
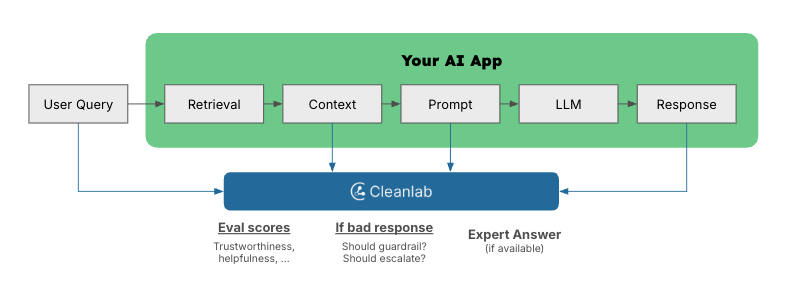
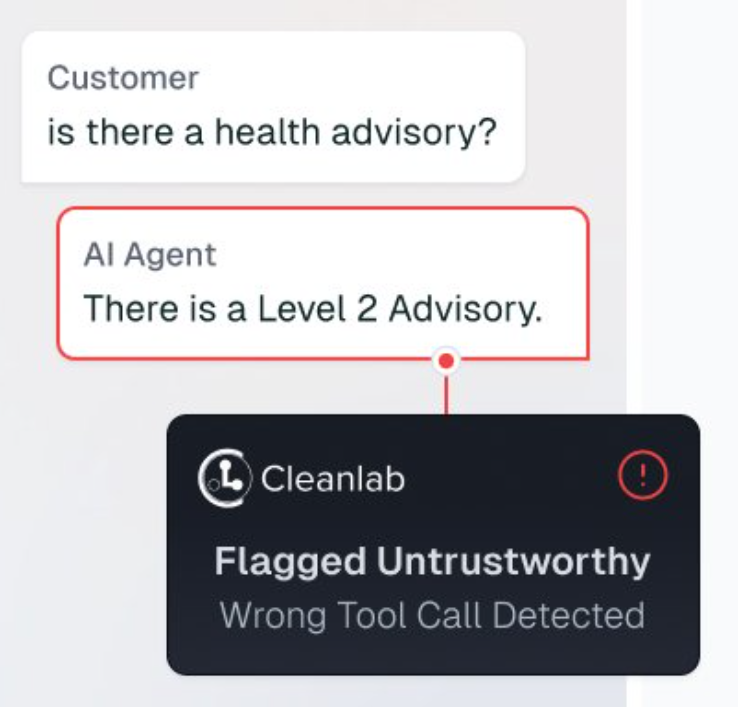
Cleanlab makes AI agents reliable. Detect issues, fix root causes, and apply guardrails for safe, accurate performance.
Joined October 2021
- Tweets 701
- Following 233
- Followers 2,445
- Likes 651
206 Photos and videos







Pinned Tweet

18 Nov 2025
🚀 New from Cleanlab: Expert Guidance
AI agents running multi-step workflows can fail in tiny, trust-breaking ways.
Expert Guidance lets teams fix these behaviors with simple human feedback, instantly.
✈️In one airline workflow: 76% → 90% after only 13 guidance entries.
1
3
15
8,931
Jan 28
We're thrilled to join forces with @joinHandshake, where we'll be able to scale our team's pioneering work to inflect change with the world's leading AI labs. Hear more from our CEO and Co-founder, @cgnorthcutt, to learn about our next chapter.
Jan 28

News: @joinHandshake acquires @CleanlabAI!
This "ten-year old job marketplace" has quietly become a top human data lab for AI--building an AI research org, acquiring top AI talent, and advancing Cleanlab tech and research to lead data foundations for frontier AI.
1 of 4
1
2
1,087
Cleanlab retweeted

16 Dec 2025
Achieving 20% improvement in structured extraction tasks using @DSPyOSS and GEPA
Building on a blog post from @CleanlabAI I wanted to see how quickly I could optimize a structured extraction task with DSPy GEPA
In about 3 hours (mostly me getting in the way of claude code):
- 22 percentage points over vanilla structured outputs
- Ran 4 experiments in total
- ~$3 total cost
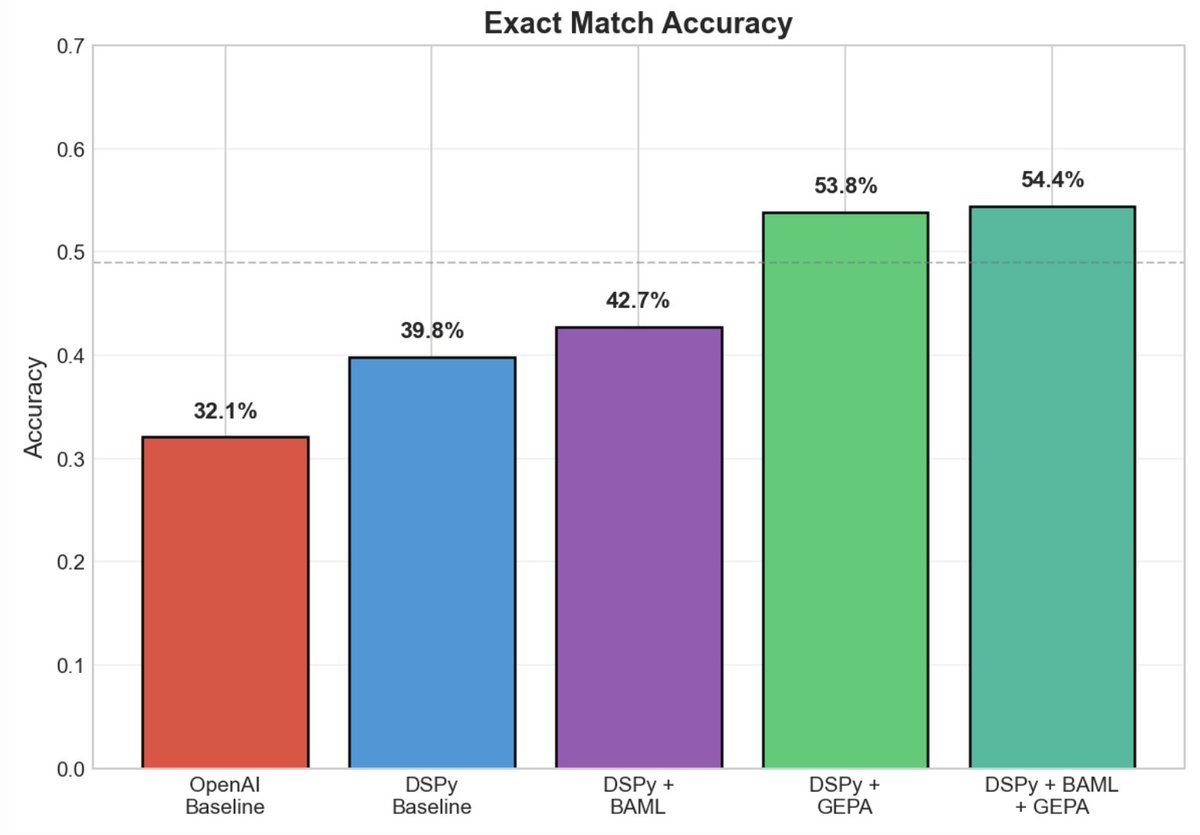
I tested 5 approaches incrementally:
• OpenAI Baseline: 32.1% exact match
• DSPy Baseline: 39.8%
• DSPy BAML: 42.7%
• DSPy GEPA: 53.8%
• DSPy BAML GEPA: 54.4%
2
16
92
17,652
Cleanlab retweeted

7 Dec 2025
For anyone who cares about structured output benchmarks as much as I do, here's an early Christmas present 🎁 ! Pretty well thought out from the folks @CleanlabAI.
Seems like I'll def be using it to compare LLMs using BAML and DSPy!
github.com/cleanlab/structur…
4
11
60
3,652
Cleanlab retweeted

11 Dec 2025
Where Did $37B in Enterprise AI Spending Go?
$19B → Applications (51%)
$18B → Infrastructure (49%)
Our report includes a snapshot of the Enterprise AI ecosystem, mapped across departmental, vertical AI, and infrastructure.
Although coding captures more than half of departmental AI spend at $4 billion, the technology is gaining traction across many enterprise departments: IT operations tools ($700M), marketing platforms ($660M), customer success tools ($630 M).
AI-native startups are rapidly emerging across every job function, capturing a meaningful share of the $7.3B spent on departmental AI in 2025. mnlo.vc/enterprise-ai-25

2
2
14
1,729
Cleanlab retweeted

5 Dec 2025
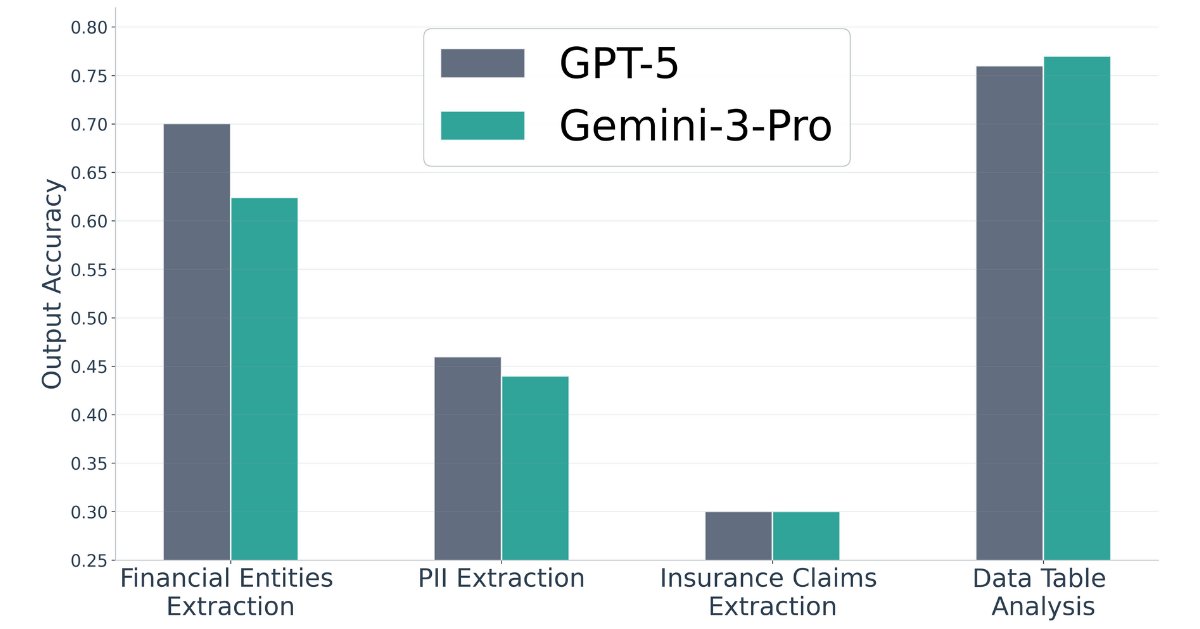
Which LLM is better for Structured Outputs / Data Extraction: Gemini-3-Pro or GPT-5?
We ran popular benchmarks, but found their "ground truth" is full of errors.
To enable reliable benchmarking, we've open-sourced 4 new Structured Outputs benchmarks with *verified* ground-truth
3
9
34
23,702
3 Dec 2025
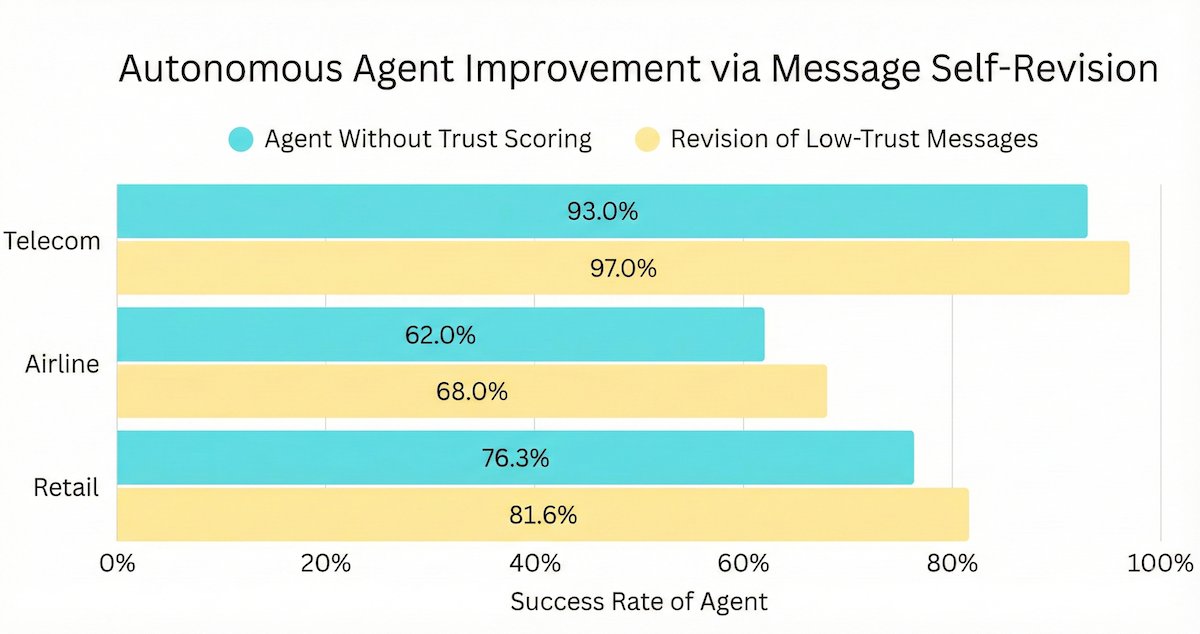
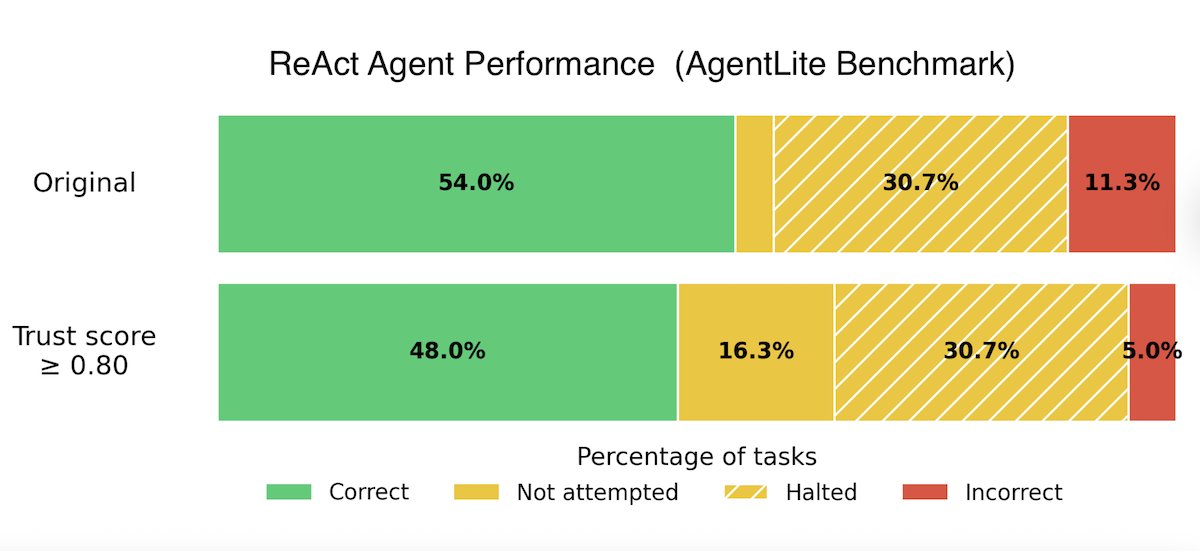
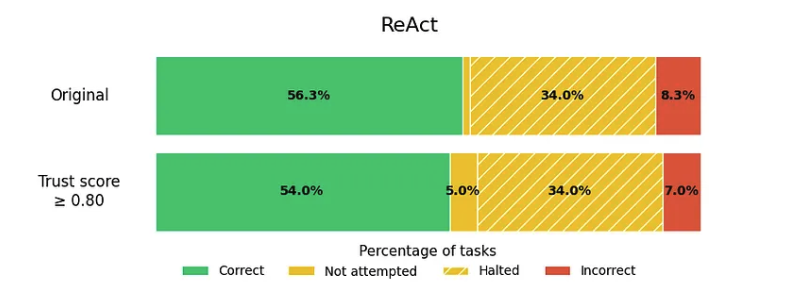
We discovered how to cut the failure rate of any AI agent on Tau²-Bench, the #1 benchmark for customer service AI.
Agents often fail in multi-turn, tool-use tasks due to a single bad LLM output (reasoning slip, hallucinated fact, misunderstanding, wrong tool call, etc). We introduce an automated LLM trust scoring message revision pipeline that mitigates this brittleness and keeps agents on the rails.
Benchmarks show that our approach remains effective across all Tau²-Bench domains (Telecom, Retail, Airline) and different LLMs -- cutting agent failure rates up to 50%.
2
1
4
212
3 Dec 2025
This pipeline can used to automatically make any agent more reliable.
Extensive benchmarks here: cleanlab.ai/blog/tau-bench/
1
124
18 Nov 2025
🚀 New from Cleanlab: Expert Guidance
AI agents running multi-step workflows can fail in tiny, trust-breaking ways.
Expert Guidance lets teams fix these behaviors with simple human feedback, instantly.
✈️In one airline workflow: 76% → 90% after only 13 guidance entries.
1
3
15
8,931
10 Nov 2025
The “Year of the Agent” just got pushed back.
Out of 1,837 enterprise leaders, most are struggling with stack churn reliability.
⚙️ 70% rebuild every 90 days
😬 Less than 35 % are happy with their infrastructure
🤖 Most “agents” still aren’t really acting yet
5
7
24
15,411
10 Nov 2025
The reality: We’re moving from hype to hardening, building the reliability layer AI needs.
🔍 Read the full Cleanlab report → cleanlab.ai/ai-agents-in-pro…
📰 @Computerworld feature → computerworld.com/article/40…
1
2,368
30 Oct 2025
🚧 Even the best AI models still hallucinate.
OpenAI’s recent paper on Why Language Models Hallucinate shows why this problem persists, especially in domain-specific settings.
For teams implementing guardrails, we put together a short walkthrough: youtu.be/i_6fjKgboFg?si=aaAE…
1
3
1,571
16 Oct 2025
AI pilots prove intelligence, but AI in production demands reliability.
The best teams separate their stack early: 🧠 Core = how AI thinks 🛡️ Reliability = how it stays safe
That’s how prototypes become products.
👉cleanlab.ai/blog/emerging-re…
2
7
22
13,119
30 Sep 2025
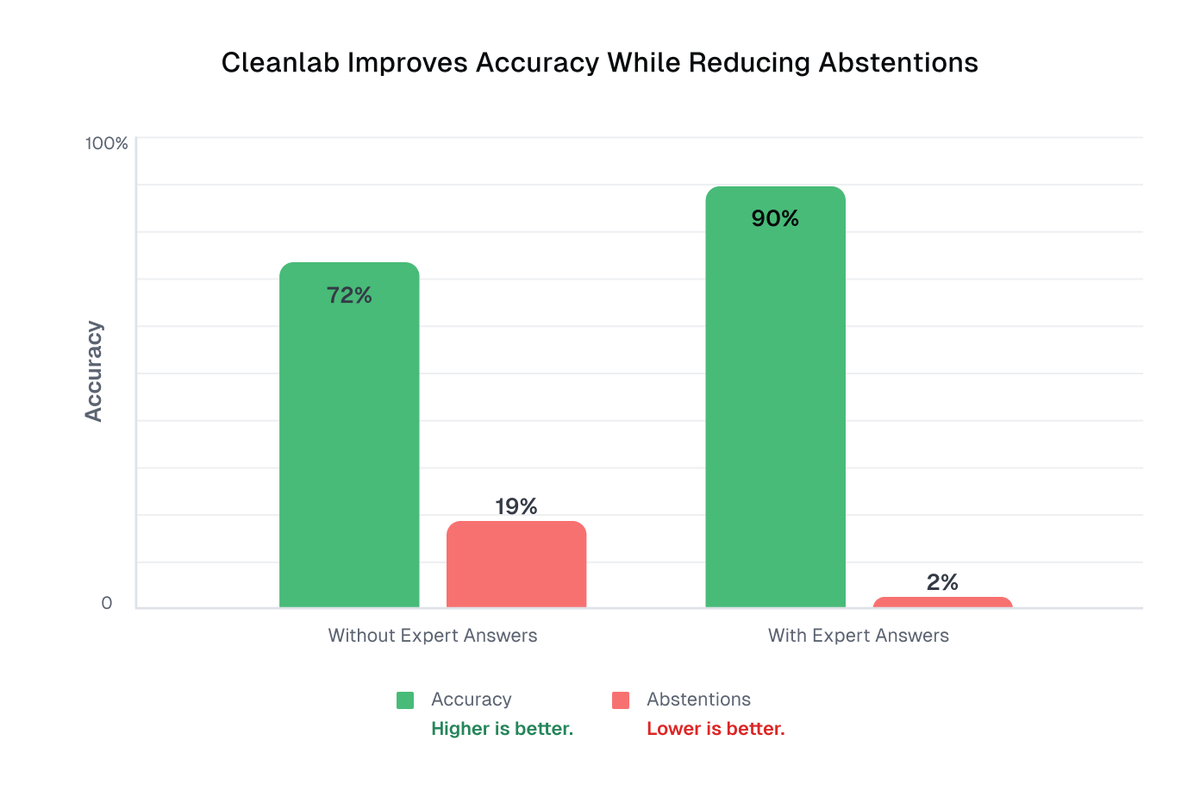
AI agents won’t replace humans. Their real power comes when humans guide it.
We just added Expert Answers to our platform:
👩🏫 SMEs fix AI mistakes right away
🔁 Fixes are reused across future queries
📈 Accuracy improves, “IDK” drops 10x
Full blog: cleanlab.ai/blog/expert-answ…
192
23 Sep 2025
Launching an AI agent without human oversight is basically launching a rocket without mission control 🚀
Cool for a few minutes… until something breaks.
🕹️ It’s not the rocket that makes the mission succeed. It’s the control center.
cleanlab.ai/blog/managing-ai…
9
23
79
19,911
17 Sep 2025
📍 Live at @AIconference 2025 in San Francisco!
Tomorrow, @cgnorthcutt is sharing practical strategies for building trustworthy customer-facing AI systems, and our team is around all day to connect.
👋 Stop by and geek out with us!
3
198
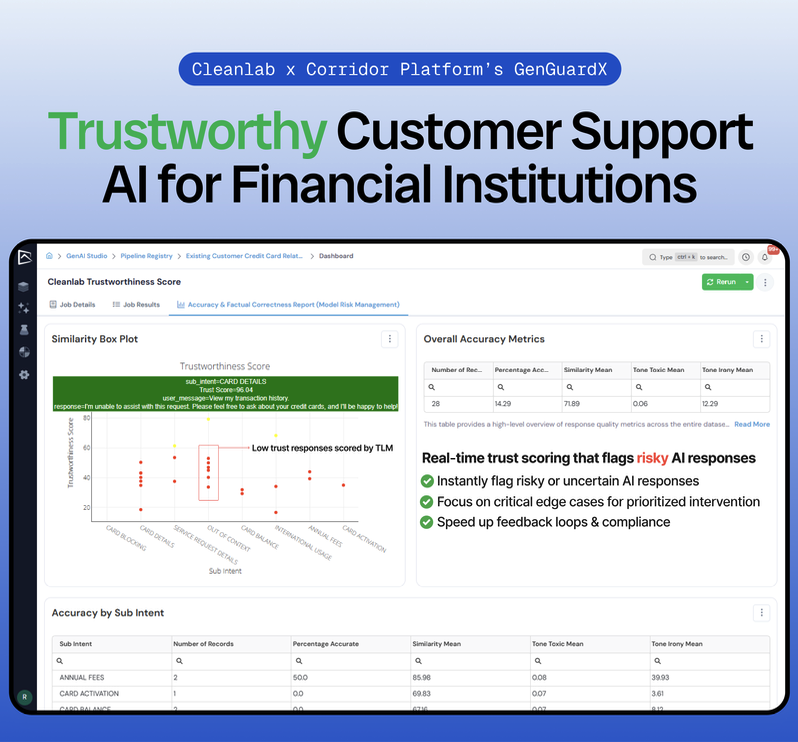
16 Sep 2025
Most AI pilots in financial services never make it to production.
The reason is simple: they can’t be trusted.
Today, Cleanlab @CorridorAI are fixing that by combining governance with real-time remediation so AI is finally safe to deploy at scale.
🔗 businesswire.com/news/home/2…
4
417
11 Sep 2025
AI safety is not a feature. It is infrastructure.
AI agents are probabilistic, which means unpredictability is guaranteed.
The 4 risk surfaces every team building AI agents must address:
- Responses
- Retrievals
- Actions
- Queries
👉 cleanlab.ai/blog/ai-agent-sa…
ALT AI Agent Risk Surfaces
7
3
202
9 Sep 2025
🚨 Next week at @AIconference in San Francisco:
@cgnorthcutt will share practical strategies with guarantees for building customer-facing AI support agents you can actually trust.
🗓️ Sep 18 | 12:00–12:25 PM
👉 Don’t miss it. aiconference.com/
1
244