
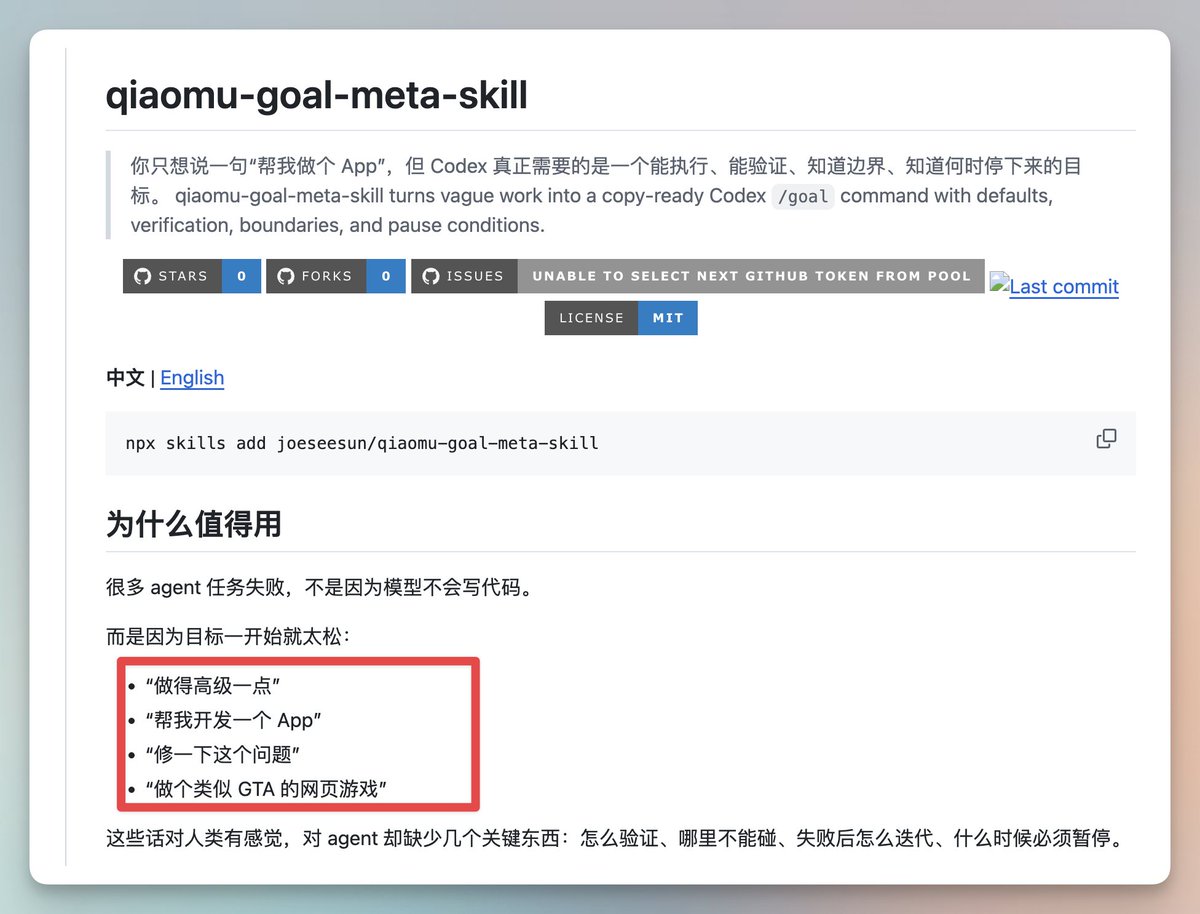
Arbor: Agentic Research That Actually Remembers What It Is Doing
Arbor is an open-source agentic research framework that builds a living hypothesis tree instead of running isolated one-off experiments.
It outperforms Claude Code and Codex across optimizer design, architecture design, coding, and math reasoning. Worth watching if you do any kind of structured research or experimentation with AI agents.
#AINews #ArtificialIntelligence
1
1

Chaos genestealer cultists did show up in more recent lore. The GSC first codex features a cult falling to Nurgle in the timeline section.
Necromunda supplement for GSC has a mention of a Chaos genestealer cult.
Chaos Oks appear in the novel "Angron's Monolith" and FFG's Tome of Blood (third party) has Khornate Orks.

Umair Shaikh retweeted

What is your go to ai for coding?
- Codex
- Claude
10
1
9
191
Thomas will shenan again retweeted

Jun 13
【New Potion Codex】Officially Released - Darkness Pathway
Dive into the chaotic endless night, grant peaceful slumber to all living beings.
The Sleepless potion is now unlocked. Let us chant together: Praise the Goddess!
#LordOfMysteries #DunnSmith #LeonardMitchell #LOM #诡秘之主 #PraisetheFool




5
38
316
5,516

I am using Codex for last 3 months, the code that it generates is high quality and run without any issues
1
❤️Maria 🔞❤️ retweeted

Read the codex, got 2 new books of the Horus Heresy series today. Mo would either be in the order Bloody Rose or Valorous Heart

2
3
85

ほえー!
OpenAI、Codexのレート制限リセット権を貯めて後から使える新機能Banked Reset提供開始 友達紹介でリセットプレゼントも(テクノエッジ) - Yahoo!ニュース share.google/Wy16RNqlHA17OoH…
8

RT @nukonuko: IPA もサイゼリヤも単純にやりたくもない仕事が増えるだけだと思うのよw
どうせ Codex App や Claude Code やそこらのコーディングエージェントからできるんだしw
幸せの総量を減らしているw
2

I severely underestimated GPT-5.5. Here’s what changed.
Yesterday was a letdown. I ran one-shots, coding challenges, and benchmarks and walked away unimpressed. Wrote it off.
Today I ran everything again, this time through the direct API instead of Codex. The difference was night and day.
What flipped:
•One-shot prompts went from mediocre to genuinely impressive
•Coding tasks (pi and holefill) came back clean and sharp
•Benchmark scores jumped significantly GPT-5.5 now leads in my testing
And I think I know why the gap existed.
Codex and the direct API aren’t the same thing. The context window differs, the model routing differs, and depending on how you authenticate, you may not even be hitting GPT-5.5 inside Codex at all. My “disappointing” day-one results were probably a configuration problem, not a model problem. My mistake.
When you actually get the real model? It’s a different story. It tore through my benchmark including problems I designed to be extremely hard. I need to build harder tests.
Fixes I shipped along the way:
Two bugs were quietly distorting results for certain providers:
•Added automatic retry on dropped connections
•Removed the hard timeout cap
Turns out DeepSeek and Kimi K2.6 both wanted to think for over an hour on some prompts. Once I let them, their scores improved substantially. In my testing, Kimi now comes close to Sonnet 4.6 in quality just considerably slower.
What this means for my previous post:
Some of what I said was wrong. I’m owning that.
The updated picture is more nuanced: GPT-5.5 shows real strength in agentic coding and multi-step tasks in my runs. But this isn’t a clean sweep other models still hold ground in specific areas, and the race is still very much alive.
GLM 5.1, Gemma, and Grok are not yet updated.

12

Prompt engineering is vibes and guesswork. SkillOpt treats it like training a neural network. From Microsoft Research.
It runs epochs with validation gates on natural-language skills for frozen LLM agents. No weights touched. You get a best_skill.md you can use right away. There's also a sleep plugin that lets Claude Code and Codex learn from your past sessions overnight and build long-term memory behind a held-out gate.
⭐ 6.4K #AI #OpenSource
github.com/microsoft/SkillOp…
Follow for daily dev finds 🔔

1

すごい!これ楽しい!
Codexへの画像生成の振り方とか勉強になりますね!
動画は外出中思いついた機能をCodexにどんどん追加させた結果、二人表示して三人で喋れるようになったやつです。

1
14

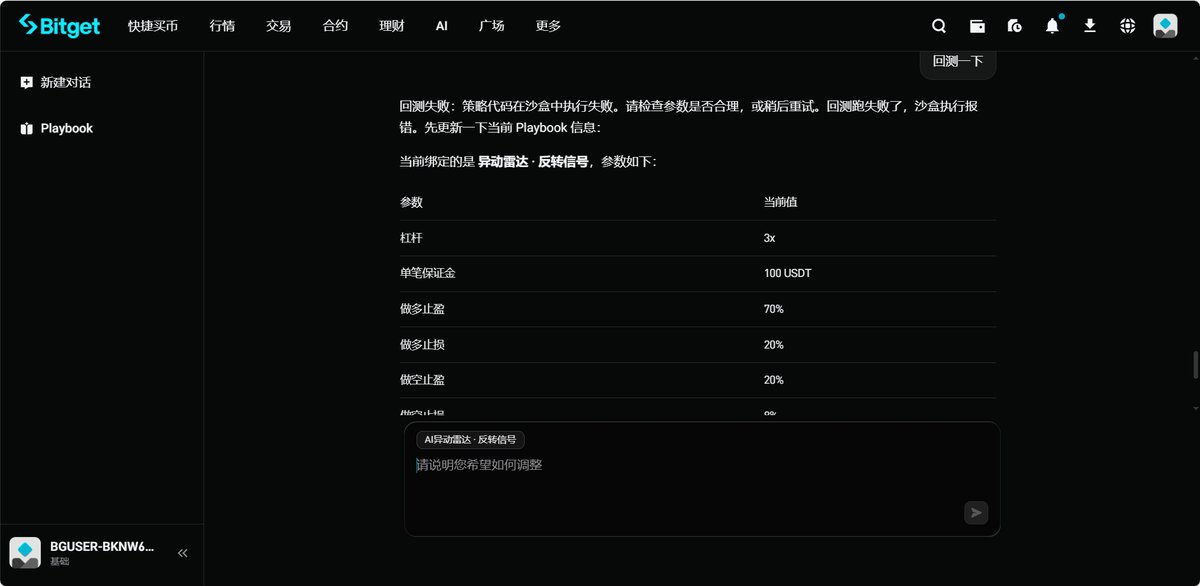
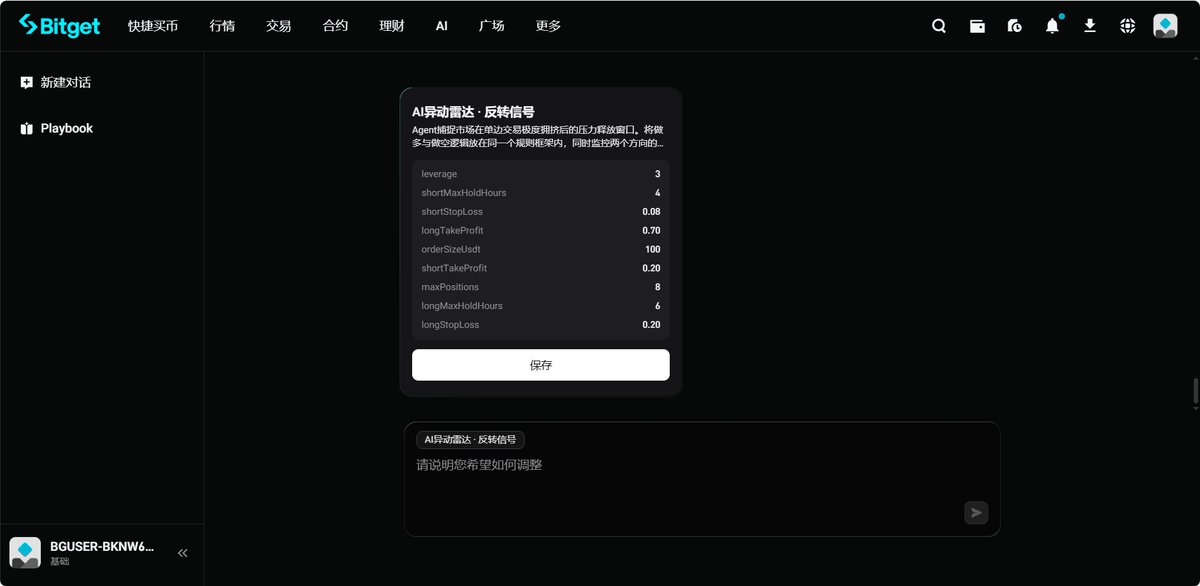
2:策略回测的时候参数可以自己选择
目前可选的参数是合约执行的通用参数(杠杆倍数、保证金)
其实和策略本身没有关系,实际本地你用codex跑getagent-skill的时候,你会发现策略本身是有参数可以修正的
后面通过成功回测后,这些参数出来了,但是还没法手动调整
5

建议推油先停用 pi 社区提供的 codex conversation 插件,目前观测到比较明显的 5.5 模型在开起该插件后对 edit tool 的调用持续 terminated 且无法恢复。
6

🚀 智谱的ZCode 3.0.0 新版来了,又是一个Codex的分X
每天有GLM5.2的300万免费token
全面切换自研 ZCode Agent 内核。 针对满血 GLM 深度优化长程推理、工具调用和大型工程执行链路,整体任务完成效果已显著优于第三方 Agent
新用户预置 GLM Start Plan 套餐和专属 150% 配额权益。 新用户即享连续 5 天 GLM 旗舰系列模型用量;升级或已订阅 GLM Coding Plan 用户应用内相比 API 调用专享 150% 配额
全新分组式任务工作区 ,支持拖拽折叠、跨区迁移、批量管理,高效管控多 Agent 并发任务,任务层级清晰可控
具体内容见 zcode.z.ai/cn


9
12
164
20,327

Why the decision to not allow editing of any text files from Codex itself?
5


なんつーか、俺はそんなに使ってないけどcodexやアンチグラビティみたいなのでツールやスキル作成しても、それを元にChatGPTとか Geminiが学習していくんじゃね?
最終的にはAIとのチャットのやり取りの中で常にその時に必要な最適化されたツールやスキルを裏で自動生成する感じになるんじゃね?
短期〜中期的(3ヶ月後〜1年後)にみると、codexとかすら無くなるんじゃないか?
10
