
Jun 11
CPU at 90%. Wait stats look clean. Queries are fast. Nothing obvious in the execution plans.
You might be looking at spinlock contention.
Spinlocks are in-memory primitives protecting SQL Server's internal structures. Unlike regular locks, they don't yield to the OS — a thread burns CPU in a tight loop waiting to acquire one.
Query them directly:
SELECT name, collisions, spins,
spins_per_collision, backoffs
FROM sys.dm_os_spinlock_stats
WHERE collisions > 0
ORDER BY spins DESC;
High spins_per_collision: threads waiting a long time.
High backoffs: spinlock had to back off and retry.
Key types to know:
- LOGCACHE_ACCESS: log cache, high-volume inserts
- LOCK_HASH: lock manager hash bucket contention
- SOS_SCHEDULER: scheduler queue contention
- BUFFERPOOL: buffer pool access
Contention usually means too many cores hammering the same structure. Look at NUMA awareness, workload distribution, or newer SQL Server versions with improved spinlock partitioning.
#SQLServer #Spinlocks #Performance #Internals
9

Jun 1
Since I completed the WAL, I decided to take a deep dive into the pager system. While doing so, I noticed that there are other key components in place i needed to understand first, and one of which is the Cache, AKA BufferPool.
@s1ntaxe770r @0xGreat @TiemmaBakare
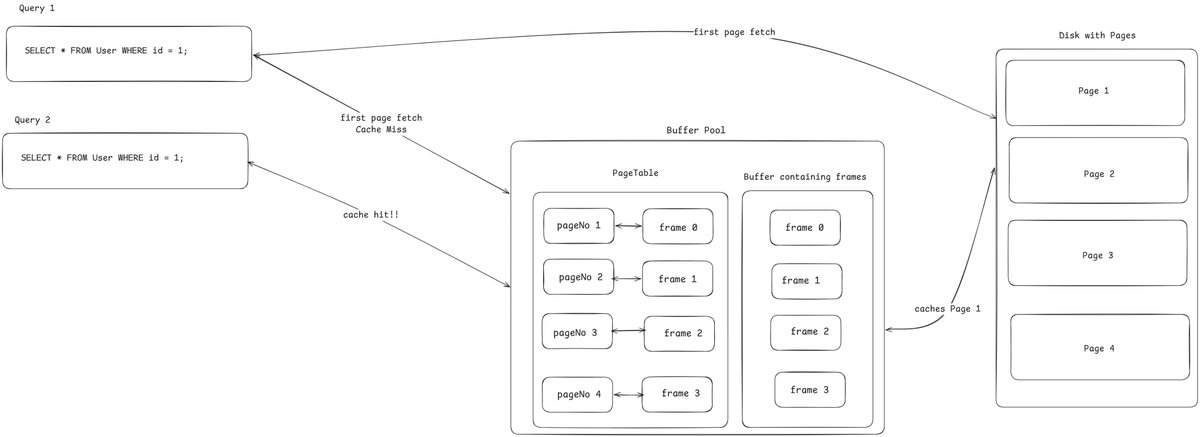
1
2
6
218

Feb 14
The missing 3.5GB is off-heap memory.
DirectByteBuffer allocates native memory outside the JVM heap, so heap dumps and GC tools don’t see it.
Monitor it using:
- XX:NativeMemoryTracking jcmd VM.native_memory
-XX:MaxDirectMemorySize
JMX BufferPool metrics (java.nio:type=BufferPool,name=direct)
Heap is fine. Native memory is consuming the rest.
3
25
2,232



4 Dec 2025
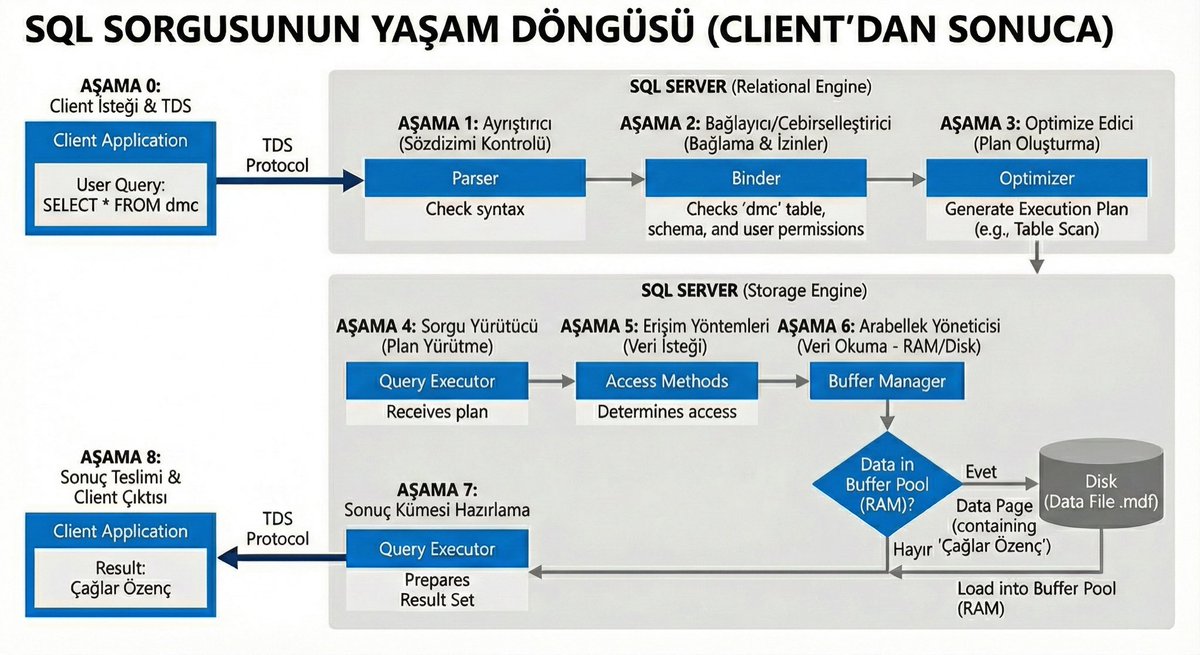
Bir sorgu çalıştığında arka planda 8 aşamalı bir yolculuk başlıyor.
Bu görsel tam olarak bunu özetliyor 👇
1️⃣ TDS ile SQL Server’a ulaşır
2️⃣ Parser sözdizimini kontrol eder
3️⃣ Binder şema izinleri doğrular
4️⃣ Optimizer Execution Plan oluşturur
5️⃣ Query Executor planı yürütür
6️⃣ Access Methods veri yolunu belirler
7️⃣ Buffer Manager veriyi RAM / Disk’ten çeker
8️⃣ Sonuç TDS ile geri döner
➡️ Performans sorunlarının �’ı bu adımlardan birindeki tıkanmadan çıkar.
✔ Kötü plan → CPU/IO artışı
✔ RAM’de olmayan veri → Disk gecikmesi
✔ Yanlış erişim yolu → Concurrency kaybı
✔ Eksik izin/yanlış şema → Binder hataları
Gerçek farkındalık:
“Sorgu yavaşladı” değil…
👉 Sorgunun geçtiği yol tıkandı.
Bu 8 adımı anlamak;
index stratejisinden locking davranışlarına,
execution plan okumadan tuning’e kadar
her şeyin temelidir.
#SQLServer #Database #ExecutionPlan #QueryOptimization #PerformanceTuning #BufferPool #MicrosoftDataPlatform
1
103

28 Nov 2025
November marked a month of education 🧠
From longform content on our upcoming bufferpool upgrade to our collateral transparency report and livestreams with ecosystem partners, here's a recap captured through our main video highlights:
→ methprotocol.xyz/blog/commun…

8
4
30
1,293

ep. 3 of the java podcasts ₊˚⊹⋆˙౨ৎ˚⟡˖ ࣪
in this edition, explore NYC with me as i discuss some exciting new alpha ft. bufferpool upgrades @mETHProtocol
4
2
20
926

27 Apr 2025
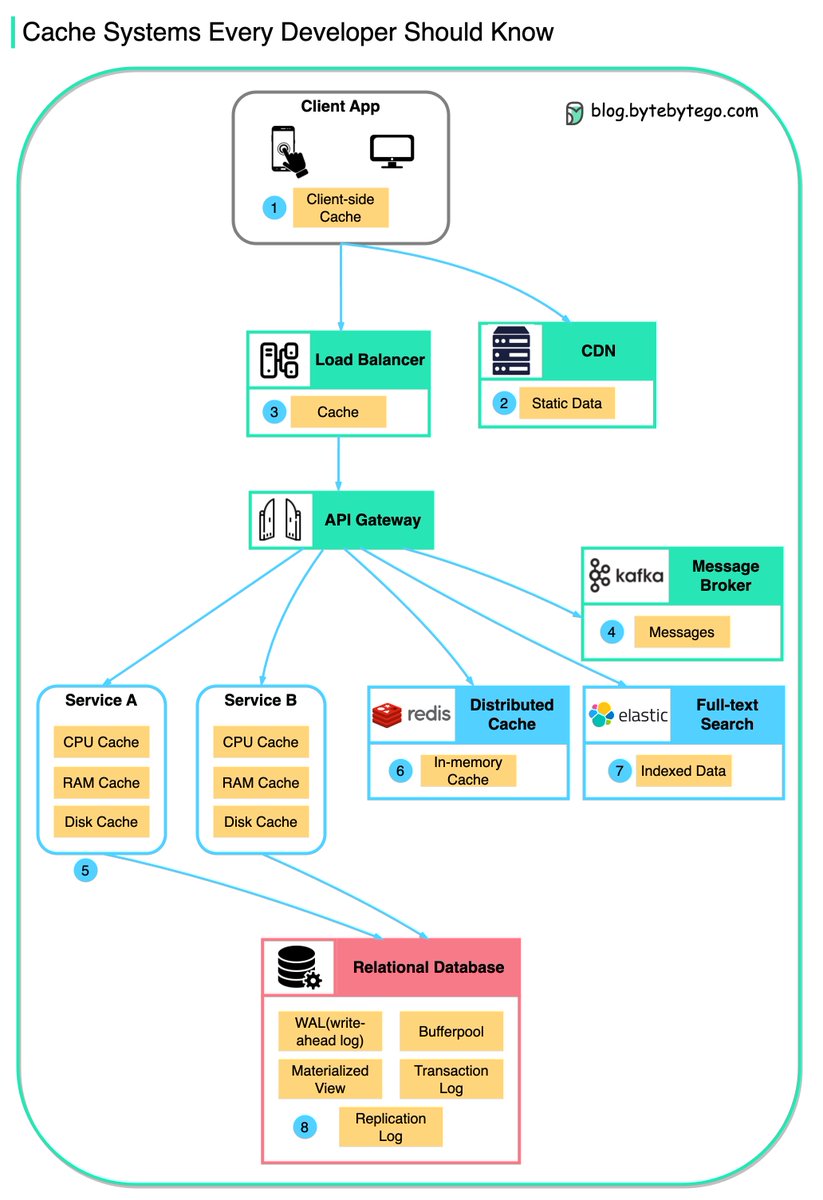
Data is cached everywhere, from the front end to the back end!
This diagram illustrates where we cache data in a typical architecture.
There are 𝐦𝐮𝐥𝐭𝐢𝐩𝐥𝐞 𝐥𝐚𝐲𝐞𝐫𝐬 along the flow.
🔹 1. Client apps: HTTP responses can be cached by the browser. We request data over HTTP for the first time, and it is returned with an expiry policy in the HTTP header; we request data again, and the client app tries to retrieve the data from the browser cache first.
🔹 2. CDN: CDN caches static web resources. The clients can retrieve data from a CDN node nearby.
🔹 3. Load Balancer: The load Balancer can cache resources as well.
🔹 4. Messaging infra: Message brokers store messages on disk first, and then consumers retrieve them at their own pace. Depending on the retention policy, the data is cached in Kafka clusters for a period of time.
🔹 5. Services: There are multiple layers of cache in a service. If the data is not cached in the CPU cache, the service will try to retrieve the data from memory. Sometimes the service has a second-level cache to store data on disk.
🔹 6. Distributed Cache: Distributed cache like Redis hold key-value pairs for multiple services in memory. It provides much better read/write performance than the database.
🔹 7. Full-text Search: we sometimes need to use full-text searches like Elastic Search for document search or log search. A copy of data is indexed in the search engine as well.
🔹 8. Database: Even in the database, we have different levels of caches:
- WAL(Write-ahead Log): data is written to WAL first before building the B tree index
- Bufferpool: A memory area allocated to cache query results
- Materialized View: Pre-compute query results and store them in the database tables for better query performance
- Transaction log: record all the transactions and database updates
- Replication Log: used to record the replication state in a database cluster
Over to you: With the data cached at so many levels, how can we guarantee the 𝐬𝐞𝐧𝐬𝐢𝐭𝐢𝐯𝐞 𝐮𝐬𝐞𝐫 𝐝𝐚𝐭𝐚 is completely erased from the systems?
--
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): bit.ly/bbg-social
2
115
506
41,137
15 Jan 2025
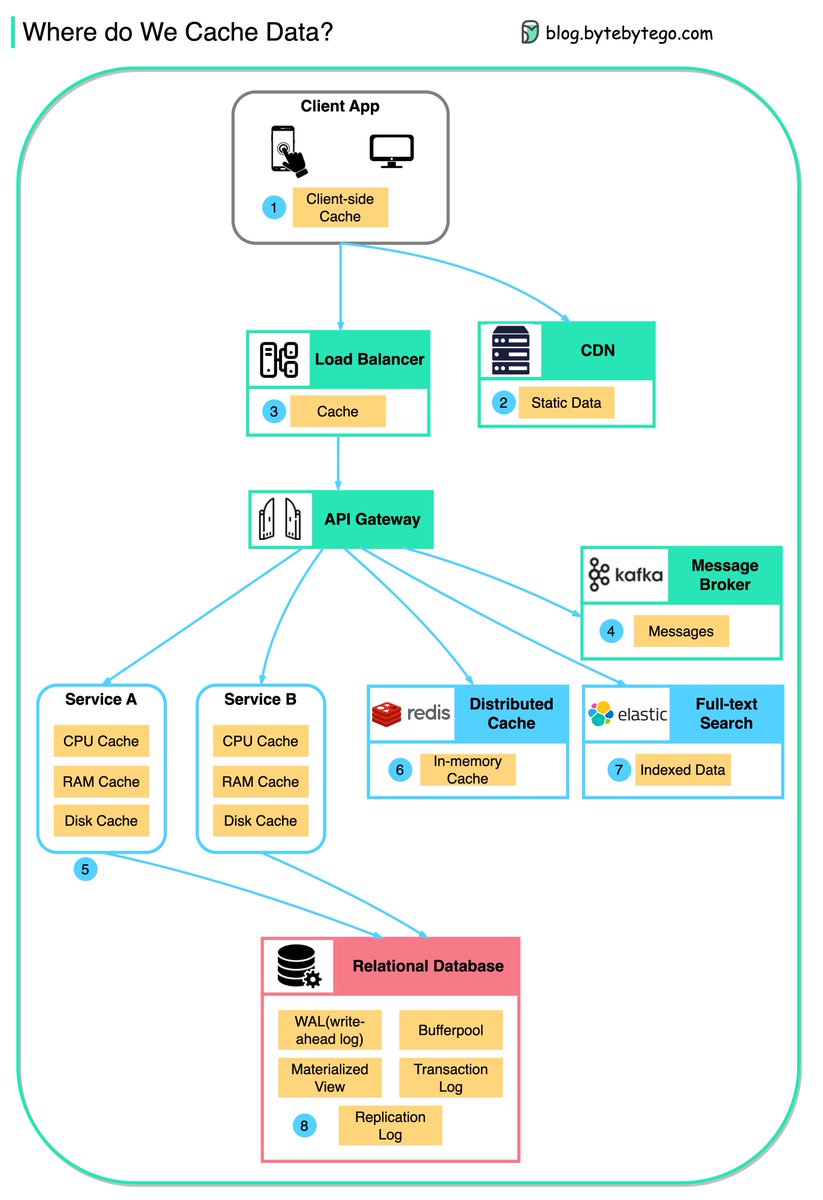
Data is cached everywhere, from the front end to the back end!
This diagram illustrates where we cache data in a typical architecture.
There are 𝐦𝐮𝐥𝐭𝐢𝐩𝐥𝐞 𝐥𝐚𝐲𝐞𝐫𝐬 along the flow.
1. Client apps: HTTP responses can be cached by the browser. We request data over HTTP for the first time, and it is returned with an expiry policy in the HTTP header; we request data again, and the client app tries to retrieve the data from the browser cache first.
2. CDN: CDN caches static web resources. The clients can retrieve data from a CDN node nearby.
3. Load Balancer: The load Balancer can cache resources as well.
4. Messaging infra: Message brokers store messages on disk first, and then consumers retrieve them at their own pace. Depending on the retention policy, the data is cached in Kafka clusters for a period of time.
5. Services: There are multiple layers of cache in a service. If the data is not cached in the CPU cache, the service will try to retrieve the data from memory. Sometimes the service has a second-level cache to store data on disk.
6. Distributed Cache: Distributed cache like Redis hold key-value pairs for multiple services in memory. It provides much better read/write performance than the database.
7. Full-text Search: we sometimes need to use full-text searches like Elastic Search for document search or log search. A copy of data is indexed in the search engine as well.
8. Database: Even in the database, we have different levels of caches:
- WAL(Write-ahead Log): data is written to WAL first before building the B tree index
- Bufferpool: A memory area allocated to cache query results
- Materialized View: Pre-compute query results and store them in the database tables for better query performance
- Transaction log: record all the transactions and database updates
- Replication Log: used to record the replication state in a database cluster
Over to you: With the data cached at so many levels, how can we guarantee the 𝐬𝐞𝐧𝐬𝐢𝐭𝐢𝐯𝐞 𝐮𝐬𝐞𝐫 𝐝𝐚𝐭𝐚 is completely erased from the systems?
--
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): bit.ly/bbg-social
5
87
425
30,332

23 Aug 2024
Caching is not just about using a distributed cache.
It happens at every layer of your application - right from the front end to the database.
The only thing that changes is its overall usage.
✅ Front End App
Browsers cache stuff all the time. HTTP responses, asset files, HTML pages, and so on.
Developers can set the caching directives in response headers to control the behavior.
✅ Content Delivery Networks
CDNs can cache static content like images, stylesheets, and JS files.
Their advantage is caching stuff closer to the users, reducing latency in the process.
✅ Load Balancers
Some load balancers can also cache frequently accessed data.
Responses can be served without calling the backend server. This improves the response times and also reduces the load on the server or database.
✅ Service Instance Cache
Service instances can employ their caching solutions to boost performance.
This can be in the form of in-memory caches that are checked before fetching from the database.
✅ Distributed Cache
A more robust caching solution can use distributed caches like Redis. They help with faster reads and writes than going to a traditional relational database.
✅ Full-text Search Tools
Searching through tons of text information is a time-consuming task.
Tools like ElasticSearch help index the data for faster text search, effectively acting as a cache.
✅ Databases
You might think that databases always fetch from the disk.
But databases also use special caching mechanisms. For example, a Bufferpool is like a cache within the database that holds data pages to support faster reads.
Also, Materialized Views store results of pre-computed results of expensive queries for faster access
Lastly, many new-age databases have their own built-in cache solutions.
👉 So - what types of caching solutions have you used?
4
93
358
18,602

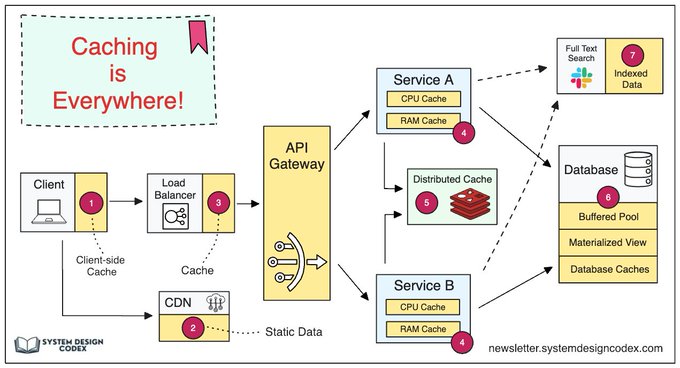
Data is cached everywhere, from the client-facing side to backend systems
Let's look at the many caching layers:
1. Client Apps: Browsers cache HTTP responses. Server responses include caching directives in headers. Upon subsequent requests, browsers may serve cached data if still fresh.
2. Content Delivery Networks: CDNs cache static content like images, stylesheets, and JavaScript files. They serve cached content from locations closer to users, reducing latency and load times.
3. Load Balancers: Some load balancers cache frequently requested data. This allows serving responses without engaging backend servers, reducing load and response times.
4. Message Brokers: Systems like Kafka can cache messages on disk per a retention policy. Consumers then pull messages according to their own schedule.
5. Services: Individual services often employ caching to improve data retrieval speeds, first checking in-memory caches before querying databases. Services may also utilize disk caching for larger datasets.
6. Distributed Caches: Systems like Redis cache key-value pairs across services, providing faster read/write capabilities compared to traditional databases.
7. Full-text Search Engines: Platforms like Elasticsearch index data for efficient text search. This index is effectively a form of cache, optimized for quick text search retrieval.
8. Databases: There are specialized mechanisms to enhance performance, some of which include caching concepts:
- Bufferpool: This is a cache within the database that holds copies of data pages. It allows for quick reads and writes to temporary storage in memory, reducing the need to access data from disk.
- Materialized Views: They are similar to caches in that they store the results of computationally expensive queries. The database can return these precomputed results quickly, rather than recalculating them.
–
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): bit.ly/496keA7

3
76
333
21,210
21 Apr 2024
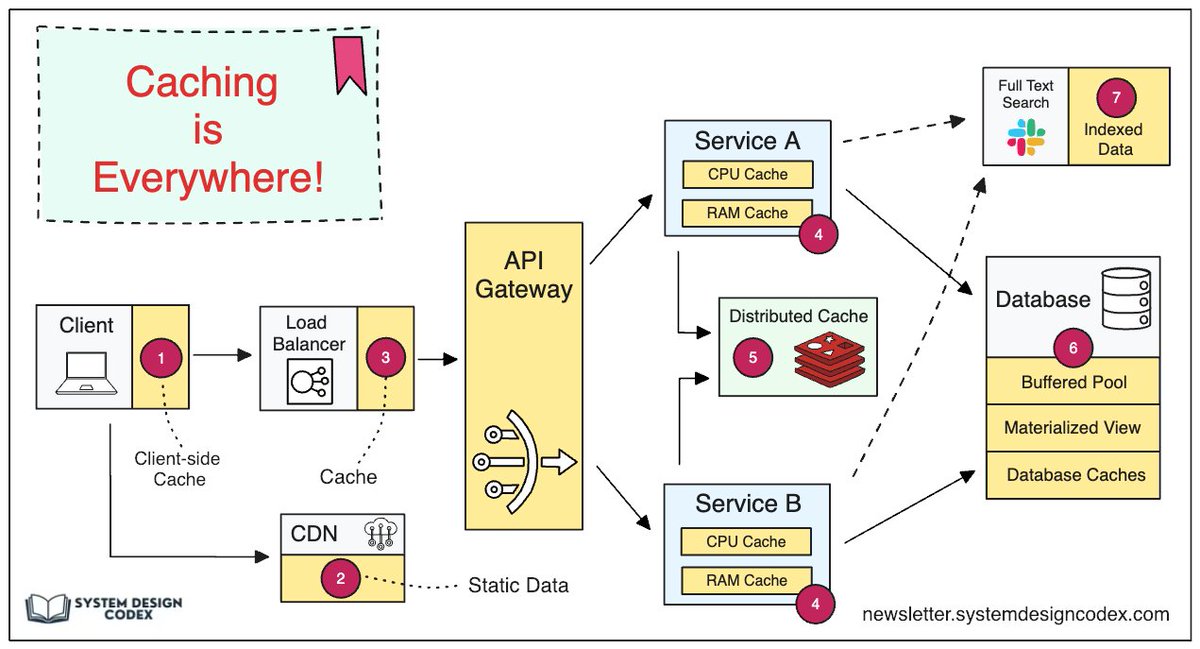
Data is cached everywhere, from the front end to the back end!
This diagram illustrates where we cache data in a typical architecture.
There are 𝐦𝐮𝐥𝐭𝐢𝐩𝐥𝐞 𝐥𝐚𝐲𝐞𝐫𝐬 along the flow.
🔹 1. Client apps: HTTP responses can be cached by the browser. We request data over HTTP for the first time, and it is returned with an expiry policy in the HTTP header; we request data again, and the client app tries to retrieve the data from the browser cache first.
🔹 2. CDN: CDN caches static web resources. The clients can retrieve data from a CDN node nearby.
🔹 3. Load Balancer: The load Balancer can cache resources as well.
🔹 4. Messaging infra: Message brokers store messages on disk first, and then consumers retrieve them at their own pace. Depending on the retention policy, the data is cached in Kafka clusters for a period of time.
🔹 5. Services: There are multiple layers of cache in a service. If the data is not cached in the CPU cache, the service will try to retrieve the data from memory. Sometimes the service has a second-level cache to store data on disk.
🔹 6. Distributed Cache: Distributed cache like Redis hold key-value pairs for multiple services in memory. It provides much better read/write performance than the database.
🔹 7. Full-text Search: we sometimes need to use full-text searches like Elastic Search for document search or log search. A copy of data is indexed in the search engine as well.
🔹 8. Database: Even in the database, we have different levels of caches:
- WAL(Write-ahead Log): data is written to WAL first before building the B tree index
- Bufferpool: A memory area allocated to cache query results
- Materialized View: Pre-compute query results and store them in the database tables for better query performance
- Transaction log: record all the transactions and database updates
- Replication Log: used to record the replication state in a database cluster
Over to you: With the data cached at so many levels, how can we guarantee the 𝐬𝐞𝐧𝐬𝐢𝐭𝐢𝐯𝐞 𝐮𝐬𝐞𝐫 𝐝𝐚𝐭𝐚 is completely erased from the systems?
–
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): bit.ly/3KCnWXq
1
95
449
32,650
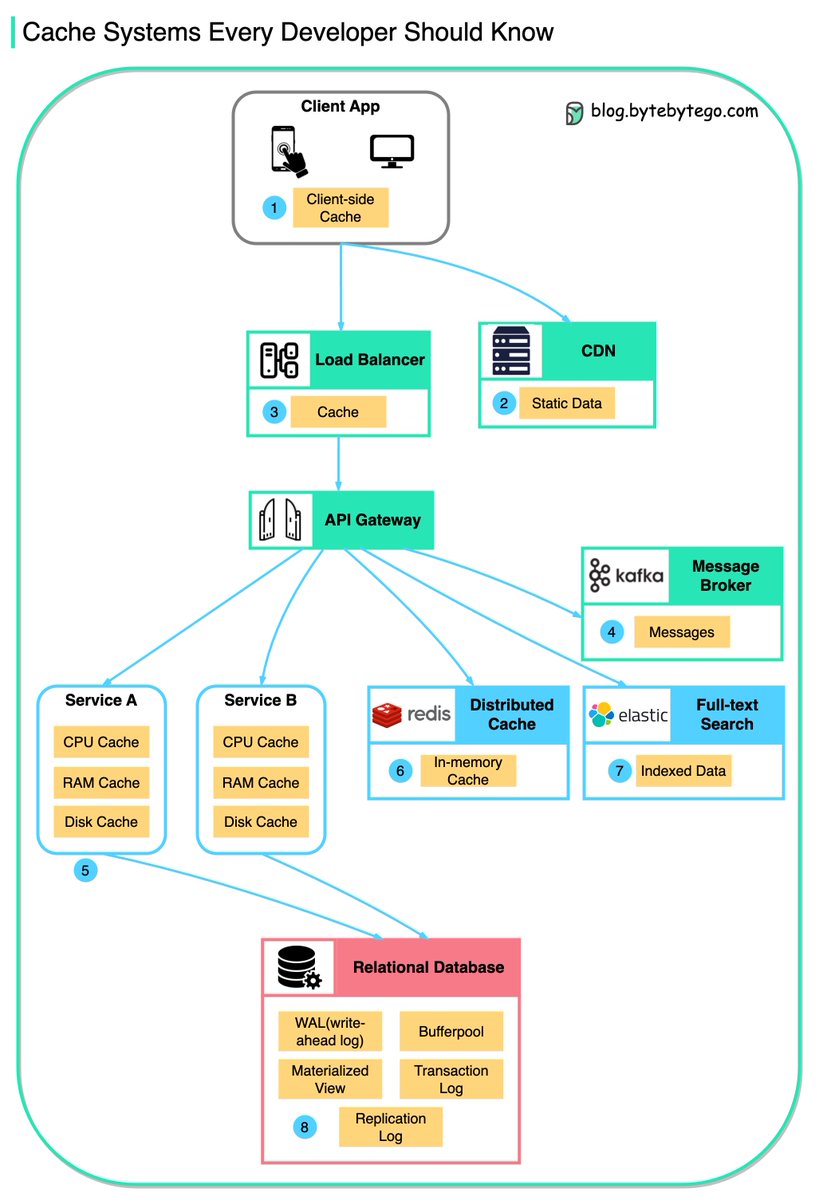
Data is cached everywhere, from the client-facing side to backend systems
Let's look at the many caching layers:
1. Client Apps: Browsers cache HTTP responses. Server responses include caching directives in headers. Upon subsequent requests, browsers may serve cached data if still fresh.
2. Content Delivery Networks: CDNs cache static content like images, stylesheets, and JavaScript files. They serve cached content from locations closer to users, reducing latency and load times.
3. Load Balancers: Some load balancers cache frequently requested data. This allows serving responses without engaging backend servers, reducing load and response times.
4. Message Brokers: Systems like Kafka can cache messages on disk per a retention policy. Consumers then pull messages according to their own schedule.
5. Services: Individual services often employ caching to improve data retrieval speeds, first checking in-memory caches before querying databases. Services may also utilize disk caching for larger datasets.
6. Distributed Caches: Systems like Redis cache key-value pairs across services, providing faster read/write capabilities compared to traditional databases.
7. Full-text Search Engines: Platforms like Elasticsearch index data for efficient text search. This index is effectively a form of cache, optimized for quick text search retrieval.
8. Databases: There are specialized mechanisms to enhance performance, some of which include caching concepts:
- Bufferpool: This is a cache within the database that holds copies of data pages. It allows for quick reads and writes to temporary storage in memory, reducing the need to access data from disk.
- Materialized Views: They are similar to caches in that they store the results of computationally expensive queries. The database can return these precomputed results quickly, rather than recalculating them.
–
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): bit.ly/496keA7
2
66
288
13,541
8 Mar 2024
Caching is not just about using a distributed cache.
It happens at every stage of your application stack - right from the front-end app to the database.
The only thing that changes is the scope.
[1] Front End Application
Browsers cache stuff all the time. HTTP responses, asset files, HTML pages and so on.
Developers can set the caching directives in response headers to control the behavior.
[2] Content Delivery Networks
CDNs can cache static content like images, stylesheets and JS files.
Their advantage is caching stuff closer to the users, reducing latency in the process.
[3] Load Balancers
Some load balancers can also cache frequently accessed data.
Responses can be served without calling the backend server. This improves the response times and also reduces the load on the server or database.
[4] Service Instance Cache
Service instances can employ their own caching solutions to boost performance.
This can be in the form of in-memory caches that are checked before fetching from the database.
[5] Distributed Cache
A more robust caching solution can use distributed caches like Redis. They help with faster reads and writes than going to a traditional relational database.
[6] Full-text Search Tools
Searching through tons of text information is a time-consuming task.
Tools like ElasticSearch help index the data for faster text search, effectively acting as a cache.
[7] Databases
You might think that databases always fetch from the disk.
But databases also use special caching mechanisms. For example, a Bufferpool is like a cache within the database that holds data pages to support faster reads.
Also, Materialized Views store results of pre-computed results of expensive queries for faster access
Lastly, many new-age databases have their own built-in cache solutions.
So - what types of caching solutions have you used?
9
92
397
21,001
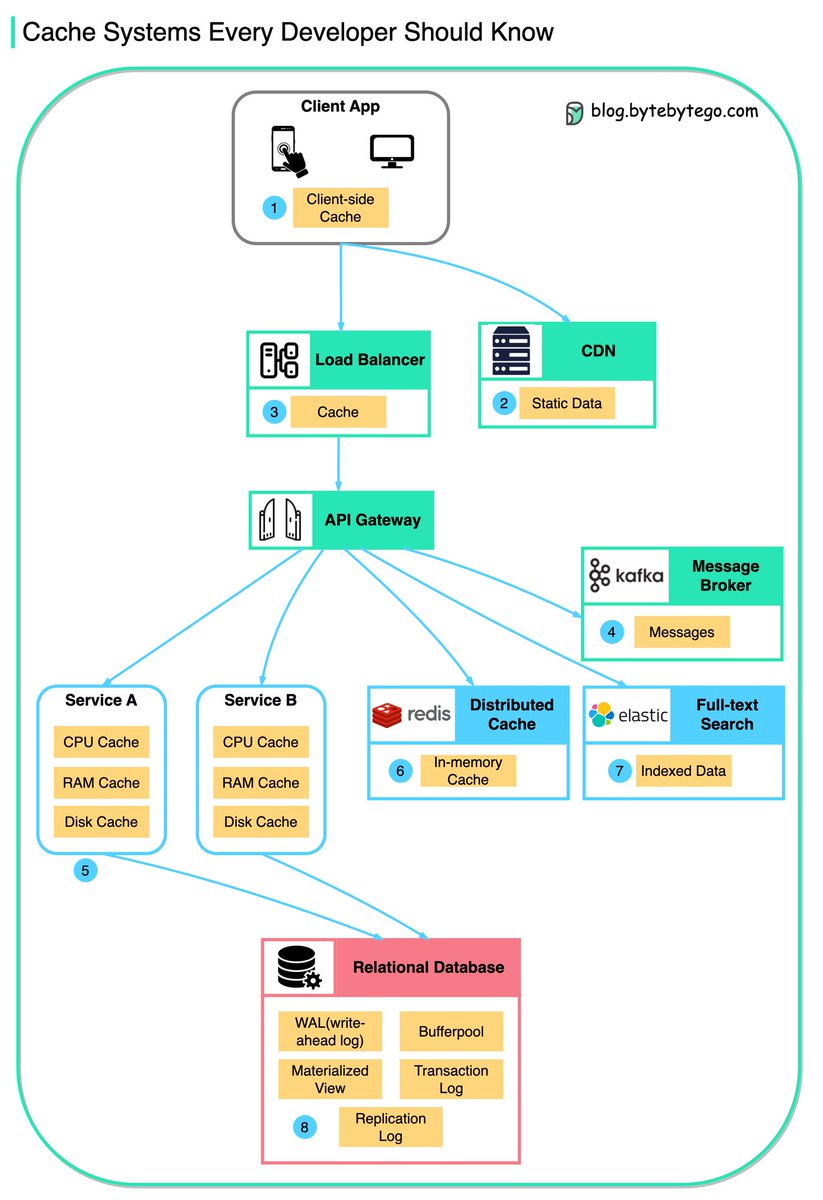
Data is cached at many stages, from the client-facing side to backend systems. Let's look at the many caching layers:
1. Client Apps: Browsers cache HTTP responses. Server responses include caching directives in headers. Upon subsequent requests, browsers may serve cached data if still fresh.
2. Content Delivery Networks: CDNs cache static content like images, stylesheets, and JavaScript files. They serve cached content from locations closer to users, reducing latency and load times.
3. Load Balancers: Some load balancers cache frequently requested data. This allows serving responses without engaging backend servers, reducing load and response times.
4. Message Brokers: Systems like Kafka can cache messages on disk per a retention policy. Consumers then pull messages according to their own schedule.
5. Services: Individual services often employ caching to improve data retrieval speeds, first checking in-memory caches before querying databases. Services may also utilize disk caching for larger datasets.
6. Distributed Caches: Systems like Redis cache key-value pairs across services, providing faster read/write capabilities compared to traditional databases.
7. Full-text Search Engines: Platforms like Elasticsearch index data for efficient text search. This index is effectively a form of cache, optimized for quick text search retrieval.
8. Databases: There are specialized mechanisms to enhance performance, some of which include caching concepts:
- Bufferpool: This is a cache within the database that holds copies of data pages. It allows for quick reads and writes to temporary storage in memory, reducing the need to access data from disk.
- Materialized Views: They are similar to caches in that they store the results of computationally expensive queries. The database can return these precomputed results quickly, rather than recalculating them.
–
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): bit.ly/496keA7
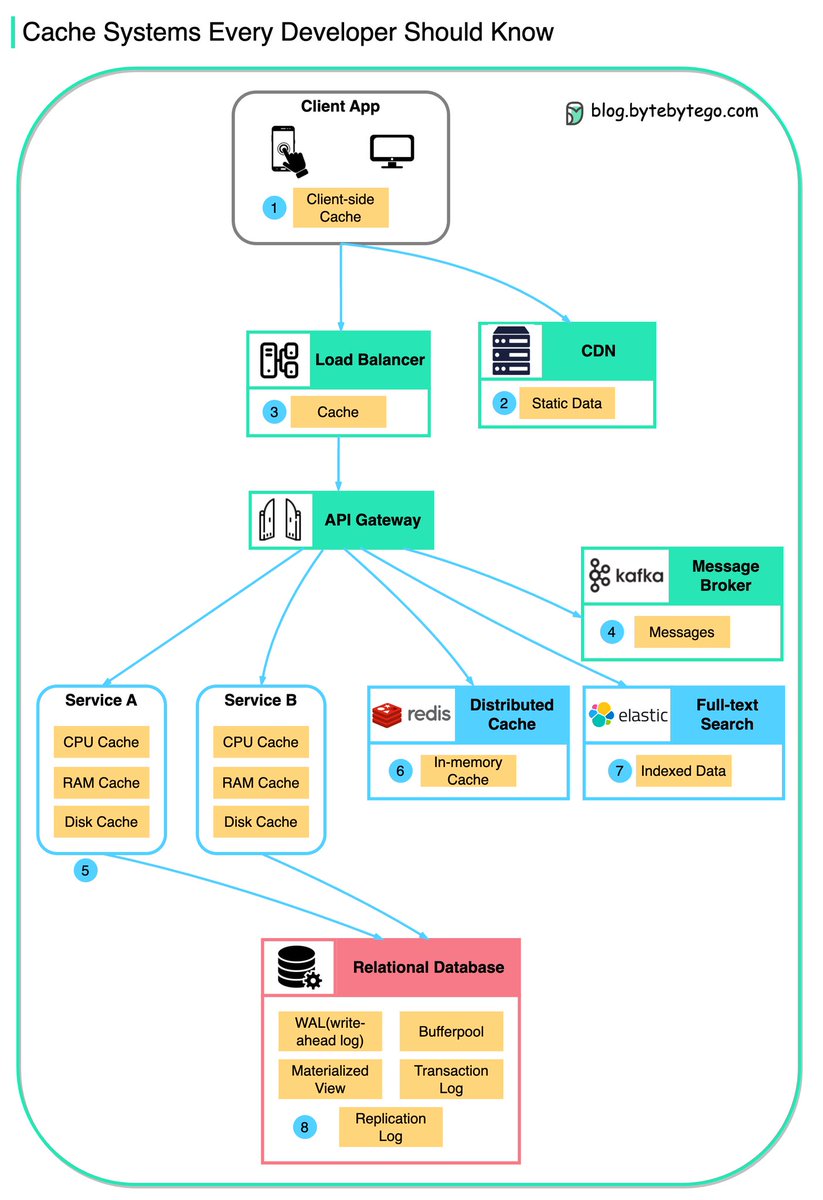
ALT A diagram illustrating various cache systems used in software development, showing client-side, CDN, load balancer, message broker, service-level, distributed, full-text search, and database caching layers.
2
128
461
23,851
10 Feb 2024
Data is cached everywhere, from the front end to the back end!
This diagram illustrates where we cache data in a typical architecture.
There are 𝐦𝐮𝐥𝐭𝐢𝐩𝐥𝐞 𝐥𝐚𝐲𝐞𝐫𝐬 along the flow.
🔹 1. Client apps: HTTP responses can be cached by the browser. We request data over HTTP for the first time, and it is returned with an expiry policy in the HTTP header; we request data again, and the client app tries to retrieve the data from the browser cache first.
🔹 2. CDN: CDN caches static web resources. The clients can retrieve data from a CDN node nearby.
🔹 3. Load Balancer: The load Balancer can cache resources as well.
🔹 4. Messaging infra: Message brokers store messages on disk first, and then consumers retrieve them at their own pace. Depending on the retention policy, the data is cached in Kafka clusters for a period of time.
🔹 5. Services: There are multiple layers of cache in a service. If the data is not cached in the CPU cache, the service will try to retrieve the data from memory. Sometimes the service has a second-level cache to store data on disk.
🔹 6. Distributed Cache: Distributed cache like Redis hold key-value pairs for multiple services in memory. It provides much better read/write performance than the database.
🔹 7. Full-text Search: we sometimes need to use full-text searches like Elastic Search for document search or log search. A copy of data is indexed in the search engine as well.
🔹 8. Database: Even in the database, we have different levels of caches:
- WAL(Write-ahead Log): data is written to WAL first before building the B tree index
- Bufferpool: A memory area allocated to cache query results
- Materialized View: Pre-compute query results and store them in the database tables for better query performance
- Transaction log: record all the transactions and database updates
- Replication Log: used to record the replication state in a database cluster
Over to you: With the data cached at so many levels, how can we guarantee the 𝐬𝐞𝐧𝐬𝐢𝐭𝐢𝐯𝐞 𝐮𝐬𝐞𝐫 𝐝𝐚𝐭𝐚 is completely erased from the systems?
–
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): bit.ly/3KCnWXq
2
97
382
25,018

20 Dec 2023
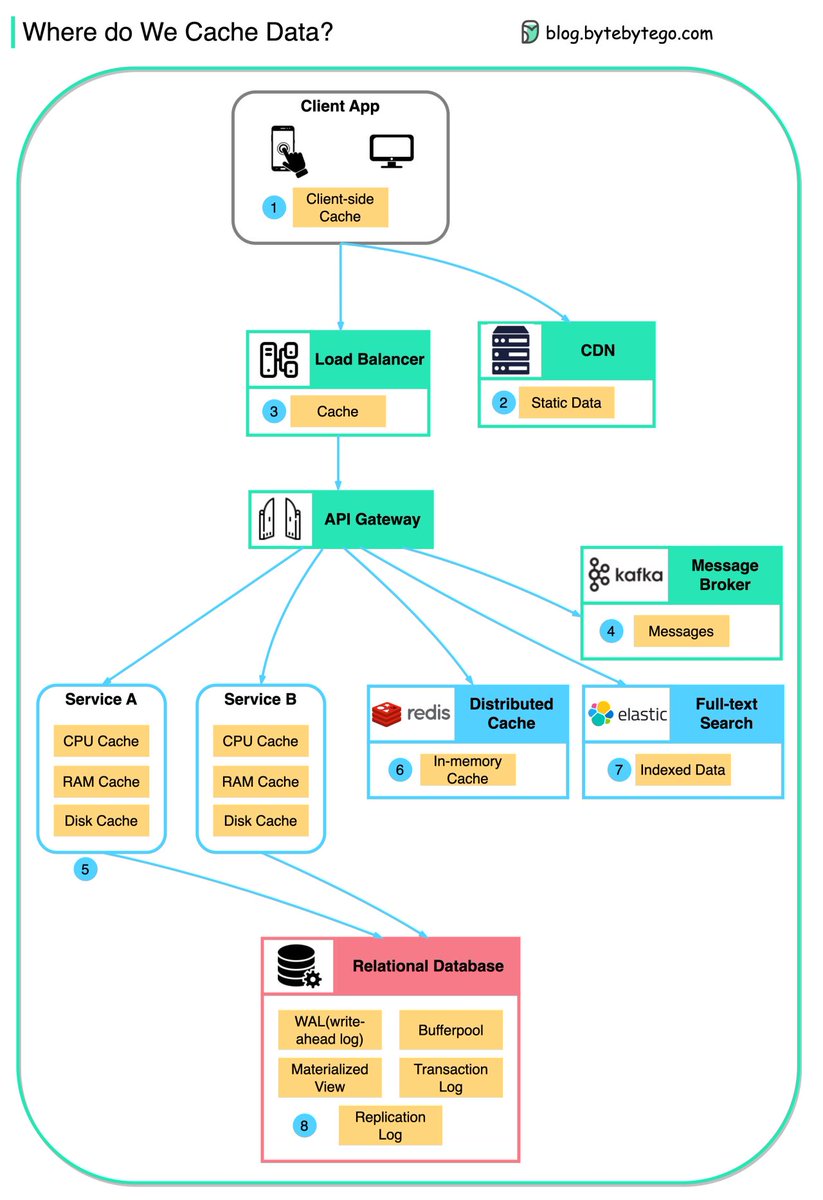
Where do we cache data?
Data is cached everywhere, from the front end to the back end!
This diagram illustrates where we cache data in a typical architecture.
There are multiple layers along the flow.
Client apps: HTTP responses can be cached by the browser. We request data over HTTP for the first time, and it is returned with an expiry policy in the HTTP header; we request data again, and the client app tries to retrieve the data from the browser cache first.
CDN: CDN caches static web resources. The clients can retrieve data from a CDN node nearby.
Load Balancer: The load Balancer can cache resources as well.
Messaging infra: Message brokers store messages on disk first, and then consumers retrieve them at their own pace. Depending on the retention policy, the data is cached in Kafka clusters for a period of time.
Services: There are multiple layers of cache in a service. If the data is not cached in the CPU cache, the service will try to retrieve the data from memory. Sometimes the service has a second-level cache to store data on disk.
Distributed Cache: Distributed cache like Redis hold key-value pairs for multiple services in memory. It provides much better read/write performance than the database.
Full-text Search: we sometimes need to use full-text searches like Elastic Search for document search or log search. A copy of data is indexed in the search engine as well.
Database: Even in the database, we have different levels of caches:
- WAL(Write-ahead Log): data is written to WAL first before building the B tree index
- Bufferpool: A memory area allocated to cache query results
- Materialized View: Pre-compute query results and store them in the database tables for better query performance
Transaction log: record all the transactions and database updates
Replication Log: used to record the replication state in a database cluster
Over to you: With the data cached at so many levels, how can we guarantee the sensitive user data is completely erased from the systems?
--
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): bit.ly/3KCnWXq

5
112
456
32,542

14 Dec 2023
Um 9 Uhr darf ich mit meinem Vortrag zum Thema Bufferpool-Fragmentierung den SQL Server Track im Raum Okzident auf den IT-Tagen in Frankfurt eröffnen.
#ittage #ittage2023

3
202