. citation-form-check
3. academic-verify
github.com/aipoch/medical-re…
#AIPOCH #BiomedicalAI #ResearchIntegrity #EvidenceAssessment #Bioinformatics #MachineLearning #ScientificWriting #ClinicalResearch #Omics #TranslationalMedicine
1
3
3,484

May 10
Don't miss our exciting keynote at @sewebmeda 🎤Prof. @FrankVanHarmele will show us how to use design patterns for neuro-symbolic medical decision support systems!
📍 2:00 PM, Room 1, May10, Dubrovnik @eswc_conf
sewebmeda-workshop.github.io…
#KnowledgeGraphs #BiomedicalAI #healthcare

2
62

May 9
🎓 Fully Funded PhD in Vision Science & Multimodal Biomarkers for Age-Related Macular Degeneration (Sweden 🇸🇪)
💶 Fully funded doctoral studentship with competitive salary and excellent research benefits at one of the world’s leading medical universities
✅ Passionate about #Ophthalmology #BiomedicalAI #RetinalImaging 👁️💻🔬📊.
✅ Highly recommend this interdisciplinary #fullyfunded #PhDPosition for up to 4️⃣years within the Department of Clinical Neuroscience, @karolinskainst 🇸🇪
📌 This #phdproject focuses on “𝗠𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗕𝗶𝗼𝗺𝗮𝗿𝗸𝗲𝗿𝘀 𝗶𝗻 𝗔𝗴𝗲-𝗥𝗲𝗹𝗮𝘁𝗲𝗱 𝗠𝗮𝗰𝘂𝗹𝗮𝗿 𝗗𝗲𝗴𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻”
You’ll work on:
🔷 Advanced retinal imaging & functional vision testing
🔷 AI-driven analytics for biomarker discovery
🔷 Detecting subtle structural & functional retinal changes
🔷 Multimodal data integration & translational vision research
🔷 Improving monitoring, risk stratification & personalised care in AMD
🌍 Join a dynamic and collaborative research environment working at the intersection of optometry, ophthalmology, stem cell science & translational medical research.
⏰ 𝗗𝗲𝗮𝗱𝗹𝗶𝗻𝗲: 𝟯𝟭𝘀𝘁 𝗠𝗮𝘆, 𝟮𝟬𝟮𝟲
✅ Work with Dr. Abinaya Priya Venkataraman, Rune Brautaset’s research group & leading researchers in vision science and ocular imaging
👉 Full details & apply here:
🔗phdscanner.com/opportunities…
📩 Want more like this?
➕ Follow @PhdScanner and join WhatsApp for updates:
whatsapp.com/channel/0029Vb5…
🌐 Visit: phdscanner.com
#fullyfundedPhD #PhDposition #PhDVacancy #KarolinskaInstitutet #Sweden #VisionScience #MedicalImaging #Ophthalmology #AIinHealthcare #RetinalImaging
♻️ Share with someone applying this cycle
@phdhardtalk

3
9
679
Aligning LLMs with Biomedical Knowledge using Balanced Fine-Tuning
1. The paper argues that “low-confidence tokens” mean something different in biomedicine: they often form dense contiguous runs that encode rare entities (genes/mutations/pathway nodes) and mechanistic causal chains—i.e., epistemic uncertainty (knowledge gaps)—rather than the sparse stylistic alternatives (aleatoric uncertainty) common in general text.
2. This observation motivates Balanced Fine-Tuning (BFT), a dual-scale post-training objective designed to keep learning signal on knowledge-dense uncertainty while still stabilizing optimization—addressing a key failure mode where Dynamic Fine-Tuning (DFT) down-weights exactly the biomedical tokens that matter.
3. The authors operationalize “dense epistemic uncertainty” with a teacher-forcing diagnostic: compute per-token confidence, slide a 256-token window, and classify windows by (a) fraction of low-confidence tokens and (b) longest contiguous low-confidence run. Sparse-low windows (Group A) tend to be stylistic; dense-low windows (Group B) are enriched for biomedical entities and causal connectives.
4. BFT token-level innovation: replace DFT’s absolute confidence weighting with group-normalized reweighting using a local context confidence (mean confidence in a g=256 sliding window). Each token weight is proportional to cb,t / (Clocb,t ε), clipped to [0,1] and stop-gradient detached—suppressing isolated low-confidence outliers while preserving gradients in globally hard (dense-low) biomedical spans.
5. BFT sample-level innovation: reallocate learning across sequences using a bounded hard-sample coefficient derived from the minimum local context confidence within the sequence. This explicitly shifts optimization budget toward samples containing the hardest knowledge-dense regions, complementing token-level gating.
6. Across tasks (medical evaluation, biological reasoning, sparse-reward RL, and representation learning), BFT provides more consistent gains than SFT and DFT under the same training recipe and model family (DeepSeek-R1-Distill 14B/32B/70B), suggesting the uncertainty-aware loss design transfers across biomedical settings.
7. Backbone replacement results in agentic biology pipelines: swapping closed-source backbones with a BFT-aligned 70B model improves GeneAgent biological process reasoning and matches/exceeds the original VCWorld Gemini-2.5-Flash backbone on chemical perturbation reasoning (VCWorld average accuracy reported at 0.70 for BFT 70B vs 0.68 for Gemini-2.5-Flash; SFT/DFT replacements lag behind).
8. Sparse-reward RL compatibility is a key takeaway: after subsequent GRPO on Tahoe-100M with sparse binary rewards, SFT and DFT degrade, but all BFT variants improve (e.g., BFT 70B from 0.70 to 0.74 average on held-out VCWorld cell lines). The paper links this to richer mechanistic traces (more entities, more causal connectives, longer responses), which increases “credit assignment surface area” under sparse rewards.
9. Beyond generation, BFT aims to narrow the generative–discriminative split in computational biology: BFT-generated biomedical profile texts (encoded with a text embedding model) yield stronger gene- and cell-level representations, improving gene property prediction and gene interaction tasks, cell clustering, multimodal integration (scIB), and perturbation response prediction—sometimes rivaling or outperforming specialized biology foundation models in reported settings.
10. Practical considerations: BFT introduces only one main hyperparameter (window size g, default 256) and is reported robust across a broad range; it also shows reduced hidden preference transfer in a synthetic-data “subliminal learning” style safety test compared to SFT, staying closer to the base model’s behavior.
💻Code: github.com/TencentAILabHealt…
📜Paper: arxiv.org/abs/2511.21075
#LLM #BioNLP #ComputationalBiology #BiomedicalAI #FineTuning #ReinforcementLearning #SingleCell #PerturbationBiology #RepresentationLearning #AIAlignment

1
14
1,488
Apr 30
Don't miss our exciting keynote at #SeWeBMeDA2026! 📷Prof. Frank van Harmelen @FrankVanHarmele will show us how to use design patterns for neuro-symbolic medical decision support systems!
📷 May 10, Dubrovnik (co-located with @eswc_conf)
📷 sewebmeda-workshop.github.io…
#BiomedicalAI
3
4
44
Apr 28
Join us on May 10 in Dubrovnik for an exciting afternoon of talks on neuro-symbolic AI for healthcare & more, co-located with @eswc_conf!
📷 Check out the full schedule: sewebmeda-workshop.github.io…
#ESWC2026 #SemanticWeb #KnowledgeGraphs #BiomedicalAI #healthcare #lifescience
3
4
42

Apr 8
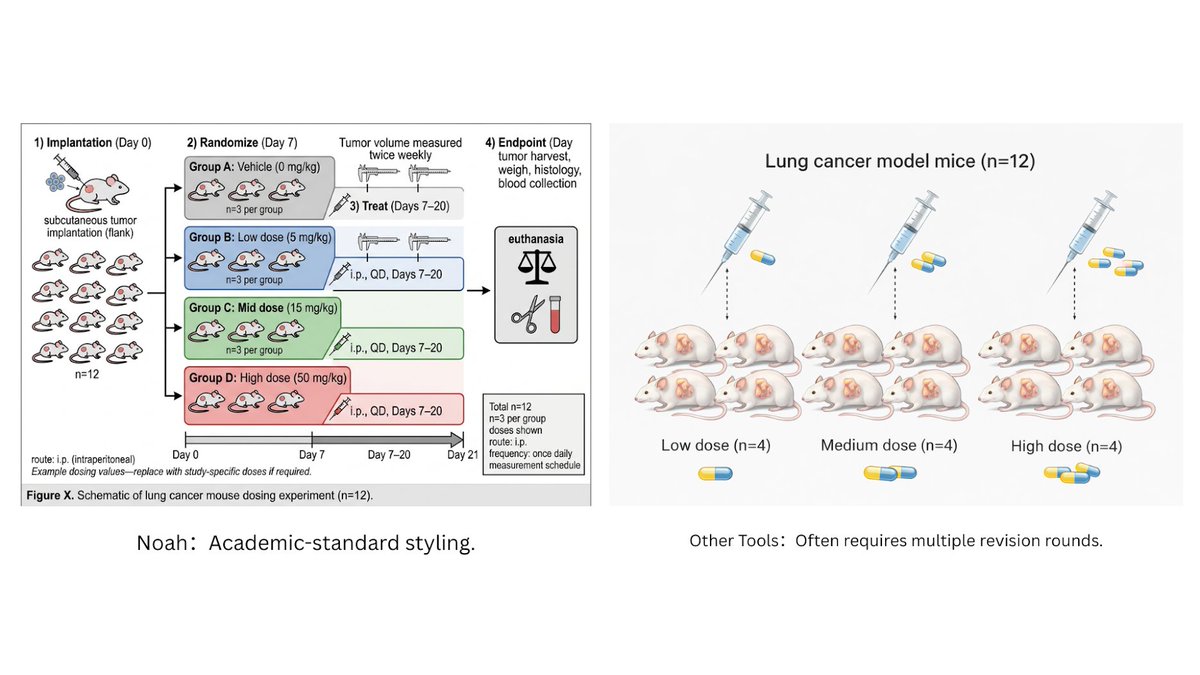
🚨 Noah AI, bilimsel araştırma dünyasına özel ilk gerçek “Biomedical Figure Generator”ı tanıttı.
Genel amaçlı görüntü araçlarından farklı olarak, bu araç bilimsel mantığa dayalı, akademik standartlarda figürler üretiyor.
Sistem üç adımlı yapılandırılmış bir akışla çalışıyor:
Understand → Retrieve → Visualize
Öne çıkan yetenekleri:
• Bilimsel olarak doğru ve okunaklı etiketler
• Mantıksal mekanizma diyagramları
• Yüksek kaliteli metin render’ı (Nano Banana 2 altyapısı)
• Akademik yayınlara uygun profesyonel stil
Hazır şablonlar arasında şunlar yer alıyor:
Animal Experiment, Drug Mechanism of Action, Clinical Trial Design, Mechanism Diagrams ve daha fazlası.
Araştırmacılar ve bilim insanları için önemli bir zaman tasarrufu ve kalite artışı sağlayan bu araç, dikey AI uygulamalarının gücünü bir kez daha gösteriyor.
🔗 Noah AI Biomedical Figure Generator:
noah.bio/hitl
Sizce bu tür dikey AI araçları, genel amaçlı modellere göre bilimsel çalışmalarda ne kadar daha etkili olacak?
Yorumlarda görüşlerinizi paylaşın.
#NoahAI #BiomedicalAI #ScientificFigure #AIForResearch #AcademicAI #YapayZeka #AI2026
13
1,329

Apr 3
Exciting news for the AI and Biomedicine community! 🧬💻
Join the 2nd MMFM-BIOMED Workshop at @CVPR in Denver! We’re bringing together experts to tackle the challenges and opportunities of Multimodal Foundation Models for Biomedicine.
Call for Papers is OPEN! 📝
We’re looking for short papers (max 4 pages) on:
🔹 Challenges in current modeling, such as multimodal alignment, data curation, benchmarking, and agentic systems
🔹 New opportunities in drug discovery & surgery
Important Dates:
⏰ Submission Deadline: May 1, 2026
📣 Notification: May 10, 2026
📅 Workshop: June 3-4, 2026
Featuring incredible speakers from @Stanford, @Princeton, @EPFL, and the University of Strasbourg!
Submit your work here: mmfm-biomed.github.io/
#CVPR #BiomedicalAI #FoundationModels #MachineLearning #HealthTech #AI

5
17
14,325