
being lightskin really is something cuas eyou stand next to mixed ppl and everyone thing you one of them

Brunson is about to be the cause of even more racially ambiguous children named Jalen. This is like a second meteor strike after the Jalen Rose one.
1
1
330

Jose Cuas is pitching the rest of the 10th, which is even more familiar to Royals fans. Storm Chasers really catering to their expanded audience
1
521

Hugging Face Daily Papers — 2026-06-13
44 papers today. Full list with arXiv links:
1. EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
Highlight: Large language model (LLM) agents have achieved strong performance on a wide range of benchmarks, yet most evaluations assume static environments.
arXiv: arxiv.org/abs/2606.13681
2. MiniMax Sparse Attention
Highlight: Ultra-long-context capability is becoming indispensable for frontier LLMs: agentic workflows, repository-scale code reasoning, and persistent memor.
arXiv: arxiv.org/abs/2606.13392
3. WeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
Highlight: Computer-use agents (CUAs) increasingly operate in runtimes that combine visual desktop control, command-line execution, code editing, browsers, an.
arXiv: arxiv.org/abs/2606.09426
4. SpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning
Highlight: Spatial reasoning, the ability to determine where objects are, how they relate, and how they move in 3D, remains a fundamental challenge for vision.
arXiv: arxiv.org/abs/2606.13673
5. InterleaveThinker: Reinforcing Agentic Interleaved Generation
Highlight: Recent image generators have demonstrated impressive photorealism and instruction-following capabilities in single-image generation and editing. Ho.
arXiv: arxiv.org/abs/2606.13679
6. MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Population-Level Test-Time Scaling
Highlight: We present MaxProof, a population-level test-time scaling framework for competition-level mathematical proof in the MiniMax-M3 series. M3 first tra.
arXiv: arxiv.org/abs/2606.13473
7. Robust-U1: Can MLLMs Self-Recover Corrupted Visual Content for Robust Understanding?
Highlight: Multimodal Large Language Models (MLLMs) have demonstrated remarkable success in visual understanding, yet their performance degrades significantly.
arXiv: arxiv.org/abs/2606.08063
8. FORT-Searcher: Synthesizing Shortcut-Resistant Search Tasks for Training Deep Search Agents
Highlight: Training deep search agents requires verifiable questions whose answers remain unavailable until sufficient evidence has been acquired through sear.
arXiv: arxiv.org/abs/2606.12087
9. LabVLA: Grounding Vision-Language-Action Models in Scientific Laboratories
Highlight: Scientific laboratories increasingly rely on AI systems to reason about experiments, but the physical act of doing science remains largely outside.
arXiv: arxiv.org/abs/2606.13578
10. HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
Highlight: Holistic visual tokenizers are fundamental to unified multimodal models (UMMs) as they map diverse visual inputs into a unified representation spac.
arXiv: arxiv.org/abs/2606.13289
11. N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
Highlight: The success of Large Language Models in mathematical reasoning relies heavily on the generation of diverse and valid solution paths during the roll.
arXiv: arxiv.org/abs/2606.10768
12. EurekAgent: Agent Environment Engineering is All You Need For Autonomous Scientific Discovery
Highlight: LLM-based agents have shown increasing potential in automating scientific discovery. Given an optimizable metric and an execution environment, they.
arXiv: arxiv.org/abs/2606.13662
13. Demystifying Hidden-State Recurrence: Switchable Latent Reasoning with On-Policy Reinforcement Learning
Highlight: Latent chain-of-thought compresses reasoning by replacing visible reasoning traces with continuous hidden-state recurrence, but existing formulatio.
arXiv: arxiv.org/abs/2606.13106
14. VideoMDM: Towards 3D Human Motion Generation From 2D Supervision
Highlight: We introduce VideoMDM, a diffusion-based framework that trains 3D human motion priors directly from accurate 2D poses extracted from monocular vide.
arXiv: arxiv.org/abs/2606.13364
15. VIA-SD: Verification via Intra-Model Routing for Speculative Decoding
Highlight: Speculative decoding (SD) addresses the high inference costs of LLMs by having lightweight drafters generate candidates for large verifiers to vali.
arXiv: arxiv.org/abs/2606.12243
16. Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
Highlight: Despite generating increasingly photorealistic images, text-to-image (T2I) models still exhibit localized, subtle, and structurally complex failure.
arXiv: arxiv.org/abs/2606.06113
17. From 2D Grids to 1D Tokens: Reforming Shared Representations for Multimodal Image Fusion
Highlight: Multimodal image fusion aims to integrate complementary information from different modalities into a fused image that preserves rich local details.
arXiv: arxiv.org/abs/2606.12303
18. MoVerse: Real-Time Video World Modeling with Panoramic Gaussian Scaffold
Highlight: We present MoVerse, a real-time video world model that creates an interactively navigable scene from a single narrow-field-of-view image. This sett.
arXiv: arxiv.org/abs/2606.13376
19. TreeSeeker: Tree-Structured Trial, Error, and Return in Deep Search
Highlight: Deep search requires agents to answer complex questions through multi-step web search, browsing, evidence comparison, and synthesis. A central chal.
arXiv: arxiv.org/abs/2606.11662
20. HarnessBridge: Learnable Bidirectional Controller for LLM Agent Harness
Highlight: Large language models are increasingly deployed as agents for long-horizon tasks, yet their performance is shaped not only by model capability and.
arXiv: arxiv.org/abs/2606.12882
21. Risk Under Pressure: Compute-Aware Evaluation of Adversarial Robustness in Language Models
Highlight: Adversarial robustness evaluations of large language models (LLMs) typically report attack success rate (ASR) under fixed query budgets, implicitly.
arXiv: arxiv.org/abs/2606.11409
22. High-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
Highlight: Few-step diffusion distillation has become increasingly mature for 4-8-step generation, yet pushing further to 2 steps remains challenging. In this.
arXiv: arxiv.org/abs/2606.12575
23. Visual Para-Thinker : A Single-Policy Multi-Agent Framework for Visual Reasoning
Highlight: Visual reasoning requires integrating evidence distributed across regions, attributes, and relations, making single-chain reasoning prone to early.
arXiv: arxiv.org/abs/2606.09290
24. SG-OPD: Sign-Gated On-Policy Distillation via Sign-Consistency Gating and Phased Teacher Sampling
Highlight: On-policy distillation (OPD) trains a student on its own trajectories with dense per-token supervision from a stronger teacher, and often outperfor.
arXiv: arxiv.org/abs/2606.09304
25. Rethinking Psychometric Evaluation of LLMs: When and Why Self-Reports Predict Behavior
Highlight: Anticipating LLM behavioral tendencies from low-cost psychometric probes is critical for safe deployment, but only if self-reports (SR) reliably pr.
arXiv: arxiv.org/abs/2606.12730
26. EvoBrowseComp: Benchmarking Search Agents on Evolving Knowledge
Highlight: Search Agents -- large language models augmented with search tools -- have intensified the need for future-proof evaluation benchmarks. Existing be.
arXiv: arxiv.org/abs/2606.13120
27. MaskAlign: Token-Subset Representation Alignment for Efficient Diffusion Training
Highlight: Representation alignment with pretrained vision models has recently shown strong potential for accelerating diffusion transformer training. By alig.
arXiv: arxiv.org/abs/2606.08788
28. See What I See, Know What I Think: Dense Latent Communication Across Heterogeneous Agents
Highlight: Multi-agent systems communicate mostly through text, paying a lossy and expensive decode and re-encode cost. KV-cache communication is a promising.
arXiv: arxiv.org/abs/2606.13594
29. Evoflux: Inference-Time Evolution of Executable Tool Workflows for Compact Agents
Highlight: Compact language models (LMs) reduce cost, latency, and deployment risk for tool agents. Yet MCP-style tool use requires more than isolated functio.
arXiv: arxiv.org/abs/2606.12674
30. MuJoCo-Drones-Gym: A GPU-Accelerated Multi-Drone Simulator for Control and Reinforcement Learning
Highlight: Robotic simulators are a cornerstone of modern research in aerial robotics, serving both as a vehicle for the development of new control algorithms.
arXiv: arxiv.org/abs/2606.08039
31. Getting Better at Working With You: Compiling User Corrections into Runtime Enforcement for Coding Agents
Highlight: Interactive LLM agents are becoming part of daily work, but they do not reliably become easier to work with over time: a correction remembered in o.
arXiv: arxiv.org/abs/2606.13174
32. ArogyaSutra: A Multi-Agent Framework for Multimodal Medical Reasoning in Indic Languages
Highlight: Multimodal Large Language Models (MLLMs) have shown promising reasoning capabilities in general domains, yet their performance remains limited in s.
arXiv: arxiv.org/abs/2606.13572
33. $\texttt{WEAVER}$, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
Highlight: The potential impacts of world models (WMs, i.e., learned simulators) on robotics are far-reaching -- policy evaluation, policy improvement, and te.
arXiv: arxiv.org/abs/2606.13672
34. Surflo: Consistent 3D Surface Flow Model with Global State
Highlight: Geometry is invariant to viewpoint, which makes any collection of images a redundant encoding of a single 3D state. Existing feed-forward reconstru.
arXiv: arxiv.org/abs/2606.13644
35. WebChallenger: A Reliable and Efficient Generalist Web Agent
Highlight: Autonomous web navigation remains challenging for LLM agents, and the strongest generalist systems rely on proprietary reasoning models whose infer.
arXiv: arxiv.org/abs/2606.10423
36. Flash-GMM: A Memory-Efficient Kernel for Scalable Soft Clustering
Highlight: We present \textbf{Flash-GMM}, a fused Triton kernel for efficient computation of Gaussian Mixture Models (GMMs) over large-scale data in a single.
arXiv: arxiv.org/abs/2606.10896
37. IDEAL: In-DEpth ALignment Makes A Discrete Representation AutoEncoder
Highlight: Built on pretrained vision foundation models (VFMs), representation autoencoders (RAEs) have recently emerged as a promising approach for construct.
arXiv: arxiv.org/abs/2606.11096
38. Revisiting Articulated Parts Perception in Robot Manipulation
Highlight: We are surrounded by various objects with movable, articulated parts, e.g., box, handle, door. An accurate and generalizable perception of articula.
arXiv: arxiv.org/abs/2606.08103
39. The Cold-Start Safety Gap in LLM Agents
Highlight: Are tool-calling LLM agents equally safe throughout a conversation? We discover they are not: agents are most vulnerable at the very start of a ses.
arXiv: arxiv.org/abs/2606.07867
40. ToolSense: A Diagnostic Framework for Auditing Parametric Tool Knowledge in LLMs
Highlight: Large language models deployed as agents over large tool catalogs face a critical tool-retrieval bottleneck. As embedding-based retrieval approache.
arXiv: arxiv.org/abs/2606.12451
41. A Stationary (and Therefore Compatible) Representation is All You Need
Highlight: Learning compatible representations aims to learn feature representations that can be used interchangeably over time whenever a model undergoes upd.
arXiv: arxiv.org/abs/2606.12488
42. PianoKontext: Expressive Performance Rendering from Deadpan Context
Highlight: Expressive performance rendering (EPR) aims to generate realistic performances constrained on sequences of notes. However, flow matching audio edit.
arXiv: arxiv.org/abs/2606.12282
43. Leveraging Morphology for Historical Script Metrological Analysis
Highlight: Advances in handwritten text recognition have enabled large-scale transcription of historical documents, but still provide limited access to interp.
arXiv: arxiv.org/abs/2606.09446
44. On the Limits of LLM Adaptability: Impact of Model-Internalized Priors on Annotation Task Performance
Highlight: Large Language Models (LLMs) are increasingly used for zero-shot annotation and LLM-as-a-judge tasks, yet their reliability hinges on how model-int.
arXiv: arxiv.org/abs/2606.00467
Trend summary:
- Agents / Computer-use / Spatial reasoning: 18
- Multimodal / Vision / Video: 10
- Reasoning / Math / RL: 7
- Other ML methods: 5
- LLMs / Efficient modeling: 3
- Audio / Speech: 1
Papers with code links found: 32/44
1
149

So Facebook . Haters are going nuts that his name was removed from the Kennedy center and they acting like he is getting removed from office . I hope it’s satanic bots. Cuas so don’t really want to think people are that stupid
1
1
40

Ganarle a Sra Ayuso. Ja ja ja cuas je je je 😜 vaya loca La Niña de la Curva
3

If armor is that easy to destroy it doesn't make sense to invest into it unless it's cheap, expendable. You either find a way to protect tanks against drones (APS, cUAS turrets, etc) or replace each expensive tank with dozens (if not hundreds) of cheap UGVs and UAVs.
1
27

Can I cut the Gordian knot by suggesting not that we hang back, but a focus on a balanced capability with drones/LMs a key part of the mix but not as an excuse to ditch heavy metal, artillery etc. Also CUAS. 50 years ago the tank was supposedly obsolete due to Sagger/RPG7 etc …
4
63

A ti cuas? Non t'inde faghes sa irgonza de iscrìere ca@@adas mannas gai?
5
SonOfSarcasm 🇩🇪 🇺🇦 🇮🇱 retweeted

X45/Litauen umfasst derzeit ~ 3000 Soldaten, Endstärke 4800 wird 12/27 erreicht sein, problemlos.
Die Drohnenabwehr (cUAS) ist im ArtBtl 455 in einer Bttr konzentriert. Flugabwehr stellt die FlaBttr mit IRIS-T SLM/SLS auf Boxer. Fliegerabwehr können alle.
@C_C_Codegeass_

"Ein Besuch zeigt: Die Brigade ist bestens ausgestattet, muss aber noch üben."
Da habt Ihr Euch aber klassisch täuschen lassen. Diese Brigade hat keinerlei Drohen- und Hubschrauberabwehr, damit ist sie überhaupt nicht bestens ausgestattet, wenn sie vom Schutz der Nato-Ostflanke schreiben.
Diese Brigade hat Probleme ihre Sollstärke zusammenzubekommen, weil es da eben nicht so rosig ist.
Wenn man wirklich wissen will wie jmd dasteht, dann kommt man unangemeldet, man kommt überraschend und inspiziert sofort die Ausstattung.
Aber man kündigt nie einen Besuch, Wochen vorher an.
UND wichtig (!)
Man lässt sich zeigen, was man sehen will, aber man lässt sich nicht vorführen, was man zu sehen hat.
4
2
22
3,382
Marios 🇬🇷 retweeted

Jun 10
⚔️🇨🇾 The upgraded version of the #Antigoni #CUAS HPM.
Made by Ecliptic Defence and Space. Stay tuned for more during #EUROSATORY 2026.
‼️More info: share.google/P9pphBnGMIoiOAK…

16
57
1,207

If we'd had the Centurion or Stryker CUAS variant protecting drone targets, I suspect their success wouldn't have been disproportionate. As it stands, it was. The wrong lessons are being learned from Iran, in that we could've ended Diesel and electrical infrastructure.
1
1
15

⎐كُـود⎐كوبِون⎐خـِصم⎐
⎐نون⎐
⊵S3Q⊴
⎐ايهرب⎐ايهيرب اهرب
⊵GCA5893⊴
⊴تيمو ⊴
⊵TEB72⊴
❮كارديال❯
A004
⎐نمشي⎐
⊵AABN⊴
⎐ريف⎐للعطور ⎐
⎐AX140⊴
ماكــس⎐
A9B
***
cUas
1

MBDA signing a JV memorandum with Ukrainian Armor is one of the more important defense-industrial signals of 2025, and it's being underpriced.
Europe's largest missile prime — maker of Storm Shadow, Meteor, Taurus, and a contributor to Patriot — is not partnering with a Ukrainian integrator for manufacturing capacity. It's partnering for IP. Specifically: C-UAS doctrine and deep strike integration refined under daily high-intensity fire. That feedback loop now compresses what used to be 5-10 year Western R&D cycles into weeks.
The economics have already inverted. Russia launches $20k Shaheds; legacy interceptors cost $2M per shot. The companies solving that math — Anduril, Shield AI, Allen Control Systems on the kinetic side, Saronic on maritime autonomy, Hadrian on the production stack — are absorbing Ukrainian combat data directly or indirectly. MBDA is institutionalizing the channel.
The read-through for private markets: battle-tested defense IP is the scarce asset of the next decade, and nearly all of it accrues to private companies long before any S-1. By the time these names hit public markets, the multiple has already re-rated. America 2030 gets built in the pre-IPO window, or not at all.
#defensetech #CUAS #privatemarkets #PreIPO
48
Pro retweeted

Jun 12
Σουιδικό CV90 ρε ρόλο CUAS με πυροβόλο 40mm και προγραμματιζόμενα πυρομαχικά 40x365mm.
Όπως φαίνεται στο βίντεο καταρίπτει ταχέως κινούμενο target UAV με μόλις 3 βολές.
Εδώ έχει συνηδητοποιήσει κανένας ότι δεν υέχουμε καμία απολυτως προστασία από τις ασσύμετρες απειλές;
Jun 10

Treino de militares suecos com viatura blindada "Luftvärnskanonvagn" 9040 (LVKV 9040), variante de defesa anti-aérea do blindado CV90, equipada com radar 360° PS-95 sobre a torre, emprega munições 3P de 40 mm (40×365mm R) para derrubar drone-alvo de treino "Raven", de tipologia "Shahed", de construção pela letã Temeso, no decurso do exercício multinacional "Baltic Zenith 2026", no Campo de Treino de Jūrmalciems, Nīca, Kurzeme Sul, Letónia, a 8 de Junho de 2026.
Produzida pela BAE Systems Bofors, a munição 3P, acrónimo que descreve três das características da sua tipologia, i.e., (i) pre-fragmentada, (ii) programável e (iii) com opção de detonação por proximidade, está disponível em calibre de 40 e 57 mm. Recebe informação de programação no momento de disparo que permite ajustar a sua operação táctica para o contexto anti-áereo ou de superfície (naval ou terrestre), para objectivos de maior ou menor dimensão, e com opção de detonação por contacto ou proximidade.
O drone-alvo Raven (lit. "Corvo") de produção pela empresa Temeso, com sede na capital da Letónia, Rīga, lançado por catapulta portátil (e com recuperação por paraquedas), tem 2 metros de envergadura de asa, um comprimento de 1,9 metros, motor de combustão à retaguarda, sustenta uma velocidade de 55 m/s, com um alcance operacional de 30 km, um peso máximo à descolagem de 18 kg com um "payload" (350x80x220mm) até 6 kg. A Temeso, em operação desde 2015, é, desde 2020, parte da Federação de Indústrias de Defesa e Segurança da Letónia.
O exercício "Baltic Zenith 2026" iniciou-se a 1 de Junho de 2026 e decorre ao longo de uma semana e meia até 10 de Junho de 2026, contando com a participação de forças da Letónia, Lituânia, Suécia e Canadá. Tem lugar no Campo de Treino de Jūrmalciems, georreferenciação 56.262499934750565, 20.98338856514214, fundado em 2017 na costa Leste do Mar Báltico.
A 24 de Outubro de 2025 as Força Armadas da Suécia anunciaram o envio em 2026 de um destacamento de blindados LVKV 90 para a Letónia, no contexto da força "NATO Multinational Brigade Latvia", reforçando as capacidades de defesa anti-aérea desta República do Báltico.
Vídeo via Forças Armadas ("Försvarsmakten") da Suécia. Foto drone Raven via TV Kurzeme | ReTV. Fotograma de impacto seleccionado e editado por E&E.


3
7
43
1,115

Jun 13
Turkey does well for sure but software / sensor fusion wise US is far and ahead. Ukraine is at least battle tested especially with FPV and CUAS. But still I don’t think competition will be meaningful, even the American defense startups are signing partnerships everywhere
1
31

Jun 13
Wait why is the CUAS training looking like for the SHTF community? Just hoping shooting clays on the weekends will be sufficient?
Jun 12

skynet will use thermite drones to smoke out all the human preppers hiding in the forest... this is what the last stand will look like for many
Be ready
1
1
115

like ive been saying lately for the ones that do hurt the kids we need a millstone industry for the ones that cannot/refuse to be rehabilitated cuas i dont want tax dollars going to the ones that refuse just like the death penalty but i pray that doesnt have to happen
2
33
Flipp N Research retweeted

Jun 12
$ONDS
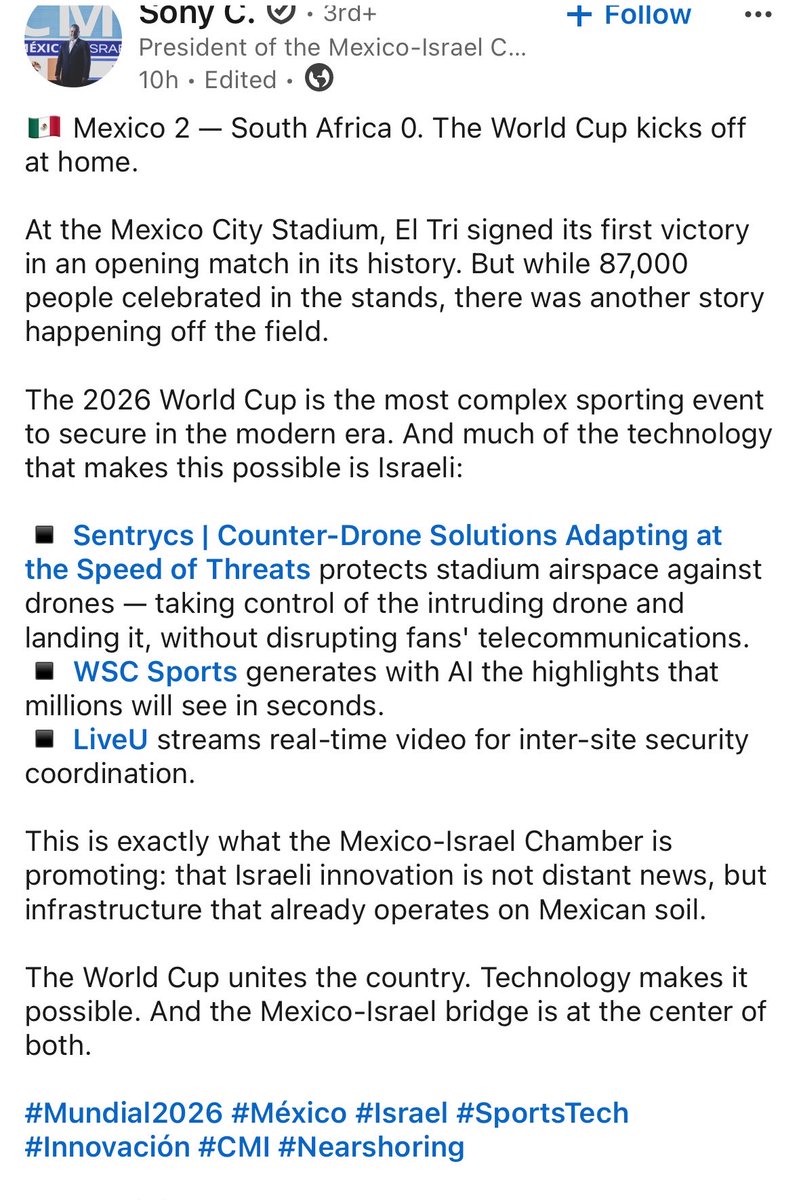
🇲🇽🤝🇮🇱 The President of the Mexico-Israel Chamber of Commerce identifying Sentrycs as a key CUAS solution protecting FWC games in Mexico‼️
🗣️ “This is exactly what the Mexico-Israel Chamber is promoting: that Israeli innovation is not distant news, but infrastructure that already operates on Mexican soil”
Also confirming the relationship between Sentrycs & LiveU that I highlighted a few months back.

4
6
88
5,669