

Pentest-AI combines 17 specialized agents, 200 security tools, MCP integration, exploit chaining, PoC validation, and automated reporting into a single offensive security framework.
📦 Repo: github.com/0xSteph/pentest-a…
#CyberSecurity #BugBounty #Pentesting #AI #InfoSec #ClaudeCode
2


ClaudeCodeさわったことないんですよね🥲新しいことにぶち込まれると恐縮するので、まずはその人のツイート盗み見して勉強してみます!!ありがとうございます!!
2
みほ🌠星と創作を愛する🐱クリエイター retweeted

📘\出版のお知らせ/📘
『いちばんやさしいChatGPT Codexの教科書』
✅ 最近騒がれ始めたので気になる
✅ ChatGPTの画面で見かけてはいるが…
✅ ClaudeCodeとの違いがわからん
ド素人の私がいろいろ試してみました☺️
びっくりする機能満載でしたよ✨
KUで無料だよ✌️
amazon.co.jp/dp/B0H57T3ZM3

7
4
15
177

ClaudeCode使って個人開発してる人みんなゼッッッタイ設定した方がいいです!!!
効率化半端ないです!

Claude Code使ってる人へ
「コーディング終わったのに気づかずずっと待ってた」
あるある解消できます🔔
入力待ちになったときClaude codeが音を鳴らして教えてくれます!
やり方はClaude codeに指示するだけ❗️👇
40

14m
X見てたら同じようにClaudeCodeが暴走してる人、まぁまぁいた。
作業の途中で突然めちゃくちゃ独り言を言い出したり、すごい反省文書いてきたりと、まぁまぁホラー。
久々に自分でコード書いていくかなー
1
21

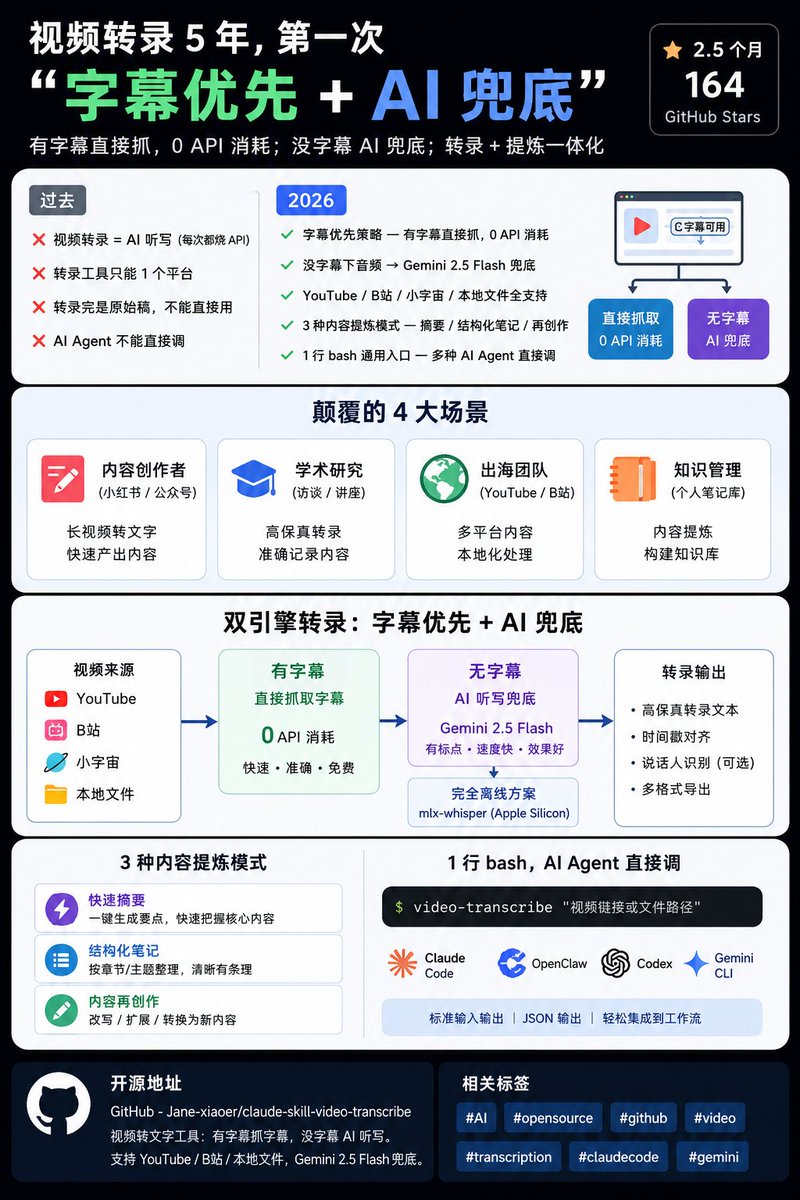
视频转录 5 年,第一次"字幕优先 AI 兜底"。
过去:
❌ 视频转录 = AI 听写(每次都烧 API)
❌ 转录工具只能 1 个平台
❌ 转录完是原始稿,不能直接用
❌ AI Agent 不能直接调
2026:
✅ 字幕优先策略 — 有字幕直接抓,0 API 消耗
✅ 没字幕下音频 → Gemini 2.5 Flash 兜底
✅ YouTube / B站 / 小宇宙 / 本地文件全支持
✅ 3 种内容提炼模式 — 快速摘要 / 结构化笔记 / 内容再创作
✅ 1 行 bash 通用入口 — Claude Code / OpenClaw / Codex / Gemini CLI
🔗 内容创作者(小红书 / 公众号)— 长视频转文字
🔗 学术研究(访谈 / 讲座)— 高保真转录
🔗 出海团队(YouTube / B站内容本地化)— 多平台
🔗 知识管理(个人笔记库)— 内容提炼
🔗 GitHub: GitHub - Jane-xiaoer/claude-skill-video-transcribe: 视频转文字工具:有字幕抓字幕,没字幕 AI 听写。支持 YouTube/B站/本地文件,Gemi
#AI #opensource #github #video #transcription #claudecode #gemini
31

Hey @chopra_tejas rtk was disabled. Also had a similar behavior with claudecode where i saw it recognizing the content was chunked and tried to read it in chunks
5

21m
Been thinking about the Fable 5 thing all day and I think people are mad at the wrong part.
On the surface it's that Anthropic was quietly nerfing the model when you ask about AI training stuff — like, you'd get an answer but it was secretly the dumber version, and they didn't tell you. People found it because someone actually read page 247 of the system card. Wild.
But the more I look at it, the more I think that's not actually the story.
Anthropic got hit this hard because they spent three years being "the honest lab." OpenAI does shadow downgrades all the time and people just shrug. Anthropic does it once and gets called anti-science.
Which is sort of the cost of having a brand, I guess. When you build the whole identity on one thing, you don't get to pick the day people start enforcing it on you.
The way I'm reading it — they're stuck in a triangle they can't get out of. Strong model, open to everyone, fully transparent. You can't really have all three at once. Mythos 5 is the strongest but it's locked to a tiny group. Opus 4.8 is open and honest but a tier weaker. Fable 5 tried to do all three and transparency was the one that broke.
Useful to think about for my own work too. Tapi is nothing like Anthropic in scale, but the same shape of tradeoff is there — ship fast, work for everyone, be honest when it doesn't. Pick two, can't fake the third.
This week's gonna be rough for them. Honestly they'll probably bounce back faster than most people think. The thing that actually changed is that "we mentioned it in a footnote" doesn't work anymore. If it matters, it has to be on page one.
Page 247 is page one now.
#claude #fable #Anthropic #LLM #claudecode

Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
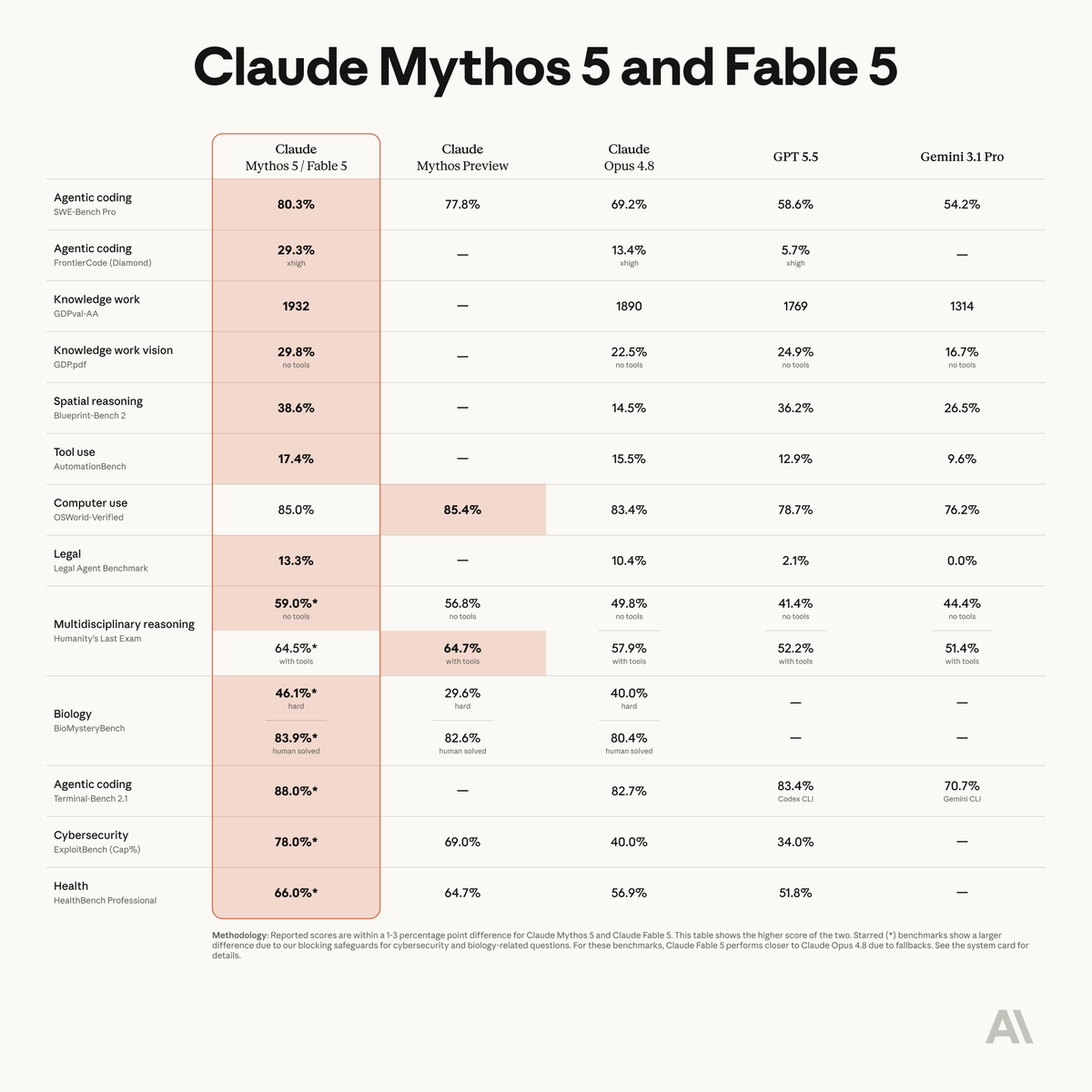
ALT Benchmark table titled Mythos 5 & Fable 5, comparing Claude Mythos 5 and Fable 5 against Claude Mythos Preview, Claude Opus 4.8, GPT 5.5, and Gemini 3.1 Pro.
96

CodexかClaudeCodeに投げ込む用のリポジトリです。自キャラでぐるぐるアバターを作りたい方が居たら参考にしてください。
github.com/rotejin/tomari-gu…


1
65
400
22,660

※(6/14)。くた・れAI 。AI依存症になるな ! AIを恋人にするな ! AIを使うな、自分で考えて文章を書け ! ! 審決の取り消し、(被告=東洋ライスの権利無効)。知的財産高等裁判所により「権利無効」とされた3 @kbozon note.com/ykbozon/n/n41eb73ea…
※(6/14)。くた・れAI 。AI依存症になるな ! AIを恋人にするな ! AIを使うな、自分で考えて文章を書け ! !
審決の取り消し、(被告=東洋ライスの権利無効)。
知的財産高等裁判所により「権利無効」とされた314件目のものです。
drive.google.com/file/d/1EKE…
docs.google.com/spreadsheets…
特許権者である東洋ライス株式会社は、利害関係者と思われる幸南食糧株式会社に無効審判(無効2015-800174)を起こされましたが、特許庁の審判部において「審判請求は成り立たない」とされて特許権を維持しました。
敗れた幸南食糧株式会社は、これを不服として知的財産高等裁判所に訴えました。
知的財産高等裁判所は、「特許庁が無効2015-800174号事件について平成28年1月3日にした審決を取り消す。」として、幸南食糧株式会社の訴えを認めました。
その中で、知的財産高等裁判所は、「特許法36条6項2号の明確性要件を欠く場合,特許を受けることはできないとされることに変わりはない。請求項1及び2の記載が,いずれも明確性要件を欠く。」としています。
特許庁の審査段階では、審査官(長井啓子)が【検索論理式】を作り、先行技術文献として特願2005-093152号(特開2006-271229号)を含む9件を出願人に提示しています。
そして、拒絶査定を下しました。
出願人の東洋ライス株式会社は、これを不服として、審判に持ち込みました。
審判請求人から「手続補正書」が提出されて、前置移管がなされ、審査官(長井啓子)は「前置報告書」の中で「特許請求の範囲」に記載が不明確で、拒絶されるべきものとしています。
一方、審判官(高橋三成 ら)は、「拒絶理由通知書」を発し、その中で特許法第36条第6項第2号の要件を満たしていないとしました。
審判請求人は、「手続補正書」を提出し、みごと特許権者となりました。
次に、利害関係者と思われる幸南食糧株式会社は、東洋ライス株式会社の保有する本件特許5306571に対して、「無効審判(無効2015-800174 (1))」を起こしました。
この無効審判においては、審判官(鳥居稔 ら)は、「請求人の主張する無効理由1ないし無効理由3および提出した証拠方法によっては特許発明1および特許発明2に係る特許を無効とすることはできない。」として、特許権は維持されました
そして、これを不服として、幸南食糧株式会社は、知的財産高等裁判所に提訴しました。
しかしながら、上記のとおり知的財産高等裁判所において、「特許無効」との判断がなされました。
なお、この知的財産高等裁判所の判断に基づいて、特許庁の審判部(紀本孝 ら)は、(無効2015-800174(2))において東洋ライス株式会社の保有する「特許5306571」を「無効」とするとの判断を下し、結局本件特許は「権利無効」が確定しました。
特許庁の審判官のか弱い判断に基づいての、出願人への特許付与は許されません。
ここで、本件特許公開(特開2006-314901)の「出願情報」のうち「FI」と「Fターム」を、本エクセル資料の2シート目以降に挙げておきました。
(ハッシュタグ)
#OpenAI #Claude #ChatGPT #Gemini #Copilot #AI #生成AI #知財 #特許 #特許調査 #専利 #チャットGPT #GPT-5 #INPIT #JPlatPat #note #JPO #USPTO #EPO #Patent #GPT #Threads #Bing #DX #IT #DeepSeek #AI画像生成 #IPランドスケープ #深層学習 #仕事 #ディープラーニング #ビジネス #ビジネスモデル #知財戦略 #知的財産 #知的財産権 #知的財産高等裁判所 #特許法 #特許庁 #特許事務所 #特許分類 #ClaudeCode
107



shnch3211 retweeted

Jun 12
ClaudeCodeの自動化はこの仕組みに落ち着いた。「おはよう」をトリガーにして、複数のスキルがそれぞれ/loop実行される。
業務系の自動化であれば夜間実行する必要がないのでこれで十分。
Agent Viewを使って各ワーカーのセッション状況確認可能。
たぶん15日以降もサブスク内で使えるはず。(たぶん)

10
52
857
144,947

31m
美国政府紧急限制外国人访问 Anthropic 旗下 Claude 的最先进模型
Mythos 5 神话 / Fable5 寓言
原来是Fable 5这模型太强大了,能自动阅读代码库找到安全漏洞。
并可以为黑客提供攻击思路
对于这事大家怎么看?
#Claudecode #Fable #Mythos

88