
6 Nov 2024
Unlock Better Learning! Poor air quality in Nigerian schools harms millions of kids. Respiratory issues, cognitive decline & long-term health risks. Introducing Healthy Air's DNO Catalyst: 99.99% pollutant removal!
#CleanLearning
#USElection2024
#THE8
#electionday2024
2
46

🌟 Exciting News for Schools! 🌟
🍏 Introducing Hydrolyte®: The Key to Creating Healthy Learning Environments! 🍏
As we continue to prioritize the health and safety of our students and staff, we're thrilled to share Hydrolyte®, a groundbreaking solution designed to enhance cleanliness and ensure a safer learning atmosphere.
🔹 Why Hydrolyte®?
Effective Cleaning: Eliminates germs and bacteria, keeping surfaces clean and safe for everyone.
Eco-Friendly: Making it a responsible choice for our schools.
Easy to Use: Simplifies the cleaning process, ensuring thorough sanitation without the hassle.
🏫 Together, we can create a healthier, more conducive environment for learning. Embrace a cleaner future with Hydrolyte® in your school today!
🔗 Learn more at pctl.com or call us at 843-390-7900.
#Hydrolyte #HealthySchools #CleanLearning #StudentSafety #EcoFriendly
2
6
539
Exciting News for Healthier Schools!
Hydrolyte® — the revolution in creating safe and healthy learning environments! 🏫✨
As we continue striving for excellence in education, ensuring our classrooms are clean and germ-free has never been more important. Hydrolyte® is here to make that task easier and more effective than ever.
Why choose Hydrolyte® for your school?
🛡️ Powerful disinfection that combats germs and viruses
🌱 Non-toxic and gentle for children
🌍 Eco-friendly, supporting our commitment to sustainability
Let's empower our teachers and protect our children with Hydrolyte®. Because when our schools are healthier, our future is brighter! 🌟
🔗 Learn more about how Hydrolyte® can transform your school at pctl.com or call us at 843-390-7900!
#HealthySchools #Hydrolyte #CleanLearning #SafeEnvironment

2
6
260
🌟✨ Teaching Hygiene Excellence: Discover Why Schools Embrace Hypochlorous Acid! 🌟✨
🔬 As schools prioritize cleanliness and safety, the choice of disinfectants matters more than ever. 📚✏️ Hypochlorous acid, Hydrolyte®, has emerged as a top contender for maintaining pristine learning environments! 🏫💡
✅ Effective: When used as directed Hydrolyte® kills germs, bacteria, and viruses without harsh chemicals, ensuring a safe space for students and staff alike.
✅ No VOCs or Quats to trigger respiratory problems
✅ Eco-friendly: Biodegradable and environmentally sustainable, aligning with schools' commitment to a greener future.
Join the hygiene revolution! 🌱💧 #HygieneExcellence #HypochlorousAcid #SchoolSafety #CleanLearning

3
218

13 Dec 2023
Train robust classification models on noisy tabular data!
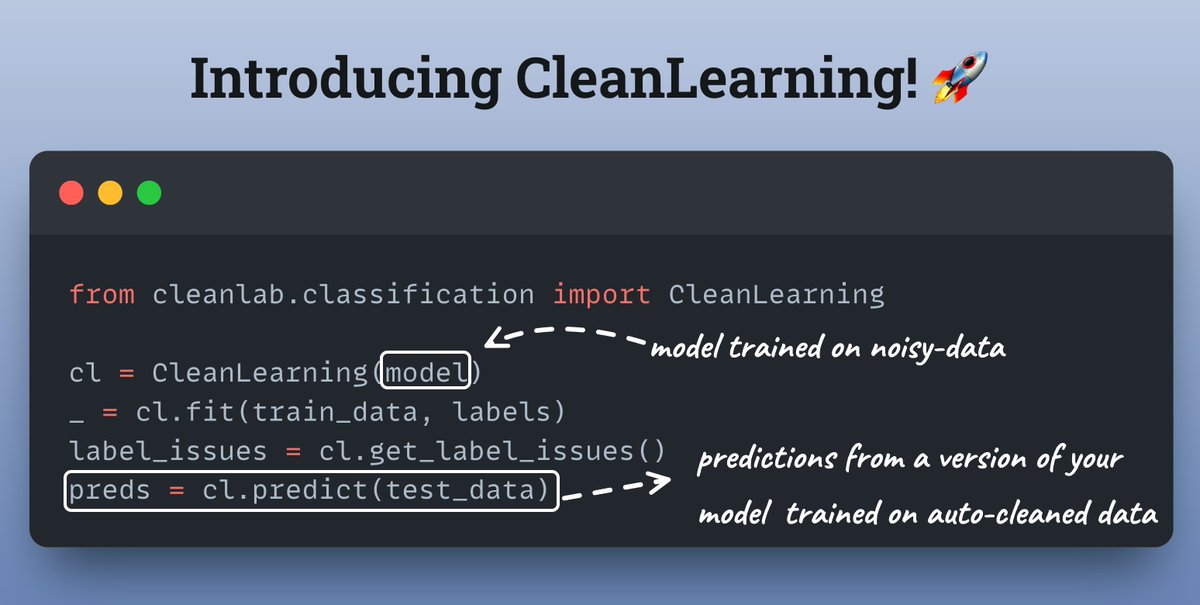
Introducing CleanLearning! 🚀
Now you can automatically identify all mislabeled samples in your data & train robust models.
The best part, all it needs is a few line of code!
Let's say you Already have an sklearn compatible model, tabular data and given labels.
Here's all you need to do👇
You must be wondering how it works! 💭
CleanLearning by @CleanlabAI is developed by folks at MIT, and it's powered by a novel algorithm called Confident Learning!
Below, I have provided a simplified explanation of the same!
Check this out👇
Cleanlab also has a no-code studio that let's you clean any data & train robust models in just a few clicks!
I have shared all the relevant links in the next tweet!
That's a wrap, thanks for reading!
Find me → @akshay_pachaar ✔️
For more content like this!
Cheers! 🥂

8
49
241
34,036

10 Feb 2023
Full video on SmartCherrysThoughts.com
#cleanlanguage #cleanlearning #communicatewithvisuals #MikeHaber #PeopleTech #saicharanpaloju #smartcherrysthoughts #systemsthinking #VisualConsultant #visualisation @michaelthaber
2
592
10 Feb 2023
Chatting with Mike Haber, Visual Consultant, Linux Tech to People Tech smartcherrysthoughts.com/sma…
#cleanlanguage #cleanlearning #communicatewithvisuals #MikeHaber #PeopleTech #saicharanpaloju #smartcherrysthoughts #systemsthinking #VisualConsultant #visualisation @michaelthaber
1
455

10 Feb 2023
This weeks episode of "All the Remote Things" sees me having an amazing chat with @caitlinwalkerTA (Caitlin Walker (PhD)) director of CleanLearning to discuss Clean Language and how it changes the way teams work.
youtube.com/watch?v=kZ5IpNCJ…
1
3
169

4 May 2022
💪 Instantly make any model more robust by adapting it with cleanlab’s CleanLearning wrapper.
⛳ Start using cleanlab open-source for free: github.com/cleanlab/cleanlab
#machinelearning #datascience #artificialintelligence #deeplearning #data #datacentricai

1
3

22 Jun 2021
Excellent read, the training of new hires and refresher training is so essential in our industry. Industry training via @CleanLearning is a great place to start. 👍🏻
19 Jun 2021

The pandemic has yielded numerous key lessons for the cleaning industry, not least the importance of effective cleaning and training.
reminetwork.com/articles/5-e…
2
28 May 2021
Did you know that Bee-Clean has a National Pandemic Management Team? We meet biweekly to discuss changes in #pandemic management & stay current on pandemic #cleaning protocols. Today we had the pleasure of hearing from @cleanlearning. #thankyou for the informative presentation!
1
3

8 Apr 2020
Coming up on @The_MorningNews
6:09 Keith Sopha, @CleanLearning
6:40 Janet Brown, @planetjanetyyc
7:09 Craig Jenne - #covid19 questions
7:49 @LeelaAheer
8:09 Dr Axel Moehrenschlager, @calgaryzoo
8:49 Nirmala Naidoo, @GreenCalgary
9:09 Laurie Schacht, toy expert
1
1

9 Jun 2019
Hopefully I’ll be able to give you at least a taste of what it’s all about at some point Hayley. I’m super excited about sharpening my tools and adding more to my pannier. And to focused, purposeful time with great people.
3

9 Jun 2019
Really looking forward to 3 whole days on the Wirral immersed in Systemic Modelling with the wonderful @caitlinwalkerTA & @marian_way @CleanLearning 😊🌏 new pad & pens ready!

2
2
9 Jun 2019
Really looking forward to being immersed for 3 whole days of Systemic Modelling with @caitlinwalkerTA & @marian_way @CleanLearning 😊🌏 new pad and pens ready. 😊

1
4

20 Mar 2019
Creating more #DramaFree conversations around the world - tweeting from Moscow, emailing Malaysia and planning our trip to Japan #CleanLearning

1
7



