
27 Nov 2025
Gotten the Gensyn Node roles and a good uptime it’s time to make valuable content on what @gensynai is.
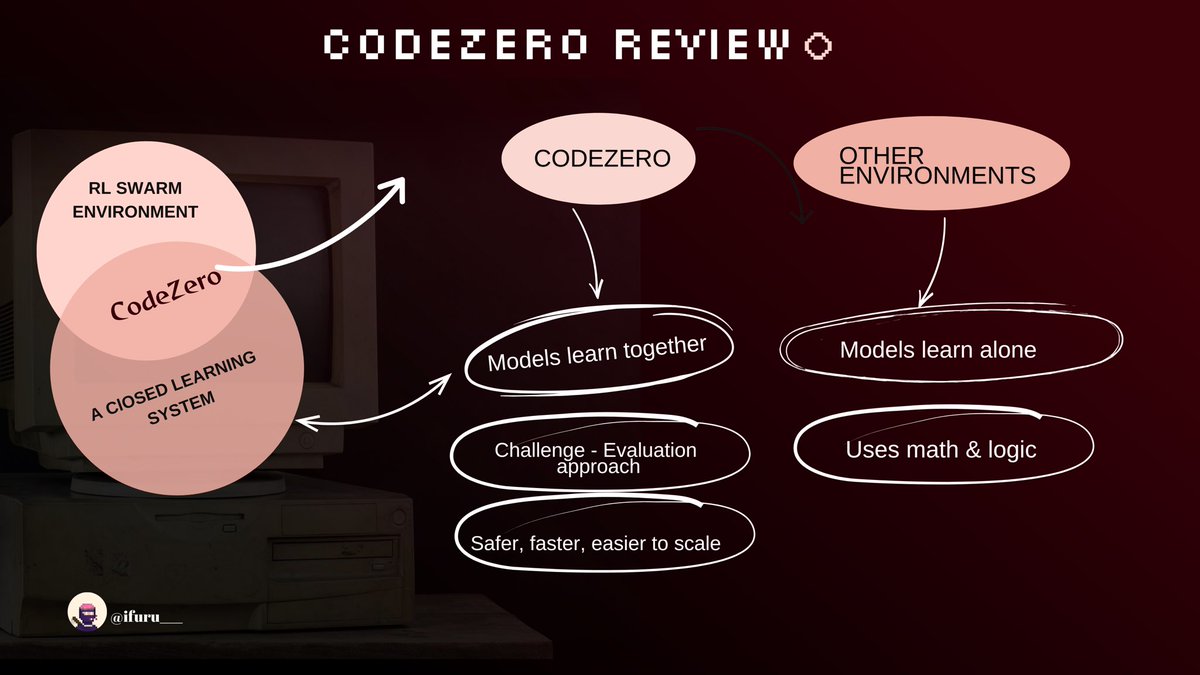
Code Zero.
Most AI models today learn the same boring way:
one model sitting alone doing tasks someone gives it hoping it gets better.
But Gensyn looked at that and said:
“Why is one model learning alone when the whole squad can learn together?”
And boom CodeZero was born.
Think of CodeZero like a group chat where every AI model is actually learning from each other.
One model creates a coding challenge.
Another tries to solve it.
A third one checks the answer.
Nobody leaves the group chat.
Nobody goes outside.
Everything happens inside one tight loop.
A whole learning community.
Before now, training AIs felt like giving math homework to one child at a time.
But with CodeZero?
It’s like putting the whole class together,
letting the smart ones set the questions,
others solve them,
and a neutral teacher mark everything.
Simple. Natural. Fast.
And the crazy part?
The “teacher” never runs the code — it only judges if the code looks correctBefore now, training AIs felt like giving math homework to one child at a time.
But with CodeZero?
It’s like putting the whole class together,
letting the smart ones set the questions,
others solve them,
and a neutral teacher mark everything.
Simple. Natural. Fast.
And the crazy part?
The “teacher” never runs the code it only judges if the code looks correct.
That’s how they keep things safe.
That’s how they keep things safe.
The 3 Roles in the CodeZero Squad
1. Proposers “The Question Setter”
They choose the challenges and adjust the difficulty.
2. Solvers “The Try-Your-Best Students”
They attempt the challenges, learn, and share their attempts so others learn too.
3. Evaluators “The Strict Teacher”
Frozen models that don’t learn
They just grade.
The Loop (relatable version)
Here’s the flow:
• Someone sets a question
• Someone tries to solve it
• Someone checks the solution
• The question becomes harder or easier
• Everyone learns from each attempt
• The cycle repeats
It’s basically group work that actually works.
What makes CodeZero smart
• Uses real datasets (MBPP CodeContest)
• Uses Qwen models for different jobs
• Tracks how consistent & correct the models are
• Difficulty adjusts like a game leveling up
• Runs safely inside the Gensyn RL swarm no extra setup

9
2
9
179

27 Nov 2025
𝐑𝐞𝐯𝐢𝐞𝐰𝐢𝐧𝐠 𝐂𝐨𝐝𝐞𝐙𝐞𝐫𝐨: The Self-Teaching Coding Swarm
@gensynai
In our previous post, we saw how RL swarm environment was built to train AI models to be up to standard
now, gensyn has taken it to turbo mode⚡️
with “CodeZero’’
》𝐖𝐓𝐇 𝐢𝐬 𝐂𝐨𝐝𝐞𝐙𝐞𝐫𝐨
CodeZero is a new enviroment structured for all AI models that is learning to come together to learn , collaborate & grow in a closed system
they do this by learning in a closed loop system without external interference
they (models) generate problems >> solve them >> evaluate solutions (all in same p2p network)
instead of one model learning alone like it does in the general RL swarm environment, you have a swarm - a large group of models helping each other to get better
but why CodeZero ?
》𝐖𝐡𝐲 𝐂𝐨𝐝𝐞𝐙𝐞𝐫𝐨 𝐢𝐬 𝐬𝐩𝐞𝐜𝐢𝐚𝐥
so previous environments train models through the use of math and logic
but CodeZero uses a new task approach assigned challenges which are evaluated in a model based reward structure
model participate as proposers, solvers and evaluators each playing a significant role in this learning loop
》𝐓𝐡𝐞 𝟑 𝐑𝐨𝐥𝐞𝐬 𝐢𝐧 𝐂𝐨𝐝𝐞𝐙𝐞𝐫𝐨
Proposers >> Solvers >> Evaluators
▪︎ Proposers
they create coding questions and unit tests and when necessary adjust difficulty: easy, medium, hard, etc.,
▪︎ Solvers
They try to solve the coding problems and learn through reinforcement learning (RL)
they also share their attempts with other solvers.
▪︎ Evaluators
these are “frozen” models ,they don’t learn or change instead they grade the solutions and give rewards,
they NEVER execute the code : they judge by structure and predicted correctness
》𝐓𝐡𝐞 𝐭𝐫𝐚𝐢𝐧𝐢𝐧𝐠 𝐥𝐨𝐨𝐩
In a simplified manner, here’s how the CodeZero training cycle operates
1/ proposers create tasks
they generate coding problems tests
2/ solvers pick tasks, either from proposers or from real datasets like MBPP and CodeContests
3/ solvers generate rollouts
A rollout = the solver’s attempts.
4/ solvers share rollouts
everyone learns from everyone.
5/ evaluators score the attempts; using structure, formatting, and predicted correctness.
6/ rewards are assigned
a composite score is created.
7/ proposers adjust difficulty
If solvers succeed too much → harder tasks.
If solvers fail too much → easier tasks.
8/ solvers update themselves
Using GRPO (Group Relative Policy Optimization)
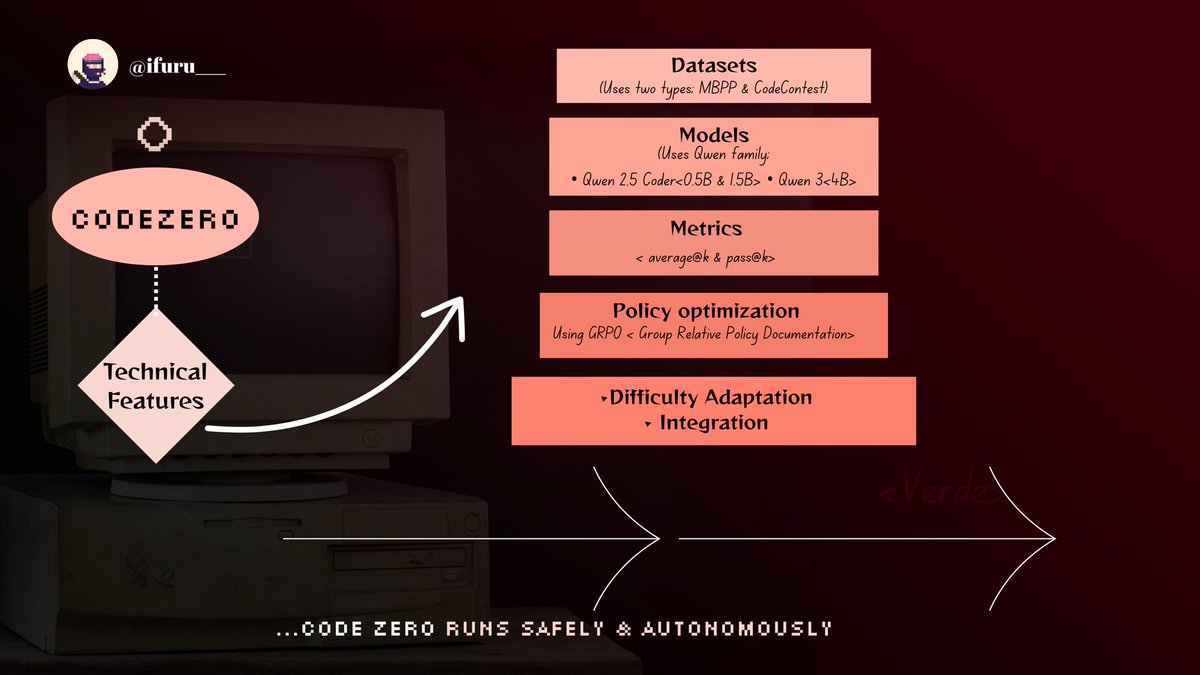
》𝐂𝐨𝐝𝐞𝐙𝐞𝐫𝐨 𝐭𝐞𝐜𝐡𝐧𝐢𝐜𝐚𝐥𝐢𝐭𝐢𝐞𝐬
when it comes to the technicalities that enables CodeZero to learn safely and autonomously
it’s datasets, model architectures, metrics and optimization strategies play that role
▪︎ It’s dataset - codezero makes use of 2 data sets (MBPP & CodeContest)
datasets help in fallback stability and baseline challenges
▪︎ Models - codezero employs Qwen family across different roles
Qwen 2.5 Coder <0.5B & 1.5B> - used for solvers , rollout generation etc
Qwen 3<4B> - for proposers and evaluators, provides stronger generation and assessment abilities
▪︎ Metrics - CodeZero tracks metrics using;
average@k (measures model consistency)
pass@k (measures if at least one of k attempts is correct)
▪︎ Safety
codes aren’t executed here !!
evaluators only look at code structure, formatting, predicted correctness
this avoids running unsafe code.
▪︎ Difficulty Adaptation : Its difficulty has 5 levels, it adjusts based on how they are performing
▪︎ Policy Optimization
solvers improve using GRPO,
▪︎ Integration
as for integration, it runs on existing Gensyn RL Swarm; same network, identity files & setup
so nothing special needed to run CodeZero
》 𝐅𝐢𝐧𝐚𝐥 𝐭𝐡𝐨𝐮𝐠𝐡𝐭𝐬
I think the idea of CodeZero is profound as it promotes self sufficient networks where models can learn together, what is interesting is how it integrates with RL swarm environment and doesn’t need a special environment and setup to run on
I believe this is the way forward for model learning
Gswarm!!

24 Nov 2025

We’re Using AI We Can’t Audit and that’s a Problem
》𝖨𝗇𝗍𝗋𝗈𝖽𝗎𝖼𝗍𝗂𝗈𝗇 (problem)
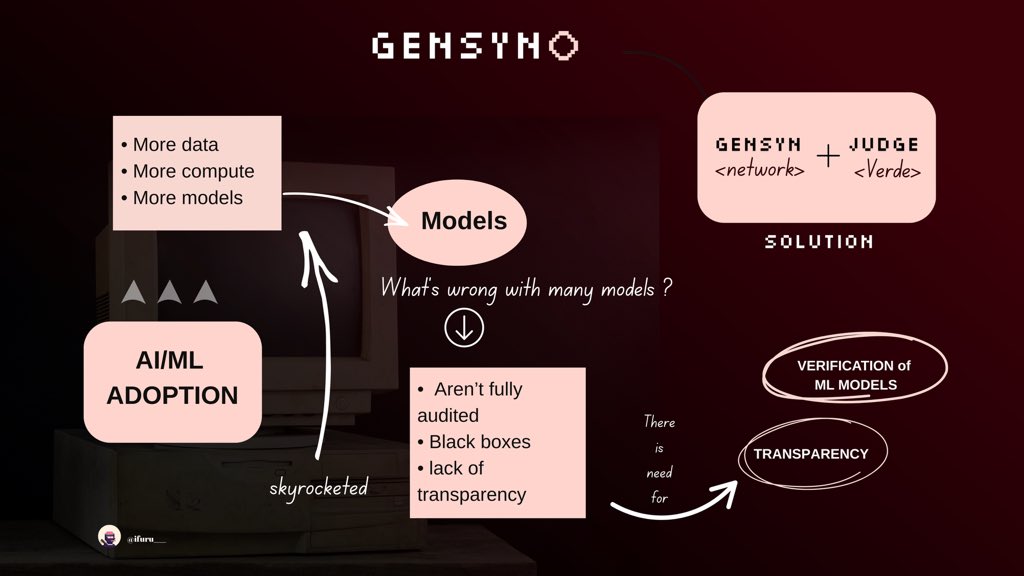
It’s no news to us that AI/ML adoption is skyrocketing
the demand has gone through the roof: more data, more compute, more models are needed
more and more decisions are being made by machine learning (ML) models: credit risk, hiring, medical diagnosis, content moderation, policy tools
but many of these models are black boxes: we often don’t know what data they were trained on, how they make certain decisions, or whether they behave correctly when used in a new situation
a report by arVix stated that and I quote “studies show that ML models trained in one domain may behave very differently when deployed in another (the “underspecification” problem)
this begs the question of where we are heading and what can be done
》What needs to change
we need verification and validation of ML models, not just how they perform on training/test data, but how they behave in deployment, across scenarios
we need transparency: data lineage (where the data came from), model provenance (who made it, trained it, what assumptions)
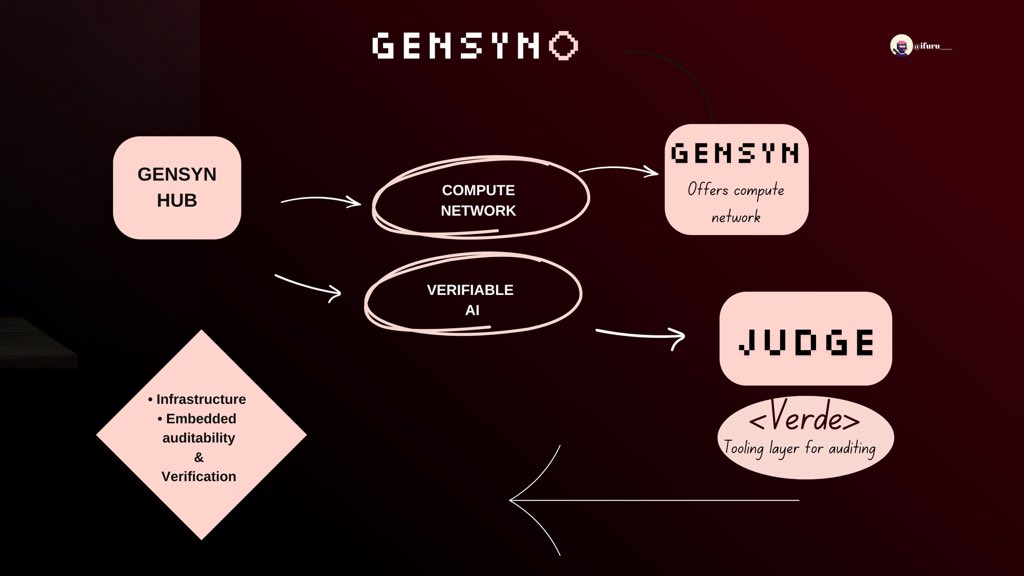
》Gensyn’s role
gensyn offers a compute network: not just centralised cloud providers, but a protocol that allows many machines to participate in training and inference tasks
what interests me is how it is built for verifiable AI
meaning you can trust that the computation was done correctly, that the model’s training path is auditable, that participants followed protocol.
components like Judge (a verification/validation layer) perform checks on tasks submitted, ensure hosts did what they claimed, validate results or subsets of them.
Judge is built under Verde (which is lets say a tooling layer for “verifiable execution model auditing”) help ensure the model you end up with has clear provenance, performance records, and behaves as expected in deployment
Gswarm
36
1
51
1,208

17 Jul 2025
The results are out for #SlashBuild2025 🚀
Congrats to our top 3:
🥇 Aniket Gupta
🥈 Nikita Karmakar
🥉 @subhojitnath221
…and 13 more stars who made it to the list!
Full results in the image 📷
#CodeContest #NooBuild

3
58

20 Mar 2025
KSRCT presents Top Coders - Code Contest 2024-25!
In collaboration with eBox and the Training & Placement Cell, we bring you an exciting Problem-Solving Challenge in C Language! On March 22, 2025, 10:00 AM @ Cyberdome, IT Park
#ksrct1994 #eBox #TrainingAndPlacement #CodeContest

13
45
119

11 Dec 2024
Wow, over 10 participants joined in 🎉
If you’re proud of your work and want to share your code, the submission link is waiting for you in the comments
Let’s see what you’ve got 📷
#Contest #codecontest #webdev
1
5
143

18 Jun 2024
[Vie du centre 😁] Aujourd'hui a eu lieu le concours interne #codecontest au centre @Inria_lyon
👩💻 Par groupe, nos chercheurs, doctorants, stagiaires et fonctions supports ont réalisé du codage autour d'un ascenseur
🎉 Bravo à eux pour leur curiosité et leur implication !




1
4
262

25 Feb 2024
🚀 Calling all designers, developers & hackers! 🎨💻
Join the #Handshake Website Building Contest! Show off your skills & spread good vibes!
🏆 Win up to 3,000 HNS!
📅 Deadline: March 10th
🔒 Bonus: Ensure HTTPS & DANE!
Details:
2024.handycon.xyz/website-bu…
Good luck!
#WebDev #WebDesign #CodeContest #CodingChallenge #HandyCon2024 #hnssite
5
15
47
4,251

19 Feb 2024
We've added a feature to AlphaCodium that lets you enter your own problem.
Input (at the moment...) should be according to CodeContest format.

1
5
358

6 Jan 2024
🚀 Exciting #new! Participated in #WeekendContest107 on #Coding Ninja and secured the 74th rank out of 19,884 participants! 🏆 Grateful for the challenge and eager for more. Let's #connect and share coding stories! 🌟 #CodingNinja #CodeContest #Top100 #reactjs
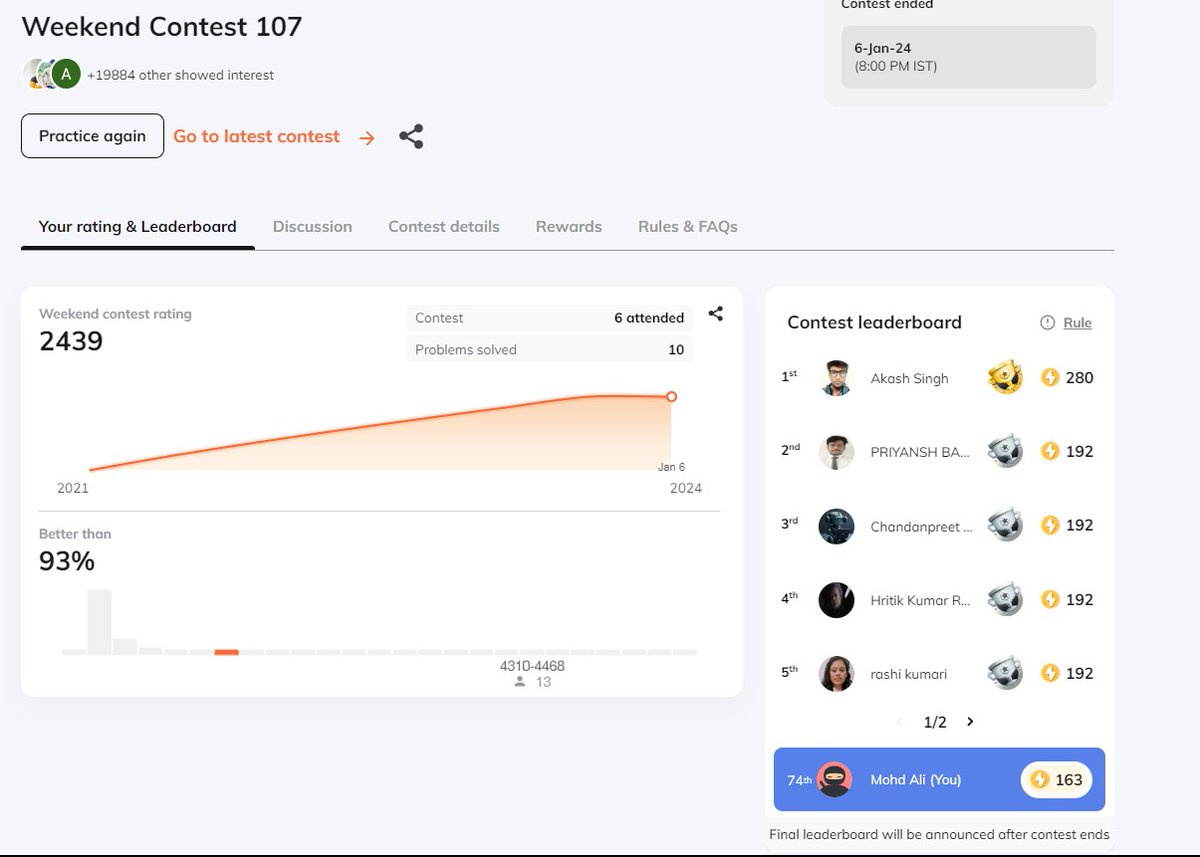
ALT https://www.codingninjas.com/studio/contests/weekend-contest-107
1
5
201


ALT Stand de BPCE SI
1
1
8
405

16 Feb 2023
The Association of Computer Engineers in association with BCA Students conducted the “Coding and Debugging Contest” on for the students of II Year and III Year BCA.
#code #debugging #codinganddebugging #contest #codecontest #eatthebug #eatthebugs #coding #college #codingchallenge


2
79

#viedecentre | Code Game
Ce matin, 50 participants se sont prêtés au jeu du #codecontest 👉Le challenge : proposer le code de l'ascenseur d'un immeuble de 5 étages 🛗
Au programme : logique, échanges, code et...pizzas 🍕
Merci à tou(te)s & félicitations aux équipes gagnantes🏅




1
11
724

10 Oct 2022
Déjà inscrits ? 😃
Et si tu t’entraînais ? 🤓
C’est par ici 👉🏻isograd-testingservices.com/…
#Concoursdecode #EuroInformation #GreenIT #CodeContest #Octobre #Informatique #Code #Développeurs #Challenge

1
3

13 Jun 2022
An event in which a large number of people meet to engage in collaborative computer programming (solve a problem in agriculture, pisciculture) with the use of IoT(internet of things)
#free
#codecontest
#sigerisSarl
#hackathon
3 Jun 2022


1
7

Let us explain... No, it's too much. Let us summarize! ✨
TWO DAYS #JavaScriptCodeathon ⏰
Remember! you could be one of the TOP 3 😏👇
#rviewer #tech #javascript #techcontest #coding #codecontest #it #cto #developer
go.rviewer.io/javascript-cod…
2
4
Three days! #RviewerCodeathon...
Last call! 👉 bit.ly/3pcWzJn
#GetWithTechJobs #techcontest #coding #codecontest #it #cto #developer
1

Nuestra cara al ver que solo quedan 4 días para que acabe el #RviewerCodeathon...
Tranqui, aún estás a tiempo de participar, obtener tu recompensa y entrar en el top10! CORRE! 🔥
👉 bit.ly/3GVN47l
#GetWithTechJobs #techcontest #coding #codecontest #it #cto #developer
2
4

25 May 2021
1. RUBY
2. PYTHON
3. JANUS
4. DRAGON
@Indian_Contests
@turingcom
#CoderLife #CodeFun #CodeContest #ContestTime #ContestAlert
#Contest #ContestAlertIndia
Tags
@PareshR7684 @AmarjeetMarwaha @manojku30735347 @AhujaSakshi13 @PiyushShitansh @promisingace @MaisuriaChetan
3

25 May 2021
1) RUBY
2) PYTHON
3) JANUS
4) DRAGON
@vaishalimaisur2
@vandanasehgal3
@AparnaA22141836
@Purvaa5
@Indian_Contests
#CoderLife #CodeFun #CodeContest #ContestTime #ContestAlert #AnswerAndWin #TagAndWin
#Contest #ContestAlertIndia
2

25 May 2021
1. RUBY
2. PYTHON
3. JANUS
4. DRAGON
#CoderLife #CodeFun #CodeContest
@AbhishekIPLFeak
@cool_bindra
@proudy_indian1
@Deepak62032235
@Pulkit_Agrawal0
@Sreejit40765940
@Shivamthepower1
@shimmer_sneh
@GopiDevi11
@GILESSINGH
@singhm_20
@yogitabaid
4